










描述
內容簡介
| ● 打不過AI就加入他!建立自己的GPT產品
● 手刻ChatGPT從NLP基礎開始 ● PyTorch親手打造RNN、LSTM、GRU、BERT、GPT ● Attention、Transformer詳解 ● 用GPT做出自動詩詞創作平台
全書分為4篇:「自然語言處理基礎篇」「PyTorch入門篇」「用PyTorch完成自然語言處理任務篇」和「實戰篇」。 第1篇包含自然語言處理的背景知識、常用的開放資源、架設Python環境以及使用Python完成自然語言處理的基礎任務。 第2篇包含PyTorch環境設定和PyTorch的基本使用,以及機器學習的一些基本原理和工作方法。 第3篇介紹如何使用PyTorch完成自然語言處理任務,各介紹一種模型,包括分詞(又稱斷詞)、RNN、詞嵌入、Seq2seq、注意力機制、Transformer、預訓練語言模型。 第4篇是實戰篇,第分別講解自然語言理解的任務和自然語言生成的任務,即「中文地址解析」和「詩句補充」。這兩個任務綜合了前面各章的知識,並展示了從資料下載、處理、模型到使用者互動介面開發的全部流程。 從入門到專案實戰,打下你在NLP這一門最紅技術上的紮實基礎。
☘ 目標讀者 ■ 有一定程式設計基礎的電腦同好。 ■ 希望學習機器學習和自然語言處理的人。 ■ 電腦及其相關專業的學生。 ■ 對自然語言處理領域感興趣的研究者。 ■ 對自然語言處理感興趣並樂於實踐的人。
|
作者
| 孫小文 畢業於北京郵電大學計算機學院(國家示範性軟件學院),目前就職於微軟(中國),研究領域包括自然語言處理、分佈式存儲和計算、搜索技術。王薪宇 畢業於北京郵電大學計算機學院(國家示範性軟件學院),曾在知名互聯網公司工作,主要研究領域為自然語言處理。 楊談 |
目錄
| 第1篇 自然語言處理基礎篇
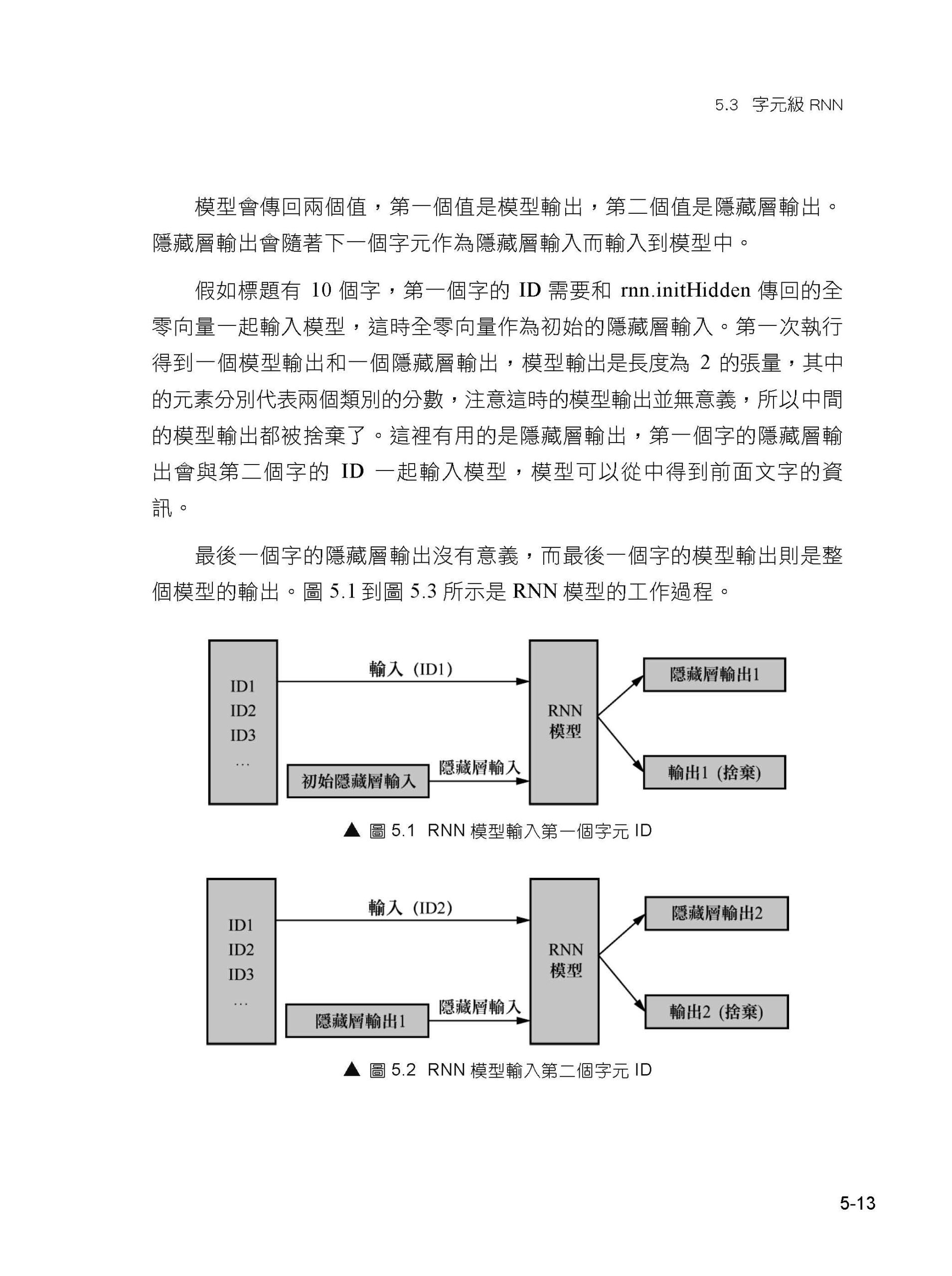
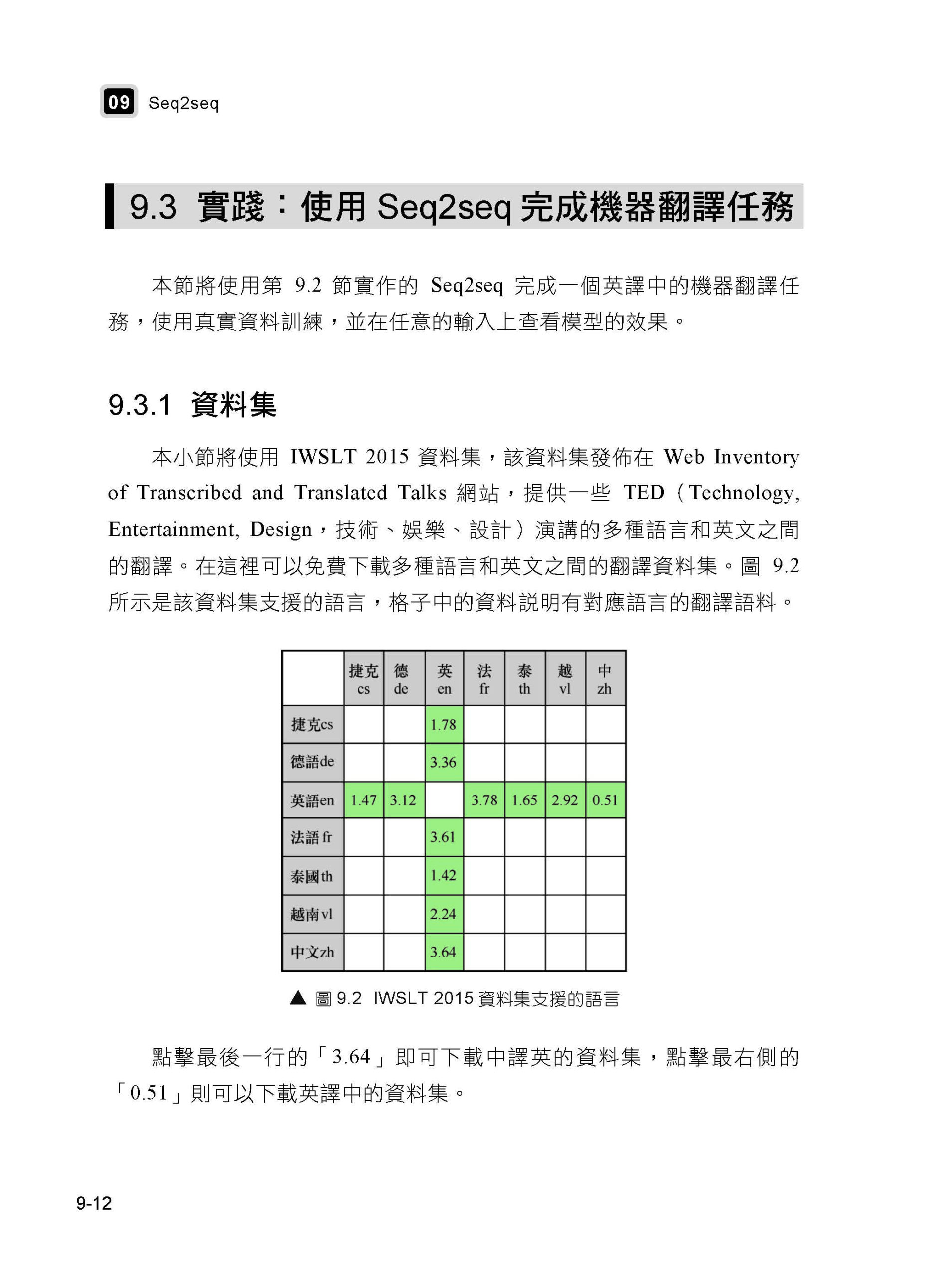
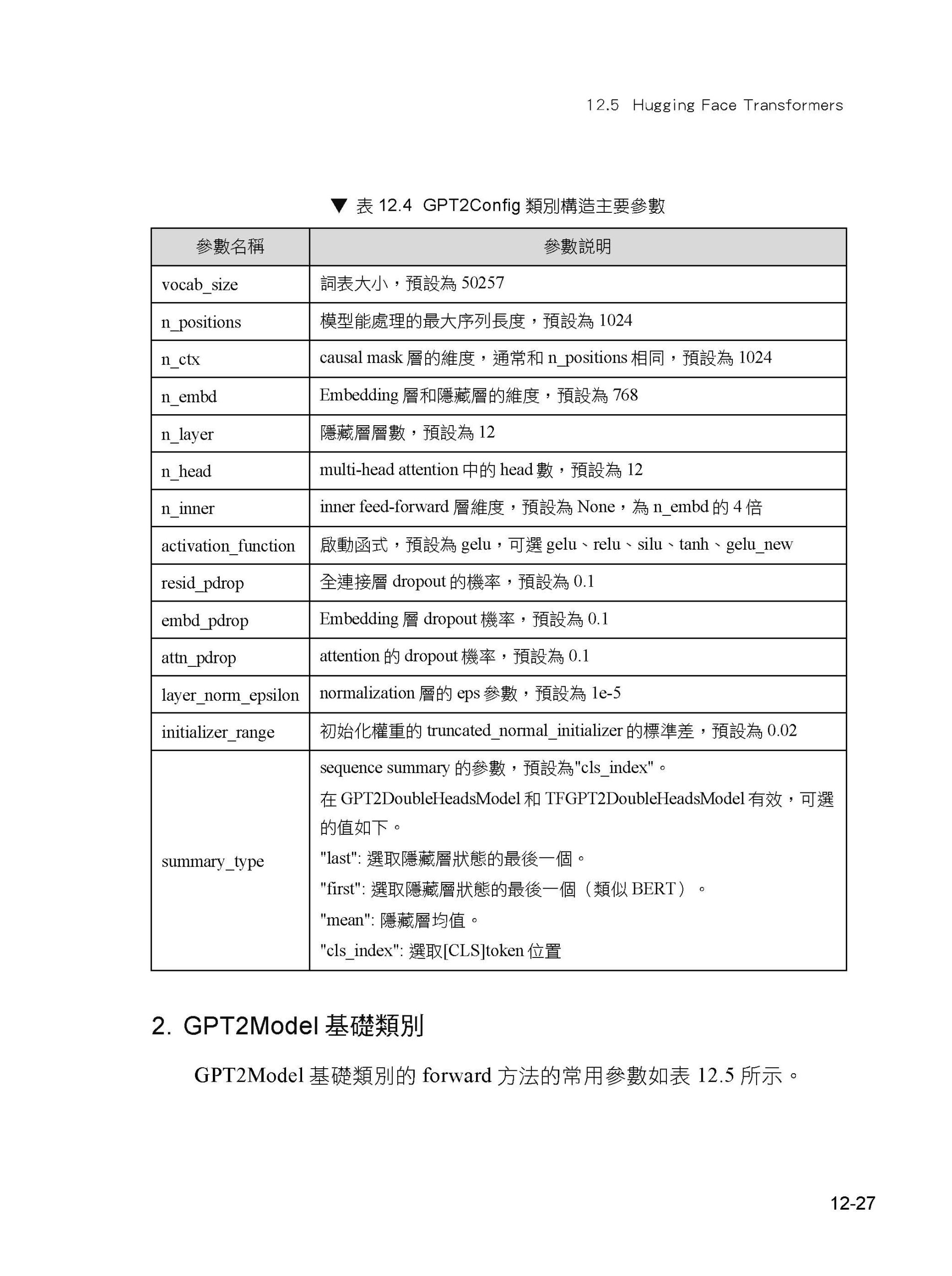
第1章 自然語言處理概述 1.1 什麼是自然語言處理 1.2 自然語言處理中的挑戰 1.3 自然語言處理中的常用技術 1.4 機器學習中的常見問題 1.5 小結 第2章 Python自然語言處理基礎 2.1 架設環境 2.2 用Python處理字串 2.3 用Python處理語料 2.4 Python的一些特性 2.5 在Python中呼叫其他語言 2.6 小結 第2篇 PyTorch入門篇 第3章 PyTorch介紹 3.1 概述 3.2 與其他框架的比較 3.3 PyTorch環境設定 3.4 Transformers簡介及安裝 3.5 Apex簡介及安裝 3.6 小結 第4章 PyTorch基本使用方法 4.1 張量的使用 4.2 使用torch.nn 4.3 啟動函式 4.4 損失函式 4.5 最佳化器 4.6 資料載入 4.7 使用PyTorch實作邏輯回歸 4.8 TorchText 4.9 使用TensorBoard 4.10 小結 5.1 資料與目標 5.2 輸入與輸出 5.3 字元級RNN 5.4 資料前置處理 5.5 訓練與評估 5.6 儲存和載入模型 5.7 開發應用 5.8 小結 第3篇 用PyTorch完成自然語言處理任務篇 第6章 分詞問題 6.1 中文分詞 6.2 分詞原理 6.3 使用協力廠商工具分詞 6.4 實踐 6.5 小結 第 7 章 RNN 7.1 RNN的原理 7.2 PyTorch中的RNN 7.3 RNN可以完成的任務 7.4 實踐:使用PyTorch附帶的RNN完成發文分類 7.5 小結 第8章 詞嵌入 8.1 概述 8.2 Word2vec 8.3 GloVe 8.4 實踐:使用預訓練詞向量完成發文標題分類 8.5 小結 第9章 Seq2seq 9.1 概述 9.2 使用PyTorch實作Seq2seq 9.3 實踐:使用Seq2seq完成機器翻譯任務 9.4 小結 第10章 注意力機制 10.1 注意力機制的起源 10.2 使用注意力機制的視覺循環模型 10.3 Seq2seq中的注意力機制 10.4 自注意力機制 10.5 其他注意力機制 10.6 小結 第11章 Transformer 11.1 Transformer的背景 11.2 以卷積網路為基礎的Seq2seq 11.3 Transformer的結構 11.4 Transformer的改進 11.5 小結 第12章 預訓練語言模型 12.1 概述 12.2 ELMo 12.3 GPT 12.4 BERT 12.5 Hugging Face Transformers 12.6 其他開放原始碼中文預訓練模型 12.7 實踐:使用Hugging Face Transformers中的BERT做發文標題分類 12.8 小結 第4篇 實戰篇 第13章 專案:中文地址解析 13.1 資料集 13.2 詞向量 13.3 BERT 13.4 HTML5演示程式開發 13.5 小結 第14章 專案:詩句補充 14.1 了解chinese-poetry資料集 14.2 準備訓練資料 14.3 實作基本的LSTM 14.4 根據句子長度分組 14.5 使用預訓練詞向量初始化 Embedding層 14.6 使用Transformer完成詩句生成 14.7 使用GPT-2完成對詩模型 14.8 開發HTML5演示程式 14.9 小結
參考文獻 |
序
| 自然語言處理是目前人工智慧領域中最受人矚目的研究方向之一,發展非常迅速。自然語言處理又是一個非常開放的領域,每年都有大量的可以免費閱讀的論文、可以自由下載和使用的開原始程式碼被發佈在網際網路上。感謝這些致力於自然語言處理研究,又樂於分享的研究者和開發者,使我們有機會學習這一領域最新的研究成果,理解自然語言處理領域中的精妙原理,並能夠在開原始程式碼函式庫的基礎上建立一些美妙的應用。
如果沒有他們的努力和奉獻,無法想像我們僅僅透過兩行程式 ,就能在幾秒內定義和建立一個包含超過1億參數的模型,並下載和載入預訓練參數(耗時數分鐘,具體時間根據網速而定)。這些預訓練參數往往是使用性能強大的圖形處理單元(Graphics Processing Unit, GPU)在巨量的資料中訓練數天才能得到的。 即使擁有性能強大的GPU,要獲取巨量訓練資料,或者進行長時間的訓練也都是困難的,但是借助公開發佈的預訓練權重,僅僅需要兩行程式就都可以做到。同時還可以在能接受的時間內對模型進行Fine-tuning(微調)訓練,載入與訓練參數後,再使用目標場景的資料訓練,使模型更符合實際的應用場景。 如果你沒有 GPU,或者只有一台性能一般的家用電腦,也完全可以比較快速地使用模型去完成一些通用的任務,或者在一定的資料中訓練一些不太複雜的模型。 自然語言處理越來越豐富的應用正在改變我們的生活。從語音合成、語音辨識、機器翻譯,到視覺文字聯合,越來越精確的自然語言理解讓更多事情成為可能。現在的人工智慧技術使電腦可以用越來越接近人類的方式去處理和使用自然語言。 更令人興奮的是,這些事情我們也可以借助開原始程式碼去實作,並根據大量公開的論文、文件和範例程式去理解程式背後的原理。
|