





描述
內容簡介
|
★★★【機器學習】+【演算法】★★★ ★★★★★【PyTorch】+【Jupyter】★★★★★ 一步一腳印、腳踏實地 機器學習經典演算法全面講解
我們平常視為理所當然的L1、L2、Softmax,Cross Entropy,都是基礎的機器學習所推導出來的,很多人以為不需要學的機器學習演算法,才是站穩腳步的基本大法!
本書就是讓你可以用Python來真正真槍實戰上手機器學習。從最基礎的資料清理、特徵工程開始,一直到資料集遺漏值的研究,包括了特徵變換、建構,降維等具有實用性的技巧,之後說明了模型是什麼,接下來全書就是各種演算法的詳解,最後還有一個難得的中文自然語言處理的案例,不像一般機器學習的書千篇一律MNIST手寫辨識、人臉辨識這麼平凡的東西,難得有深入「機器學習」的動手書,讓你真的可以在人工智慧的領域中走的長長久久。
大集結!聚類演算法 ✪K-means 聚類 ✪系統聚類 ✪譜聚類 ✪模糊聚類 ✪密度聚類 ✪高斯混合模型聚類 ✪親和力傳播聚類 ✪BIRCH 聚類
技術重點 ✪資料探索與視覺化 ✪Python實際資料集特徵工程 ✪模型選擇和評估 ✪Ridge回歸分析、LASSO回歸分析以及Logistic回歸分析 ✪時間序列分析 ✪聚類演算法與異常值檢測 ✪決策樹、隨機森林、AdaBoost、梯度提升樹 ✪貝氏演算法和K-近鄰演算法 ✪支持向量機和類神經網路 ✪關聯規則與文字探勘 ✪PyTorch深度學習框架 |
作者簡介
| 余本國
博士、碩士研究生導師。主講線性代數、高等數學、微積分、機率統計、數學實驗、Python語言、大數據分析基礎等課程。 2012年到加拿大York University做訪問學者。 現工作於海南醫學院生物醫學信息與工程學院。 作品有《Python數據分析基礎》、《基於Python的大數據分析基礎及實戰》等書。
孫玉林
長期從事大數據統計分析、機器學習與電腦視覺等方面的研究,曾多次獲得數學建模與資料探勘比賽一等獎。 出版《Python在機器學習的應用》、《R語言統計分析與機器學習》、《PyTorch深度學習入門與實戰》等著作。 |
目錄
| 01 Python 機器學習入門
1.1 機器學習簡介 1.2 安裝Anaconda(Python) 1.3 Python 快速入門 1.4 Python 基礎函數庫入門實戰 1.5 機器學習模型初探 1.6 本章小結
02 資料探索與視覺化 2.1 遺漏值處理 2.2 資料描述與異常值發現 2.3 視覺化分析資料關係 2.4 資料樣本間的距離 2.5 本章小結
03 特徵工程 3.1 特徵變換 3.2 特徵 3.3 特徵選擇 3.4 特徵提取和降維 3.5 資料平衡方法 3.6 本章小結
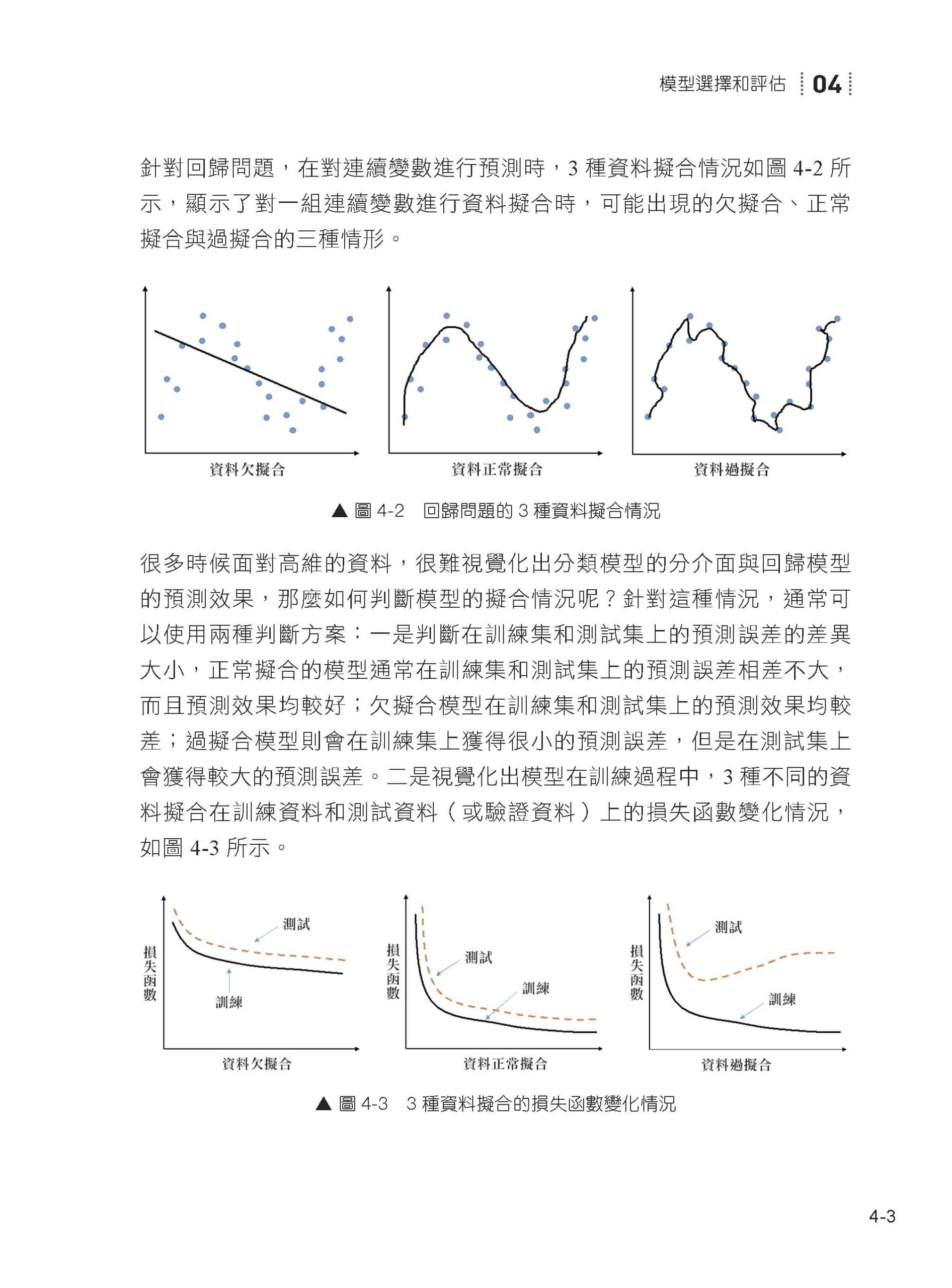
04 模型選擇和評估 4.1 模型擬合效果 4.2 模型訓練技巧 4.3 模型的評價指標 4.4 本章小結
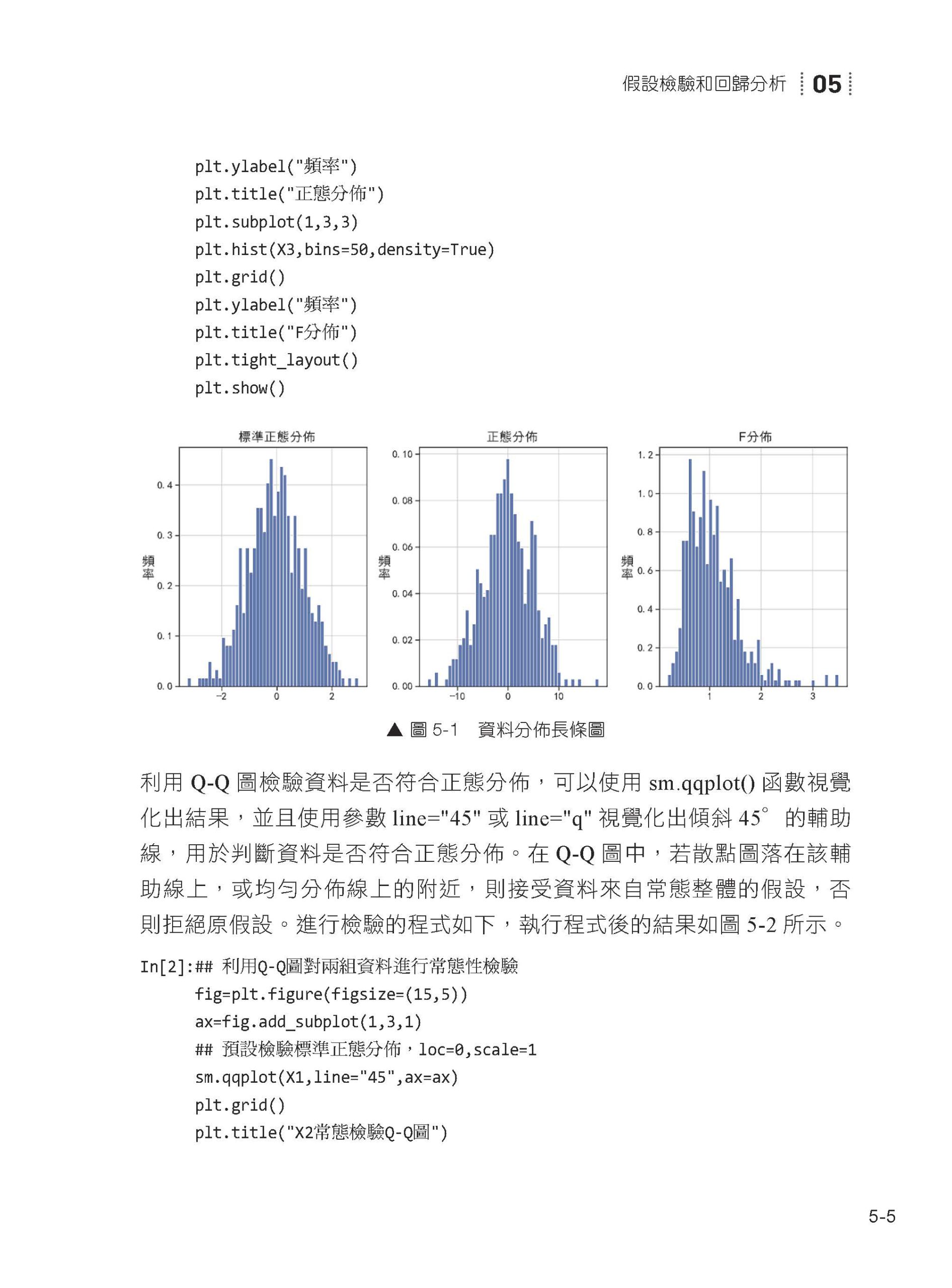
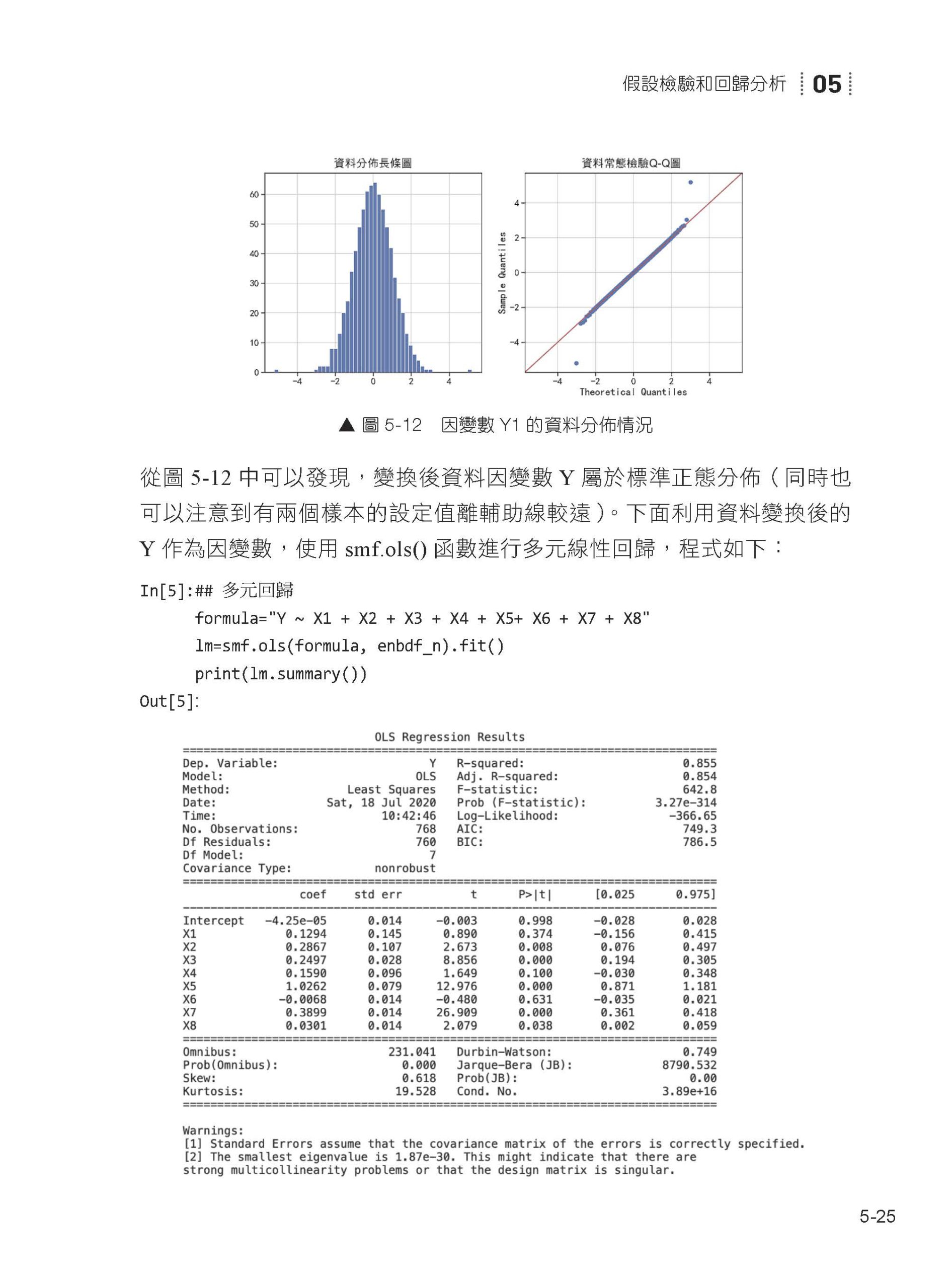
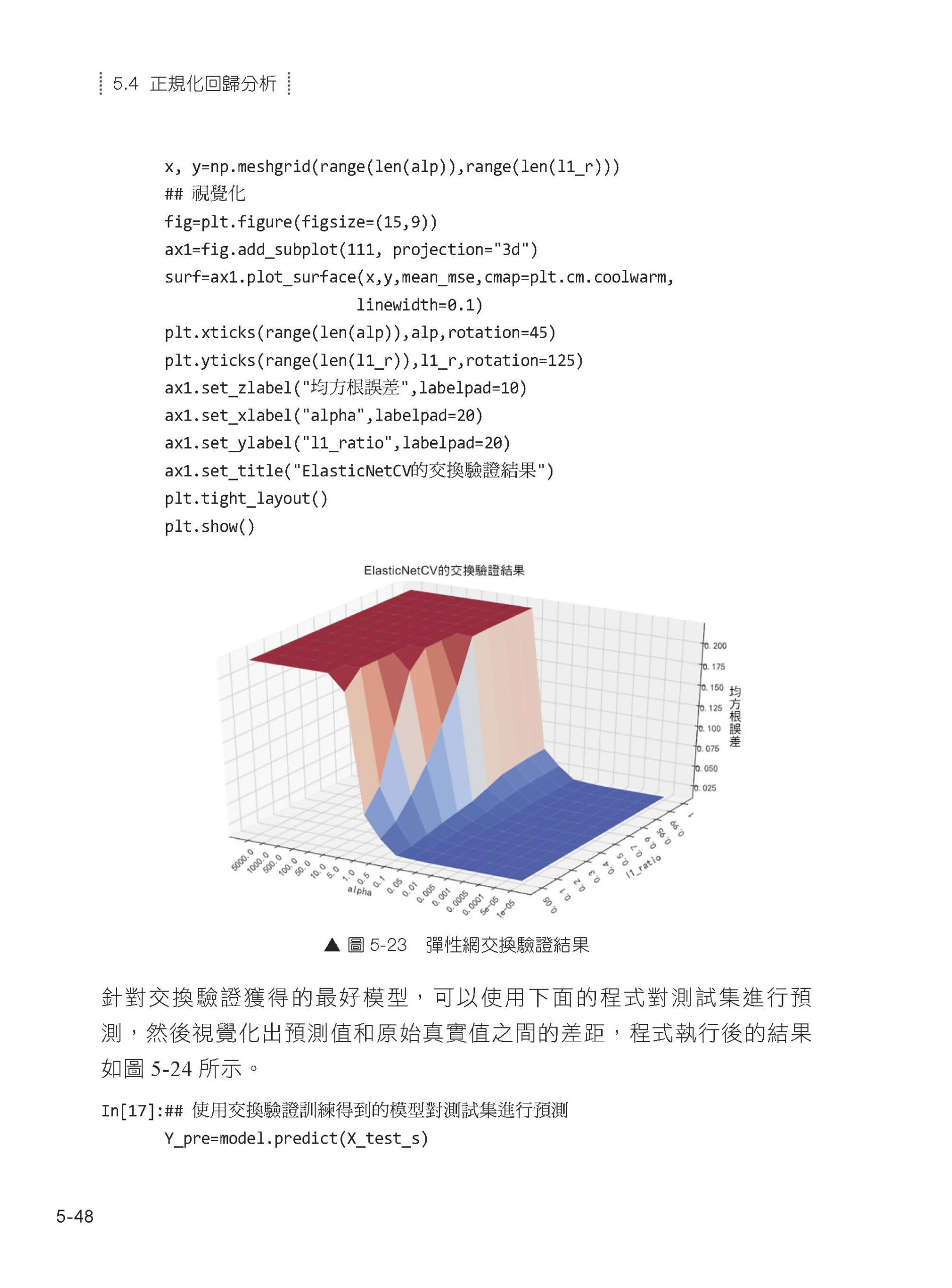
05 假設檢驗和回歸分析 5.1 假設檢驗 5.2 一元回歸 5.3 多元回歸 5.4 正規化回歸分析 5.5 Logistic 回歸分析 5.6 本章小結
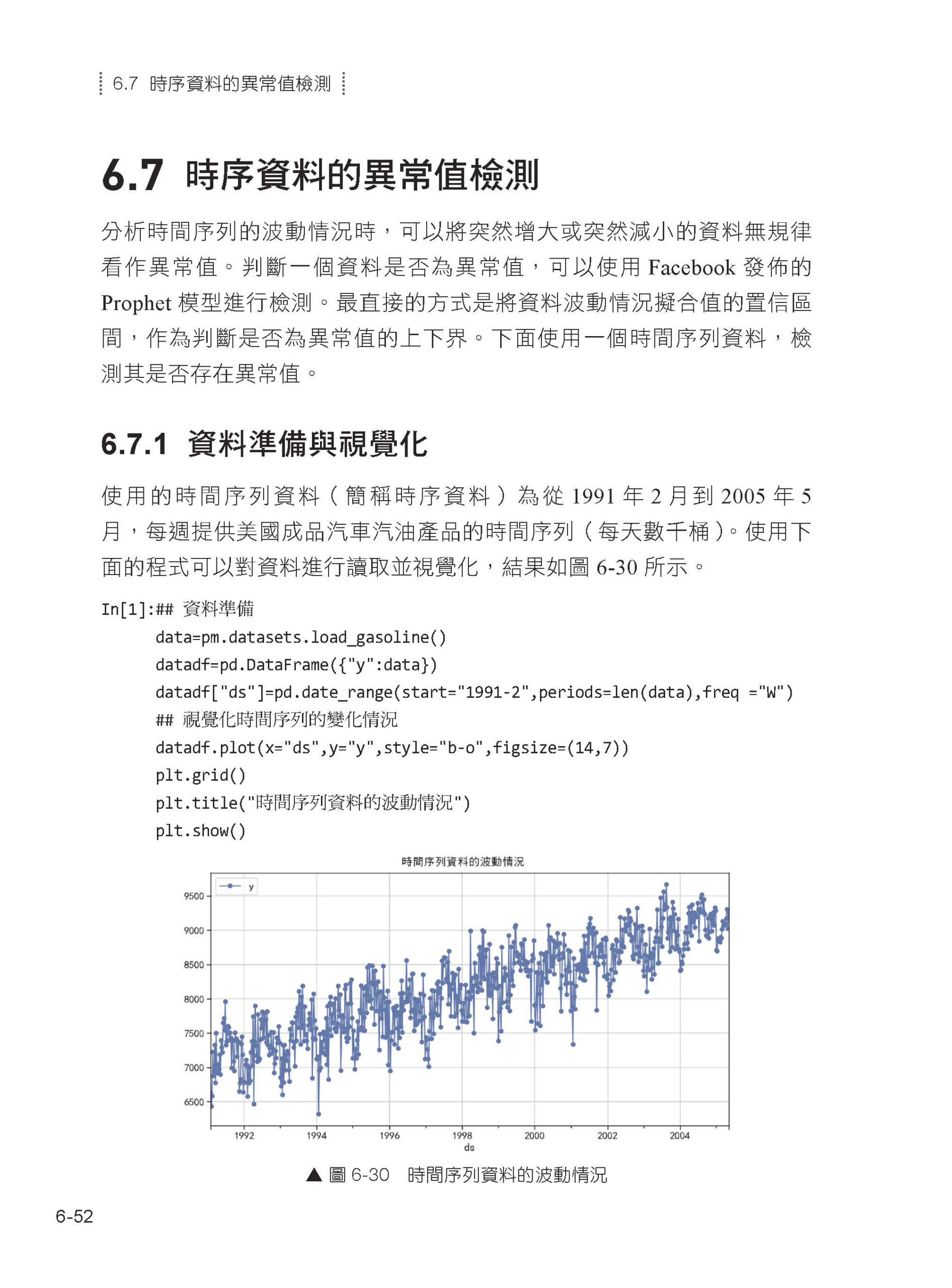
06 時間序列分析 6.1 時間序列資料的相關檢驗 6.2 移動平均演算法 6.3 ARIMA 模型 6.4 SARIMA 模型 6.5 Prophet 模型預測時間序列 6.6 多元時間序列ARIMAX模型 6.7 時序資料的異常值檢測 6.8 本章小結
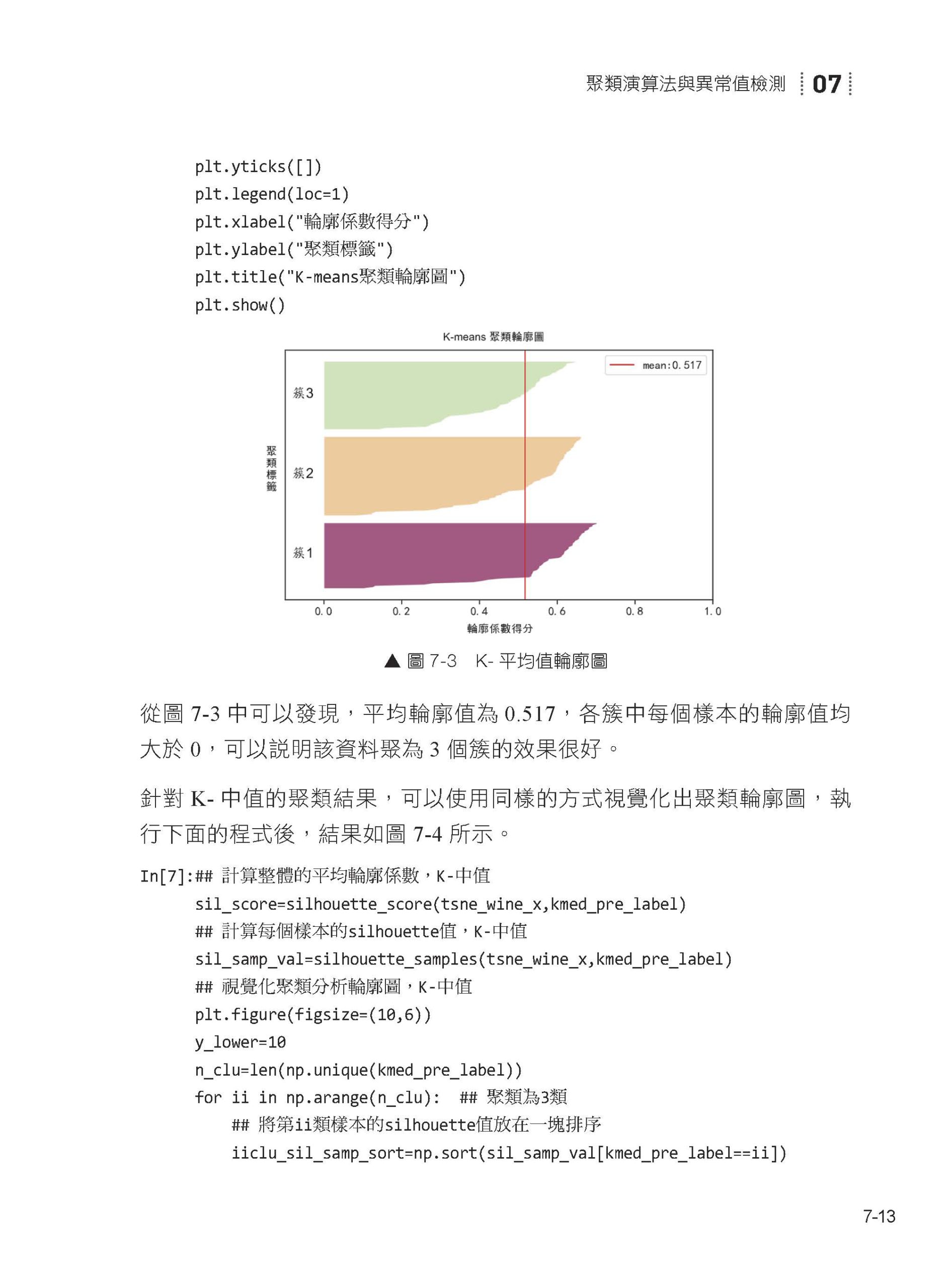
07 聚類演算法與異常值檢測 7.1 模型簡介 7.2 資料聚類分析 7.3 資料異常值檢測分析 7.4 本章小結
08 決策樹和整合學習 8.1 模型簡介與資料準備 8.2 決策樹模型 8.3 隨機森林模型 8.4 AdaBoost 模型 8.5 梯度提升樹(GBDT) 8.6 本章小結
09 貝氏演算法和K- 近鄰演算法 9.1 模型簡介 9.2 貝氏分類演算法 9.3 貝氏網路資料分類 9.4 K- 近鄰演算法 9.5 本章小結
10 支持向量機和類神經網路 10.1 模型簡介 10.2 支援向量機模型 10.3 全連接神經網路模型 10.4 本章小結
11 連結規則與文字探勘 11.1 模型簡介 11.2 資料連結規則探勘 11.3 文字資料前置處理 11.4 文字聚類分析 11.5 《三國演義》人物關係分析 11.6 本章小結
12 深度學習入門 12.1 深度學習介紹 12.2 PyTorch 入門 12.3 卷積神經網路辨識草書 12.4 循環神經網路新聞分類 12.5 自編碼網路重構圖像 12.6 本章小結
A 參考文獻 |
序
| 人工智慧的浪潮正在席捲全球,機器學習是人工智慧領域最能表現智慧的分支。隨著電腦性能的提升,機器學習在各個領域中大放光彩。尤其是自從2016 年AlphaGo 戰勝人類圍棋頂尖高手後,機器學習、深度學習「一夜爆紅」,遍佈網際網路的各個角落,成為民眾茶餘飯後討論最多的話題。不過很多人可能苦於不知如何下手,又或考慮到演算法中的數學知識,從而產生了放棄學習的念頭。因此本書剔除了枯燥乏味的數學原理及其推導過程,用淺顯易懂的程式去實現這些經典和主流的演算法,並在實際的場景中對演算法進行應用。
Python 語言是全球最熱門的程式語言,其最大的優點就是自由、開放原始碼。隨著Python 的不斷發展,其已經在機器學習和深度學習領域受到了許多學者和企業的關注。本書在簡介機器學習理論知識的同時,重點研究如何使用Python 語言來建模分析實際場景中的資料,增強讀者的動手能力,促進讀者對理論知識的深刻瞭解。
本書共分為12 章,前4 章介紹了Python 的使用與基於Python 機器學習的預備知識,後8 章則分模組介紹了統計分析、機器學習與深度學習的主流演算法和經典應用。本書盡可能做到內容全面、循序漸進,案例經典實用,而且程式透過Jupyter Notebook 來完成,清晰易懂,方便操作,即使沒有Python 基礎知識的讀者也能看懂本書的內容。
透過閱讀第1 章~第4 章,你將學到以下內容。 第1 章:Python 機器學習入門。先介紹機器學習相關知識,然後介紹如何安裝Anaconda 用於Python 程式的運行,接著介紹Python 相關的基礎知識, 快速入門Python 程式設計, 最後介紹NumPy、pandas 與Matplotlib 等第三方Python 函數庫的使用。 第2 章:資料探索與視覺化。將介紹如何使用Python 對資料集的遺漏值、異常值等進行前置處理,以及如何使用豐富的視覺化圖型,展示資料之間的潛在關係,增強對資料的全面認識。 第3 章:特徵工程。利用Python 結合實際資料集,介紹如何對資料進行特徵變換、特徵建構、特徵選擇、特徵提取與降維,以及對類別不平衡資料進行資料平衡的方法。 第4 章:模型選擇和評估。該章主要介紹如何更進一步地訓練資料,防止模型過擬合,以及針對不同類型的機器學習任務,如何評價模型的性能。
透過閱讀第5 章~第12 章,你將學到以下內容。 第5 章:假設檢驗和回歸分析。該章主要介紹統計分析的相關內容,如t檢驗、方差分析、多元回歸分析、Ridge 回歸分析、LASSO 回歸分析以及Logistic 回歸分析等內容。 第6 章:時間序列分析。該章將介紹如何對時間序列這一類特殊的資料進行建模和預測,結合實際資料集,比較不同類型的預測演算法的預測效果。 第7 章:聚類演算法與異常值檢測。該章主要介紹機器學習中的資料聚類和異常值檢測兩種無監督學習任務內容。其中聚類演算法將介紹K- 平均值聚類、K- 中值聚類、層次聚類、密度聚類等經典的聚類演算法;異常值檢測演算法將介紹LOF、COF、SOD 等經典的無監督檢測演算法。 第8 章:決策樹和整合學習。該章主要介紹幾種基於樹的機器學習演算法,如決策樹、隨機森林、AdaBoost、梯度提升樹等模型在資料分類與回歸中的應用。 第9 章:貝氏演算法和K- 近鄰演算法。該章將介紹如何利用貝氏模型進行文字分類及如何建構貝氏網路,同時還會介紹K- 近鄰演算法在資料分類和回歸上的應用。 第10 章:支持向量機和類神經網路。該章主要介紹支持向量機與全連接神經網路在資料分類和回歸上的應用。 第11 章:連結規則與文字探勘。該章主要結合具體的資料集,介紹如何利用Python 進行連結規則分析及對文字資料的分析與探勘。 第12 章:深度學習入門。該章主要依靠PyTorch 深度學習框架,介紹相關的深度學習入門知識,如透過卷積神經網路進行圖型分類、透過循環神經網路進行文字分類及透過自編碼網路進行圖型重建等實戰案例。
本書在編寫時盡可能地使用了目前最新的Python 庫,但是隨著電腦技術的迅速發展,以及作者水準有限,編寫時間倉促,書中難免存在疏漏,敬請讀者不吝賜教。
余本國 |