









描述
內容簡介
|
作者簡介
| 徐歆閔(Min Hsu)
現任職於軟體公司的資深資料科學家,致力於將機器學習技術應用於真實世界的產品中。曾獲iThome鐵人賽AI & Data組冠軍,著有《科技巨頭的演算法大揭祕》,擅長以深入淺出的方式,拆解複雜的技術概念。熱衷於知識分享與技術實踐,相信動手實作是弭平理論與應用之間鴻溝的最佳路徑。
* Medium:medium.com/smhsu * Instagram:@data.scientist.min |
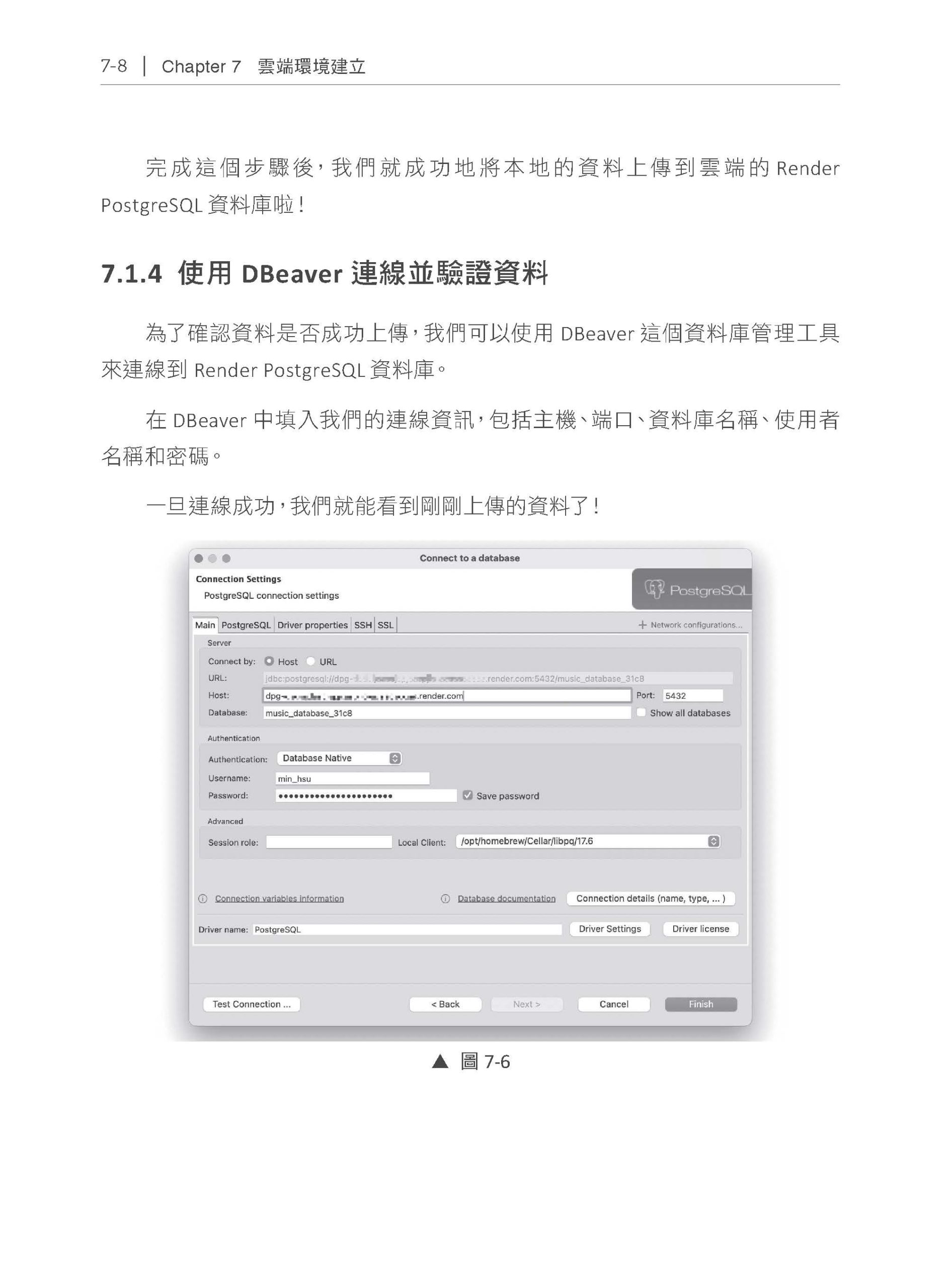
目錄
| Chapter 1 機器學習專案的生命週期介紹
1.1 定義商業目標 1.2 蒐集和準備資料 1.2.1 數據版本控制(Data Versioning) 1.2.2 資料標記的一致性 1.2.3 不同資料類型的挑戰 1.2.4 資料管線(Data Pipeline) 1.2.5 數據測試(Data Testing) 1.2.6 資料漂移和概念漂移 1.3 模型開發與版本管理 1.3.1 建立模型的迭代過程 1.3.2 模型開發中的挑戰 1.4 模型部署與應用整合 1.4.1 軟體問題與部署考量 1.5 監控與持續改進 1.5.1 監控與維護系統 1.5.2 模型老化和重新訓練 1.6 模型導向迭代vs. 資料導向迭代 1.6.1 模型導向迭代 1.6.2 資料導向 1.6.3 如何選擇適合的策略呢? 1.7 實作專案:音樂搜尋和推薦系統
Chapter 2 本地開發環境建立 2.1 開始專案前的必要工具準備 2.1.1 安裝Python 2.1.2 安裝Git 和註冊GitHub 帳號 2.1.3 Docker 2.2 使用uv 來管理Python 環境與套件 2.2.1 uv:更快、更強大的Python 套件與環境管理工具
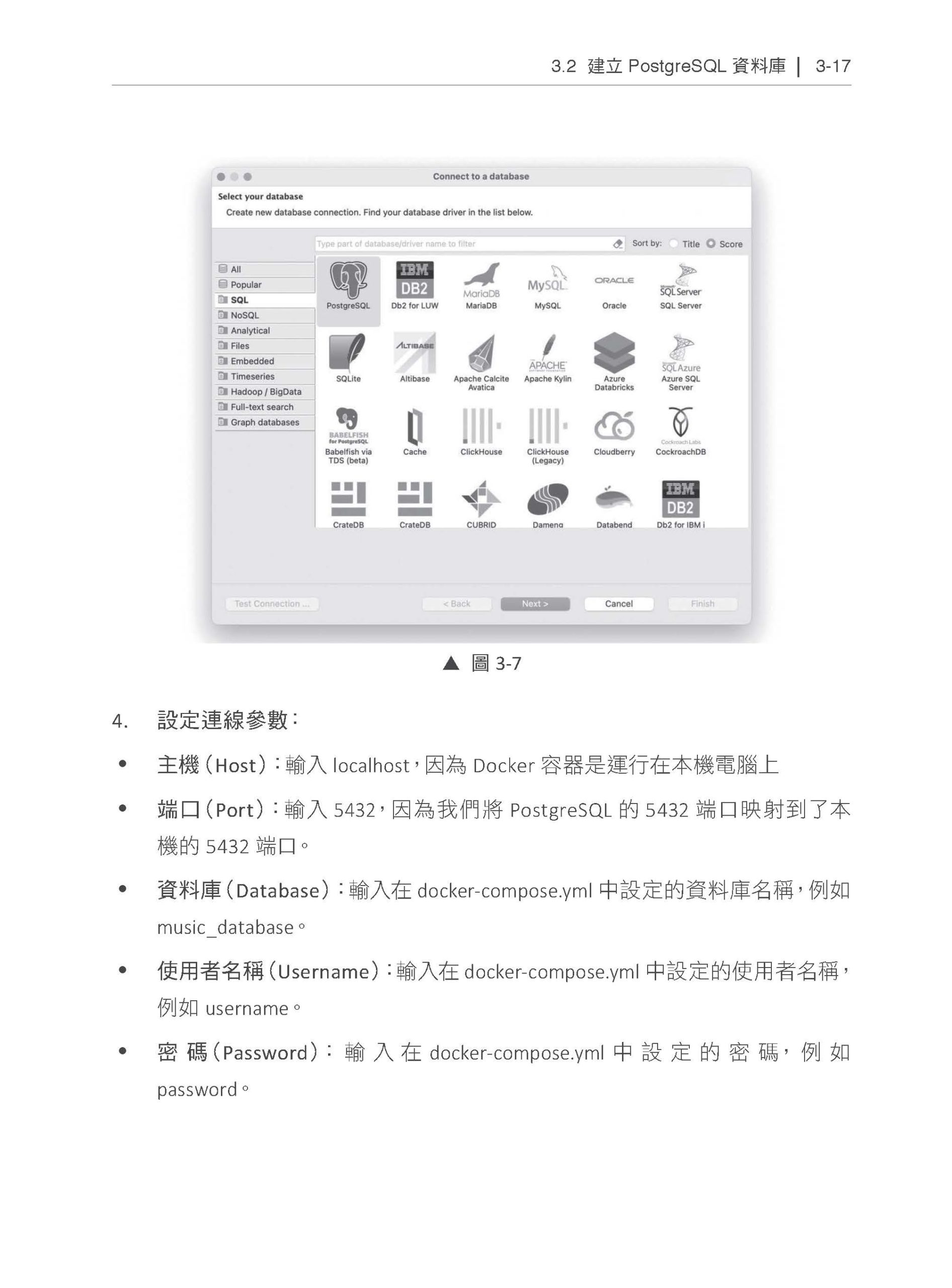
Chapter 3 在本地建立資料庫 3.1 專案環境建立 3.2 建立PostgreSQL 資料庫 3.2.1 docker-compose.yml 的介紹 3.2.2 用DBeaver 查看資料 3.3 SQLModel:Python 的資料庫操作 3.4 向量資料庫和Qdrant 的介紹 3.4.1 什麼是向量資料庫(Vector Database)? 3.4.2 Qdrant 的概念介紹 3.4.3 用Docker compose 建立Qdrant 3.5 用Python 連線至Qdrant 3.6 把PostgreSQL 和Qdrant 合併成一個Docker Compose
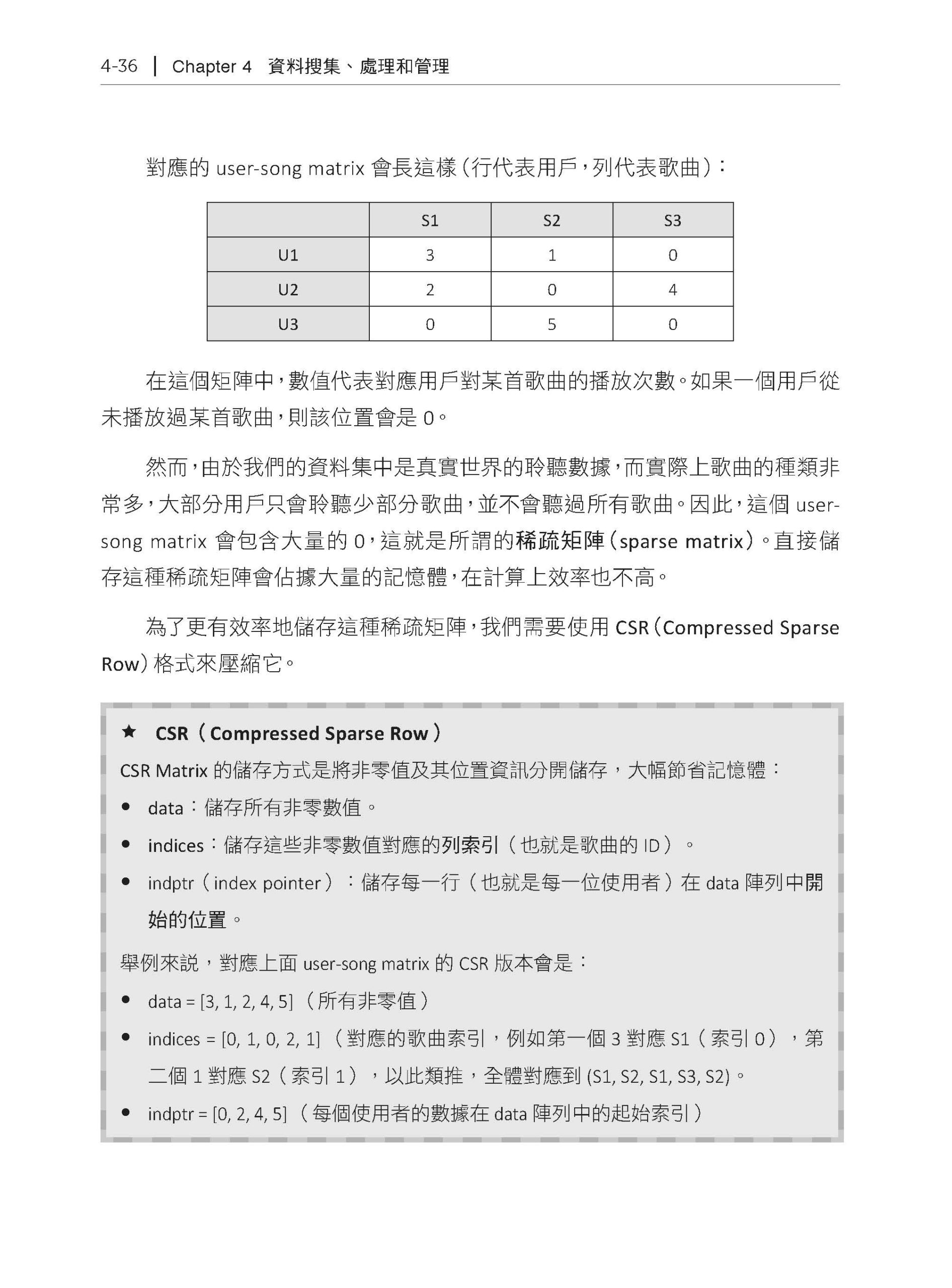
Chapter 4 資料搜集、處理和管理 4.1 專案環境建立 4.2 下載跟處理Million Song Dataset 4.2.1 前處理資料集 4.2.2 建立資料庫 4.3 下載跟處理The Echo Nest Taste Profile Subset 4.3.1 下載資料 4.3.2 寫入PostgreSQL Database 中 4.3.3 建立user-song matrix 4.3.4 存入Qdrant 向量資料庫中 4.4 Spotify 音樂資料表 4.4.1 讀取資料 4.4.2 資料前處理 4.5 DVC 的介紹 4.5.1 什麼是DVC? 4.5.2 DVC 的使用教學
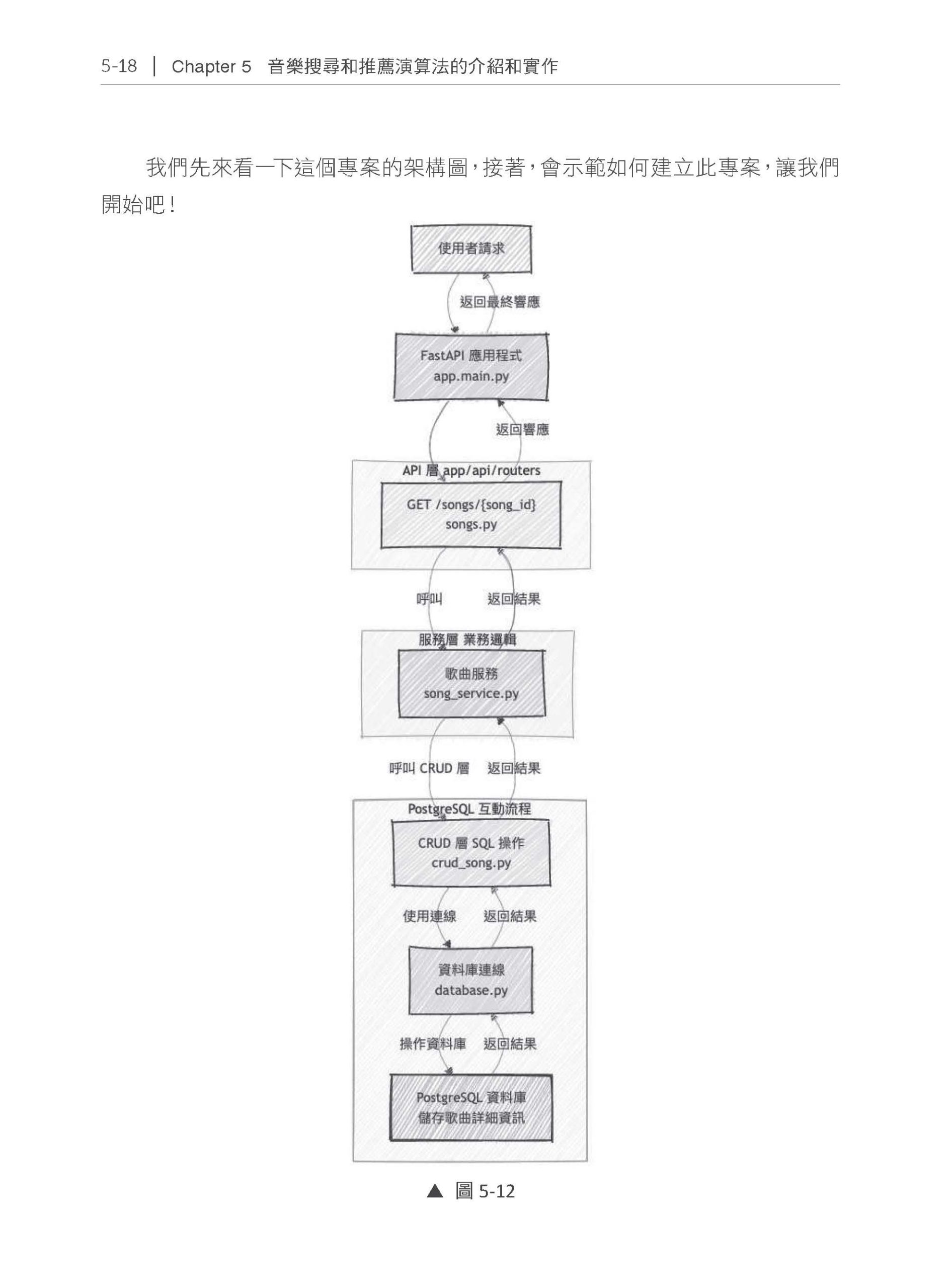
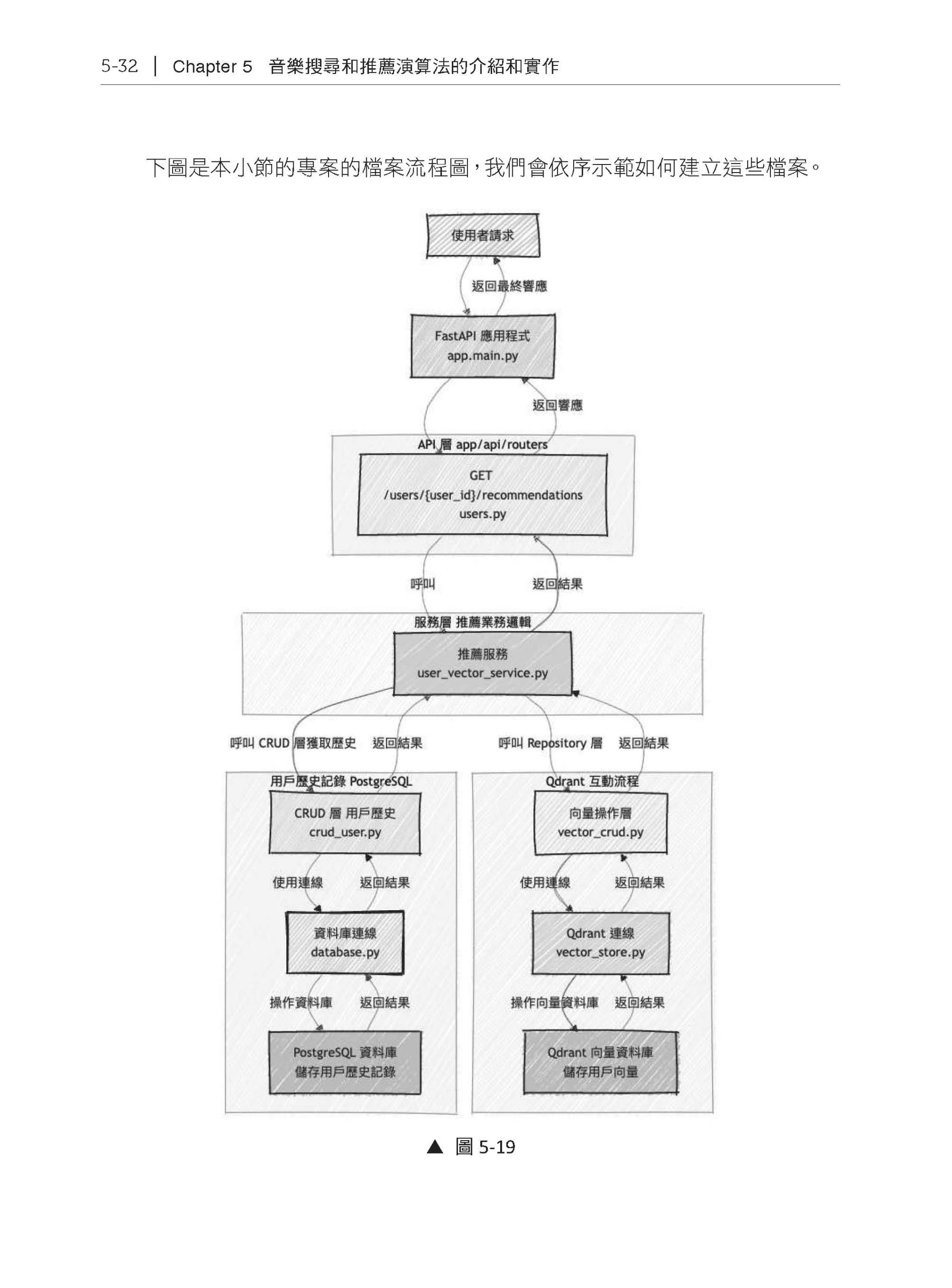
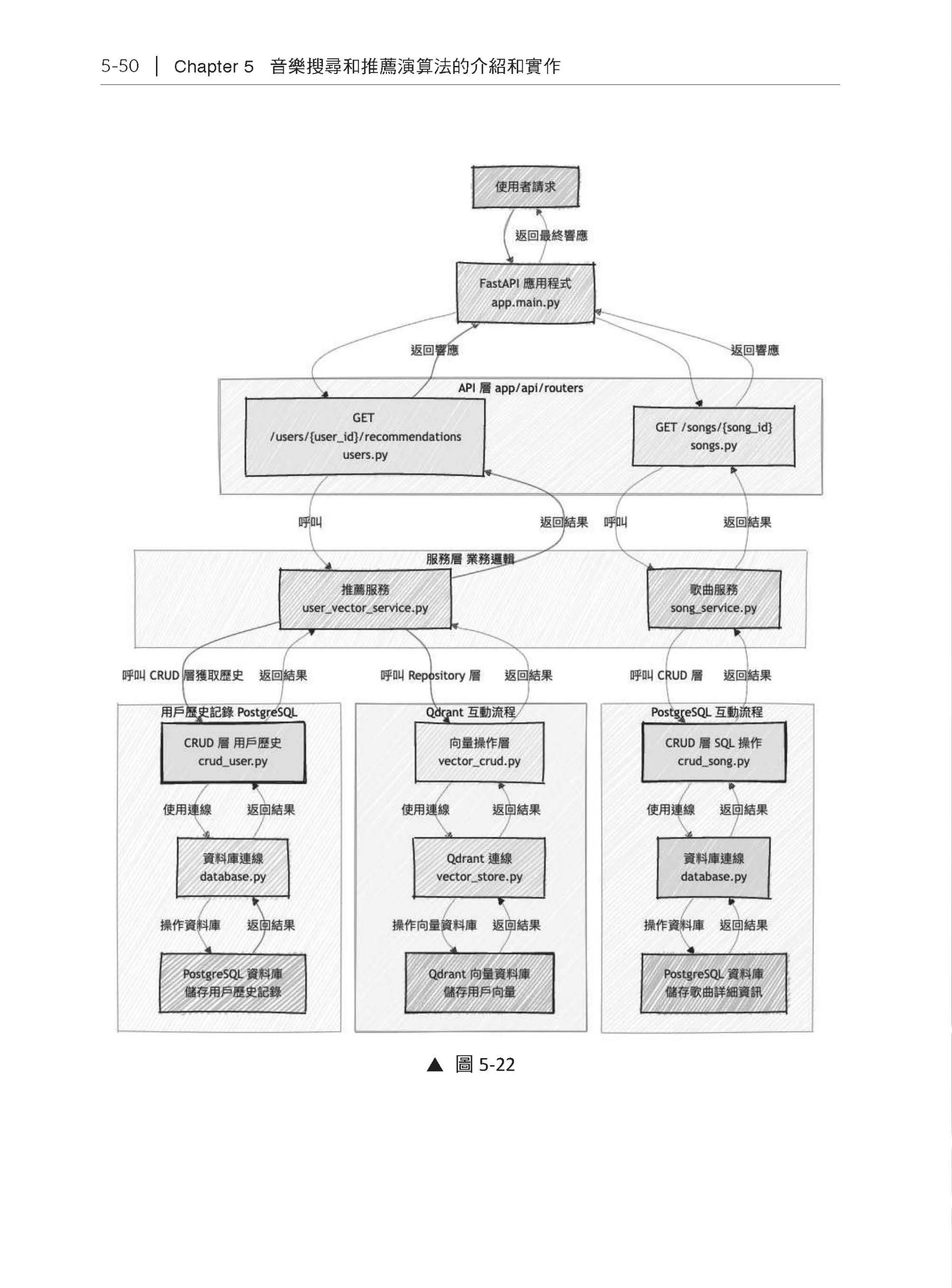
Chapter 5 音樂搜尋和推薦演算法的介紹和實作 5.1 FastAPI 的基本用法介紹 5.1.1 FastAPI 的基本介紹 5.1.2 對資料進行CRUD 操作 5.1.3 專案架構 5.1.4 建立API 5.2 FastAPI 後端專案建立——音樂搜尋系統 5.2.1 專案環境建立 5.2.2 建立歌曲搜尋Mock API 5.2.3 用FastAPI 連接到PostgreSQL 資料庫 5.2.4 用FastAPI 連接到Qdrant 向量資料庫 5.2.5 小結
Chapter 6 搜尋畫面的UI 建立 6.1 Streamlit 的安裝方法 6.2 Streamlit 核心概念 6.2.1 基本介面 6.2.2 互動元件 6.2.3 版面佈局 6.3 範例實作:音樂推薦系統搜尋網頁 6.3.1 與後端FastAPI 溝通 6.3.2 設定頁面
Chapter 7 雲端環境建立 7.1 Render 的PostgreSQL 資料庫部署 7.1.1 Render 基礎設定 7.1.2 在Render 上建立PostgreSQL 資料庫 7.1.3 將本地資料搬遷到Render PostgreSQL 7.1.4 使用DBeaver 連線並驗證資料 7.2 部署FastAPI 服務到Render 7.3 設定雲端的Qdrant 向量資料庫 7.3.1 設定Qdrant Cloud 7.3.2 上傳資料到Qdrant Cloud 7.4 Streamlit Community Cloud
Chapter 8 音樂分類模型的介紹和實作 8.1 MLflow 的介紹 8.1.1 MLflow 的核心元件 8.2 實驗追蹤(MLflow Tracking) 8.2.1 MLflow Tracking 的概念 8.2.2 MLflow Tracking 的範例 8.2.3 啟動MLflow UI 8.3 MLflow Signature 與Input Example 的介紹 8.3.1 概念介紹 8.3.2 如何建立Model Signature 跟Input Example 8.4 使用Docker 部署MLflow Tracking Server、PostgreSQL 與MinIO 8.4.1 使用Docker 啟動MLflow Tracking 伺服器與UI 8.4.2 使用PostgreSQL 作為MLflow 後端儲存 8.4.3 使用MinIO 作為Artifact 儲存位置 8.5 模型封裝與版本管理(MLflow Models + MLflow Registry) 8.5.1 如何將模型註冊到Registry? 8.5.2 設定標籤(Tags)與別名(Aliases)
Chapter 9 模型部署 9.1 將模型部署到BentoML 9.1.1 從MLFlow 下載模型檔案 9.1.2 將模型部署到BentoML 9.1.3 建立BentoML FastAPI 服務
Chapter 10 其他應用案例與延伸專案 10.1 電商商品推薦系統 10.2 影視影片搜尋與推薦 10.3 健康與運動建議系統 10.4 金融交易風險偵測 10.5 客服問答系統 10.6 小結 |
序
| 從模型到產品,走完 AI 應用的最後一哩路
嗨,謝謝你翻開這本書。如果你正煩惱如何將電腦裡的模型,變成一個能真正服務人群的產品,那麼,你來對地方了!
幾年前,身為資料科學新手的我,總是熱切於訓練出一個表現良好的模型。不過,儘管在精挑細琢後,得到一個高準確率的模型,卻只能讓其停留在 Jupyter Notebook 中,不知道如何帶出實驗室,讓它真正走入產品、服務人群。 「要怎麼把模型變成一個用戶能隨時使用的產品?」 「當資料不斷湧入,我要怎麼確保它的表現不會變差?」 「面對數十個實驗版本,我該如何有效管理,並在出錯時快速回溯?」
這些問題的複雜性並不亞於演算法,只是身為資料科學家的我們,不熟稔於 MLOps 的技術:我們擅長於打造一顆聰明的大腦(模型),卻對如何為它建構一個強健的身體(維運架構)感到陌生。這本書,就是為了解決這個鴻溝而生。
在我的上一本書《科技巨頭的演算法大揭秘》中,專注於討論和拆解各種演算法的核心,而這本書,則轉向實際的技術開發,一起探討如何在開發完模型後,能夠走完最後一哩路,將模型真正淬鍊成產品。
這本書,就是那張不可或缺的「系統藍圖」 或許你會問,在這個 AI 能幫我們寫程式的「Vibe Coding」時代,學習這些技術還有必要嗎?我的答案是肯定的,而且比以往任何時候都更加重要。
AI 如同一位能力超群的副駕駛,能請他加速、轉彎,但最終決定要去哪、該走哪條路的,永遠是手握方向盤的我們。AI 可以生成一段完美的 Dockerfile,但我們必須先理解為何需要容器化;AI 可以寫出一個 FastAPI 的端點,但無法替我們設計整個服務的藍圖。
本書將從機器學習的完整生命週期談起,並以「音樂推薦系統」作為實戰專案,親手整合 Docker、PostgreSQL、MLflow、FastAPI、BentoML 等一系列主流工具,你會發現,這些工具並非獨立的孤島,而是一個環環相扣、彼此協作的生態系。
這本書是為所有渴望將模型推向產品化,卻不知從何下手的你而寫。無論你是希望作品能落地的資料科學家,還是想跨足 AI 領域的軟體工程師,我都希望本書能成為你手中的那份清晰的地圖,更有信心地打造出穩定、可靠且能持續創造價值的 AI 服務。
旅程即將開始,讓我們一起動手吧! 資料科學家 Min 徐歆閔 |