








描述
內容簡介
| 【新書簡介】
本書共分四部分,第一部分詳細介紹大型語言模型的基礎理論知識,包括語言模型的定義、Transformer 結構,以及大型語言模型框架等內容,並以 LLaMA 所採用的模型結構為例的程式碼。 第二部分主要介紹預訓練的相關內容,包括在模型分散式訓練中需要掌握的資料平行、流水線並行和模型平行等技術也介紹了ZeRO 最佳化,介紹預訓練資料分佈和資料預處理,以DeepSpeed 為例,介紹大型語言模型的預訓練。 第三部分為大型語言模型在指令理解,如何在基礎模型的基礎上利用有監督微調和強化學習方法,理解指令並給出回答,包括高效微調方法、有監督微調資料構造方法、強化學習基礎和近端策略優化方法,並以 DeepSpeed-Chat和 MOSS-RLHF 為例訓練類 ChatGPT 系統。 第四部分重點介紹了大型語言模型的擴充應用和評估。包括與外部工具和知識源連接的LangChain 技術。
【本書看點】 ●LLM基礎,包括GPT、Transformer、LLAMA ●常用的模型倉庫Huggingface的介紹 ●LLM的預訓練資料的介紹及整理 ●多GPU分散式訓練的基礎及實作 ●SFT有監督微調的應用實例及基礎,包括LORA、PEFT ●強化學習在LLM中的應用,包括獎勵模型及PPO ●LLM的應用,包括COT及LLM瑞士刀LangChain ●用科學方式來評估LLM的能力 |
作者簡介
|
目錄
| 第 1 章 緒論
1.1 大型語言模型的基本概念 1.2 大型語言模型的發展歷程 1.3 大型語言模型的建構流程 1.4 本書的內容安排
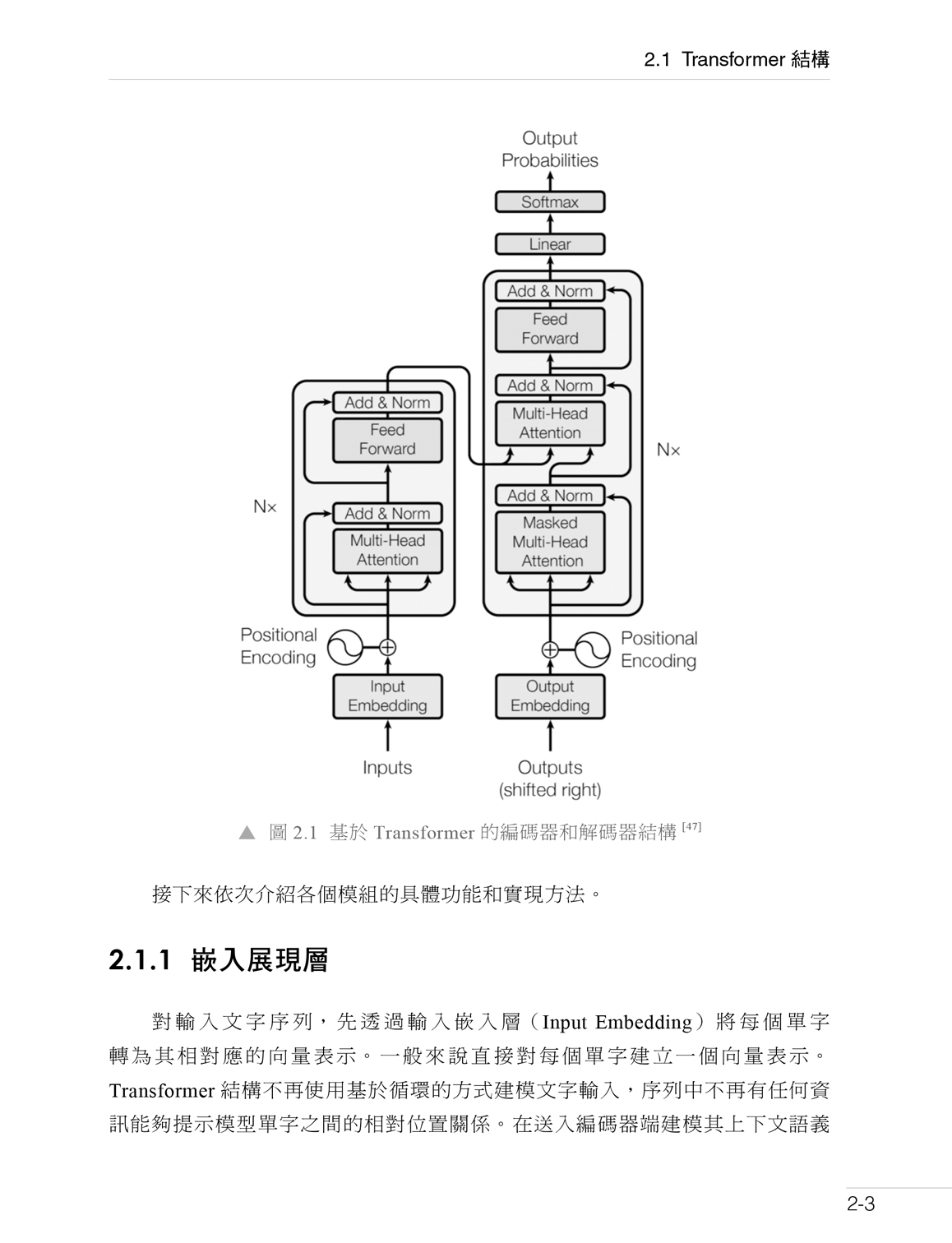
第 2 章 大型語言模型基礎 2.1 Transformer 結構 2.2 生成式預訓練語言模型 GPT 2.3 大型語言模型的結構 2.4 實踐思考
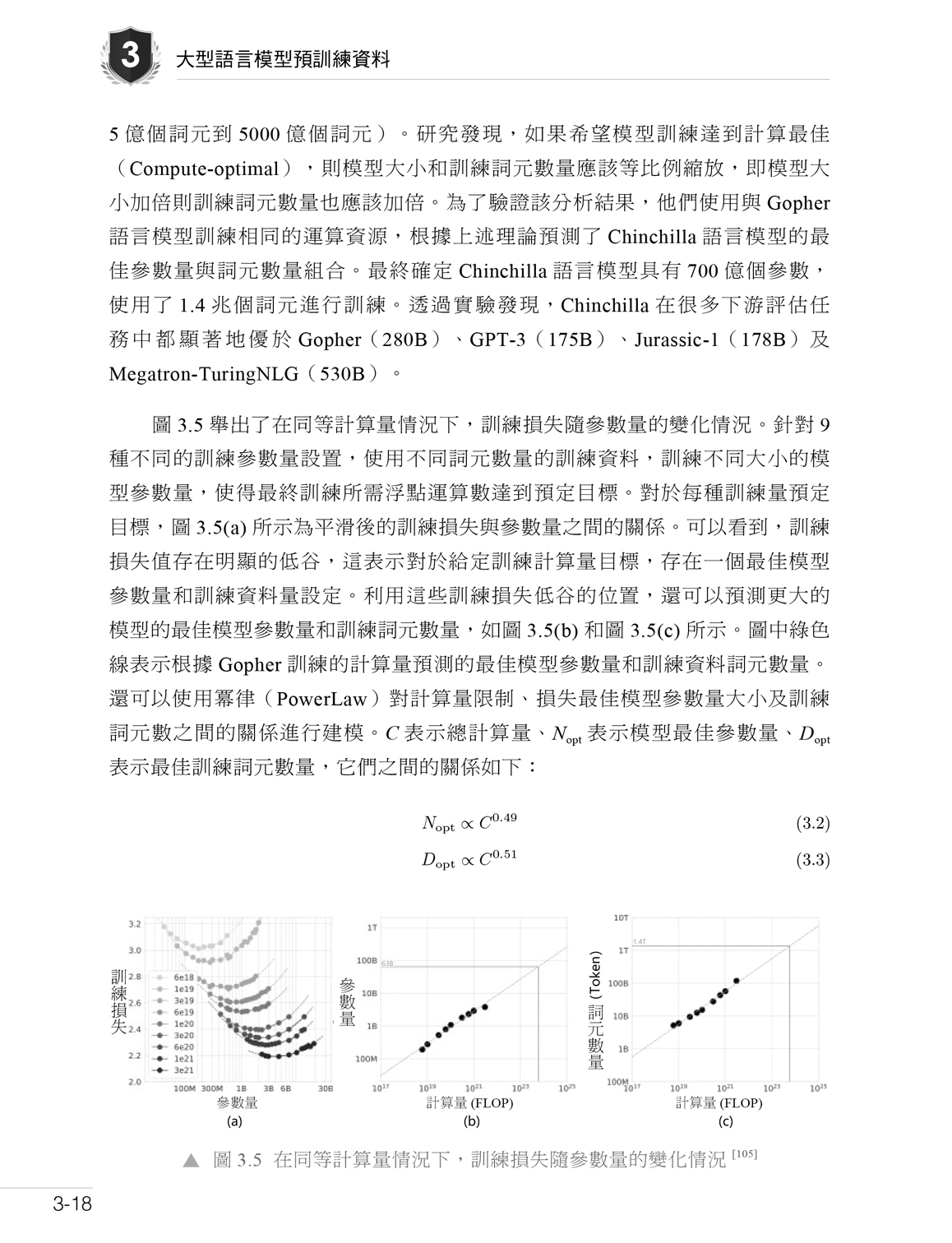
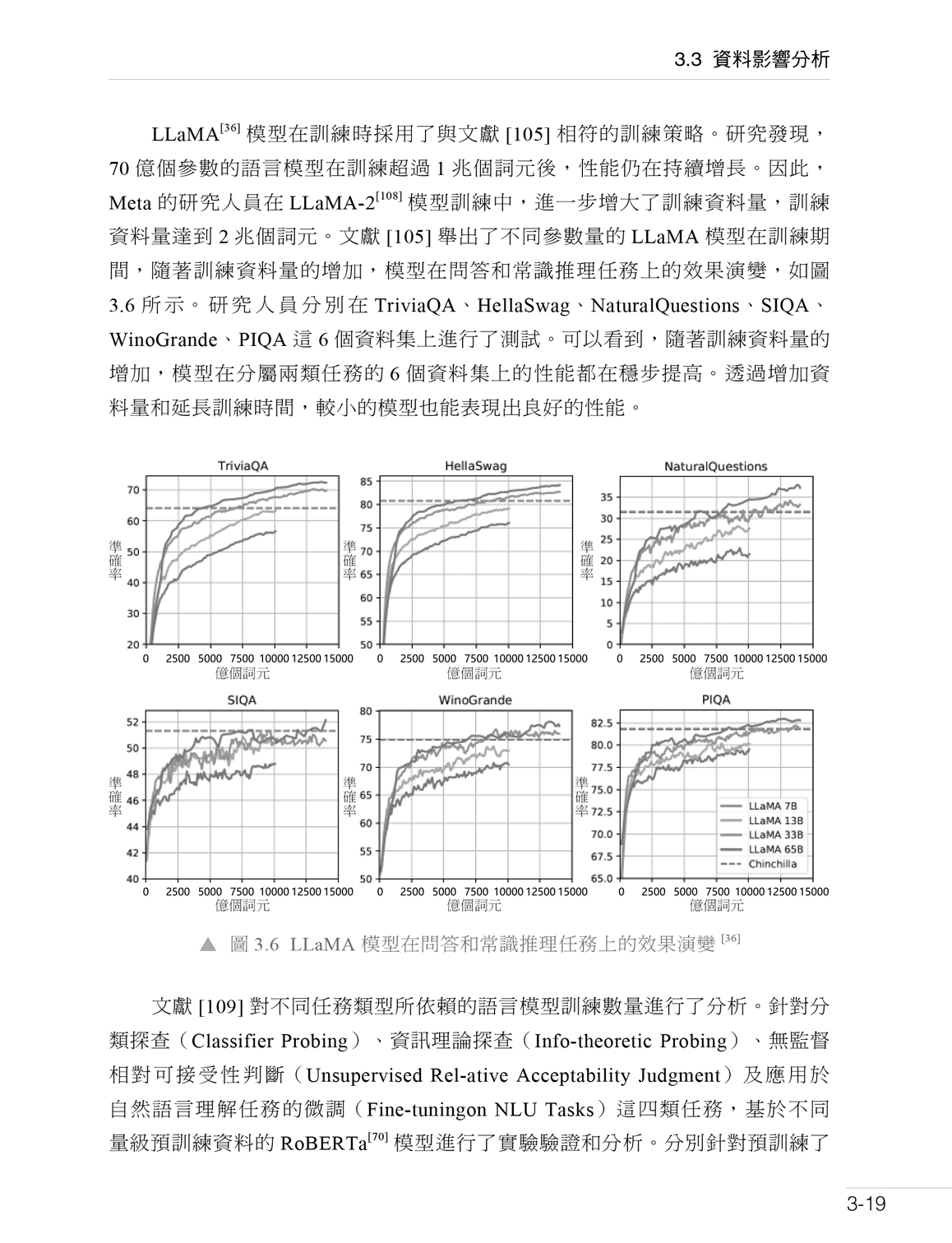
第 3 章 大型語言模型預訓練資料 3.1 資料來源 3.2 資料處理 3.3 資料影響分析 3.4 開放原始碼資料集 3.5 實踐思考
第 4 章 分散式訓練 4.1 分散式訓練概述 4.2 分散式訓練的平行策略 4.3 分散式訓練的叢集架構 4.4 DeepSpeed 實踐 4.5 實踐思考
第 5 章 有監督微調 5.1 提示學習和語境學習 5.2 高效模型微調 5.3 模型上下文視窗擴展 5.4 指令資料的建構 5.5 DeepSpeed-Chat SFT 實踐 5.6 實踐思考
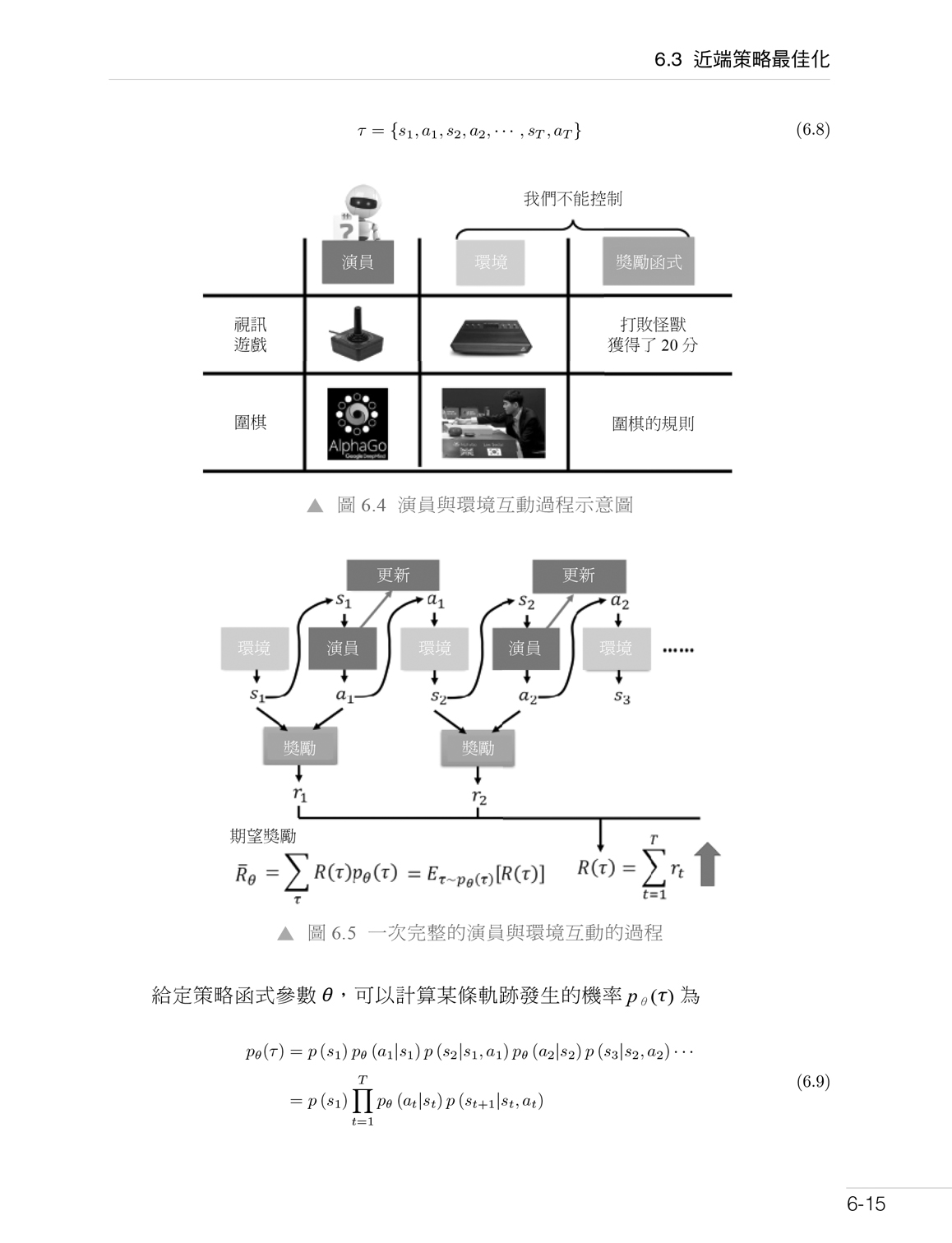
第 6 章 強化學習 6.1 基於人類回饋的強化學習 6.2 獎勵模型 6.3 近端策略最佳化 6.4 MOSS-RLHF 實踐 6.5 實踐思考
第 7 章 大型語言模型應用 7.1 推理規劃 7.2 綜合應用框架 7.3 智慧代理 7.4 多模態大模型 7.5 大型語言模型推理最佳化 7.6 實踐思考
第 8 章 大型語言模型評估 8.1 模型評估概述 8.2 大型語言模型評估系統 8.3 大型語言模型評估方法 8.4 大型語言模型評估實踐 8.5 實踐思考
參考文獻 索引 |
序
| 緣起
2018 年,Google 的研究團隊創新地提出了預訓練語言模型 BERT[1] ,該模型在諸多自然語言處理任務中展現出卓越的性能。這激發了大量以預訓練語言模型為基礎的自然語言處理研究,也引領了自然語言處理領域的預訓練範式。雖然這一變革影響深遠,但它並沒有改變每個模型只能解決特定問題的基本模式。2020 年,OpenAI 發佈了 GPT-3 模型,其在文字生成任務上的能力令人印象深刻,並在許多少標注的自然語言處理任務上獲得了優秀的成績。但是,其性能並未超越針對單一任務訓練的有監督模型。之後,研究人員陸續提出了針對大規模語言模型〔(Large Language Model,LLM),也稱大語言模型或大型語言模型〕的提示詞學習方法,並在各種自然語言處理任務中進行了試驗,同時提出了模型即服務範式的概念。在大多數情況下,這些方法的性能並未明顯地超過基於預訓練微調範式的模型。因此,這些方法的影響力主要侷限在自然語言處理的研究人員群眾中。 2022 年 11 月,ChatGPT 的問世展示了大型語言模型的強大潛能,並迅速引起了廣泛關注。 ChatGPT 能夠有效地理解使用者需求,並根據上下文提供恰當的回答。它不僅可以進行日常對話,還能夠完成複雜任務,如撰寫文章、回答問題等——令人驚訝的是,所有這些任務都由一個模型完成。在許多工上,ChatGPT 的性能甚至超過了針對單一任務進行訓練的有監督演算法。這對人工智慧領域有重大意義,並對自然語言處理研究產生了深遠影響。OpenAI 並未公開 ChatGPT 的詳細實現細節,整體訓練過程包括語言模型、有監督微調、類人對齊等多個方面,這些方面之間還會有大量的連結,這對研究人員的自然語言處理和機器學習基礎理論水準要求很高。此外,大型語言模型的參數量龐大,與傳統的自然語言處理研究范式完全不同。使用大型語言模型還需要分散式平行計算的支援,這對自然語言處理演算法研究人員提出了更高的要求。為了使更多的自然語言處理研究人員和對大型語言模型感興趣的讀者能夠快速了解大型語言模型的理論基礎,並開展大型語言模型實踐,筆者結合在自然語言處理領域的研究經驗,以及分散式系統和平行計算的教學經驗,在大型語言模型實踐和理論研究的過程中,歷時 8 個月完成本書。希望這本書能夠幫助讀者快速入門大型語言模型的研究和應用,並解決相關技術問題。 自然語言處理的研究歷史可以追溯到 1947 年,第一台通用電腦 ENIAC 問世。自然語言處理經歷了 20 世紀 50 年代末到 20 世紀 60 年代初的初創期,20 世紀 70 年代到 20 世紀 80 年代的理性主義時代,20 世紀 90 年代到 21 世紀初的經驗主義時代,以及 2006 年至今的深度學習時代。自 2017 年 Transformer 結構[2] 提出並在機器翻譯領域取得巨大成功,自然語言處理進入了爆發式的發展階段。2018 年,動態詞向量 ELMo[3] 模型開啟了語言模型預訓練的先河。隨後,以 GPT[4] 和 BERT[1] 為代表的基於 Transformer 結構的大規模預訓練語言模型相繼被提出,自然語言處理進入了預訓練微調的新時代。2019 年,OpenAI 發佈了擁有 15 億個參數的 GPT-2 模型[4] ; 2020 年,Google 發佈了擁有 110 億個參數的 T5 模型。同年,OpenAI 發佈了擁有 1750 億個參數的 GPT-3 模型[5] ,開啟了大型語言模型的時代。2022 年 11 月,ChatGPT 的問世將大型語言模型的研究推向了新的高度,引發了大型語言模型研究的熱潮。儘管大型語言模型的發展歷程只有不到 5 年時間,但其發展速度相當驚人。截至 2023 年 6 月,全球已經發佈了超過百種大型語言模型。 大型語言模型的研究融合了自然語言處理、機器學習、分散式運算、平行計算等多個學科領域,其發展歷程可以分為基礎模型階段、能力探索階段和突破發展階段。基礎模型階段主要集中在2018年至 2021 年,期間發佈了一系列具有代表性的大型語言模型,如 BERT、GPT、ERNIE、PaLM 等。這些模型的發佈為大型語言模型的研究打下了基礎。能力探索階段主要集中在 2019 年至 2022 年。由於大型語言模型在針對特定任務的微調方面存在一定困難,研究人員開始探索如何在不進行單一任務微調的情況下發揮大型語言模型的能力。同時,研究人員還嘗試用指令微調方案,將各種類型的任務統一為生成式自然語言理解框架,並使用建構的訓練資料對模型進行微調。突破發展階段以 2022 年 11 月 ChatGPT 的發佈為起點。ChatGPT 透過一個簡單的對話方塊,利用一個大型語言模型就能夠實現問題回答、文稿撰寫、程式生成、數學解題等多種任務,而以往的自然語言處理系統需要使用多個小模型進行訂製開發才能分別實現這些能力。ChatGPT在開放領域問答、各類生成式自然語言任務及對話理解等方面展現出的能力遠超大多數人的想像。這幾個階段的發展推動了大型語言模型的突破,為自然語言處理研究帶來了巨大的進展,並在各個領域展示了令人矚目的成果。
本書主要內容 本書圍繞大型語言模型建構的四個主要階段——預訓練、有監督微調、獎勵建模和強化學習展開,詳細介紹各階段使用的演算法、資料、困難及實踐經驗。預訓練階段需要利用包含數千億甚至數兆單字的訓練資料,並借助由數千顆性能 GPU 和高速網路組成的超級電腦,花費數十天完成深度神經網路參數的訓練。這一階段的困難在於如何建構訓練資料,以及如何高效率地進行分散式訓練。有監督微調階段利用少量高品質的資料集,其中包含使用者輸入的提示詞和對應的理想輸出結果。提示詞可以是問題、閒聊對話、任務指令等多種形式和任務。這個階段是從語言模型向對話模型轉變的關鍵,其核心困難在於如何建構訓練資料,包括訓練資料內部多個任務之間的關係、訓練資料與預訓練之間的關係及訓練資料的規模。獎勵建模階段的目標是建構一個文字品質對比模型,用於對有監督微調模型對於同一個提示詞舉出的多個不同輸出結果進行品質排序。這一階段的困難在於如何限定獎勵模型的應用範圍及如何建構訓練資料。強化學習階段,根據數十萬提示詞,利用前一階段訓練的獎勵模型,對有監督微調模型對使用者提示詞補全結果的品質進行評估,與語言模型建模目標綜合得到更好的效果。這一階段的困難在於解決強化學習方法穩定性不高、超參數許多及模型收斂困難等問題。除了大型語言模型的建構,本書還介紹了大型語言模型的應用和評估方法,主要內容包括如何將大型語言模型與外部工具和知識源進行連接,如何利用大型語言模型進行自動規劃以完成複雜任務,以及針對大型語言模型的各類評估方法。 本書旨在為對大型語言模型感興趣的讀者提供入門指南,並可作為高年級大學生和所究所學生自然語言處理相關課程的大型語言模型部分的補充教材。鑑於大型語言模型的研究仍在快速發展階段,許多方面尚未得出完整結論或達成共識,在撰寫本書時,筆者力求全面展現大型語言模型研究的各個方面,並避免舉出沒有廣泛共識的觀點和結論。大型語言模型涉及深度學習、自然語言處理、分散式運算、平行計算等許多領域。因此,建議讀者在閱讀本書之前,系統地學習深度學習和自然語言處理的相關課程。閱讀本書也需要讀者了解分散式運算和異質計算方面的基本概念。如果讀者希望在大型語言模型訓練和推理方面進行深入研究,還需要系統學習分散式系統、平行計算、CUDA程式設計等相關知識。
致謝 本書的寫作過程獲得了許多專家和同學的大力支援和幫助。特別感謝陳璐、陳天澤、陳文翔、竇士涵、葛啟明、郭昕、賴文斌、柳世純、汪冰海、奚志恒、許諾、張明、周鈺皓等同學(按照姓氏拼音排序)為本書撰寫提供的幫助。 大型語言模型研究進展之快,即使是在自然語言處理領域開展了近三十年工作的筆者也難以適從。其受關注的程度令人驚歎,2022 年,自然語言處理領域重要國際會議 EMNLP 中語言模型相關論文投稿佔比只有不到 5%。然而,2023 年,語言模型相關投稿量超過 EMNLP 整體投稿量的 20%。如何能既兼顧大型語言模型的基礎理論,又在快速發展的各種研究中選擇最具有代表性的工作介紹給讀者,是本書寫作過程中面臨的最大挑戰。雖然本書寫作時間只有 8 個月,但是章節內部結構幾易其稿,經過數次大幅度調整和重寫。即使如此,受筆者的認知水準和所從事的研究工作的侷限,對其中一些任務和工作的細節理解仍然可能存在不少錯誤,也懇請專家、讀者批評指正!
張奇 |