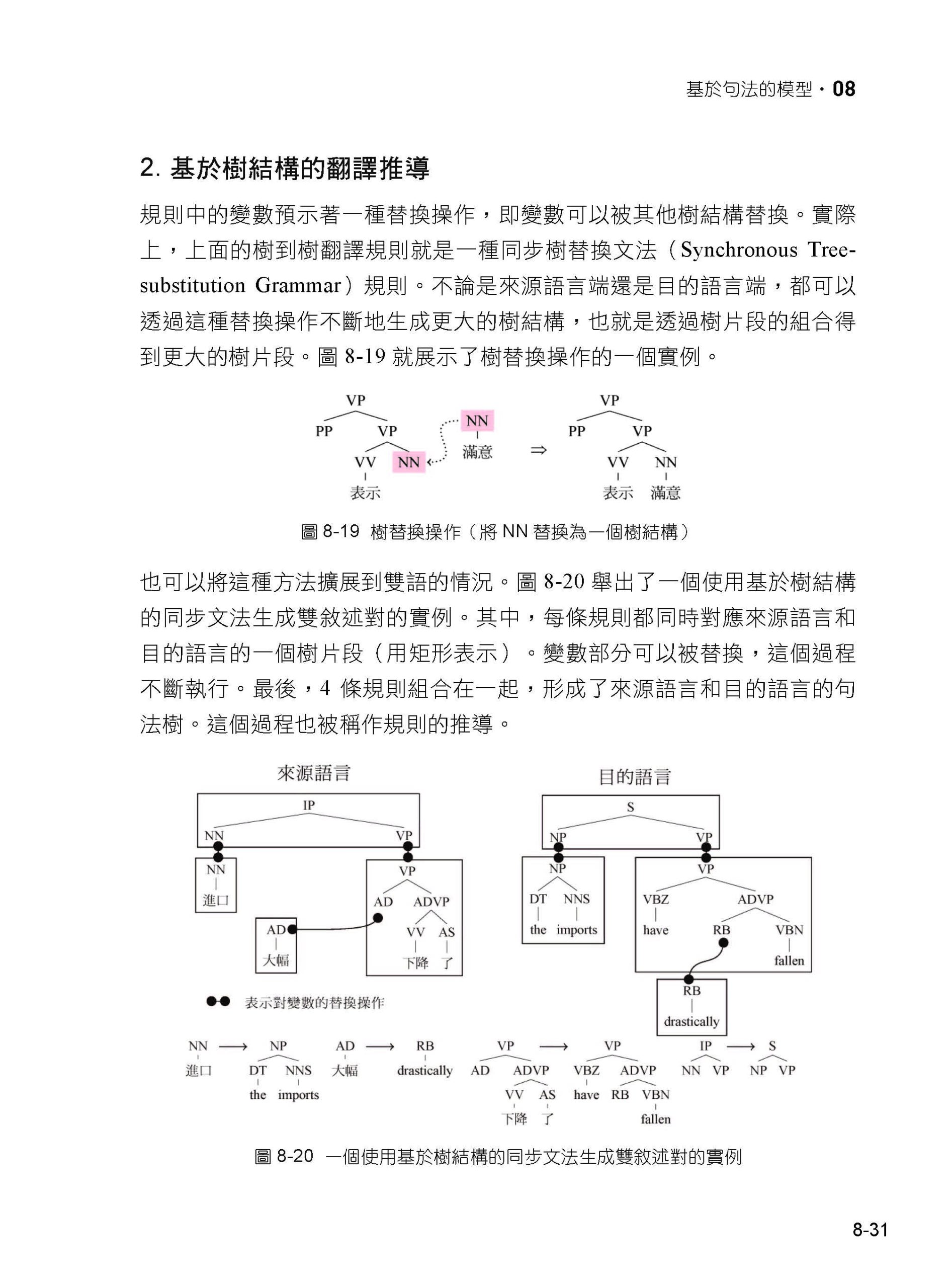
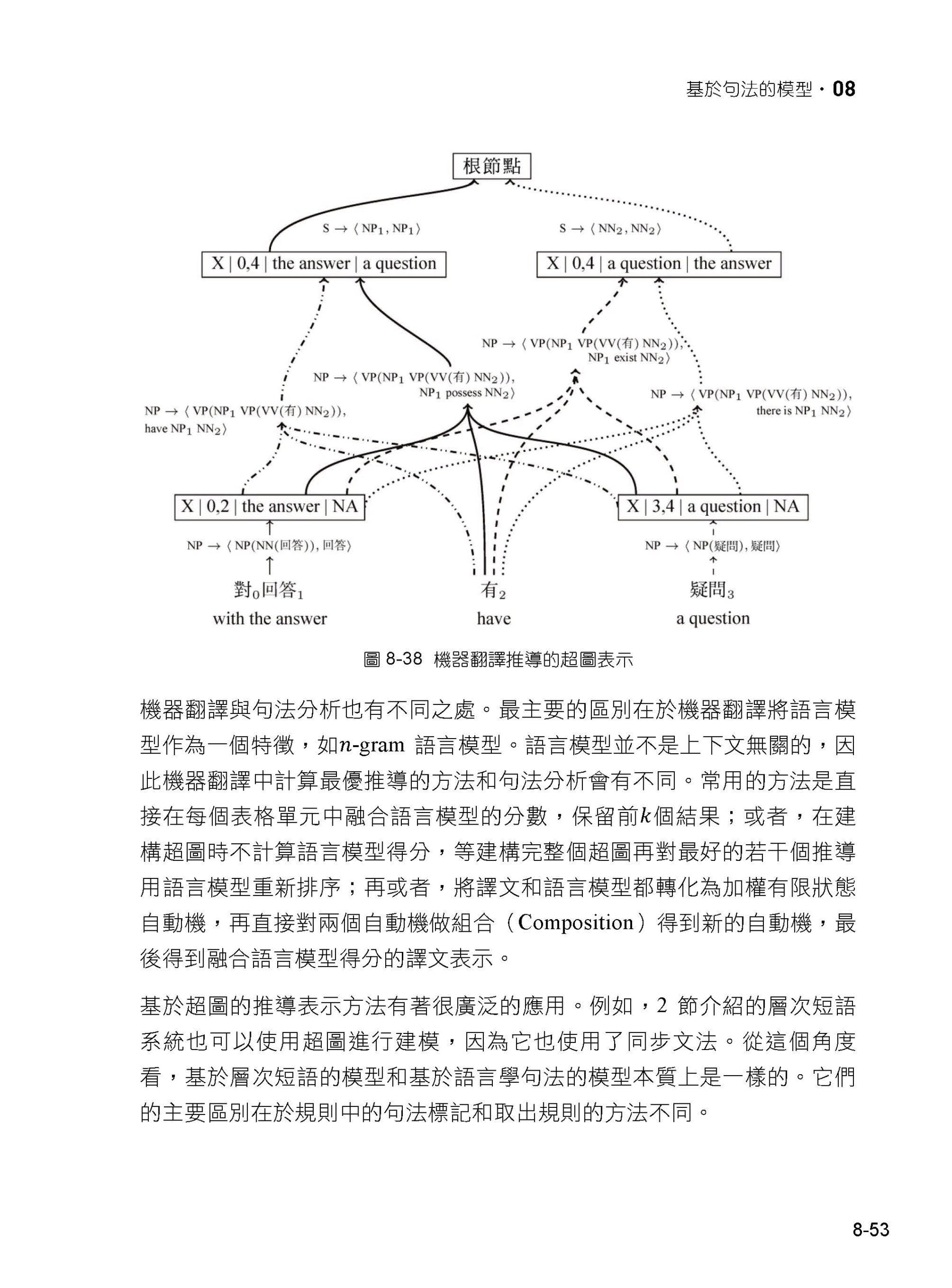
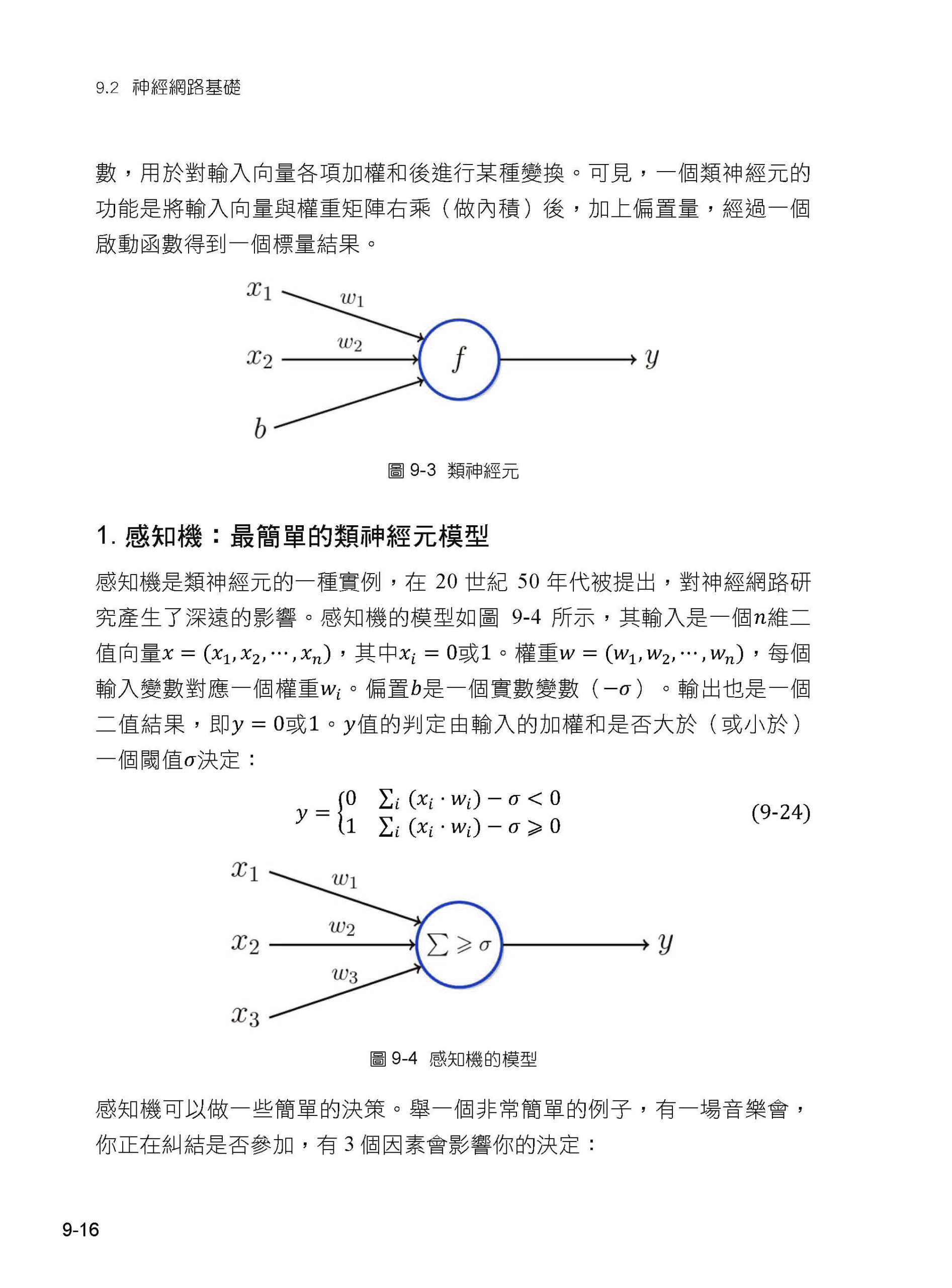
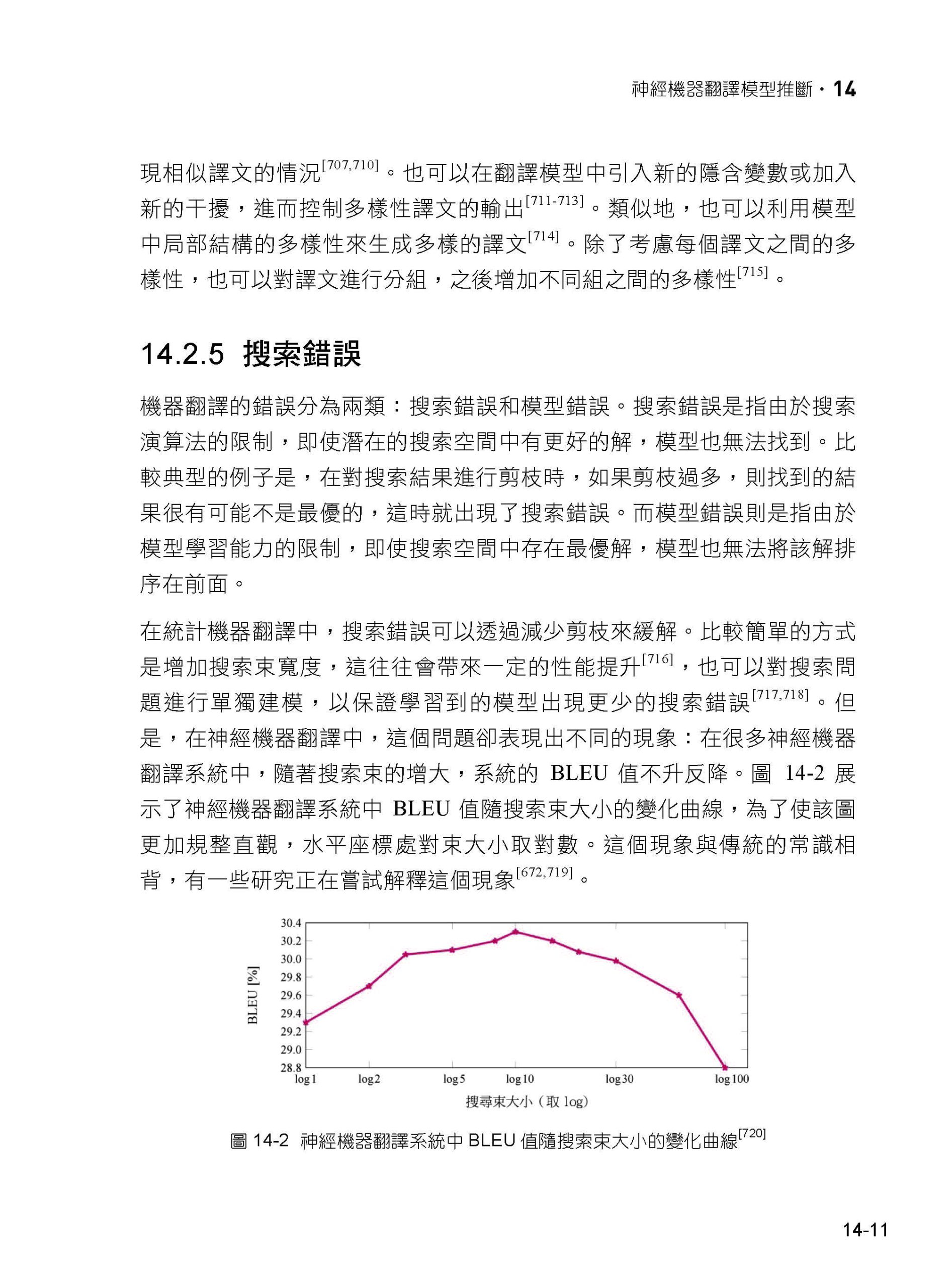
| 前言
緣起
讓電腦進行自然語言的翻譯是人類長久以來的夢想,也是人工智慧的重要目標之一。自20世紀90年代起,機器翻譯邁入了以統計建模為基礎的時代,發展到今天,已經大量應用了深度學習等機器學習方法,並獲得了令人矚目的進步。在這個時代背景下,對機器翻譯的模型、方法和實現技術進行深入了解,是自然語言處理領域的研究者和實踐者所渴望的。
與所有從事機器翻譯研究的人一樣,筆者也夢想著有朝一日,機器翻譯能夠完全實現。這個想法可以追溯到1973年,姚天順教授和王寶庫教授領銜創立了東北大學自然語言處理實驗室,把機器翻譯作為奮鬥的目標。這一舉動影響了包括筆者在內的許多人。雖然那時的機器翻譯技術並不先進,研究條件也異常艱苦,但是努力實現機器翻譯的夢想從未改變。
步入21世紀後,統計學習方法的興起給機器翻譯帶來了全新的想法,也帶來了巨大的技術進步。筆者有幸經歷了那個時代,也加入了機器翻譯研究的浪潮中。筆者從2007年開始研發NiuTrans開放原始碼系統,在2012年對NiuTrans機器翻譯系統進行產業化,並創立了小牛翻譯。在此過程中,筆者目睹了機器翻譯的成長,並不斷地被機器翻譯所取得的進步感動。那時,筆者就考慮將機器翻譯的模型和方法進行複習,形成資料供人閱讀。雖然粗略寫過一些文字,但是未成系統,只在教學環節使用,供實驗室的同學在閒暇時參考。
機器翻譯技術發展之快是無法預見的。2016年之後,隨著深度學習方法在機器翻譯中的進一步應用,機器翻譯迎來了前所未有的機遇。新的技術方法層出不窮,機器翻譯系統也獲得了廣泛應用。這時,筆者心裡又湧現出將機器翻譯的技術內容編撰成書的想法。這種強烈的念頭使筆者完成了本書的第一個版本(共7章),並將其開放原始碼,供人廣泛閱讀。承蒙同行厚愛,獲得了很多回饋,包括一些批評和意見。這使筆者可以更全面地梳理寫作想法。
最初,筆者的想法僅是將機器翻譯的技術內容做成資料供人閱讀。但是,朋友和同事們一直鼓勵筆者將其內容正式出版。雖然擔心書的內容不夠精緻,無法給同行作為參考,但最終還是下定決心重構內容。所幸,得到電子工業出版社的支持,出版本書。
寫作中,每當筆者翻閱以前的資料時,都會想起當年的一些故事。與其說這本書是寫給讀者的,不如說是寫給筆者自己及所有同筆者一樣,經歷過或正在經歷機器翻譯蓬勃發展年代的人的。希望本書可以作為一個時代的記錄,但這個時代並未結束,它還將繼續,並更加美好。
本書特色
本書全面回顧了近30年機器翻譯技術的發展歷程,並圍繞機器翻譯的建模和深度學習方法這兩個主題對機器翻譯的技術方法進行了全面介紹。在寫作中,筆者力求用樸實的語言和簡潔的實例來說明機器翻譯的基本模型,同時對相關的前端技術進行討論。其中涉及大量的實踐經驗,包括許多機器翻譯系統開發的細節。從這個角度看,本書不僅是一本理論書,還結合了機器翻譯的應用,給讀者提供了很多機器翻譯技術實踐的想法。
本書可供電腦相關專業高年級大學生及所究所學生學習之用,也可作為自然語言處理領域,特別是機器翻譯方向相關研究人員的參考資料。此外,本書各章主題明確,內容緊湊。因此,讀者可將每章作為某一專題的學習資料。
用最簡單的方式說明機器翻譯的基本思想是筆者期望達到的目標。雖然書中不可避免地使用了一些形式化的定義和演算法的抽象描述,但筆者也盡所能地透過圖例了解釋(本書共395張插圖)。本書所包含的內容較為廣泛,難免會有疏漏,望讀者海涵,並指出不當之處。
本書內容概要
本書分4個部分,共18章。章節的順序參考了機器翻譯技術發展的時間脈絡,兼顧了機器翻譯知識系統的內在邏輯。本書的主要內容包括:
第1部分:機器翻譯基礎
- 第1章 機器翻譯簡介
- 第2章 統計語言建模基礎
- 第3章 詞法分析和語法分析基礎
- 第4章 翻譯品質評價
第2部分:統計機器翻譯
- 第5章 以詞為基礎的機器翻譯建模
- 第6章 以扭曲度和繁衍率為基礎的模型
- 第7章 以子句為基礎的模型
- 第8章 以句法為基礎的模型
第3部分:神經機器翻譯
- 第9章 神經網路和神經語言建模
- 第10章 以循環神經網路為基礎的模型
- 第11章 以卷積神經網路為基礎的模型
- 第12章 以自注意力為基礎的模型
第4部分:機器翻譯前端
- 第13章 神經機器翻譯模型訓練
- 第14章 神經機器翻譯模型推斷
- 第15章 神經機器翻譯模型結構最佳化
- 第16章 低資源神經機器翻譯
- 第17章 多模態、多層次機器翻譯
- 第18章 機器翻譯應用技術
第1部分是本書的基礎知識部分,包含統計語言建模、詞法分析和語法分析基礎、翻譯品質評價等。在第1章對機器翻譯的歷史及現狀介紹之後,第2章透過語言建模任務將統計建模的思想說明出來,這部分內容是機器翻譯模型及方法的基礎。第3章重點介紹了機器翻譯涉及的詞法分析和語法分析方法,旨在為後續相關概念的使用做鋪陳,並展示了統計建模思想在相關問題上的應用。第4章相對獨立,系統地介紹了機器翻譯結果的評價方法。第1部分內容是機器翻譯建模及系統設計所需的前置知識。
第2部分主要介紹統計機器翻譯的基本模型。第5章是整個機器翻譯建模的基礎。第6章對扭曲度和繁衍率兩個概念介紹,同時列出相關的翻譯模型,這些模型在後續章節中都有涉及。第7章和第8章分別介紹了以子句和句法為基礎的模型。它們都是統計機器翻譯的經典模型,其思想也組成了機器翻譯成長過程中最精華的部分。
第3部分主要介紹神經機器翻譯模型,該模型是近年機器翻譯的熱點。第9章介紹了類神經網路和深度學習的基礎知識,以保證本書知識系統的完備性。同時,介紹了以神經網路為基礎的語言模型,其建模思想在神經機器翻譯中被大量使用。第10~12章分別對3種經典的神經機器翻譯模型介紹,以模型提出的時間為序,從最初的以迴圈網路為基礎的模型,到Transformer模型均有涉及。其中,也會對編碼器-解碼器框架、注意力機制等經典方法和技術介紹。
第4部分對機器翻譯的前端技術進行了討論,以神經機器翻譯為主。第13~15章介紹了神經機器翻譯研發的3個主要方面,它們也是近年機器翻譯領域討論最多的方向。第16~17章介紹了機器翻譯領域的熱門方向,包括無監督翻譯等主題。同時,對語音、圖型翻譯等多模態方法及篇章級翻譯等方法介紹,它們可以被看作機器翻譯在更多工上的擴充。第18章結合筆者在各種機器翻譯比賽和機器翻譯產品研發中的經驗,對機器翻譯的應用技術進行討論。
致謝
在此,感謝為本書做出貢獻的人: 曹潤柘、曾信、孟霞、單韋喬、周濤、周書含、許諾、李北、許晨、林野、李垠橋、王子揚、劉輝、張裕浩、馮凱、羅應峰、魏冰浩、王屹超、李炎洋、胡馳、薑雨帆、田豐甯、劉繼強、張哲暘、陳賀軒、牛蕊、杜權、張春良、王會珍、張俐、馬安香、胡明涵。
特別感謝為本書提供技術指導的姚天順教授和王寶庫教授。 |