




描述
內容簡介
|
作者簡介
| 梁楠 博士
畢業於北京航空航太大學,高級職稱,長期從事模式識別、機器學習、統計理論的研究與應用,負責或參與科研項目多項,專注於人工智慧、大語言模型的應用與開發,對深度學習、資料分析與預測等有獨到見解。 |
目錄
| ▌第一部分 理論基礎
►第1 章 為何需要向量資料庫 1.1 大語言模型的缺陷 1.1.1 高維向量表示中的資訊遺失問題 1.1.2 嵌入空間對語義相似度的誤差影響 1.2 高維資料儲存與檢索的技術瓶頸 1.2.1 高維資料的特性與儲存困難分析 1.2.2 高維空間中的「維度詛咒」問題簡介 1.2.3 高效檢索:索引結構與搜尋演算法簡介 1.3 傳統資料庫與向量資料庫的對比分析 1.3.1 傳統資料庫的設計原理與局限性 1.3.2 高維向量檢索在傳統資料庫中的實現困難 1.3.3 傳統資料庫與向量資料庫的性能對比分析 1.4 向量資料庫的優勢 1.5 本章小結 1.6 思考題
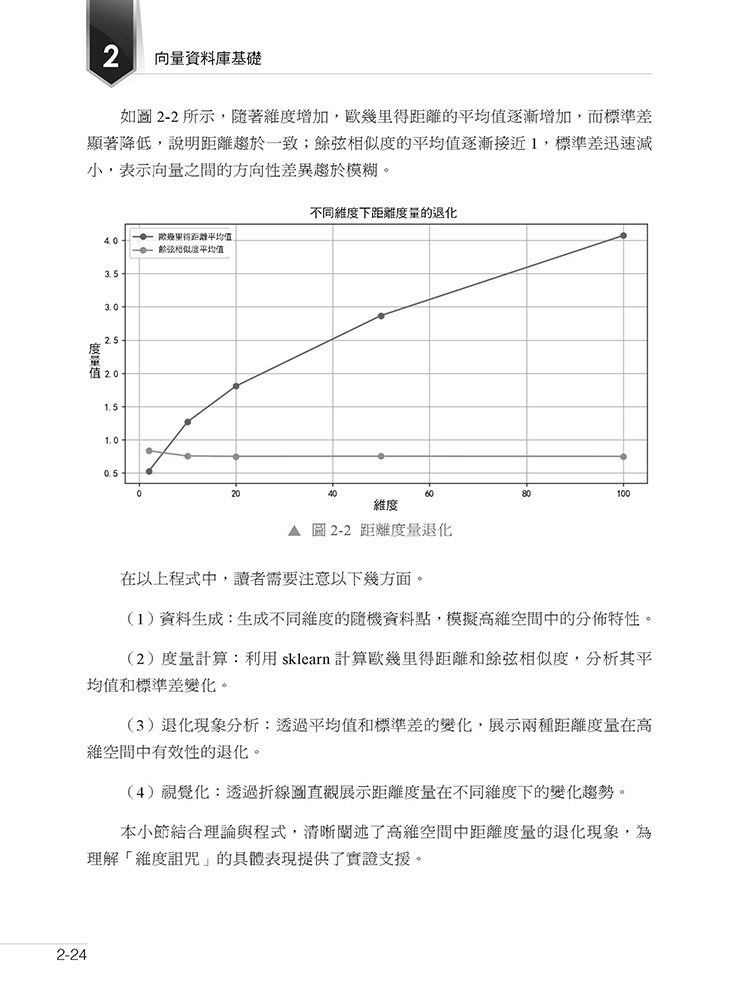
►第2 章 向量資料庫基礎 2.1 向量資料庫的核心概念與基本資料結構 2.1.1 向量資料庫的定義與發展背景 2.1.2 向量資料庫常見的資料結構:倒排索引、圖索引與分區技術 2.1.3 向量資料庫與傳統資料庫邏輯對比 2.2 特徵提取與向量表示:從資料到高維座標系 2.2.1 特徵提取的基本方法 2.2.2 嵌入向量生成 2.2.3 資料前置處理對向量品質的影響 2.3 高維空間特性與「維度詛咒」問題解析 2.3.1 高維空間中的稀疏性與資料分佈特性 2.3.2 距離度量的退化:歐幾里得距離與餘弦相似度 2.3.3 維度詛咒:降維與索引最佳化 2.4 本章小結 2.5 思考題
▌第二部分 核心技術與演算法原理 ►第3 章 向量嵌入 3.1 靜態向量嵌入 3.1.1 傳統詞向量模型:Word2Vec 與GloVe 3.1.2 靜態嵌入的局限性:語義多義性與上下文缺失 3.1.3 靜態向量嵌入在特定領域的應用 3.2 動態向量嵌入 3.2.1 動態詞向量的生成:BERT 與GPT 的嵌入機制 3.2.2 動態嵌入的優勢:上下文敏感性與語義一致性 3.2.3 動態向量嵌入的即時生成與最佳化 3.3 均勻分佈與空間覆蓋率 3.3.1 高維向量分佈分析 3.3.2 嵌入向量的均勻性測量方法 3.3.3 空間覆蓋率對檢索性能的影響 3.4 嵌入向量最佳化 3.4.1 主成分分析與奇異值分解的降維應用 3.4.2 t-SNE 與UMAP 降維技術 3.4.3 降維對嵌入語義保留與性能的權衡分析 3.5 本章小結 3.6 思考題
►第4 章 向量相似性搜尋初步 4.1 基於暴力搜尋的向量相似性檢索 4.1.1 暴力搜尋的原理與實現 4.1.2 暴力搜尋最佳化 4.2 歐幾里得距離與餘弦相似度 4.2.1 距離與相似度的數學定義 4.2.2 不同相似度指標的適用場景分析 4.3 向量搜尋的精度與召回率 4.3.1 精度、召回率與F1 評分的計算方法 4.3.2 向量搜尋性能提升方案 4.4 本章小結 4.5 思考題
►第5 章 分層定位與局部敏感雜湊 5.1 HNSW 的核心原理:圖結構與分層搜尋路徑最佳化 5.1.1 基於圖結構的近鄰搜尋模型 5.1.2 分層搜尋路徑的建構與更新 5.1.3 HNSW 索引時間複雜度分析 5.2 局部敏感雜湊的設計與性能調優 5.2.1 雜湊函式的設計與向量分區原理 5.2.2 LSH 桶化與參數調優 5.2.3 LSH 的記憶體佔用與計算性能分析 5.3 HNSW 與LSH 的具體應用 5.3.1 HNSW 在推薦系統中的應用 5.3.2 LSH 在文字和影像檢索中的應用 5.3.3 HNSW 與LSH 的組合應用:多模態檢索實例 5.4 本章小結 5.5 思考題
►第6 章 LSH 搜尋最佳化 6.1 BallTree 演算法的工作原理 6.1.1 BallTree 的節點分割與索引建構 6.1.2 BallTree 查詢過程與複雜度分析 6.2 Annoy 搜尋演算法 6.2.1 Annoy 的索引結構設計與分區原理 6.2.2 Annoy 在大規模向量檢索中的性能最佳化 6.3 隨機投影在LSH 中的應用 6.3.1 隨機投影的數學基礎 6.3.2 隨機投影在高維資料降維與檢索中的實際應用 6.3.3 隨機投影在人物誌降維與檢索中的應用 6.4 本章小結 6.5 思考題
▌第三部分 工具與系統建構 ►第7 章 相似性測量初步 7.1 從曼哈頓距離到切比雪夫距離 7.1.1 曼哈頓距離的幾何意義與公式推導 7.1.2 切比雪夫距離在棋盤模型中的應用 7.1.3 不同距離度量的適用場景分析 7.2 相似性測量的時間複雜度與最佳化 7.2.1 向量間距離計算的時間複雜度分析 7.2.2 減少距離計算的分區最佳化技術 7.2.3 並行化與硬體加速在相似性測量中的應用 7.2.4 廣告分發系統案例:基於相似性測量的高效推薦 7.3 本章小結 7.4 思考題
►第8 章 測量進階:點積相似度與雅卡爾相似係數 8.1 點積相似度測量 8.1.1 點積相似度測量實現 8.1.2 點積相似度在推薦系統中的應用案例 8.1.3 點積相似度在醫療領域的應用案例:患者治療方案匹配 8.2 雅卡爾相似係數在稀疏向量中的應用 8.2.1 稀疏向量的構造與稀疏性分析 8.2.2 雅卡爾相似係數案例分析 8.2.3 基於雅卡爾相似係數的犯罪嫌犯關係網絡分析 8.3 跨模態醫療資料相似性分析與智慧診斷系統 8.4 本章小結 8.5 思考題
►第9 章 中繼資料過濾與犯罪行為分析系統 9.1 中繼資料與向量檢索 9.1.1 中繼資料在混合檢索中的作用 9.1.2 中繼資料標籤的定義與標準化 9.1.3 智慧多條件推薦系統 9.2 多條件檢索實現 9.2.1 多維度條件組合檢索 9.2.2 基於中繼資料優先順序的排序演算法 9.2.3 基於中繼資料的酒店智慧化推薦案例分析 9.3 中繼資料索引的建構與最佳化 9.3.1 中繼資料索引建構 9.3.2 動態中繼資料的更新與重建 9.4 即時檢索與中繼資料快取 9.4.1 基於快取的高性能檢索架構 9.4.2 中繼資料快取失效與一致性管理 9.5 基於中繼資料的犯罪行為分析與即時預警系統 9.5.1 模組開發劃分 9.5.2 逐模組開發 9.5.3 犯罪分析與預警系統綜合測試 9.6 本章小結 9.7 思考題
►第10 章 FAISS 向量資料庫開發基礎 10.1 FAISS 庫的安裝與快速上手 10.1.1 FAISS 初步開發以及CPU、GPU 的版本差異 10.1.2 載入資料與基本查詢範例 10.2 基於FAISS 的索引建構與參數調整 10.2.1 不同索引類型:Flat、IVF 與HNSW 10.2.2 參數調整對搜尋精度與速度的影響 10.3 大規模向量搜尋的分片與分散式實現 10.3.1 資料分片與動態分片 10.3.2 基於分散式框架的FAISS 部署 10.4 FAISS 中的記憶體最佳化與GPU 加速 10.4.1 壓縮索引與量化技術 10.4.2 多GPU 的並行處理 10.5 本章小結 10.6 思考題
►第11 章 Milvus 向量資料庫開發基礎 11.1 Milvus 的架構設計與功能模組解析 11.1.1 Milvus 的初步使用及叢集架構與元件通訊 11.1.2 資料分區與高可用設計 11.2 使用Milvus 進行向量插入、檢索與過濾 11.2.1 向量資料前置處理與批次插入 11.2.2 複雜查詢準則實現 11.3 Milvus 的索引類型與性能調優 11.3.1 索引類型的選擇與適用場景分析 11.3.2 並行最佳化與索引更新 11.4 Milvus 在企業級應用中的部署與擴充方案 11.4.1 基於容器化的高可用部署 11.4.2 動態擴充與監控整合方案 11.5 本章小結 11.6 思考題
▌第四部分 實戰與案例分析 ►第12 章 基於FAISS 的自動駕駛泊車資料檢索系統 12.1 項目背景介紹 12.1.1 系統架構 12.1.2 應用流程 12.1.3 案例特色 12.2 模組劃分 12.3 模組化開發 12.3.1 資料前置處理模組 12.3.2 向量生成模組 12.3.3 索引建構與儲存模組 12.3.4 即時檢索模組 12.3.5 動態更新模組 12.3.6 系統監控與最佳化模組 12.4 系統綜合測試 12.5 API 介面開發與雲端部署 12.5.1 API 介面開發 12.5.2 雲端部署完整系統 12.6 本章小結 12.7 思考題
►第13 章 基於語義搜尋的向量資料庫開發實戰 13.1 語義嵌入生成與最佳化 13.1.1 使用預訓練模型生成語義向量嵌入 13.1.2 動態分詞與文字前置處理 13.1.3 領域微調技術 13.2 建構向量索引與語義檢索框架 13.2.1 選擇合適的向量索引類型 13.2.2 建構Milvus 向量索引 13.2.3 語義向量檢索與關鍵字過濾 13.2.4 結合中繼資料與篩選條件實現多維度語義搜尋 13.3 語義搜尋系統的性能調優 13.3.1 GPU 加速最佳化檢索 13.3.2 批次查詢與非同步IO 技術 13.3.3 實現基於分散式架構的語義搜尋系統 13.4 企業級語義搜尋應用整合與部署 13.4.1 建構語義搜尋RESTful 介面 13.4.2 使用Docker 與Kubernetes 實現語義搜尋系統的容器化 13.4.3 日誌監控與錯誤診斷模組 13.4.4 基於語義搜尋的文件檢索系統集成與部署 13.4.5 大型圖書館圖書檢索的測試案例 13.5 本章小結 13.6 思考題 |
序
| 前言
隨著人工智慧和巨量資料技術的迅猛發展,高維向量嵌入已成為現代資訊處理的核心技術之一,被廣泛應用於文字檢索、語義搜索、推薦系統等許多領域。然而,面對資料規模的爆炸式增長和資料複雜性的不斷提升,傳統資料庫在處理高維資料的儲存與檢索時逐漸暴露出顯著的性能瓶頸。作為針對高維向量儲存和檢索最佳化而設計的專用工具,向量資料庫憑藉其高效性和靈活性,正日益成為解決這一技術難題的關鍵方案。 本書以向量資料庫為核心,從理論基礎到實際應用,系統整理了這一技術的全貌。本書分為4 個部分,內容循序漸進,理論與實踐並重,幫助讀者全面掌握向量資料庫的技術精髓及應用技巧。 第1 部分:理論基礎。涵蓋第1、2 章,主要專注向量資料庫的理論背景與技術必要性。從高維向量的稀疏性問題、距離度量失效等現象出發,系統分析了傳統資料庫的局限性,並深入探討了向量資料庫在解決高維資料儲存與檢索中的獨特優勢。這部分內容奠定了讀者對向量資料庫核心概念和關鍵技術的理解基礎。 第2 部分:核心技術與演算法原理。涵蓋第3~6 章,全面講解了向量嵌入的原理、相似性度量方法以及高效搜索的核心演算法。本部分從靜態與動態向量嵌入出發,結合具體的距離度量方式,逐步引入諸如HNSW、局部敏感雜湊(LSH)等高效搜索演算法,並補充了BallTree 與Annoy 等演算法的適用場景與實現細節。透過這部分內容,讀者將深入掌握向量資料庫的核心技術鏈條。 第3 部分:工具與系統建構。涵蓋第7~11 章,重點介紹了FAISS 與Milvu 兩大主流向量資料庫工具的功能與最佳化方法。本部分詳細講解了如何建構索引、最佳化性能以及實現分散式系統,同時結合中繼資料過濾與相似性測量,探討了工具在複雜應用場景中的實際操作方法。這部分為從事開發與部署的技術人員提供了實用的指南。 第4 部分:實戰與案例分析。涵蓋第12、13 章,專注向量資料庫的實際應用案例。透過自動駕駛泊車資料檢索系統的完整開發流程,展示向量資料庫的模組化設計與雲端部署能力。此外,本部分深入解析基於語義搜索的開發實戰,涵蓋從語義嵌入生成到企業級語義搜索系統部署的全過程。這部分內容將理論與實踐高度結合,為讀者提供了真實場景的實施指導。 在理論與實踐並重的基礎上,本書還透過豐富的程式範例與詳細的案例剖析,展示了向量資料庫在推薦系統、行為分析和文件檢索等領域的廣泛應用價值。同時針對高性能需求,書中深入解析了GPU 加速、分散式架構與容器化部署等關鍵技術,幫助讀者掌握建構高效、可擴充系統的技能。 本書適合從事搜索系統與推薦引擎開發的工程師,希望深入理解高維向量檢索技術的研究人員,資料科學、人工智慧從業人員,以及培訓機構和大專院校相關專業的師生。 向量資料庫是技術與應用結合的典範,其發展不僅推動了人工智慧和巨量資料領域的前端研究,也為多個行業的數位化轉型注入了全新的動力。希望本書能為讀者提供理解這一技術的全新角度,助力其在實際開發中發揮更大的價值,為推動技術與應用的融合貢獻力量。 如果在學習本書的過程中發現問題或有疑問,可發送郵件至booksaga@126.com,郵件主題為「向量資料庫:大模型驅動的智慧檢索與應用」。 作者 |