



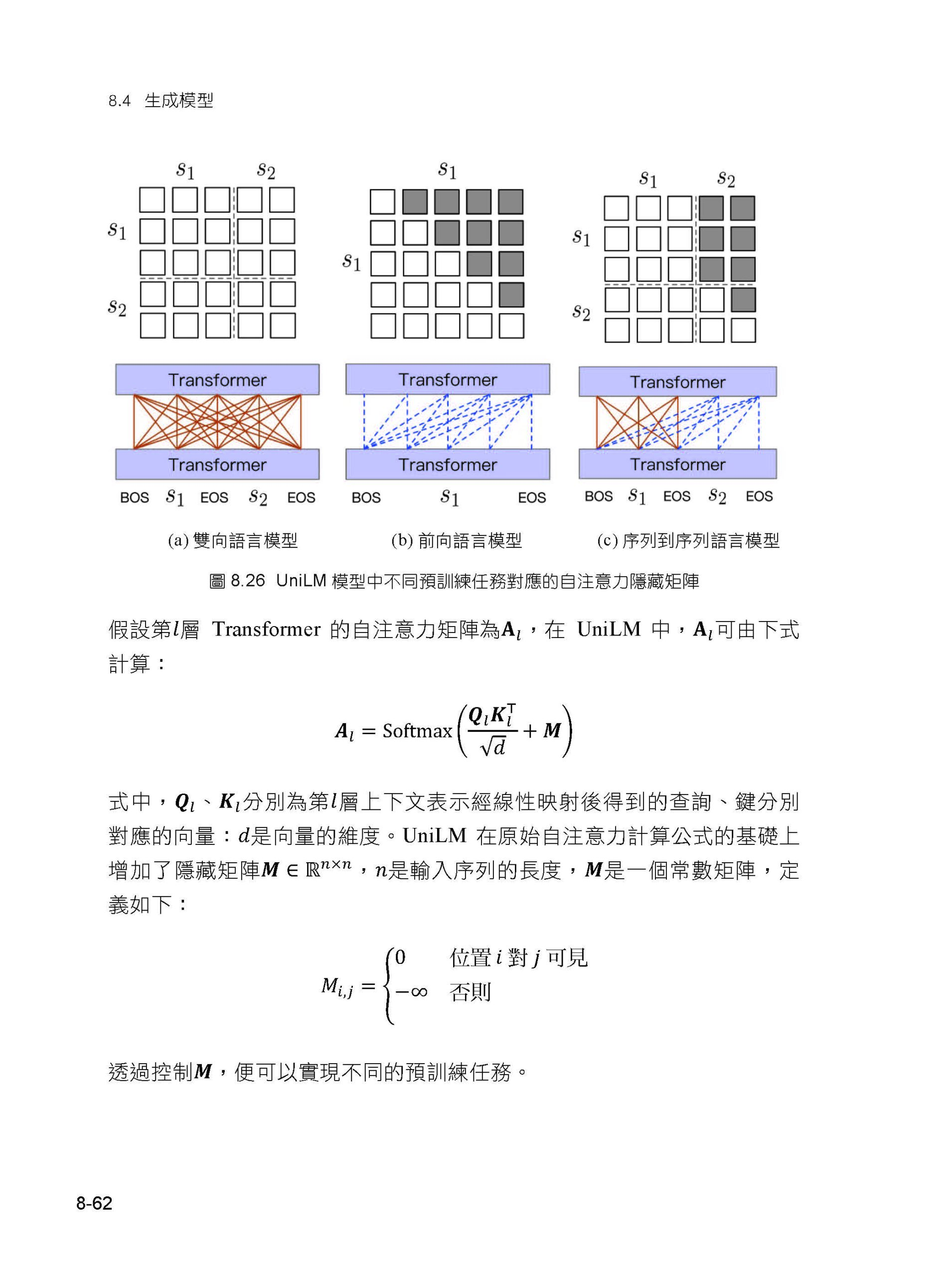


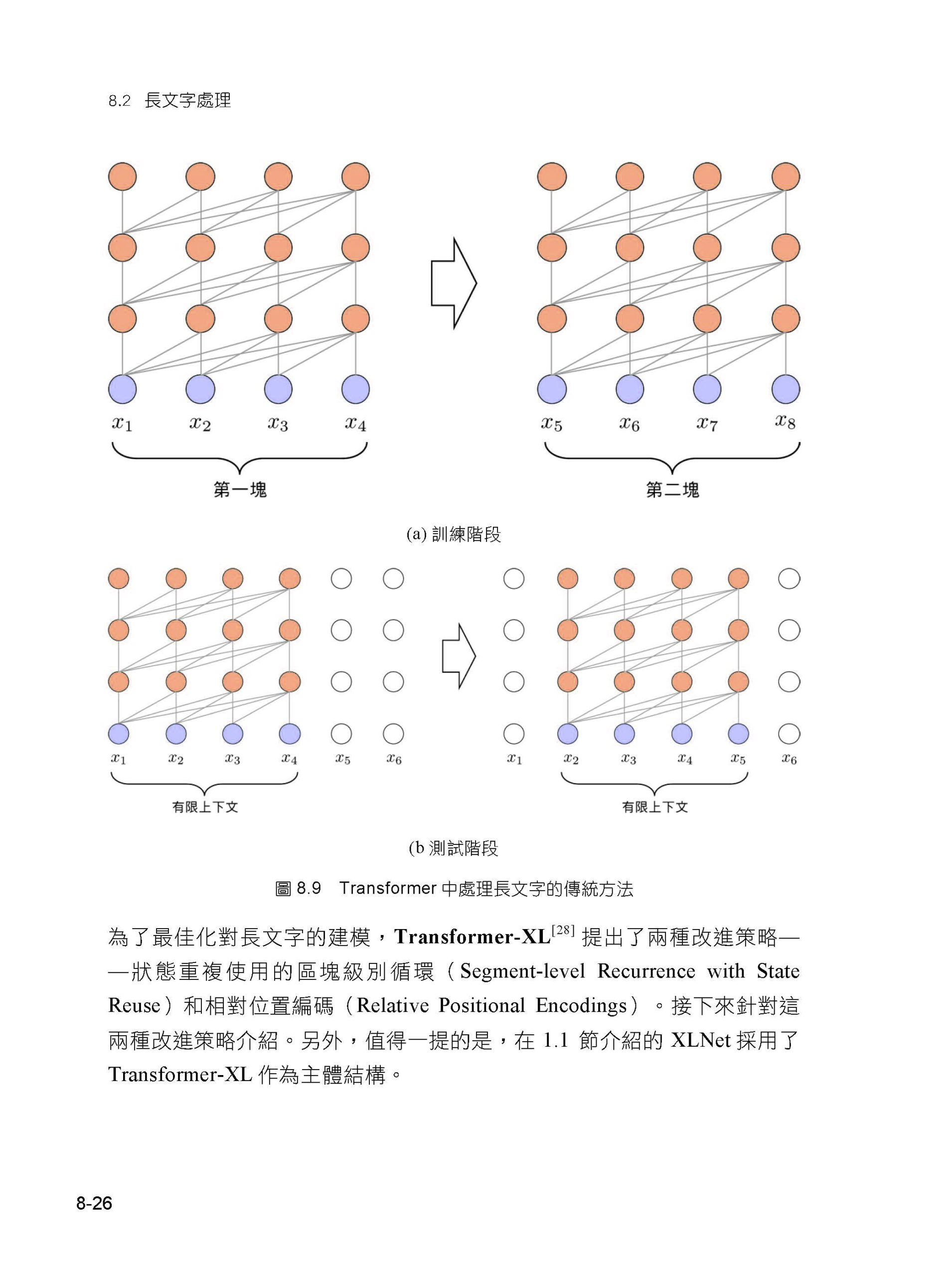
描述
內容簡介
|
★★★★★【全中文自然語言處理】★★★★★ 還在對huggingface上的預訓練模型(bert-base)等都是針對歐美語系感到困擾嗎? 本書就是為中文世界讀者專屬打造的,讓你一窺中文模型的自然語言處理! 自然語言處理(NLP)號稱「人工智慧皇冠上的珍珠」,是AI世界中最先進也是應用最廣的領域。從早期的知識模型,到中間的統計模型,一直到最新的神經網路模型,早已服務於你所看到的任何大型系統,包括Google的關鍵字排名、Google翻譯、購物網站推薦系統、Siri/OK Google等,都是NLP產出的精華。如果你還以為CNN、GAN等圖型處理的AI架構很有趣,換到NLP領域中,你會發現更多驚奇!
本書從預訓練模型的角度對理性主義和經驗主義這兩次重要的發展進行了系統性的論述,能夠幫助讀者深入了解這些技術背後的原理、相互之間的聯繫以及潛在的局限性,對於當前學術界和工業界的相關研究與應用都具有重要的價值。本書由中文自然語言處理的首席單位「哈爾濱工業大學」完成,其在Huggningface的Transformer模型上有貢獻多個純中文模型,由這些專家親著的內容,絕對是你想了解中文NLP專業的第一選擇。
本書特色 ◎不只英文,還有中文模型的自然語言處理 以往的自然語言處理專書多以處理歐美語系為主,令使用中文為母語的我們甚感遺憾,如今,本書就是你第一本可深入了解「中文模型的自然語言處理」最棒的書籍!
◎中文自然語言處理的首席單位專家親著 本書由中文自然語言處理的首席單位「哈爾濱工業大學」完成,其在Huggningface的Transformer模型上有貢獻多個純中文模型,由這些專家親著的內容,絕對是你想了解中文NLP專業的第一選擇。
◎精美圖表、專業講解 本書內含作者精心製作的圖表,有助於讀者理順思緒、更好地學習自然語言處理的奧妙。
本書技術重點 ✪詞的獨熱表示、詞的分散式表示、文字的詞袋表示 ✪文字分類問題、結構預測問題、序列到序列問題 ✪NLTK 工具集、LTP 工具集、大規模預訓練資料 ✪多層感知器模型、卷積神經網路、循環神經網路、注意力模型 ✪情感分類實戰、詞性標注實戰 ✪Word2vec 詞向量、GloVe 詞向量 ✪靜態詞向量預訓練模型、動態詞向量預訓練模型 ✪預訓練語言模型、GPT、BERT ✪模型蒸餾與壓縮、DistilBERT、TinyBERT、MobileBERT、TextBrewer ✪生成模型、BART、UniLM、T5、GPT-3、可控文字生成 ✪多語言融合、多媒體融合、異質知識融合 ✪VideoBERT、VL-BERT、DALL·E、ALIGN |
作者簡介
| 車萬翔
博士,在ACL、EMNLP、AAAI、IJCAI等國內外高水準期刊和會議上發表學術論文50餘篇,其中AAAI 2013年的文章獲得了論文提名獎,論文累計被引用6,000餘次(Google Scholar資料),H-index值為40。
郭江
博士後研究員,研究方向為自然語言處理與機器學習。在人工智慧、自然語言處理領域國際重要會議及期刊(如ACL、EMNLP、AAAI等)發表論文20餘篇。是被業界廣泛應用的中文語言技術平臺LTP的主要研發者之一。2018年,獲中文資訊學會「優秀博士學位論文」提名獎。
崔一鳴
多次獲得機器翻譯、機器閱讀理解、自然語言理解評測冠軍,其中包括機器閱讀理解權威評測SQuAD、自然語言理解權威評測GLUE等。研製的中文閱讀理解及預訓練模型開源專案被業界廣泛應用,在GitHub累計獲得1萬以上星標,HuggingFace平臺月均調用量達到100萬次。發表學術論文30餘篇(包括ACL、EMNLP、AAAI等高水準論文),申請發明專利20餘項。 |
目錄
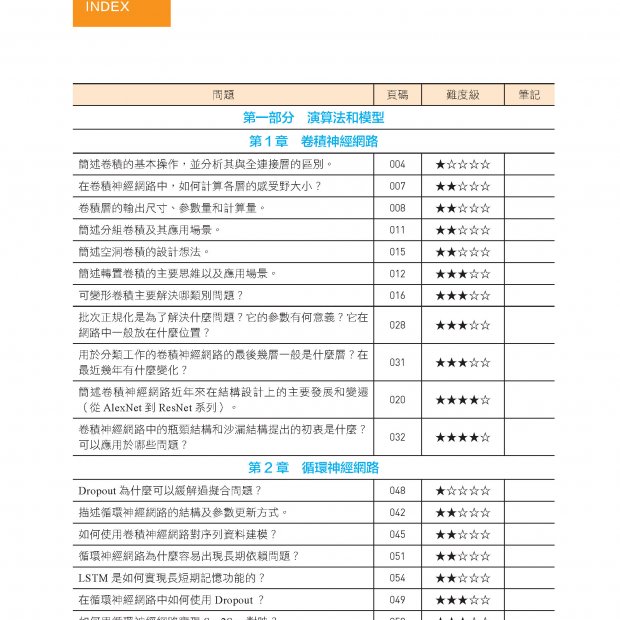
| 01 緒論
1.1 自然語言處理的概念 1.2 自然語言處理的困難 1.3 自然語言處理任務系統 1.4 自然語言處理技術發展歷史
02 自然語言處理基礎 2.1 文字的表示 2.2 自然語言處理任務 2.3 基本問題 2.4 評價指標 2.5 小結
03 基礎工具集與常用資料集 3.1 NLTK 工具集 3.2 LTP 工具集 3.3 PyTorch 基礎 3.4 大規模預訓練資料 3.5 更多資料集 3.6 小結
04 自然語言處理中的神經網路基礎 4.1 多層感知器模型 4.2 卷積神經網路 4.3 循環神經網路 4.4 注意力模型 4.5 神經網路模型的訓練 4.6 情感分類實戰 4.7 詞性標注實戰 4.8 小結
05 靜態詞向量預訓練模型 5.1 神經網路語言模型 5.2 Word2vec 詞向量 5.3 GloVe 詞向量 5.4 評價與應用 5.5 小結
06 動態詞向量預訓練模型 6.1 詞向量——從靜態到動態 6.2 以語言模型為基礎的動態詞向量預訓練 6.3 小結
07 預訓練語言模型 7.1 概述 7.2 GPT 7.3 BERT 7.4 預訓練語言模型的應用 7.5 深入了解BERT 7.6 小結
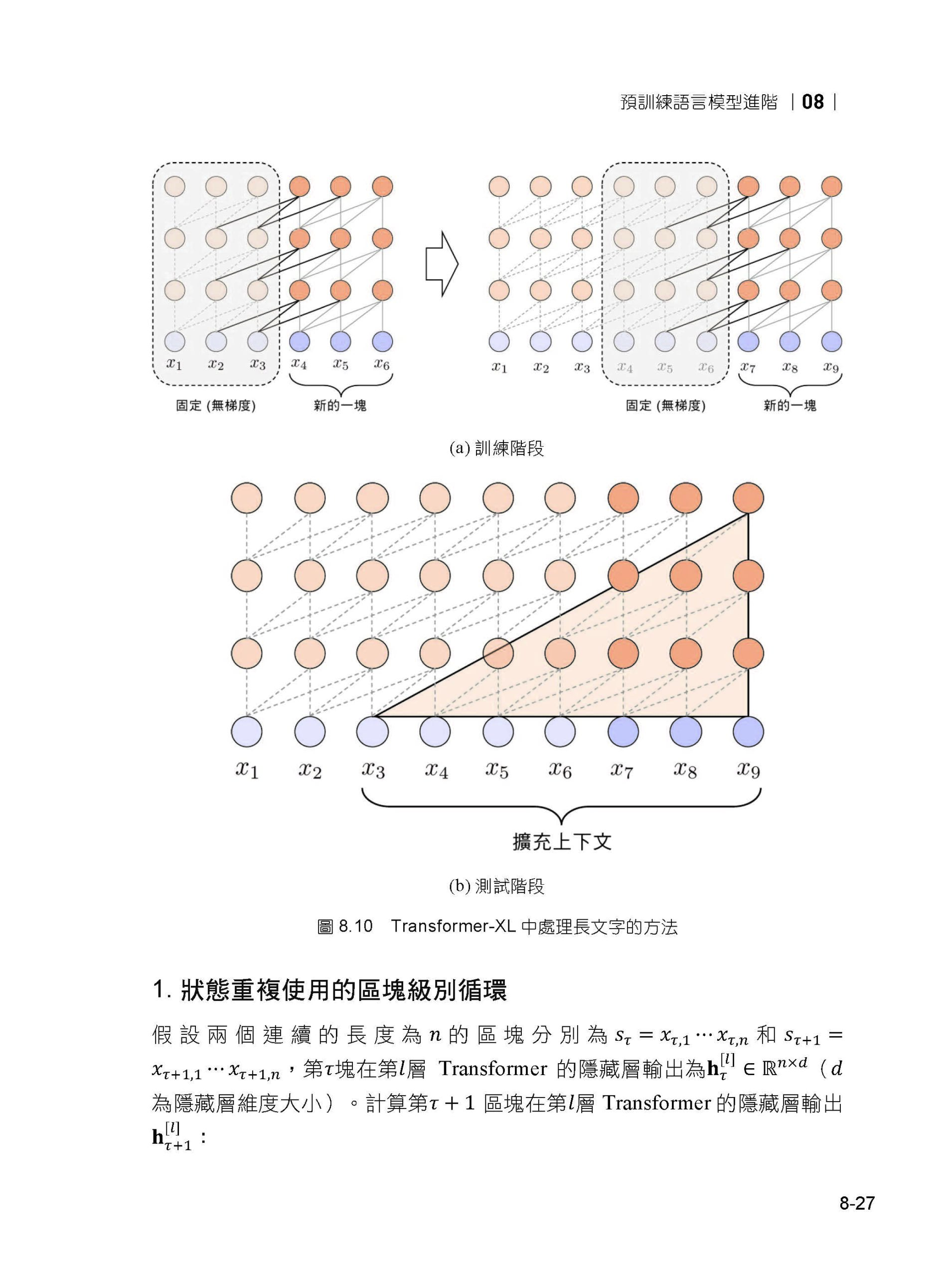
08 預訓練語言模型進階 8.1 模型最佳化 8.2 長文字處理 8.3 模型蒸餾與壓縮 8.4 生成模型 8.5 小結
09 多模態融合的預訓練模型 9.1 多語言融合 9.2 多媒體融合 9.3 異質知識融合 9.4 更多模態的預訓練模型 9.5 小結
A 參考文獻 B 術語表 |
序
| 前言
自然語言是人類思維的載體和交流的基本工具,也是人類區別於動物的根本標示,更是人類智慧發展的重要外在表現形式。自然語言處理(NaturalLanguage Processing,NLP)主要研究用電腦了解和生成自然語言的各種理論與方法,屬於人工智慧領域的重要的甚至核心的分支。隨著網際網路的快速發展,網路文字規模呈爆炸性增長,為自然語言處理提出了巨大的應用需求。同時,自然語言處理研究也為人們更深刻地了解語言的機制和社會的機制提供了一條重要的途徑,因此具有重要的科學意義。
自然語言處理技術經歷了從早期的理性主義到後來的經驗主義的轉變。近十年來,深度學習技術快速發展,引發了自然語言處理領域一系列的變革。但是深度學習的演算法有一個嚴重的缺點,就是過度依賴於大規模的有標注資料。2018 年以來,以BERT、GPT 為代表的超大規模預訓練語言模型恰好彌補了自然語言處理標注資料不足的這一缺點,幫助自然語言處理獲得了一系列的突破,使得包括閱讀了解在內的許多自然語言處理任務的性能都獲得了大幅提高,在有些資料集上甚至達到或超過了人類水準。那麼,預訓練模型是如何獲得如此強大的威力甚至「魔力」的呢?希望本書能夠為各位讀者揭開預訓練模型的神秘面紗。
本書主要內容 本書內容分為三部分:基礎知識、預訓練詞向量和預訓練模型。各部分內容安排如下。 第1 部分:基礎知識 包括第2-4 章,主要介紹自然語言處理和深度學習的基礎知識、基本工具集和常用資料集。 第2 章首先介紹文字的向量表示方法,重點介紹詞嵌入表示。其次介紹自然語言處理的三大任務,包括語言模型、基礎任務和應用任務。雖然這些任務看似紛繁複雜,但是基本可以歸納為三類問題,即文字分類問題、結構預測問題和序列到序列問題。最後介紹自然語言處理任務的評價方法。 第3 章首先介紹兩種常用的自然語言處理基礎工具集——NLTK 和LTP。其次介紹本書使用的深度學習框架PyTorch。最後介紹自然語言處理中常用的大規模預訓練資料。 第4 章首先介紹自然語言處理中常用的四種神經網路模型:多層感知器模型、卷積神經網路、循環神經網路,以及以Transformer 為代表的自注意力模型。其次介紹模型的參數最佳化方法。最後透過兩個綜合性的實戰項目,介紹如何使用深度學習模型解決一個實際的自然語言處理問題。 第2 部分:預訓練詞向量 包括第5-6 章,主要介紹靜態詞向量和動態詞向量兩種詞向量的預訓練方法及應用。 第5 章介紹語言模型以及詞共現兩大類方法的靜態詞向量的預訓練技術,它們能夠透過自監督學習方法,從未標注文字中獲得詞彙等級的語義表示。最後提供對應的程式實現。 第6 章介紹雙向LSTM 語言模型的動態詞向量的預訓練技術,它們能夠根據詞語所在的不同上下文指定不同的詞向量表示,並作為特徵進一步提升下游任務的性能。最後同樣提供對應的程式實現。 第3 部分:預訓練模型 包括第7-9 章,首先介紹幾種典型的預訓練語言模型及應用,其次介紹目前預訓練語言模型的最新進展及融入更多模態的預訓練模型。 第7 章首先介紹兩種典型的預訓練語言模型,即以GPT 為代表的以自回歸為基礎的預訓練語言模型和以BERT 為代表的以非自回歸為基礎的預訓練語言模型,其次介紹如何將預訓練語言模型應用於典型的自然語言處理任務。 第8 章主要從四個方面介紹預訓練語言模型最新的進展,包括用於提高模型準確率的模型最佳化方法,用於提高模型表示能力的長文字處理方法,用於提高模型可用性的模型蒸餾與壓縮方法,以及用於提高模型應用範圍的生成模型。 第9 章在介紹語言之外,還融合更多模態的預訓練模型,包括多種語言的融合、多種媒體的融合以及多種異質知識的融合等。
致謝 本書第1-4 章及第9 章部分內容由哈爾濱工業大學車萬翔教授編寫;第5、6 章及第8、9 章部分內容由美國麻省理工學院(MIT)郭江博士後編寫;第7 章及第8 章主要內容由科大訊飛主管研究員崔一鳴編寫。全書由哈爾濱工業大學劉挺教授主審。
本書的編寫參閱了大量的著作和相關文獻,在此一併表示衷心的感謝!感謝宋亞東先生和電子工業出版社博文視點對本書的重視,以及為本書出版所做的一切。
由於作者水準有限,書中不足及錯誤之處在所難免,敬請專家和讀者給予 批評指正。
車萬翔 |