
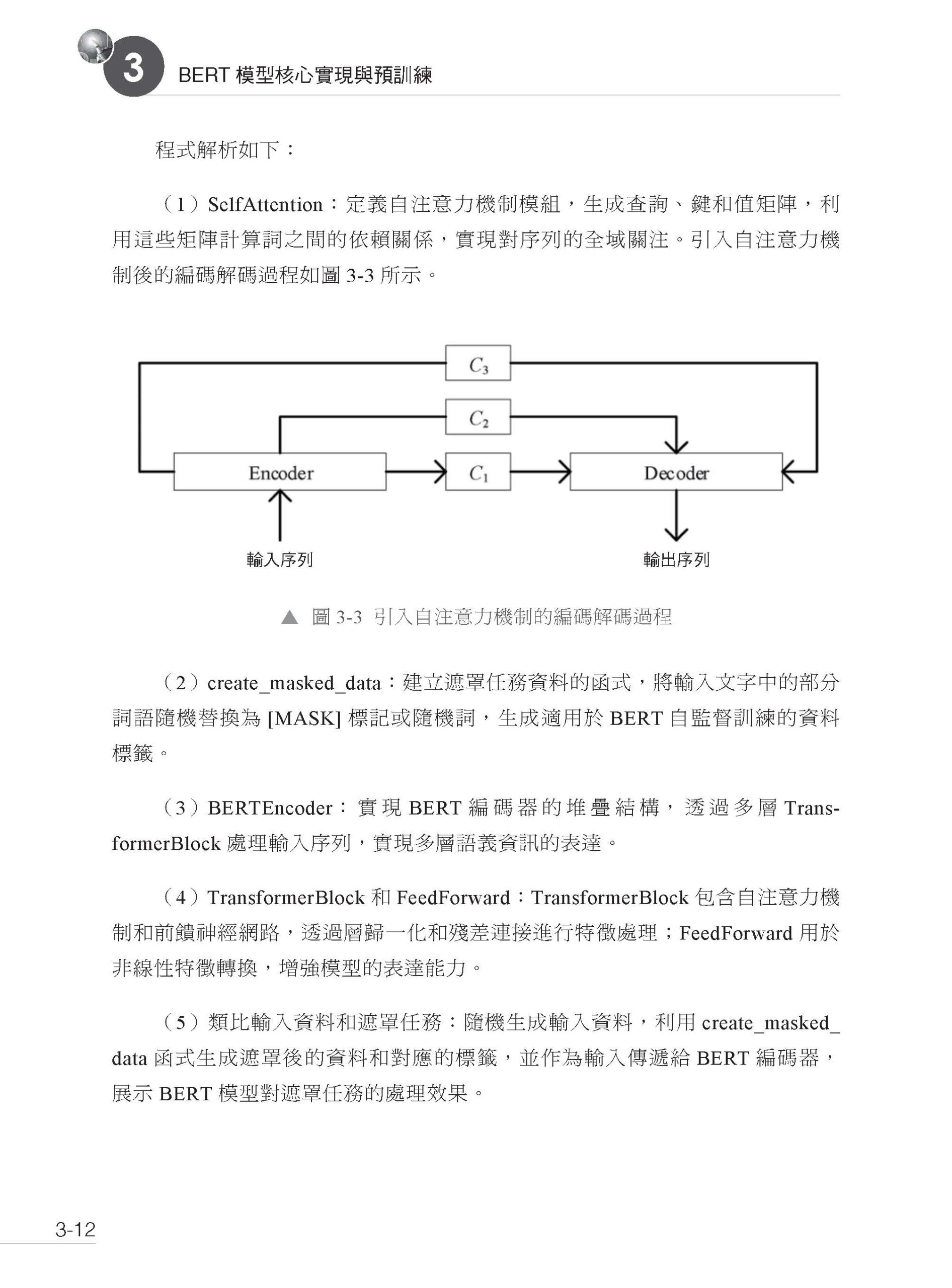

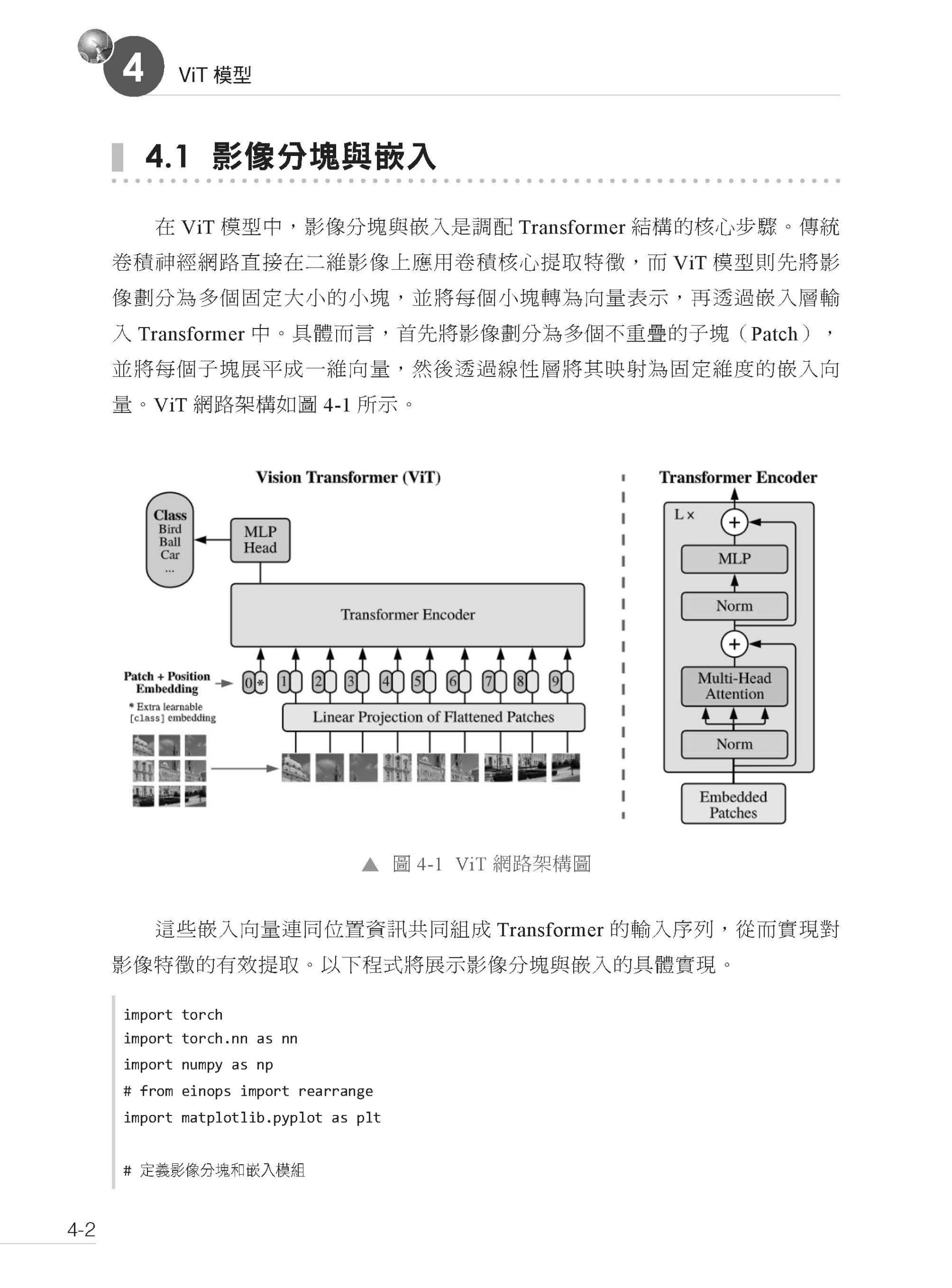





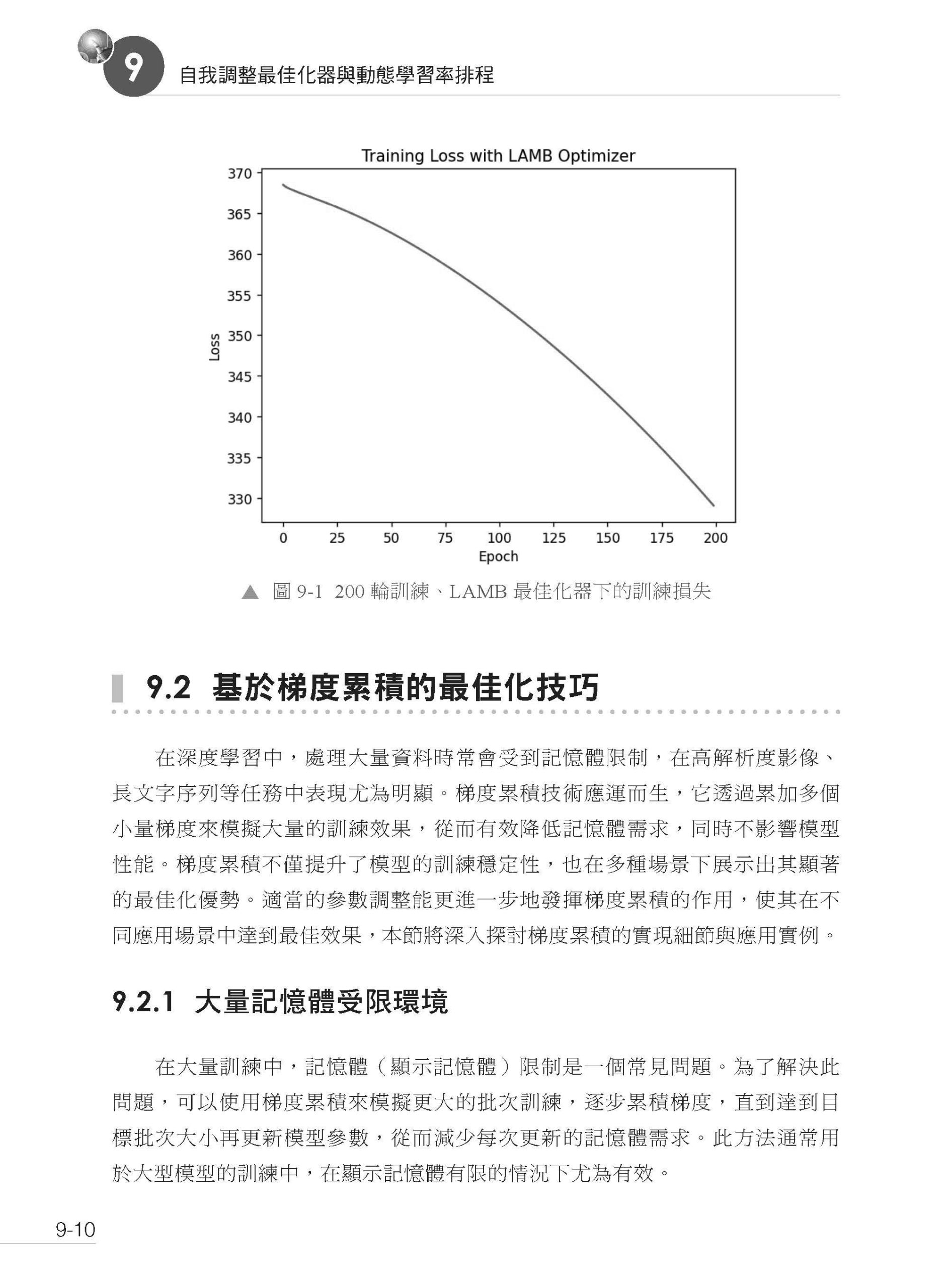
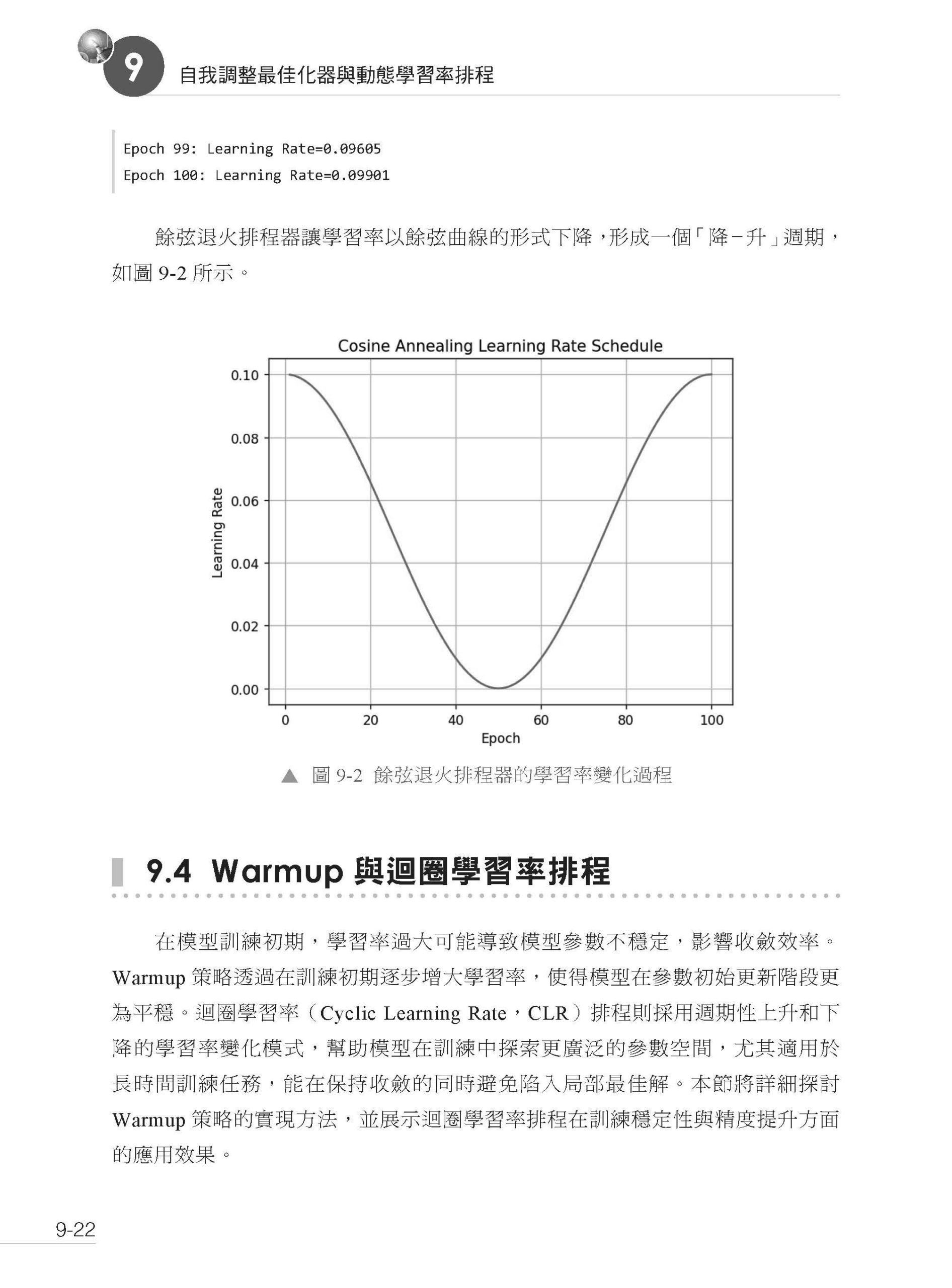




描述
內容簡介
|
作者簡介
| 梁楠 博士
畢業於北京航空航天大學,高級工程師,長期從事模式識別、機器學習、統計理論的研究與應用,負責或參與過多項科研項目,專註於人工智慧、大語言模型的應用與開發,對深度學習、數據分析與預測等有獨到見解。 |
目錄
| ▌第0 章 引言
一、大模型技術的發展歷史 1. 基於規則和統計學習的早期階段 2. 神經網路與深度學習的崛起 3. Transformer 的誕生與自注意力機制的崛起 4. 預訓練模型的興起:BERT、GPT 和T5 5. 超大規模模型與多模態應用 二、開發環境配置基礎 1. 硬體規格要求 2. 軟體相依與環境架設 3. 常見問題與解決方案
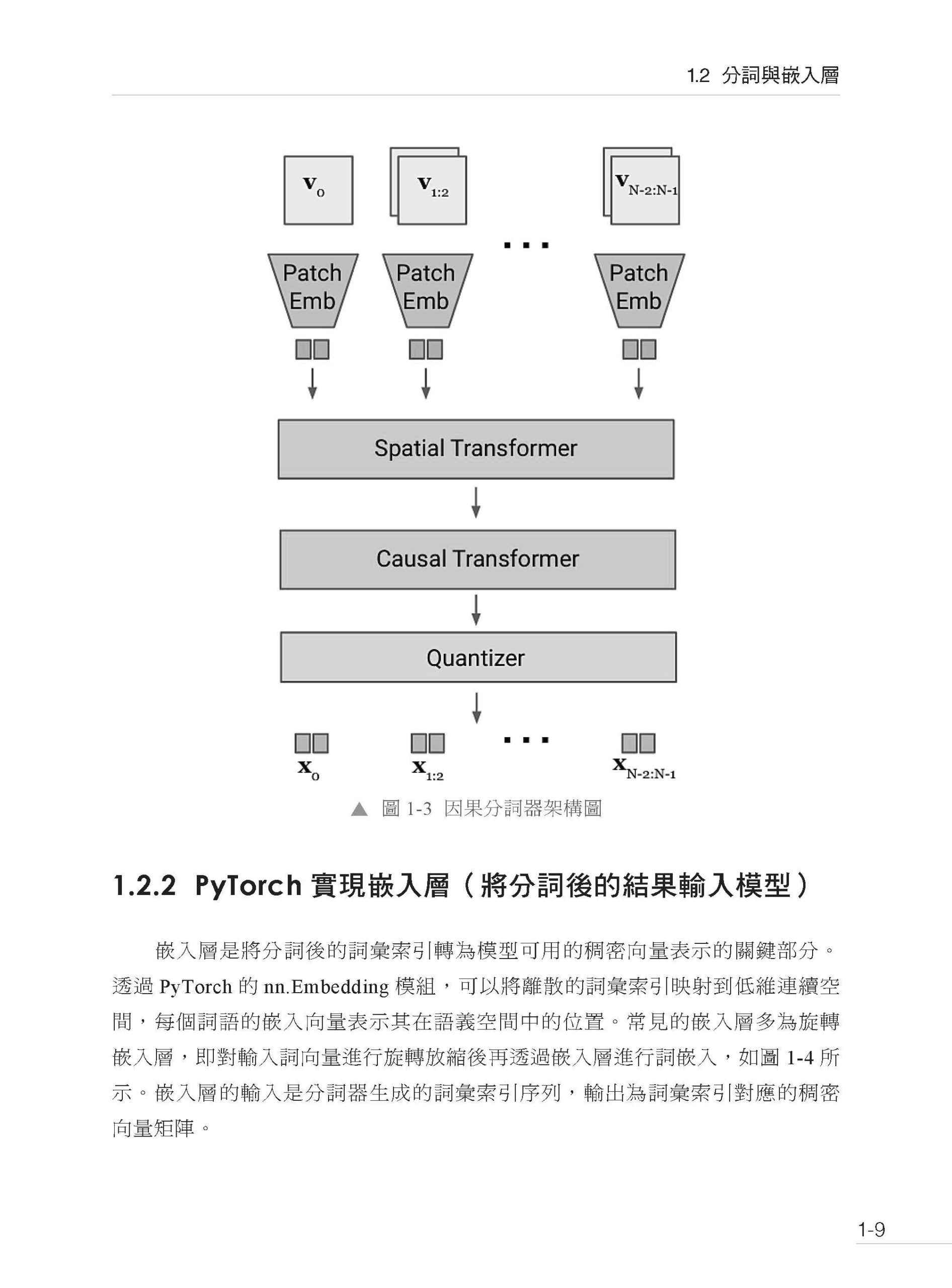
▌第1 章 Transformer 模型基礎 1.1 Seq2Seq 模型 1.1.1 編碼器-解碼器工作原理 1.1.2 Seq2Seq 結構實現 1.2 分詞與嵌入層 1.2.1 分詞器:將文字轉為嵌入向量 1.2.2 PyTorch 實現嵌入層(將分詞後的結果輸入模型) 1.3 自注意力與多頭注意力機制 1.3.1 自注意力機制計算過程(QKV 矩陣生成和點積運算) 1.3.2 多頭注意力機制與Transformer 1.4 殘差連接與層歸一化 1.4.1 殘差連接層的實現 1.4.2 層歸一化與訓練穩定性 1.5 位置編碼器 1.5.1 位置編碼的計算與實現 1.5.2 位置編碼在無序文本資料中的作用 1.6 本章小結 1.7 思考題
▌第2 章 GPT 模型文字生成核心原理與實現 2.1 GPT-2 核心模組 2.1.1 層堆疊 2.1.2 GPT-2 中的注意力機制 2.2 GPT 模型的文字生成過程 2.2.1 詳解GPT-2 文字生成過程 2.2.2 Greedy Search 和Beam Search 演算法的實現與對比 2.3 模型效果評估與調優 2.3.1 模型常見評估方法 2.3.2 基於困惑度的評估過程 2.4 本章小結 2.5 思考題
▌第3 章 BERT 模型核心實現與預訓練 3.1 BERT 模型的核心實現 3.1.1 編碼器堆疊 3.1.2 BERT 的自注意力機制與遮罩任務 3.2 預訓練任務:遮罩語言模型(MLM) 3.2.1 MLM 任務實現過程 3.2.2 如何對輸入資料進行隨機遮掩並預測 3.3 BERT 模型的微調與分類任務應用 3.4 本章小結 3.5 思考題
▌第4 章 ViT 模型 4.1 影像分塊與嵌入 4.2 ViT 模型的核心架構實現 4.2.1 ViT 模型的基礎結構 4.2.2 自注意力和多頭注意力在影像處理中的應用 4.3 訓練與評估ViT 模型 4.4 ViT 模型與注意力嚴格量化分析 4.5 本章小結 4.6 思考題
▌第5 章 高階微調策略:Adapter Tuning 與P-Tuning 5.1 Adapter Tuning 的實現 5.2 LoRA Tuning 實現 5.3 Prompt Tuning 與P-Tuning 的應用 5.3.1 Prompt Tuning 5.3.2 P-Tuning 5.3.3 Prompt Tuning 和P-Tuning 組合微調 5.3.4 長文字情感分類模型的微調與驗證 5.4 本章小結 5.5 思考題
▌第6 章 資料處理與資料增強 6.1 資料前置處理與清洗 6.1.1 文字資料前置處理 6.1.2 文字資料清洗 6.2 文字資料增強 6.2.1 同義詞替換 6.2.2 隨機插入 6.2.3 其他類型的文字資料增強方法 6.3 分詞與嵌入層的應用 6.3.1 深度理解分詞技術 6.3.2 嵌入向量的生成與最佳化 6.3.3 文字前置處理與資料增強綜合案例 6.4 本章小結 6.5 思考題
▌第7 章 模型性能最佳化:混合精度訓練與分散式訓練 7.1 混合精度訓練的實現 7.2 多GPU 並行與分散式訓練的實現 7.2.1 分散式訓練流程與常規配置方案 7.2.2 Data Parallel 方案 7.2.3 Model Parallel 方案 7.3 梯度累積的實現 7.3.1 梯度累積初步實現 7.3.2 小量訓練中的梯度累積 7.3.3 梯度累積處理文字分類任務 7.4 本章小結 7.5 思考題
▌第8 章 對比學習與對抗訓練 8.1 對比學習 8.1.1 建構正負樣本對及損失函式 8.1.2 SimCLR 的實現與初步應用 8.2 基於對比學習的預訓練與微調 8.2.1 透過對比學習進行自監督預訓練 8.2.2 對比學習在分類、聚類等任務中的表現 8.3 生成式對抗網路的實現與最佳化 8.4 對抗訓練在大模型中的應用 8.5 本章小結 8.6 思考題
▌第9 章 自我調整最佳化器與動態學習率排程 9.1 AdamW 最佳化器與LAMB 最佳化器的實現 9.1.1 AdamW 最佳化器 9.1.2 LAMB 最佳化器 9.2 基於梯度累積的最佳化技巧 9.2.1 大量記憶體受限環境 9.2.2 梯度累積的應用場景和參數調整對訓練效果的影響 9.3 動態學習率排程 9.3.1 線性衰減 9.3.2 餘弦退火 9.4 Warmup 與迴圈學習率排程 9.4.1 Warmup 策略實現 9.4.2 迴圈學習率排程 9.4.3 其他幾種常見的動態學習排程器 9.5 本章小結 9.6 思考題
▌第10 章 模型蒸餾與剪枝 10.1 知識蒸餾:教師-學生模型 10.1.1 知識蒸餾核心過程 10.1.2 教師-學生模型 10.1.3 蒸餾損失 10.2 知識蒸餾在文字模型中的應用 10.2.1 知識蒸餾在文字分類模型中的應用 10.2.2 模型蒸餾效率分析 10.2.3 文字情感分析任務中的知識蒸餾效率對比 10.3 模型剪枝技術 10.3.1 權重剪枝 10.3.2 結構化剪枝 10.3.3 在嵌入式裝置上部署手寫數字辨識模型 10.3.4 BERT 模型的多頭注意力剪枝 10.4 本章小結 10.5 思考題
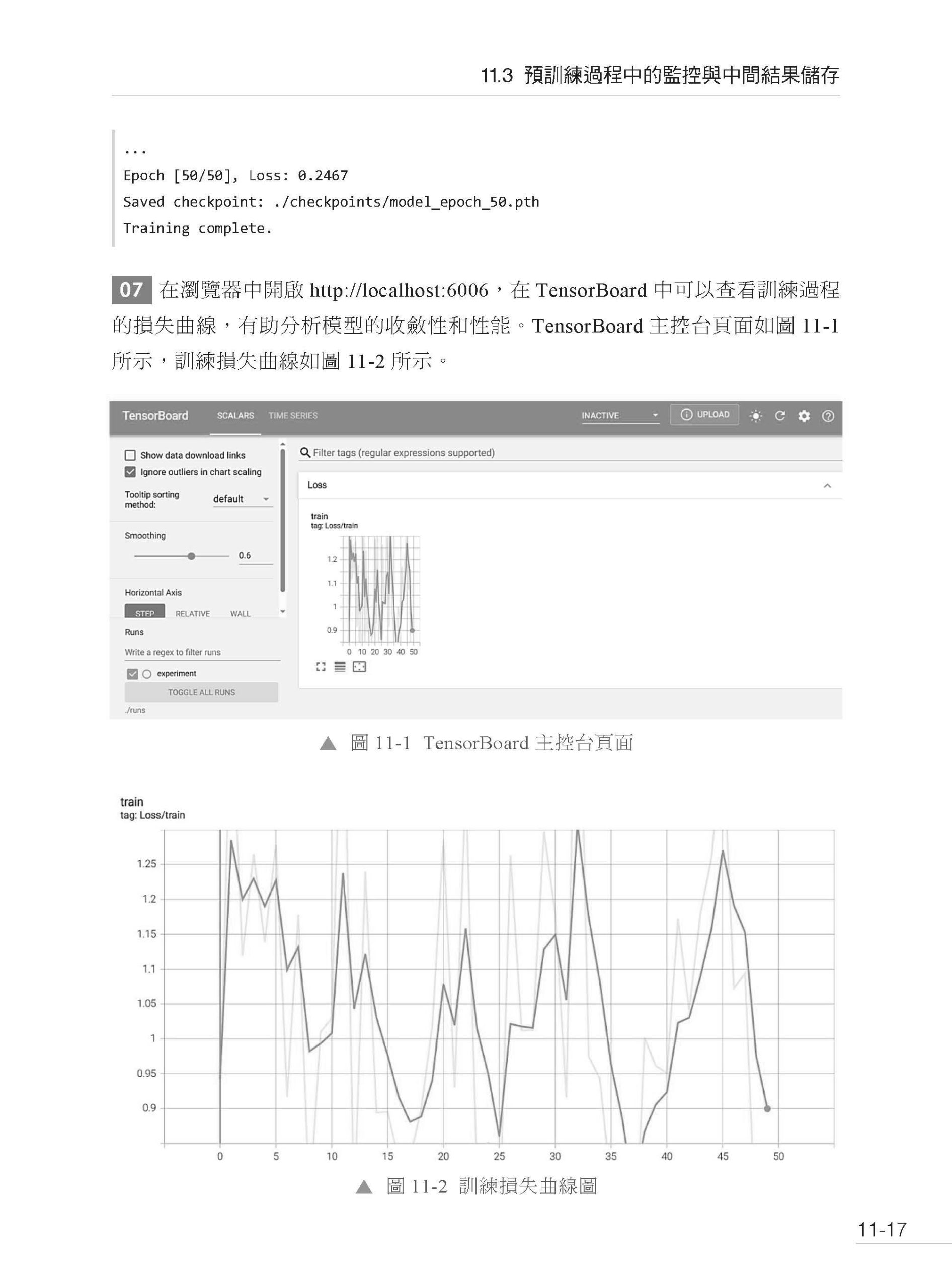
▌第11 章 模型訓練實戰 11.1 資料前置處理與Tokenization 細節 11.1.1 大規模文字資料清洗 11.1.2 常用分詞器的使用 11.2 大規模預訓練模型的設置與啟動 11.3 預訓練過程中的監控與中間結果儲存 11.4 訓練中斷與恢復機制 11.5 綜合案例:IMDB 文字分類訓練全流程 11.5.1 資料前置處理與Tokenization 11.5.2 多GPU 與分散式訓練設置 11.5.3 訓練過程中的監控與中間結果儲存 11.5.4 訓練中斷與恢復 11.5.5 測試模型性能 11.6 本章小結 11.7 思考題
▌第12 章 模型微調實戰 12.1 微調資料集的選擇與準備 12.1.1 資料集準備與清洗 12.1.2 資料集分割 12.1.3 資料增強 12.2 層級凍結與部分解凍策略 12.3 模型參數調整與最佳化技巧 12.4 微調後的模型評估與推理最佳化 12.5 綜合微調應用案例 12.6 本章小結 12.7 思考題 |
序
| 前言
在人工智慧技術日新月異的今天,深度學習中的大規模模型以其在自然語言處理、電腦視覺等領域的非凡表現,已然成為推動技術創新的核心力量。特別是大規模語言模型的異軍突起,更是吸引了無數目光。然而,這些模型的建構和訓練過程並非易事。它們涉及複雜的演算法設計、最佳化技巧、資料前置處理以及模型調優等多個環節,對開發者而言是一個巨大的挑戰。因此,急需一本能夠系統介紹大模型演算法、訓練與微調的書籍,以指導廣大開發者進行實踐。 近年來,Transformer 架構及其衍生模型,如GPT、BERT、ViT 等,已成為自然語言處理、電腦視覺等領域的核心技術。這些大模型憑藉其強大的知識表徵和模式學習能力,為人工智慧的發展注入了新的活力。本書旨在為讀者提供一條從大模型的基礎演算法到實際應用的完整學習路徑。透過閱讀本書,讀者將深入理解並掌握這些複雜模型的建構、訓練、最佳化與微調方法。無論是初學者還是有一定經驗的開發者,都能從中獲益匪淺。 本書從基礎建構模組入手,以清晰明了的方式逐步解析大模型的核心演算法原理與實現細節。本書共12 章,各章內容概述如下: 第1 章將詳細介紹Transformer 模型的基本原理,包括自注意力機制、多頭注意力、位置編碼等,為後續章節的理解奠定堅實基礎。 第2~4 章將透過實例深入剖析當前主流的模型。第2 章介紹GPT 模型文字生成的核心原理與實現,包括核心模組、文字生成過程與模型效果評估與調優方法;第3 章介紹BERT 模型的核心實現與訓練,包括模型原理、預訓練任務、模型微調與分類任務;第4 章介紹視覺Transformer 模型的實現,展示其在影像分塊、嵌入及量化分析方面的創新。 第5~10 章將深入探討如何最佳化與微調大模型。第5 章詳細講解了Adapter Tuning、P-Tuning 等微調方法,使模型能夠更進一步地適應不同任務需求;第6~8 章覆蓋資料處理、混合精度與分散式訓練、對比學習和對抗訓練等技術,幫助讀者在有限資源下高效提升模型性能;第9、10 章則專注於最佳化策略,介紹AdamW、LAMB 等自我調整最佳化器和動態學習率排程,並探討知識蒸餾與剪枝技術如何在不犧牲性能的情況下減少計算需求,從而使大模型的應用更加廣泛。 第11、12 章為實戰章節,將透過完整案例展示模型訓練和微調的流程,包括資料準備、分層凍結、超參數調節等關鍵步驟,並介紹量化與蒸餾等推理最佳化方法。 本書的內容設計以實用為導向,每一章都包含完整的程式範例與詳細註釋,以幫助讀者在理解理論的同時進行實際操作。透過一系列實戰案例演示,讀者將掌握如何從零架設一個大規模語言模型,並在不同任務中靈活地應用微調技術。 全書注重理論與實踐的結合,適合希望系統掌握大模型建構、訓練和最佳化的研發人員、大專院校學生,也適合對自然語言處理、電腦視覺等領域的大模型開發有興趣的讀者。還可作為培訓機構和大專院校相關課程的教學用書。 希望本書能幫助讀者深入理解大模型的精髓,並在各自領域中充分發揮其應用價值,共同推動人工智慧的發展。 如果讀者在學習本書的過程中遇到問題,可以發送郵件至booksaga@126.com,郵件主題為「從零建構大模型:演算法、訓練與微調」。 作者 |