





描述
本書特色、內容簡介
這是一本使用Python從零開始指導讀者的網路爬蟲入門書籍,全書以約350個程式實例,完整解說大數據擷取、清洗、儲存與分析相關知識,下列是本書有關網路爬蟲知識的主要內容。
# 認識搜尋引擎與網路爬蟲
# 認識約定成俗的協議robots.txt
# 從零開始解析HTML網頁
# 認識與使用Chrome開發人員環境解析網頁
# 認識Python內建urllib、urllib2模組,同時介紹好用的requests模組
# 說明lxml模組
# Selenium模組
# XPath方法解說
# css定位網頁元素
# Cookie觀念
# 自動填寫表單
# 使用IP代理服務與實作
# 偵測IP
# 更進一步解說更新的模組Requests-HTML
# 認識適用大型爬蟲框架的Scrapy模組
在書籍內容,本書設計爬蟲程式探索下列相關網站,讀者可以由不同的網站主題,深入測試自己設計網路爬蟲的能力,以適應未來職場的需求。
# 金融資訊
# 股市數據
# 人力銀行
# 交友網站
# 維基網站
# 主流媒體網站
# 政府開放數據網站
# 社群服務網站
# PTT網站
# 電影網站
# 星座網站
# 小說網站
# 台灣高鐵
# 露天拍賣網站
# httpbin網站
# python.org網站
# github.com網站
# ipstack.com網站API實作
# Google API實作
# Facebook API實作
探索網站成功後,本書也說明下列如何下載或儲存不同資料格式的數據。
# CSV檔案格式
# JSON檔案格式
# XML、Pickle
# Excel
# SQLite資料庫
本書沿襲作者著作的特色,程式實例豐富,相信讀者只要遵循本書內容必定可以在最短時間精通Python網路爬蟲設計。
作者簡介
洪錦魁
一位跨越電腦作業系統與科技時代的電腦專家,著作等身的作家。
■ DOS 時代他的代表作品是 IBM PC 組合語言、C、C++、Pascal、資料結構。
■ Windows 時代他的代表作品是 Windows Programming 使用 C、Visual Basic。
■ Internet 時代他的代表作品是網頁設計使用 HTML。
■ 大數據時代他的代表作品是 R 語言邁向 Big Data 之路。
除了作品被翻譯為簡體中文、馬來西亞文外,2000 年作品更被翻譯為Mastering HTML 英文版行銷美國。
近年來作品則是在北京清華大學和台灣深智同步發行:
1:Java 入門邁向高手之路王者歸來
2:Python 入門邁向高手之路王者歸來
3:HTML5 + CSS3 王者歸來
4:R 語言邁向Big Data 之路
他的著作最大的特色是,所有程式語法會依特性分類,同時以實用的程式範例做解說,讓整本書淺顯易懂,讀者可以由他的著作事半功倍輕鬆掌握相關知識。
序
這是一本使用Python從零開始指導讀者的網路爬蟲入門書籍,全書以約350個程式實例,完整解說大數據擷取、清洗、儲存與分析相關知識。
在Internet時代,所有數據皆在網路呈現,從網路獲得資訊已經成為我們日常生活的一部份。然而如何從網路上獲得隱性的數據資訊,更進一步將此數據資訊做擷取、清洗、儲存與分析的有效應用,已經是資訊科學非常重要的領域,目前國內作者這方面著作不多,同時內容單薄,這也是筆者撰寫本書的動力。本書保持筆者一貫特色,實例豐富,容易學習,有系統的一步一步引導讀者深入不同網站主題,進行探索,下列是本書有關網路爬蟲知識的主要內容。
- 認識搜尋引擎與網路爬蟲
- 認識約定成俗的協議robots.txt
- 從零開始解析HTML網頁
- 認識與使用Chrome開發人員環境解析網頁
- 認識Python內建urllib、urllib2模組,同時介紹好用的requests模組
- 說明lxml模組
- Selenium模組
- XPath方法解說
- css定位網頁元素
- Cookie觀念
- 自動填寫表單
- 使用IP代理服務與實作
- 偵測IP
- 更進一步解說更新的模組Requests-HTML
- 認識適用大型爬蟲框架的Scrapy模組
在書籍內容,筆者設計爬蟲程式探索下列相關網站。
- 金融資訊
- 股市數據
- 人力銀行
- 交友網站
- 維基網站
- 主流媒體網站
- 政府開放數據網站
- 社群服務網站
- PTT網站
- 電影網站
- 星座網站
- 小說網站
- 台灣高鐵
- 露天拍賣網站
- httpbin網站
- python.org網站
- github.com網站
- ipstack.com網站API實作
- Google API實作
- Facebook API實作
探索網站成功後,筆者也說明下列如何下載或儲存不同資料格式的數據。
- CSV檔案格式
- JSON檔案格式
- XML、Pickle
- Excel
- SQLite
在設計爬蟲階段我們可能會碰上一些技術問題,筆者也以實例解決下列相關問題。
- URL編碼與中文網址觀念
- 將中文儲存在JSON格式檔案
- 亂碼處理
- 簡體中文在繁體中文Windows環境資料下載與儲存
- 解析Ajax動態加載網頁,獲得更多頁次資料
- 使用Chromium瀏覽器協助Ajax動態加載
註:讀者需了解網路爬蟲是針對特定網站擷取特定資料,本書所有程式雖經測試,在撰寫當下是正確,筆者同時列出執行結果。但是,如果網站結構改變,可能造成程式失效。
寫過許多的電腦書著作,本書沿襲筆者著作的特色,程式實例豐富,相信讀者只要遵循本書內容必定可以在最短時間精通Python網路爬蟲設計,編著本書雖力求完美,但是學經歷不足,謬誤難免,尚祈讀者不吝指正。
洪錦魁2019-10-15
jiinkwei@me.com
圖書資源說明
本書籍的所有程式實例可以在深智公司網站下載。
目錄
第零章 認識網路爬蟲
0-1 認識HTML
0-2 網路地址URL
0-3 爬蟲的類型
0-4 搜尋引擎與爬蟲原理
0-5 網路爬蟲的搜尋方法
0-6 網路爬蟲是否合法
0-7 認識HTTP 與HTTPS
0-8 表頭(headers)
第一章 JSON 資料與繪製世界地圖
1-1 JSON 資料格式前言
1-2 認識json 資料格式
1-3 將Python 應用在json 字串形式資料
1-4 將Python 應用在json 檔案
1-5 簡單的json 檔案應用
1-6 世界人口數據的json 檔案
1-7 繪製世界地圖
1-8 XML
第二章 使用Python 處理CSV 文件
2-1 建立一個CSV 文件
2-2 用記事本開啟CSV 檔案
2-3 csv 模組
2-4 讀取CSV 檔案
2-5 寫入CSV 檔案
2-6 專題- 使用CSV 檔案繪製氣象圖表
2-7 pickle 模組
2-8 Python 與Microsoft Excel
第三章 網路爬蟲基礎實作
3-1 上網不再需要瀏覽器了
3-2 下載網頁資訊使用requests 模組
3-3 檢視網頁原始檔
3-4 分析網站使用Chrome 開發人員工具
3-5 下載網頁資訊使用urllib 模組
3-6 認識httpbin 網站
3-7 認識Cookie
3-8 設置代理IP
第四章 Pandas 模組
4-1 Series
4-2 DataFrame
4-3 基本Pandas 資料分析與處理
4-4 檔案的輸入與輸出
4-5 Pandas 繪圖
4-6 時間序列(Time Series)
4-7 專題 鳶尾花
4-8 專題 匯入網頁表格資料
第五章 Beautiful Soup 解析網頁
5-1 解析網頁使用BeautifulSoup 模組
5-2 其它HTML 文件解析
5-3 網路爬蟲實戰 圖片下載
5-4 網路爬蟲實戰 找出台灣彩券公司最新一期威力彩開獎結果
5-5 網路爬蟲實戰 列出Yahoo 焦點新聞標題和超連結
5-6 IP 偵測網站FileFab
第六章 網頁自動化
6-1 hashlib 模組
6-2 環保署空氣品質JSON 檔案實作
6-3 檢測網站內容是否更新
6-4 工作排程與自動執行
6-5 環保署空氣品質的CSV 檔案
第七章 Selenium 網路爬蟲的王者
7-1 順利使用Selenium 工具前的安裝工作
7-2 獲得webdriver 的物件型態
7-3 擷取網頁
7-4 尋找HTML 文件的元素
7-5 XPath 語法
7-6 用Python 控制點選超連結
7-7 用Python 填寫表單和送出
7-8 用Python 處理使用網頁的特殊按鍵
7-9 用Python 處理瀏覽器運作
7-10 自動進入Google 系統
7-11 自動化下載環保署空氣品質資料
第八章 PTT 爬蟲實戰
8-1 認識批踢踢實業坊
8-2 進入PTT 網址
8-3 解析PTT 進入須滿18 歲功能鈕
8-4 各篇文章的解析
8-5 解析文章標題與作者
8-6 推文數量
8-7 文章發表日期
8-8 將PTT 目前頁面內容以JSON 檔案儲存
8-9 前一頁面處理的說明
8-10 進入PPT 的Beauty 論壇網站
8-11 ipstack
第九章 Yahoo 奇摩電影網站
9-1 本週新片
9-2 中文片名和英文片名
9-3 上映日期
9-4 期待度
9-5 影片摘要
9-6 劇照海報
9-7 爬取兄弟節點
9-8 預告片
9-9 排行榜
第十章 台灣主流媒體網站
10-1 蘋果日報
10-2 聯合報
10-3 經濟日報
10-4 中國時報
10-5 工商時報
第十一章 Python 與SQLite 資料庫
11-1 SQLite 基本觀念
11-2 資料庫連線
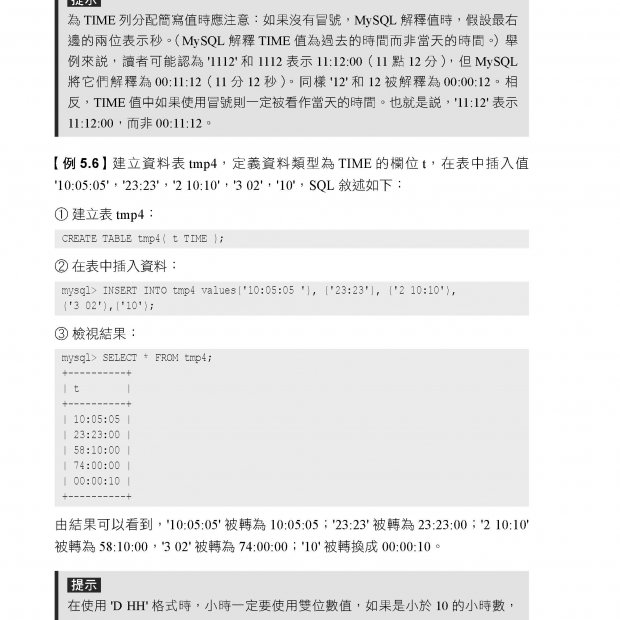
11-3 SQLite 資料類型
11-4 建立SQLite 資料庫表單
11-5 增加SQLite 資料庫表單紀錄
11-6 查詢SQLite 資料庫表單
11-7 更新SQLite 資料庫表單紀錄
11-8 刪除SQLite 資料庫表單紀錄
11-9 DB Browser for SQLite
11-10 將台北人口數儲存SQLite 資料庫
第十二章 股市數據爬取與分析
12-1 證券櫃檯買賣中心
12-2 台灣證券交易所
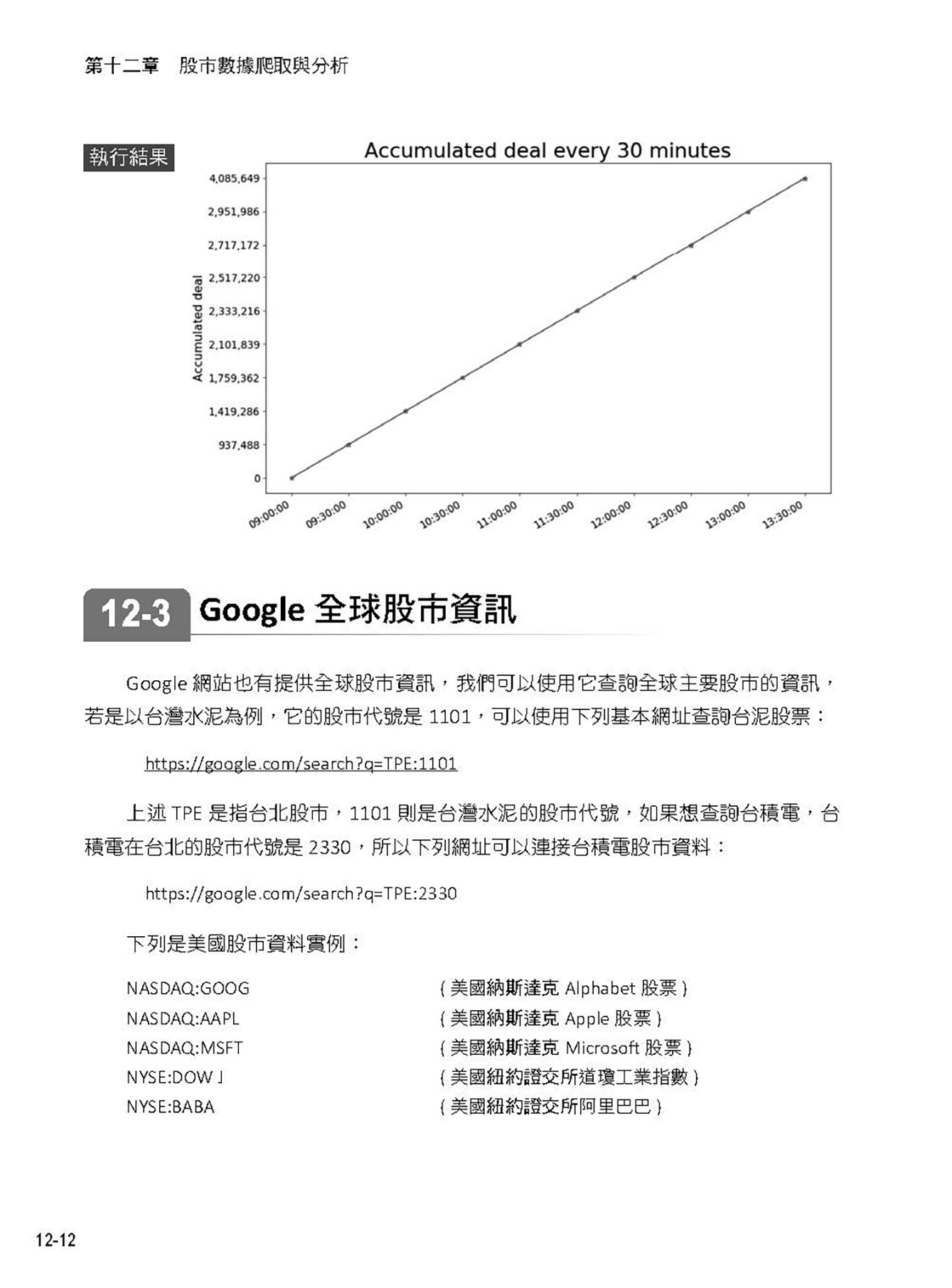
12-3 Google 全球股市資訊
12-4 Yahoo 股市資訊
12-5 台灣股市資料讀取與圖表製作
第十三章 金融資訊的應用
13-1 台灣銀行利率查詢
13-2 取得HTML 文件
13-3 分析HTML 文件
13-4 將利率表儲存成CSV 檔案
13-5 取得最優惠利率
13-6 基金資料
第十四章 Dcard 社群服務網站
14-1 進入網站
14-2 分析網站
14-3 抓取預設的熱門貼文
14-4 爬取更多Dcard 熱門文章
第十五章 星座屋網站
15-1 進入星座屋網站
15-2 分析網站與爬取星座運勢文字
15-3 星座圖片的下載
第十六章 小說網站
16-1 進入小說網站
16-2 解析網頁
16-3 處理編碼問題
16-4 爬取書籍章節標題
16-5 爬取章節內容的連結
16-6 從章節超連結輸出小說內容
16-7 將小說內文存入檔案
第十七章 台灣高鐵網站
17-1 查詢台灣高鐵的站名
17-2 時刻表查詢
第十八章 維基百科
18-1 維基百科的中文網址
18-2 爬取台積電主文資料
18-3 台積電的簡史
18-4 URL 編碼
第十九章 Python 與Facebook
19-1 Facebook 圖形API
19-2 facebook-sdk 存取資料的應用
第二十章 Google API
20-1 申請Google API 金鑰
20-2 基本操作Google Map
20-3 爬蟲擷取Google 地理資訊
20-4 地理資訊的基本應用
20-5 找尋指定區域內的景點
第二十一章 Yahoo 拍賣網站
21-1 Yahoo 拍賣網站
21-2 分析網頁與單個商品搜尋
21-3 系列商品搜尋
第二十二章 Hotels.com 旅宿網站
22-1 Hotels.com 旅宿網站
22-2 解析輸入表單
22-3 獲得查詢資料
22-4 列出一系列所找到的旅館
第二十三章 交友網站
23-1 進入交友網站
23-2 分析網頁
23-3 爬取第一筆資料
23-4 將爬取的資料儲存至CSV 檔案
23-5 爬取與儲存Ajax 加載的頁面
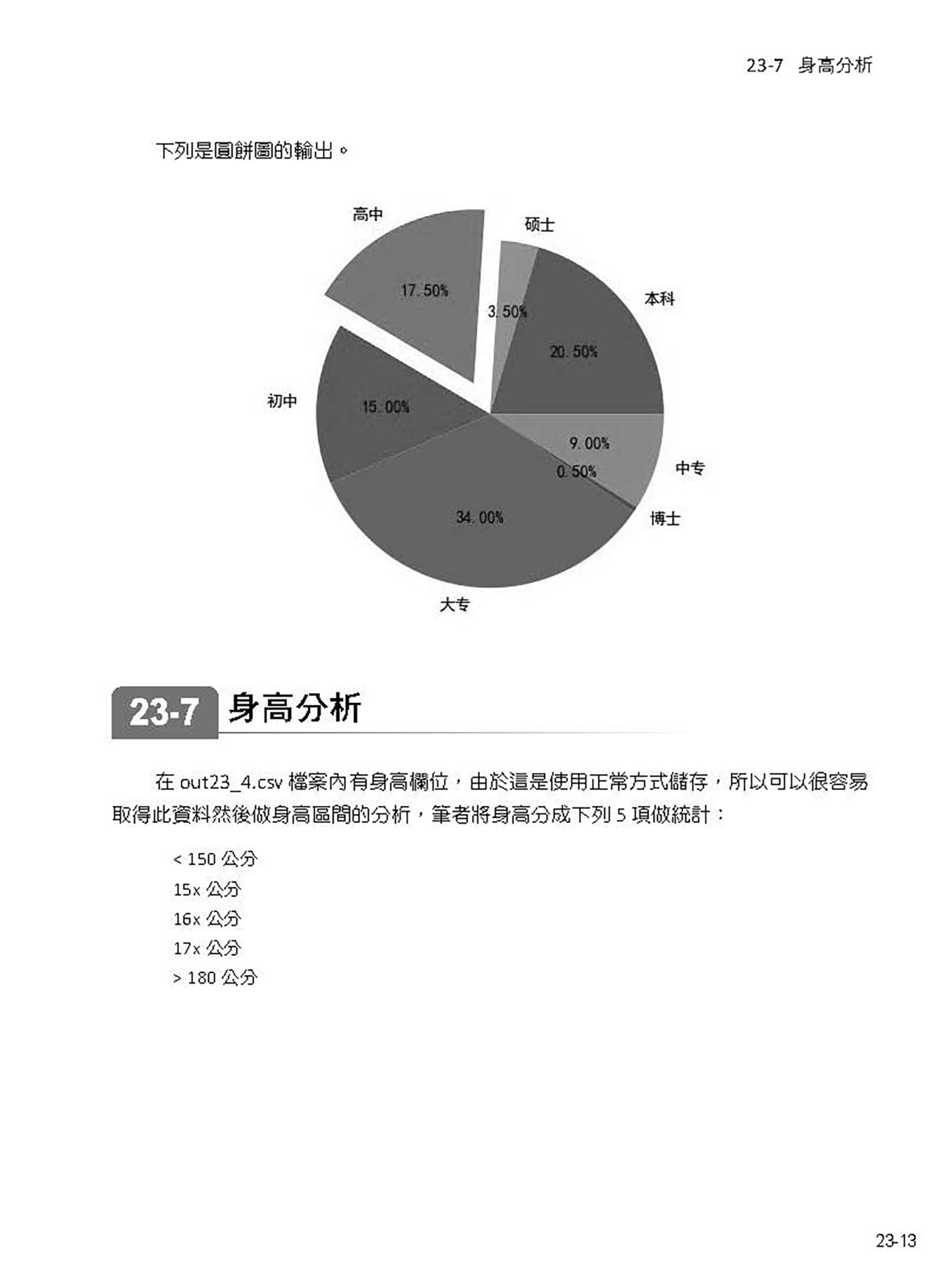
23-6 教育程度分析
23-7 身高分析
23-8 年齡分析
第二十四章 Requests-HTML 模組
24-1 安裝與導入
24-2 使用者請求Session
24-3 認識回傳資料型態與幾個重要屬性
24-4 數據清洗與爬取
24-5 搜尋豆瓣電影網站
24-6 Ajax 動態數據加載
第二十五章 人力銀行網站
25-1 認識人力銀行網頁
25-2 分析與設計簡單的爬蟲程式
25-3 更進一步分析網頁
第二十六章 Scrapy
26-1 安裝Scrapy
26-2 從簡單的實例開始 - 建立Scrapy 專案
26-3 Scrapy 定位元素
26-4 使用cookie 登入
26-5 保存文件為JSON 和CSV 檔案
26-6 Scrapy 架構圖
26-7 專題爬取多頁PTT 資料