






描述
內容簡介
|
作者簡介
| 王文廣
高級工程師,浙江大學碩士,浦東新區「明珠計畫」菁英人才,省部級科技進步獎獲得者,人工智慧標準編制專家,浦東新區首席技師,騰訊雲最具價值專家(TVP),中國人工智慧產業發展聯盟突出貢獻個人,曾出版《知識圖譜:認知智能理論與實戰》一書,致力於推進通用人工智慧技術的研究和應用。 現為上海市人工智能技術標準化委員會委員、上海市科學技術委員會評審專家、中國計算機協會(CCF)高級會員、中國中文信息學會(CIPS)語言與知識計算專委會委員、中國人工智慧學會(CAAI)深度學習專委會委員,曾參與編制十多項人工智慧領域的標準,發表數十項(篇)人工智慧領域的國家發明專利和學術論文,並參與編寫多本人工智慧方面的圖書。 |
目錄
| ▌第1 章 緒論:迎接大模型紀元
1.1 大模型崛起 1.2 大模型的固有特性 1.2.1 幻覺 1.2.2 知識陳舊 1.3 知識增強大模型 1.4 迎接大模型紀元
▌第2 章 大語言模型 2.1 大模型概述 2.2 語言模型簡史 2.3 大模型為何如此強大 2.3.1 語言模型與無監督學習 2.3.2 人類回饋強化學習 2.3.3 情境學習與思維鏈 2.4 如何使用大模型 2.4.1 翻譯 2.4.2 文字摘要 2.4.3 求解數學問題 2.4.4 語言學習和考試 2.4.5 高效撰寫文章 2.4.6 自動化程式設計和輔助程式設計 2.4.7 資料分析 2.5 垂直大模型 2.5.1 什麼是垂直大模型 2.5.2 垂直大模型的特點 2.6 思考題 2.7 本章小結
▌第3 章 向量資料庫 3.1 向量表示與嵌入 3.1.1 語言的向量表示 3.1.2 影像的向量表示 3.1.3 知識圖譜的向量表示 3.2 向量相似度 3.2.1 L2 距離 3.2.2 餘弦相似度 3.2.3 內積相似度 3.2.4 L1 距離 3.3 向量索引與檢索方法 3.3.1 最近鄰檢索和近似最近鄰檢索 3.3.2 局部敏感雜湊演算法 3.3.3 基於圖結構的HNSW 演算法 3.3.4 向量量化與乘積量化 3.4 Milvus 向量資料庫 3.4.1 Milvus 架構 3.4.2 向量索引方法 3.4.3 向量檢索方法 3.4.4 資料一致性 3.4.5 使用者認證與許可權控制 3.5 Milvus 向量資料庫實戰指南 3.5.1 安裝、配置和運行Milvus 3.5.2 連接伺服器和建立資料庫 3.5.3 資料準備 3.5.4 建立集合 3.5.5 建立索引 3.5.6 插入資料 3.5.7 載入資料 3.5.8 純量查詢 3.5.9 單向量檢索 3.5.10 混合檢索 3.6 其他主流的向量資料庫系統與工具 3.6.1 原生向量資料庫 3.6.2 資料庫的向量處理擴充 3.6.3 向量索引和檢索函數庫 3.7 思考題 3.8 本章小結
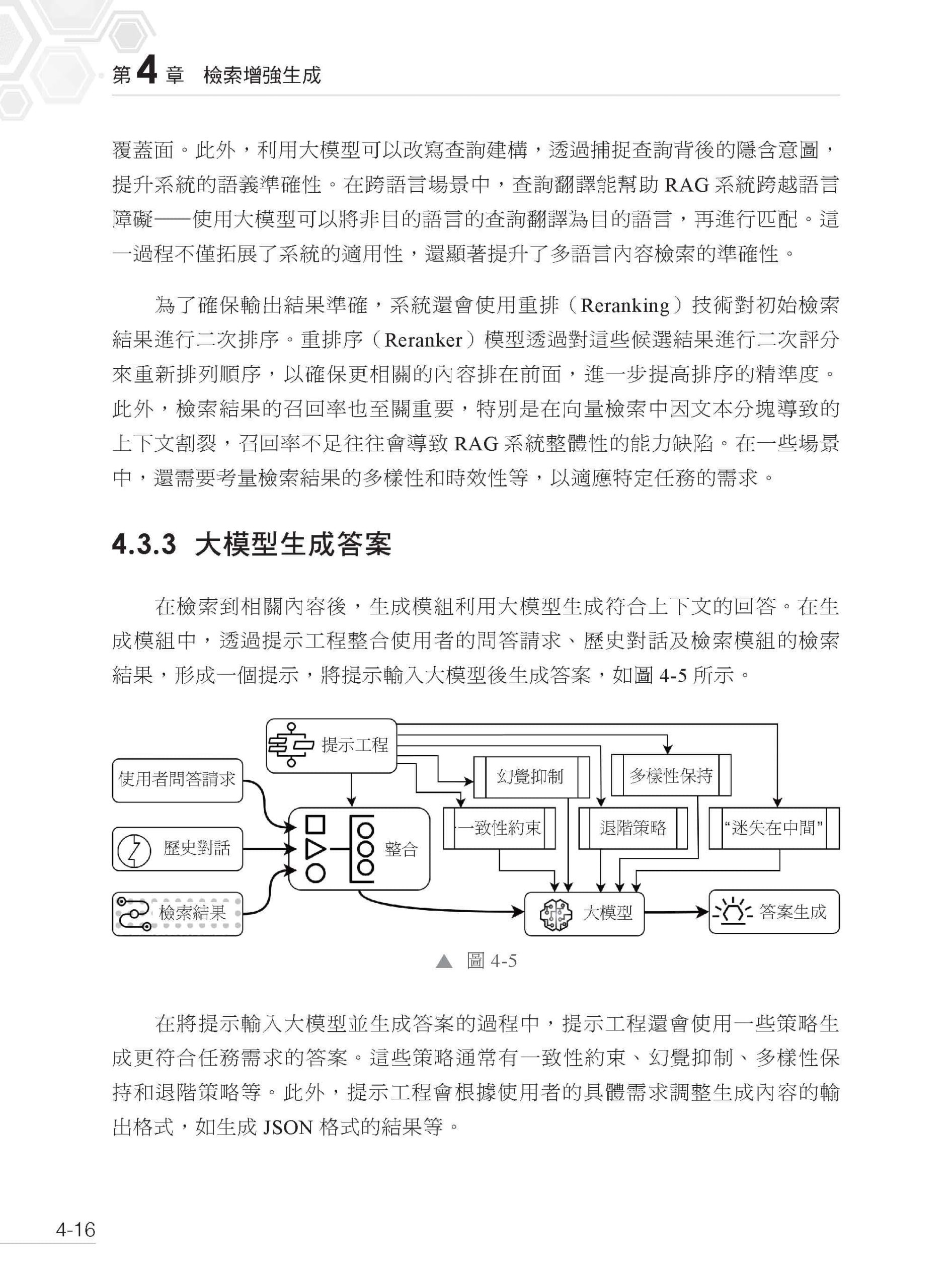
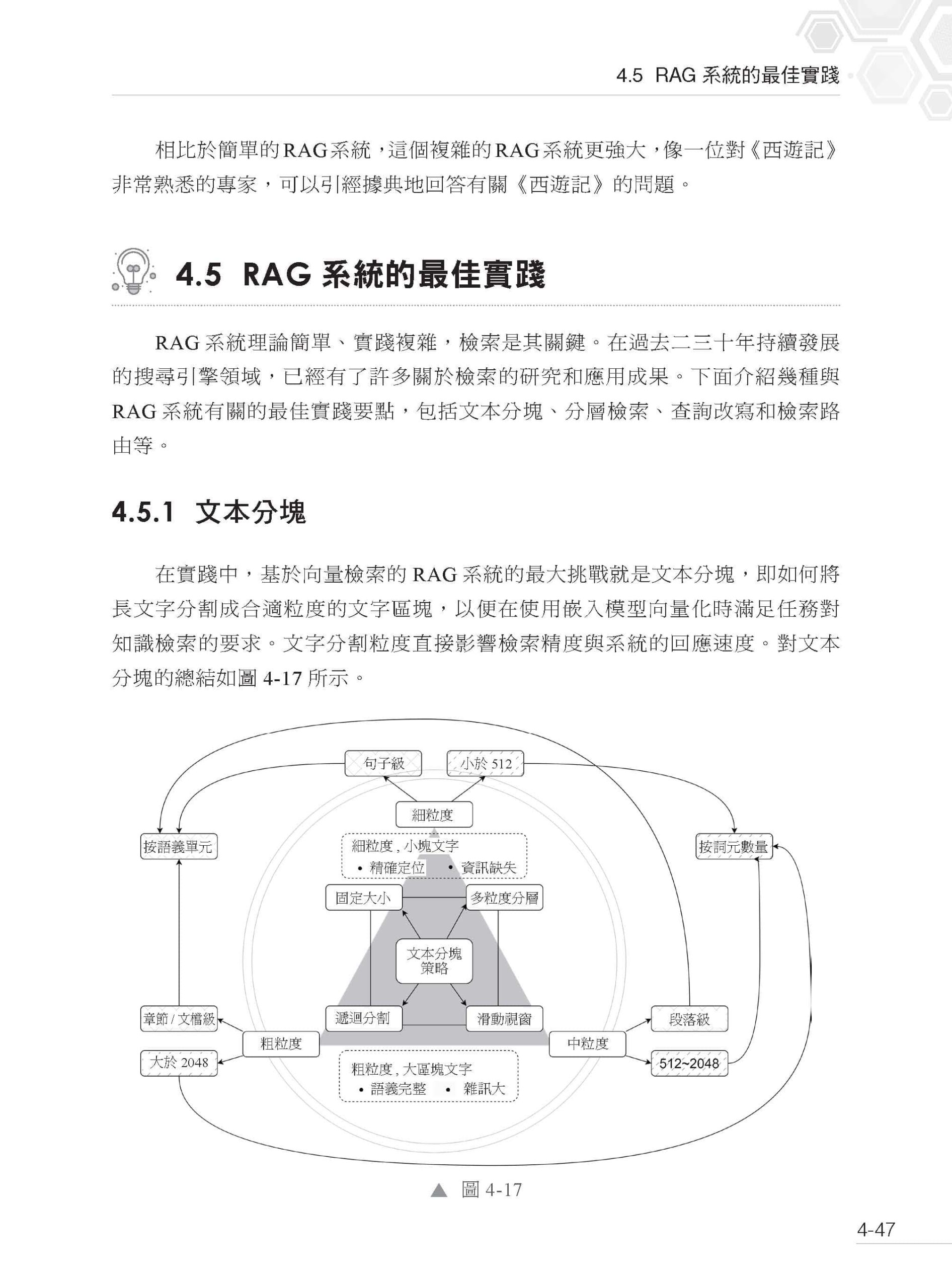
▌第4 章 檢索增強生成 4.1 檢索增強生成概述 4.2 為什麼需要RAG 4.2.1 RAG、SFT 與LoRA 4.2.2 長上下文與RAG 4.2.3 鋰電池供應鏈管理案例 4.2.4 RAG 的特點 4.3 通用的RAG 流程 4.3.1 建立知識庫 4.3.2 知識檢索 4.3.3 大模型生成答案 4.3.4 品質評估與迭代最佳化 4.4 使用Dify 建構RAG 系統 4.4.1 Dify 概述 4.4.2 安裝Dify 4.4.3 初始化Dify 4.4.4 建立知識庫 4.4.5 簡單的RAG 應用 4.4.6 RAG 效果最佳化 4.4.7 引入Elasticsearch 4.4.8 建構RAG 系統 4.5 RAG 系統的最佳實踐 4.5.1 文本分塊 4.5.2 分層檢索 4.5.3 查詢改寫 4.5.4 檢索路由 4.6 其他主流的RAG 系統框架 4.6.1 LobeChat 4.6.2 Quivr 4.6.3 LlamaIndex 4.6.4 Open WebUI 4.7 思考題 4.8 本章小結
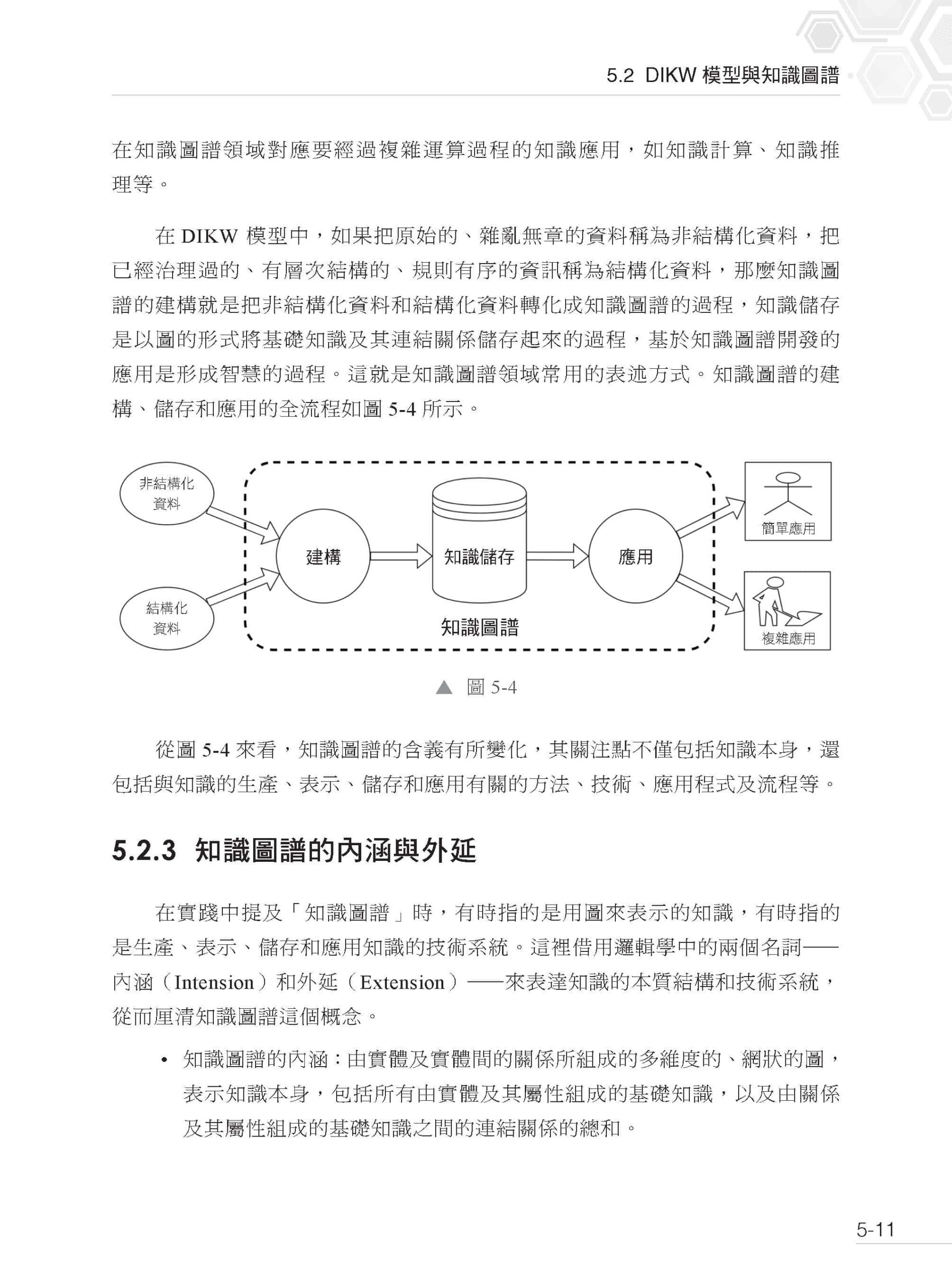
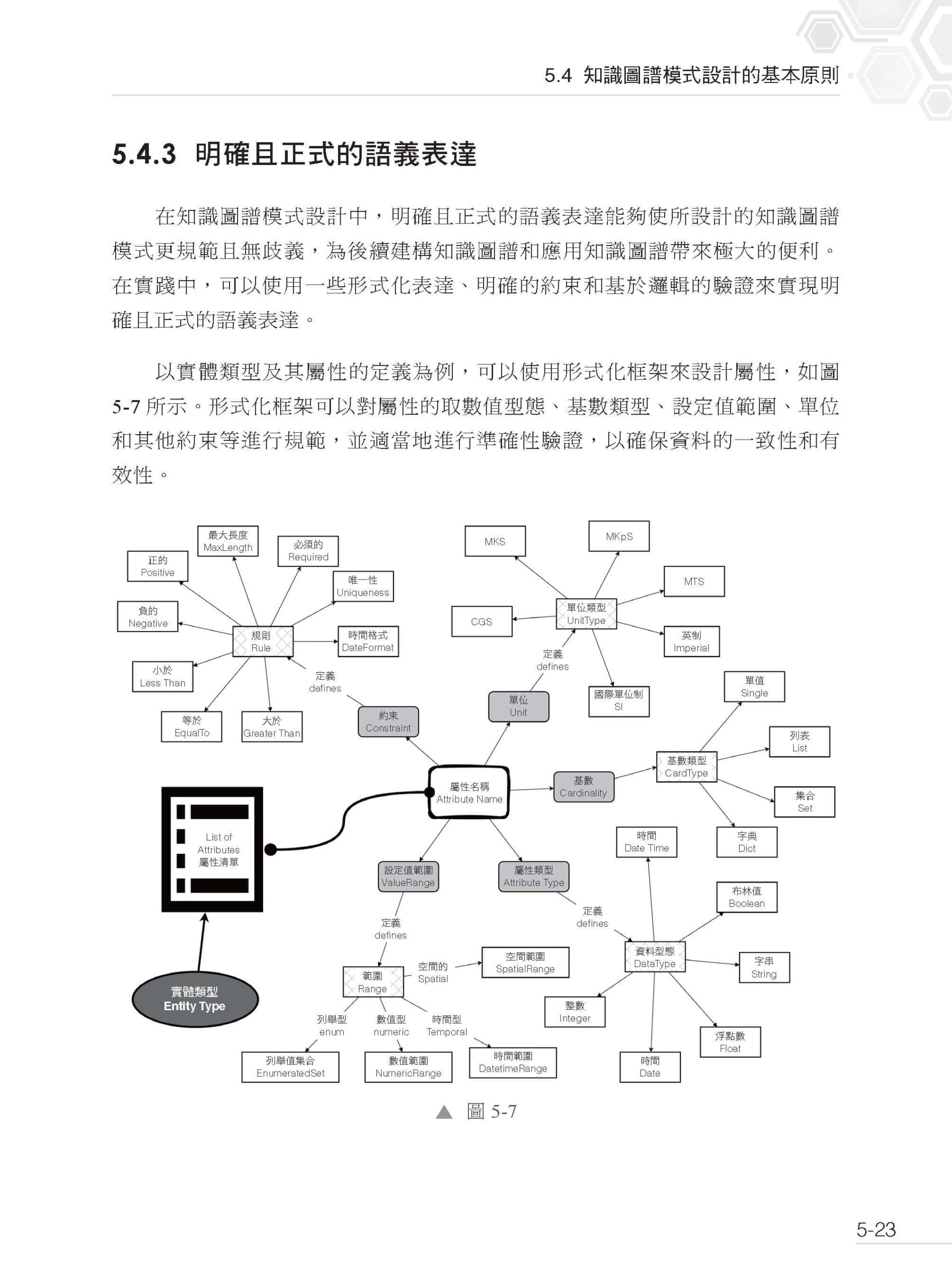
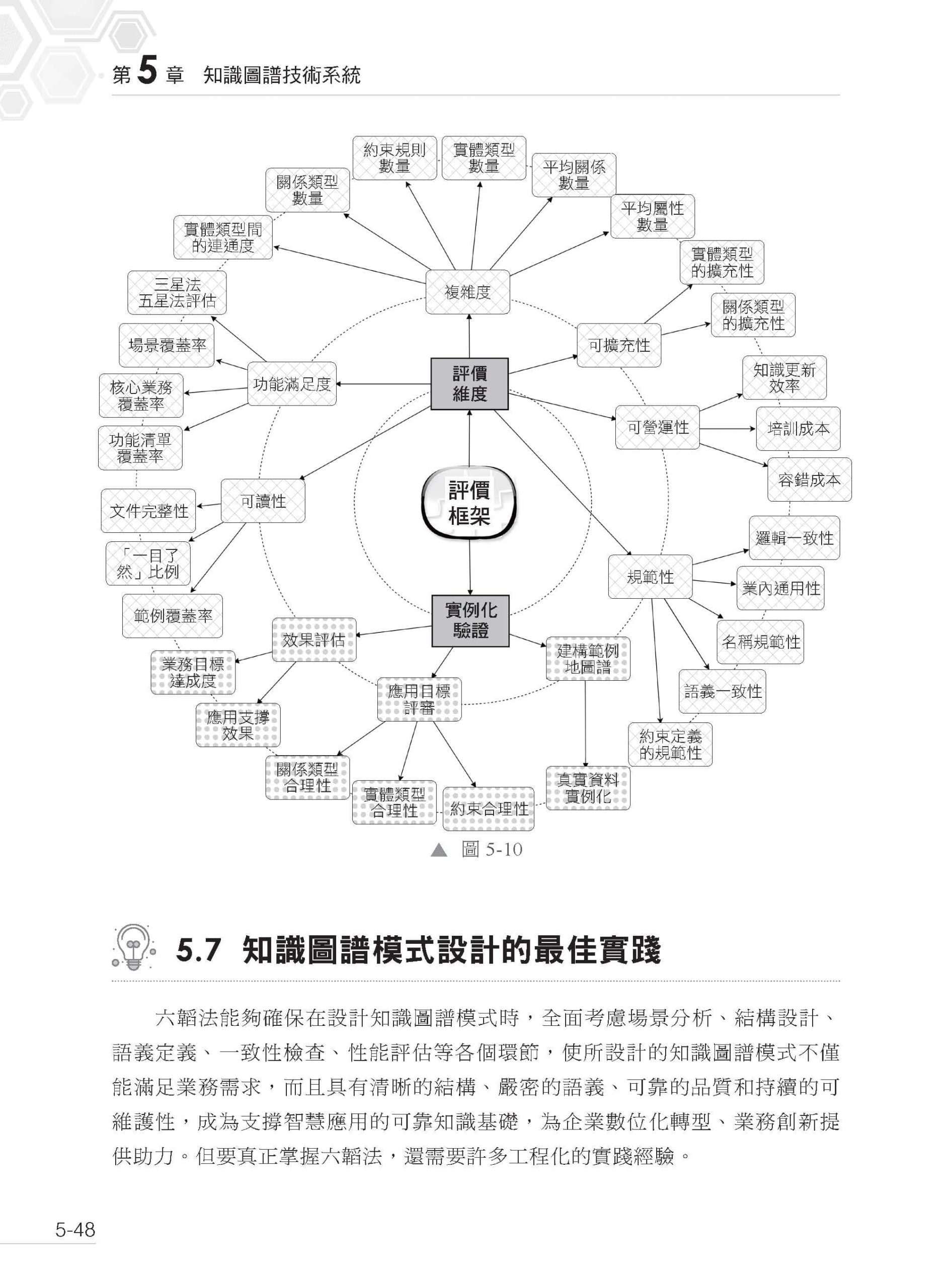
▌第5 章 知識圖譜技術系統 5.1 什麼是知識圖譜 5.1.1 知識圖譜的相關概念及其定義 5.1.2 知識圖譜實例 5.1.3 大腦的聯想機制與知識圖譜的關係建模 5.2 DIKW 模型與知識圖譜 5.2.1 DIKW 模型 5.2.2 從DIKW 模型到知識圖譜 5.2.3 知識圖譜的內涵與外延 5.2.4 知識的源流與知識圖譜 5.3 知識圖譜的技術系統 5.3.1 知識圖譜模式設計與管理 5.3.2 知識圖譜建構技術 5.3.3 知識圖譜儲存技術 5.3.4 知識圖譜應用技術 5.3.5 使用者介面與介面 5.4 知識圖譜模式設計的基本原則 5.4.1 賦予一類事物合適的名字 5.4.2 建立事物間清晰的聯繫 5.4.3 明確且正式的語義表達 5.5 知識圖譜模式設計的六韜法 5.6 大模型結合六韜法設計知識圖譜模式 5.6.1 場景:對齊參與各方的認知 5.6.2 重複使用:站在巨人的肩膀上 5.6.3 事物:定義實體類型及屬性 5.6.4 聯繫:場景需求之下的普遍聯繫 5.6.5 約束:多層次的約束規範 5.6.6 評價:迭代最佳化的起點 5.7 知識圖譜模式設計的最佳實踐 5.7.1 熟知知識圖譜及其具體應用領域 5.7.2 明確邊界,切記貪多嚼不爛 5.7.3 高內聚、低耦合 5.7.4 充分利用視覺化工具 5.8 思考題 5.9 本章小結
▌第6 章 建構知識圖譜 6.1 知識圖譜建構技術概述 6.1.1 映射式建構技術 6.1.2 取出式建構技術 6.2 取出實體和物理屬性 6.2.1 實體、物理屬性及其取出 6.2.2 用大模型取出實體和物理屬性 6.3 取出關係和關係屬性 6.3.1 實體間的關係和關係取出 6.3.2 用大模型取出關係和關係屬性 6.4 取出事件 6.4.1 事件、事件要素和事件取出 6.4.2 用大模型取出事件 6.5 多語言和跨語言 6.6 知識取出的評價指標 6.7 思考題 6.8 本章小結
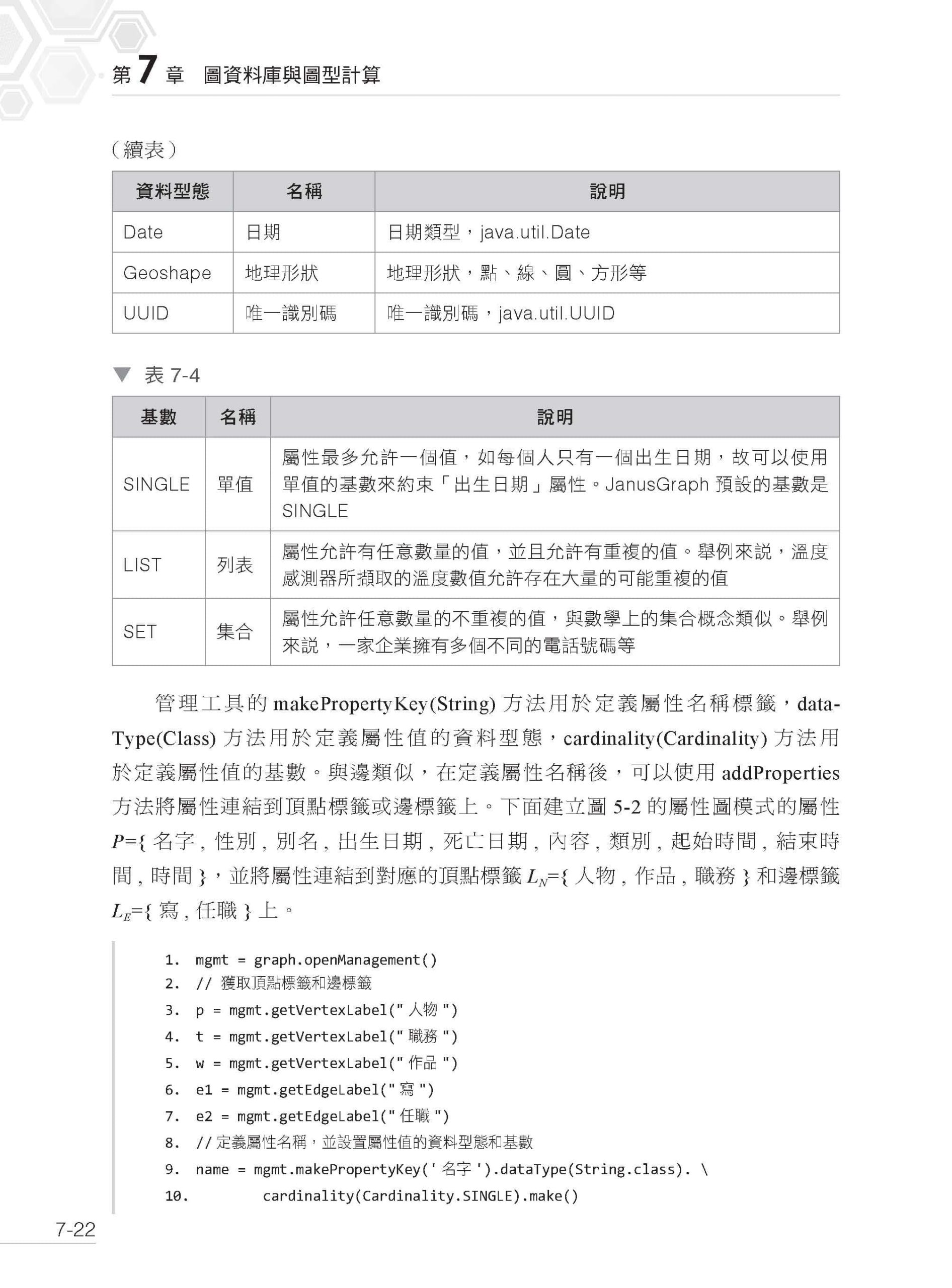
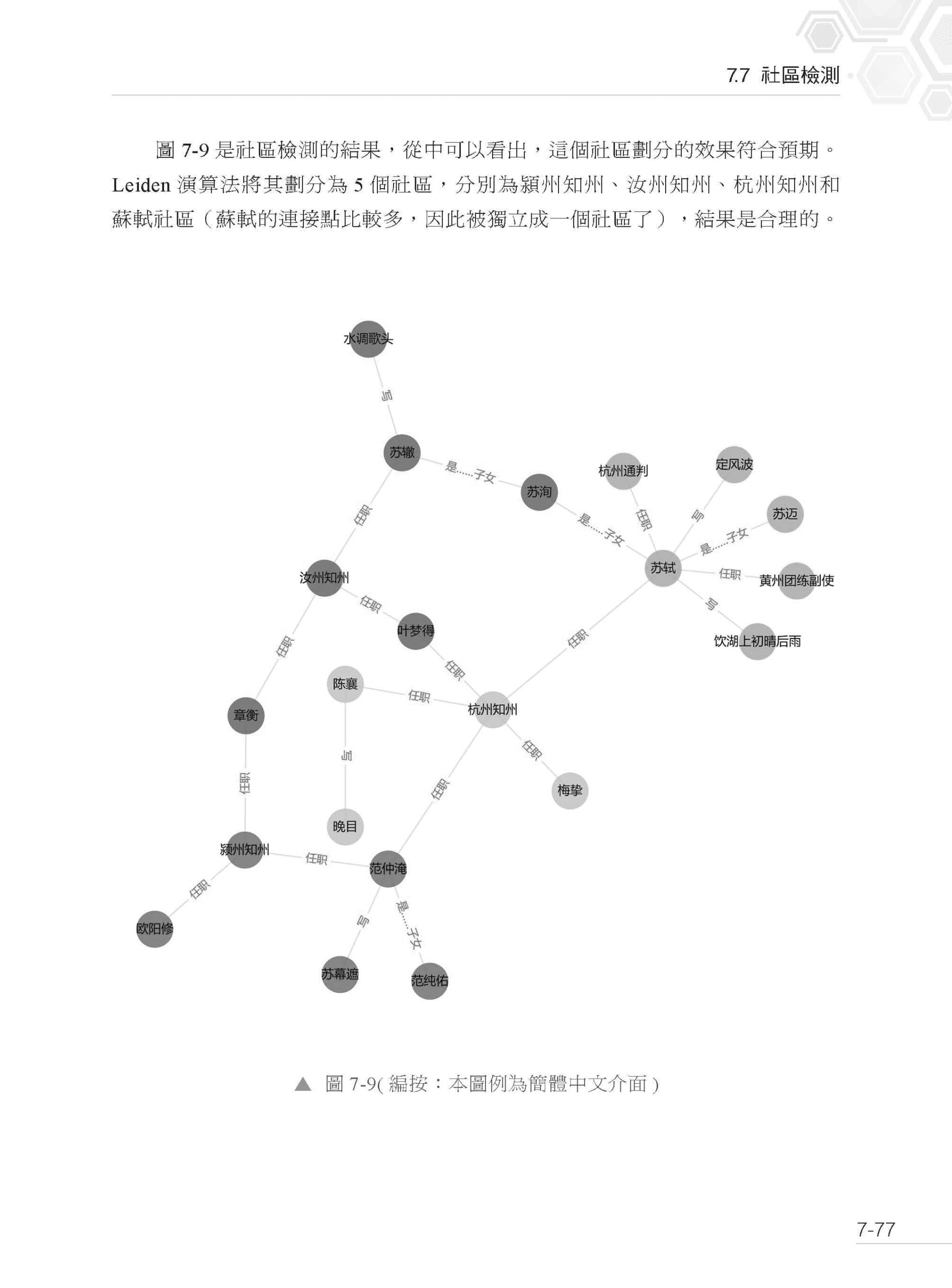
▌第7 章 圖資料庫與圖型計算 7.1 圖資料庫概述 7.1.1 頂點、邊、屬性與標籤 7.1.2 圖資料庫的儲存與查詢 7.1.3 主流的圖資料庫 7.2 JanusGraph 分散式圖資料庫 7.2.1 JanusGraph 系統架構 7.2.2 CAP 理論與JanusGraph 7.2.3 與搜尋引擎的整合 7.2.4 事務和損毀修復 7.2.5 屬性圖模式的定義 7.2.6 圖查詢語言Gremlin 7.3 JanusGraph 實戰指南 7.3.1 安裝、運行和配置JanusGraph 7.3.2 在JanusGraph 中定義屬性圖模式 7.3.3 為圖建立索引 7.3.4 索引的狀態及動作 7.3.5 查看屬性圖模式 7.3.6 為圖插入頂點、邊和屬性 7.3.7 查詢的起始與終末 7.3.8 提取圖中元素的資訊 7.3.9 過濾查詢準則 7.3.10 圖的遊走 7.3.11 分組與聚合 7.3.12 分支與迴圈 7.3.13 match、map、filter 和sideEffect 7.3.14 性能最佳化工具的使用 7.4 JanusGraph 的視覺化 7.4.1 JanusGraph-Visualizer 7.4.2 其他視覺化工具 7.5 遍歷與最短路徑演算法 7.5.1 廣度優先搜索 7.5.2 深度優先搜索 7.5.3 路徑和最短路徑 7.6 中心性 7.6.1 中心性的概念及應用 7.6.2 度中心性 7.6.3 親密中心性 7.6.4 仲介中心性 7.6.5 特徵向量中心性 7.6.6 PageRank 7.7 社區檢測 7.7.1 社區檢測概述 7.7.2 社區檢測演算法一覽 7.7.3 Leiden 演算法實戰 7.7.4 社區檢測演算法的應用場景 7.8 思考題 7.9 本章小結
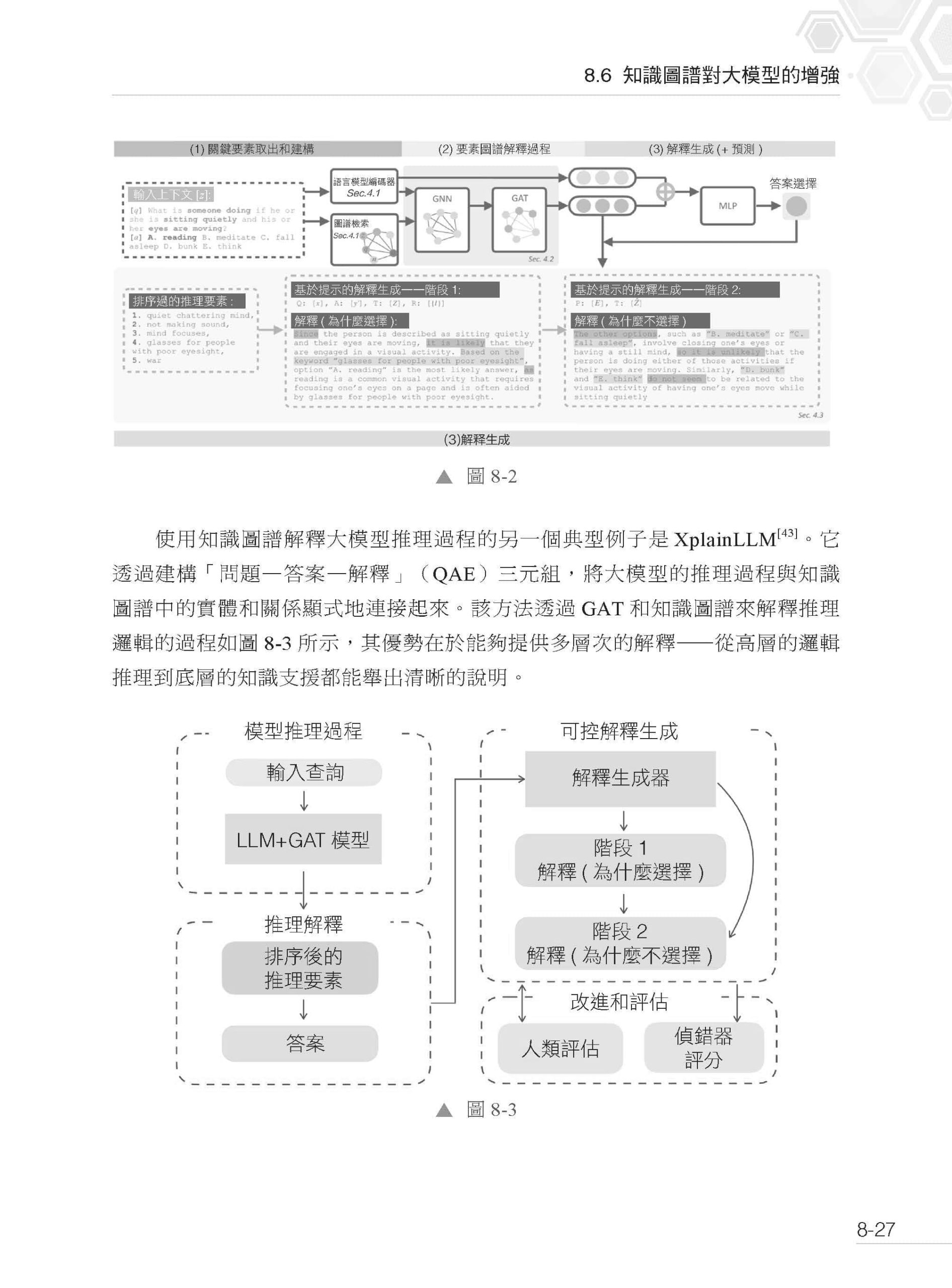
▌第8 章 圖模互補應用範式 8.1 圖模互補概述 8.2 圖模互補中的知識圖譜 8.2.1 知識的確定性和一致性 8.2.2 知識來源可追溯 8.2.3 知識的即時與及時更新 8.2.4 可解釋與可追溯的演繹推理 8.2.5 校正機制與知識的持續維護 8.2.6 基於圖機器學習與圖神經網路的機率推理 8.2.7 知識圖譜的全域視野 8.3 圖模互補中的大模型 8.3.1 從任務描述到任務需求的理解 8.3.2 利用知識圖譜檢索、整合和推理結果 8.3.3 高品質的自然語言生成 8.3.4 結合多源知識生成創新性內容 8.3.5 機率推理能力與通用性 8.3.6 知識取出 8.3.7 知識補全 8.3.8 跨語言知識對齊 8.4 圖模互補應用範式的特點 8.5 大模型對知識圖譜的增強 8.5.1 增強知識圖譜的建構 8.5.2 增強知識圖譜的補全 8.5.3 增強對知識的描述 8.5.4 增強知識圖譜的推理 8.5.5 增強知識圖譜的查詢 8.6 知識圖譜對大模型的增強 8.6.1 減少大模型的幻覺 8.6.2 內嵌知識圖譜的大模型 8.6.3 提升大模型的推理能力 8.6.4 知識圖譜增強生成 8.6.5 提升大模型生成內容的可解釋性 8.6.6 應用案例 8.7 基於圖模互補應用範式的智慧系統的典型流程 8.8 思考題 8.9 本章小結
▌第9 章 知識圖譜增強生成與GraphRAG 9.1 知識圖譜增強生成的原理 9.1.1 深度推理和即時推理 9.1.2 全域視野與深度洞察 9.1.3 知識整合 9.2 知識圖譜增強生成的通用框架 9.3 為知識圖譜建立索引 9.3.1 圖索引 9.3.2 文字索引 9.3.3 向量索引 9.3.4 混合索引 9.4 從知識圖譜中檢索知識 9.4.1 檢索方法 9.4.2 檢索過程 9.4.3 知識粒度 9.5 知識表示形式 9.5.1 鄰接表和邊表 9.5.2 自然語言文字 9.5.3 程式語言 9.5.4 語法樹 9.5.5 頂點序列 9.6 GraphRAG 概述 9.7 GraphRAG 實戰 9.7.1 安裝GraphRAG 和資料資源準備 9.7.2 轉為實體的關係屬性的DataFrame 9.7.3 計算實體、關係的排序值 9.7.4 為實體生成描述文字及向量化 9.7.5 為關係生成描述文字及向量化 9.7.6 社區分類和社區描述文字 9.7.7 呼叫API 生成GraphRAG 可用資料 9.7.8 大模型的初始化 9.7.9 局部搜索與全域搜索 9.8 思考題 9.9 本章小結
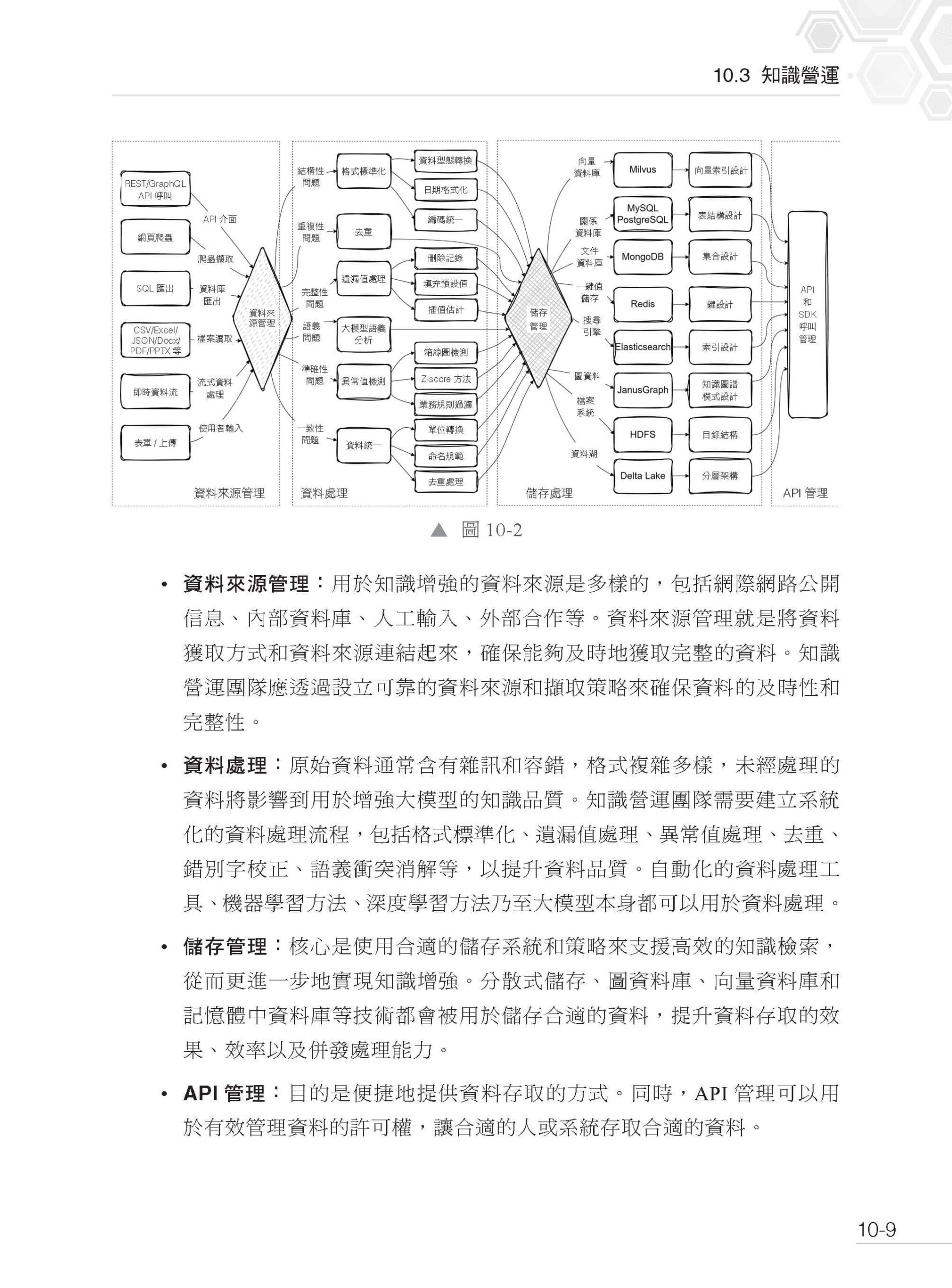
▌第10 章 知識增強大模型應用 10.1 應用框架 10.2 知識來源 10.2.1 非結構化知識 10.2.2 結構化資料庫 10.2.3 知識圖譜 10.3 知識營運 10.3.1 知識的品質 10.3.2 資料管理流程 10.3.3 法律符合規範、隱私與智慧財產權 10.3.4 可觀測性工具 10.4 應用指南 10.4.1 應用價值 10.4.2 進取者:全面推進導向的策略 10.4.3 保守者:試點驅動導向的策略 10.4.4 選型的「四三二一」原則 10.4.5 最佳實踐要點 10.5 行業應用案例 10.5.1 文件幫手 10.5.2 教育領域應用場景 10.5.3 智慧金融應用場景 10.5.4 智慧醫療應用場景 10.5.5 智慧製造應用場景 10.6 思考題 10.7 本章小結
▌參考文獻 |
序
| 人工智慧的發展史是一部不斷探索智慧本質的歷史。自1956 年達特茅斯會議提出人工智慧的概念以來,人工智慧領域經歷了多次激動人心的範式轉變。大模型技術的崛起無疑是迄今為止最具革命性的一次轉變,我們正站在一個重要的歷史節點上。這些大模型以其驚人的規模、卓越的能力和廣泛的通用性,重新定義了人類對智慧的理解,並使人工智慧突破了許多以往的技術瓶頸,達到了前所未有的高度。
然而,大模型的發展並非完美無瑕,尤其是在知識準確性、可解釋性及效率等方面仍然面臨挑戰,「幻覺」(大模型生成自信但錯誤的回答)和「知識陳舊」(大模型依據過時的資訊生成錯誤的回答)等都是急待解決的問題。如何透過結合外部知識,讓大模型變得更加智慧、高效和可靠,已成為當下人工智慧領域前端的研究方向,檢索增強生成(RAG)和圖檢索增強生成(GraphRAG)等方法是其中的翹楚。
在這一背景下,《比RAG 更強 - 知識增強LLM 型應用程式實戰》一書應運而生。本書全面系統地介紹了知識增強與大模型結合的理論、方法與實踐,為研究者和實踐者提供了清晰的指引。它從大模型的基礎出發,逐步引入知識圖譜、向量資料庫、檢索增強生成和基於知識圖譜的增強生成等關鍵技術和實踐經驗,並展現了知識增強大模型在實際場景中的廣泛應用。全書邏輯縝密、內容翔實,為學術研究和產業實踐架起了一座溝通的橋樑。
作為一名見證了人工智慧多個發展階段的研究者,我認為知識的有效組織和運用將是使機器真正實現智慧的重要基石,因此,知識增強將成為大模型發展的關鍵方向之一。本書不僅總結了當前的研究進展,而且包含作者對人工智慧的未來發展及其如何更進一步地服務人類社會的深刻思考。我相信,本書將成為研究者、工程師和學生的案頭必備圖書。我也由衷地期待這本書能夠啟發更多的研究者和實踐者投身這個充滿活力的領域,推動人工智慧技術的進步,為人類社會創造更大的價值。
願本書能啟發讀者,不僅傳授知識,更能激發創新思維。
黃萱菁 復旦大學教授 |