









描述
本書特色
- 趣味啟動
大部分的程式設計類圖書,在內容上基本都是直奔主題。但是尼采曾說過:「人們無法了解他沒有經歷過的事情。」換句話說,我們只接受過去早已了解的事物相關的資訊。這是一種比較學習過程,在這個過程中,大腦尋找每筆資訊之間的聯繫。所以教育專家普遍認為,吸引學生的注意力,比較好的辦法是用他們熟知的知識開始。
因此在本書中,我會用一個故事、一個趣味題目、一部電影的介紹等形式來作為每一章甚至很多小節的開頭,選擇的內容也多多少少與要講的主題內容相關。這並不是多餘,而是有意為之。事實上,這樣的形式在我之前出版的圖書中已經獲得了普遍認可。
- 圖文並茂
西方有句諺語,"A picture is worth a thousand words.(一圖值千言)"。用上千個字描述不明白的東西,很可能一張圖就能解釋清楚。
我非常認可這個觀點,所以本書雖沒有達到每一頁都有圖,但基本做到了絕大部分說明都有相關圖示,關鍵演算法更是透過多圖逐步分解剖析。儘管這帶來了寫作上的難度,但卻可以達到較好的效果。畢竟,讀者透過本書開始學習資料結構時,要從一無所知或略知一二到完全了解,甚至掌握應用,是一個比較艱苦的過程,用大量的圖示可以減少這個過程的長度。
- 程式詳解
我在寫作中儘量摒棄了傳統資料結構教材的「重理論思維而輕程式說明」的作法。在準備資料結構寫作時我發現,很多教材對資料結構理論和演算法設計思維講得比較好,可一到實際程式時,有的把程式貼出來加少量註釋,有的直接用虛擬程式碼形式。這對於上課的學生還好,畢竟有老師在課堂中去詳解程式撰寫原理,可是對於初學資料結構和演算法的自學者而言,如果書中不去解釋程式某些細節為什麼那樣撰寫的原因,甚至程式根本不可能在某個編譯器中執行通過,其挫折感是很強烈的。例如即使了解了圖結構中的最短路徑求解原理,也可能無法寫出最短路徑的演算法。
我把程式在執行過程中變數的變化融入到整個演算法設計思維的說明中,配合對應的示意圖,會幫助大家更加容易了解演算法的實質。這種說明模式在本書的第6、7、8、9 章的很多複雜演算法中有實際表現,越是複雜的程式越是說明細緻。這算是本書的特色,希望對讀者有幫助。
- 形式新穎
我把本書的內容虛構成一個老師上課的場景,所有內容都透過這位老師表達出來,書中的文字非常口語化,這樣做的目的是為了更加直觀地讓讀者感覺,自己是在學習,是在上課。有人可能會說,現在的課堂大都是讓人昏昏欲睡,把讀者帶入上課場景,不是更加讓讀者疲累嗎?我覺得如果你的學習經歷中聽過一些優秀老師的課,你就不會下這樣的結論。好的老師講課,是可以做到引人入勝的。有人可能會問,我為什麼不用《大話設計模式》中的對話形式,而採用講課形式呢?這是對資料結構這門學問的特點考慮的。設計模式主要都是思維表現,通常會見仁見智,用對話展開比較容易;而資料結構中更多的是定義、術語、經典演算法等,這些公認的知識,可討論的地方並不多,更多的是需要把它講清楚。讓兩個人在一起討論某個設計模式的優缺點,會非常合適,而討論資料結構定義的好壞,就沒有太大意義了,不如讓一個老師告訴學生資料結構的定義好在哪裡更符合實際。因此用傳統的講課形式會好一些。
本書沒有習題,有思考的題目也一定會列出某種答案。但本書每個複雜基礎知識的尾端,都會提供另一本書的進一步閱讀建議。這也是以本書是一本自學讀物為基礎的原則。讀者閱讀本書可能是任何時間任何地方,如果書中存在沒有解答的習題,碰到了困難是無法及時找到老師來幫助的,因此本書儘量避免讓讀者有這樣的困惑存在。對於需要練習的同學,應該考慮再去買本習題集來學習。學習資料結構和演算法,做題和上機寫程式非常有必要,從這個角度也說明,閱讀完本書其實也只是完成入門而已。
本書既然是以老師上課的形式來進行,那就免不了要融入一名教師除了授業解惑以外,還要傳達一些個人價值觀的表現。書中很多細微處,如對某位科學家的尊敬、對某個演算法的推崇、對勤奮勵志故事的說明等都在表達著一個老師向學生傳遞真、善、美的意願。我始終認為,讀者拿到的雖然只是一本沒有表情、不會說話的書,但其實也是在隔空與另一個朋友交流。人與人的交流不可能只是就事論事,一定會有情感的溝通,這種情感如果能產生共鳴、達成互信,就會讓事情(例如學習資料結構與演算法這件事)本身更容易了解和接受。
本書內容
主要包含:資料結構介紹,演算法推導大O 階的方法,線性串列結構的介紹,循序結構與鏈式結構差異,堆疊與佇列的應用,串的樸素模式比對、KMP 模式比對演算法,樹結構的介紹,二元樹前中後序檢查,線索二元樹,霍夫曼樹及應用,圖結構的介紹,圖的深度、廣度檢查,最小產生樹兩種演算法,最短路徑兩種演算法,拓撲排序與關鍵路徑演算法,尋找應用的相關介紹,折半尋找、內插尋找、費氏尋找等靜態尋找,密集索引、分段索引、倒排索引等索引技術,二元排序樹、平衡二元樹等動態尋找,二元樹、B+ 樹技術,雜湊表
技術,排序應用的相關介紹,上浮、選擇、插入等簡單排序,希爾、堆積、歸併、快速等改進排序,各位排序演算法的比較等。
作者簡介
程 杰
被讀者譽為很會寫IT技術書的專家,開創一種趣味講解IT知識的風格與模式。
參與過政府、證券、遊戲、交通等多種行業的軟體發展及專案管理工作,也擔任過軟體工程師培訓的教師,目前從事教育類APP/微信小程式的開發與運營。
高中數學教學的獨特經歷,所以著作中處處以初學者視角思考和分析問題,成為當前極受歡迎的IT技術書作者。
目錄
前言
01 資料結構緒論
1.1 開場白
1.2 你資料結構怎麼學的?
1.3 資料結構起源
1.4 基本概念和術語
1.5 邏輯結構與物理結構
1.6 資料類型
1.7 歸納回顧
1.8 結尾語
02 演算法
2.1 開場白
2.2 資料結構與演算法關係
2.3 兩種演算法的比較
2.4 演算法定義
2.5 演算法的特性
2.6 演算法設計的要求
2.7 演算法效率的度量方法
2.8 函數的漸近增長
2.9 演算法時間複雜度
2.10 常見的時間複雜度
2.11 最壞情況與平均情況
2.12 演算法空間複雜度
2.13 歸納回顧
2.14 結尾語
03 線性串列
3.1 開場白
3.2 線性串列的定義
3.3 線性串列的抽象資料類型
3.4 線性串列的循序儲存結構
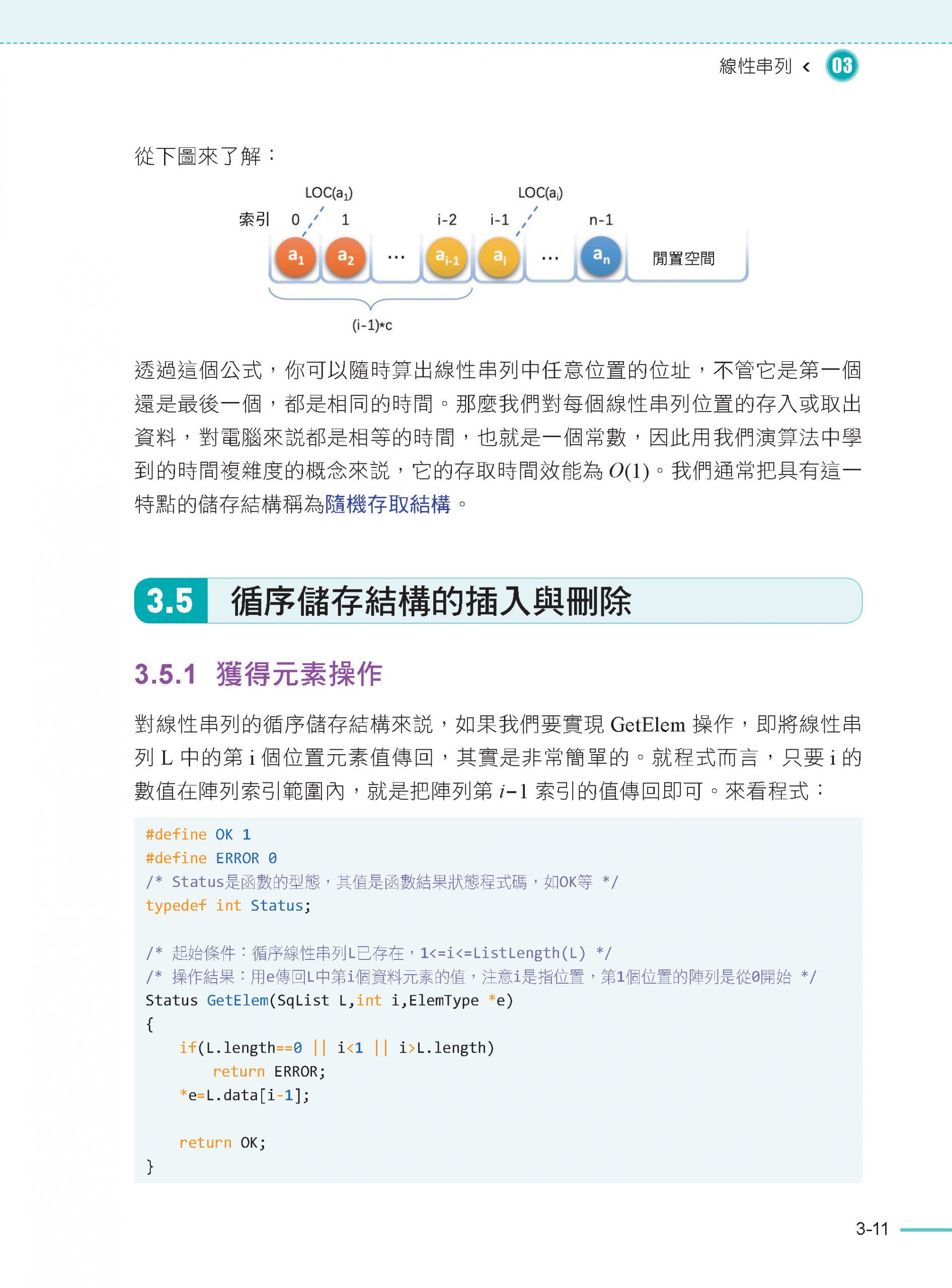
3.5 循序儲存結構的插入與刪除
3.6 線性串列的鏈式儲存結構
3.7 單鏈結串列的讀取
3.8 單鏈結串列的插入與刪除
3.9 單鏈結串列的整串列建立
3.10 單鏈結串列的整個串列刪除
3.11 單鏈結串列結構與循序儲存結構優缺點
3.12 靜態鏈結串列
3.13 循環鏈結串列
3.14 雙向鏈結串列
3.15 歸納回顧
3.16 結尾語
04 堆疊與佇列
4.1 開場白
4.2 堆疊的定義
4.3 堆疊的抽象資料類型
4.4 堆疊的循序儲存結構及實現
4.5 兩堆疊共用空間
4.6 堆疊的鏈式儲存結構及實現
4.7 堆疊的作用
4.8 堆疊的應用—遞迴
4.9 堆疊的應用—四則運算運算式求值
4.10 佇列的定義
4.11 佇列的抽象資料類型
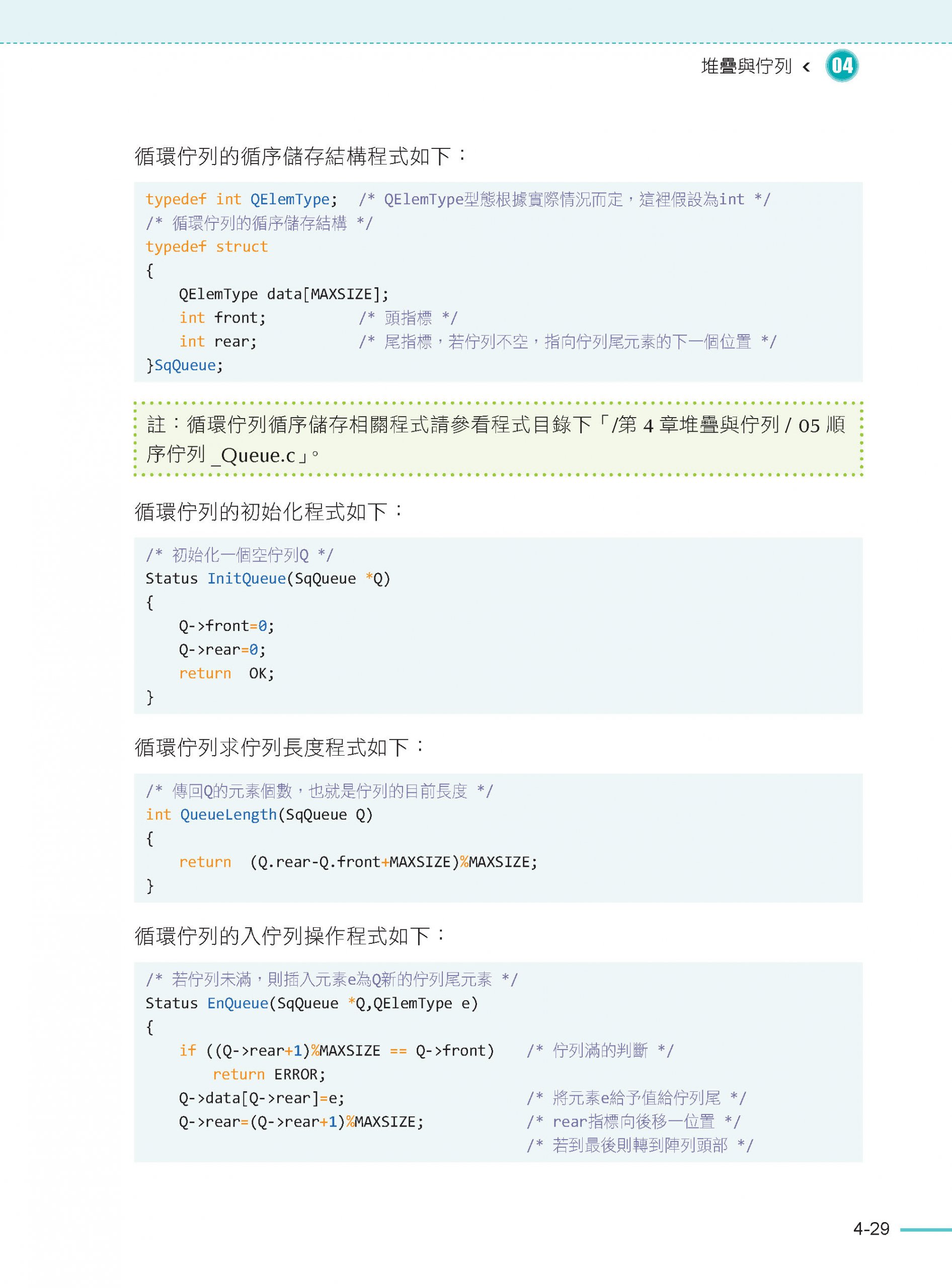
4.12 循環佇列
4.13 佇列的鏈式儲存結構及實現
4.14 歸納回顧
4.15 結尾語
05 字串
5.1 開場白
5.2 字串的定義
5.3 字串的比較
5.4 字串的抽象資料類型
5.5 字串的儲存結構
5.6 樸素的模式比對演算法
5.7 KMP 模式比對演算法
5.8 歸納回顧
5.9 結尾語
06 樹
6.1 開場白
6.2 樹的定義
6.3 樹的抽象資料類型
6.4 樹的儲存結構
6.5 二元樹的定義
6.6 二元樹的性質
6.7 二元樹的儲存結構
6.8 檢查二元樹
6.9 二元樹的建立
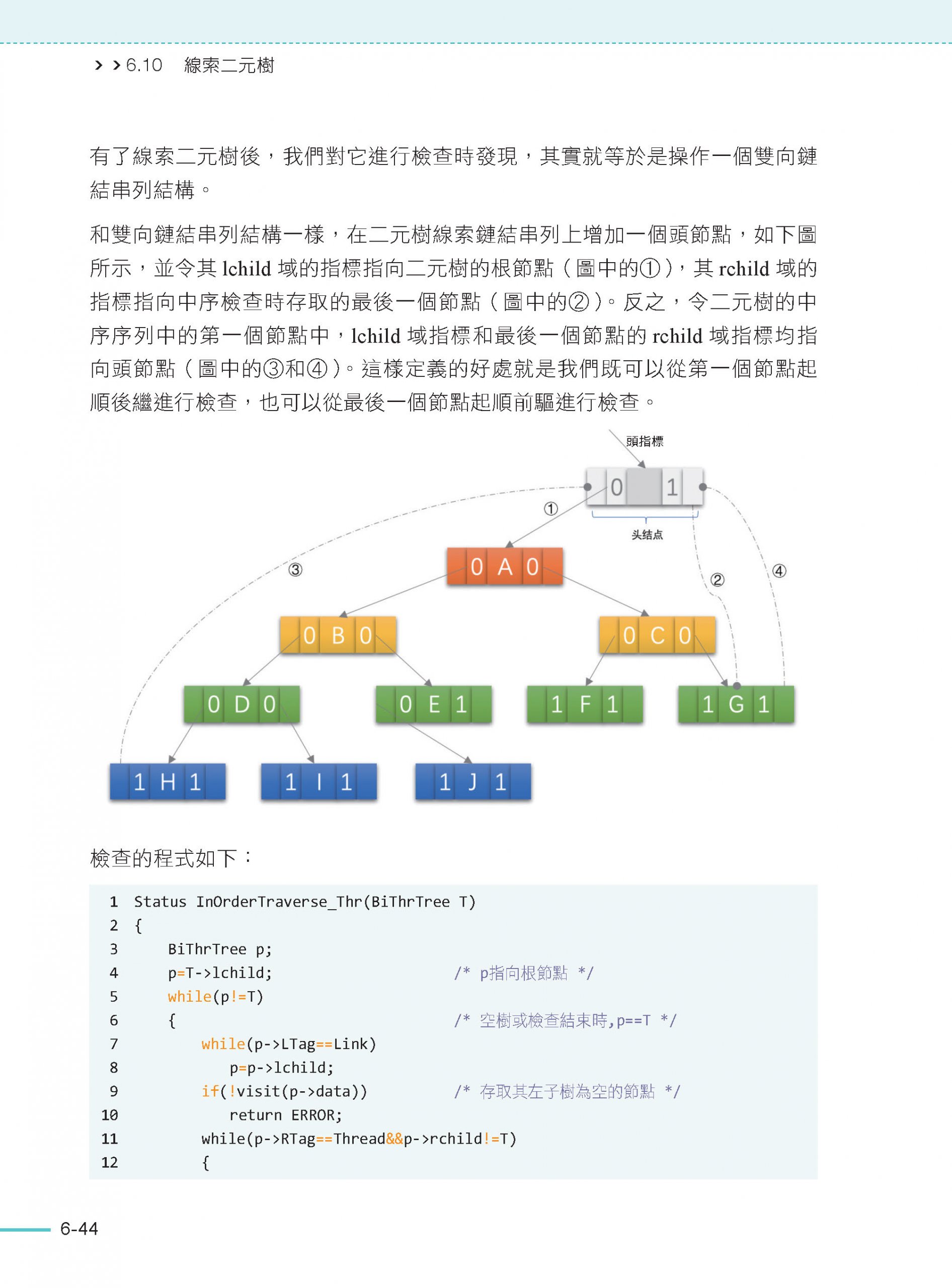
6.10 線索二元樹
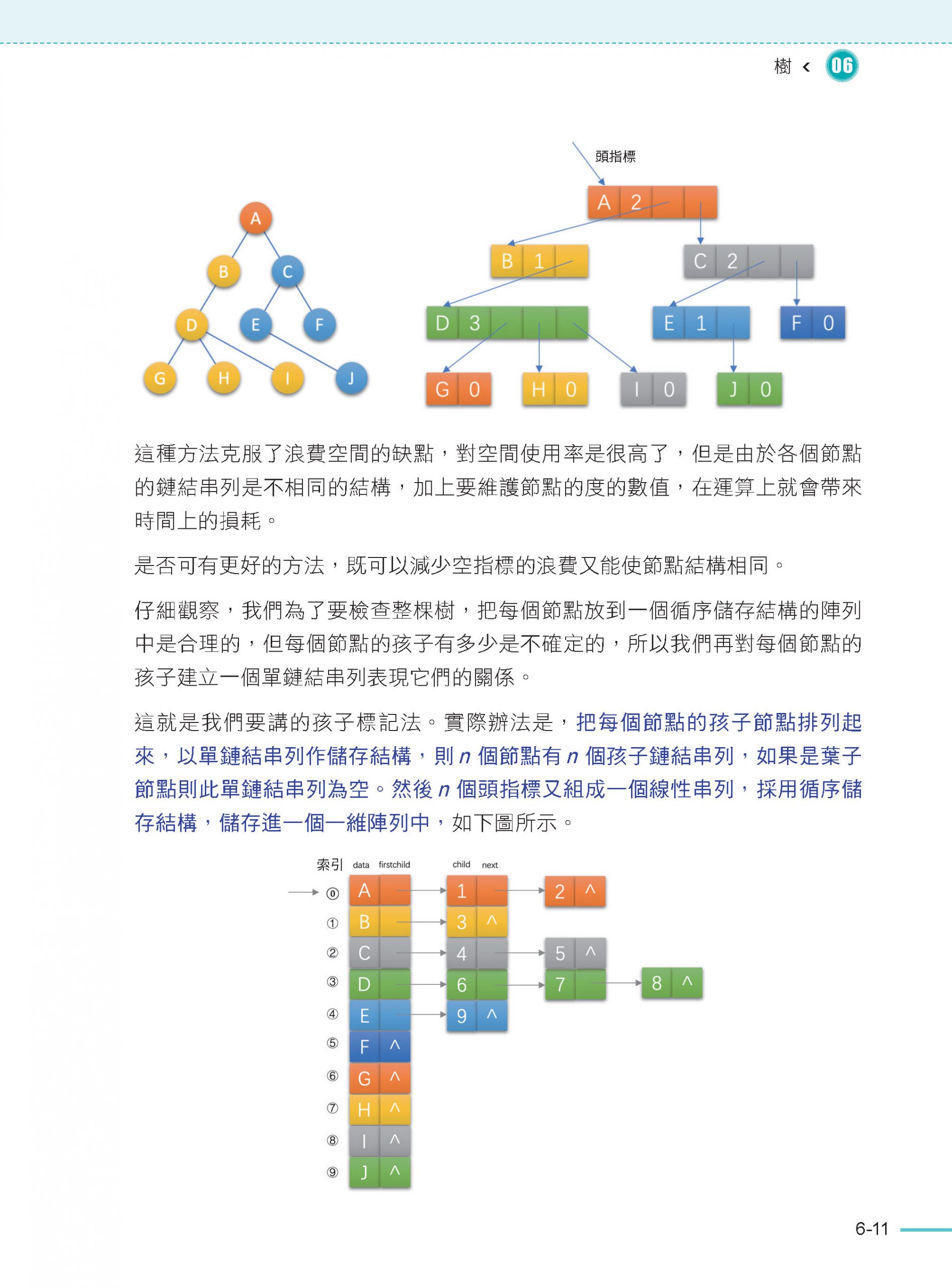
6.11 樹、森林與二元樹的轉換
6.12 霍夫曼樹及其應用
6.13 歸納回顧
6.14 結尾語
07 圖
7.1 開場白
7.2 圖的定義
7.3 圖的抽象資料類型
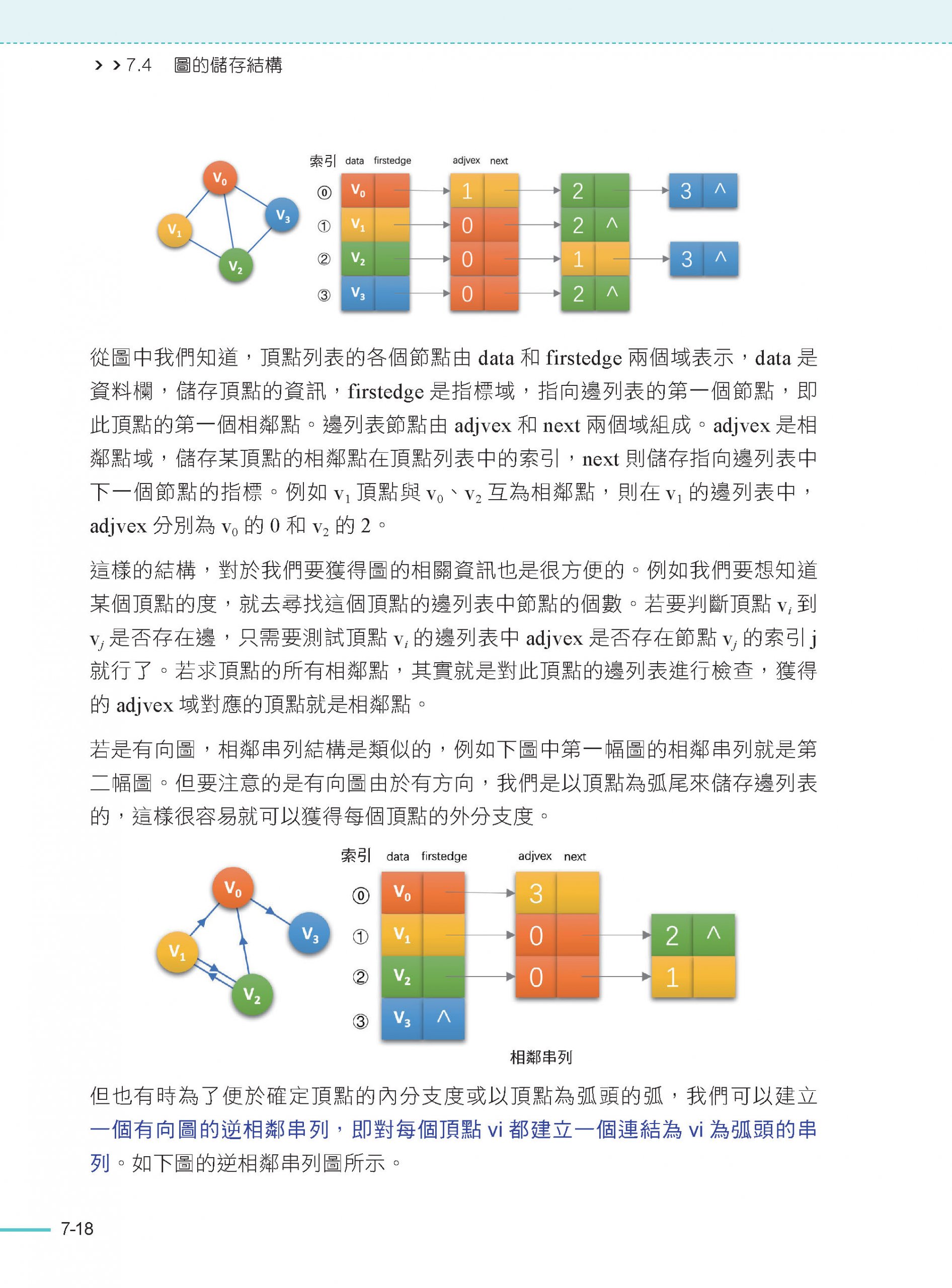
7.4 圖的儲存結構
7.5 圖的檢查
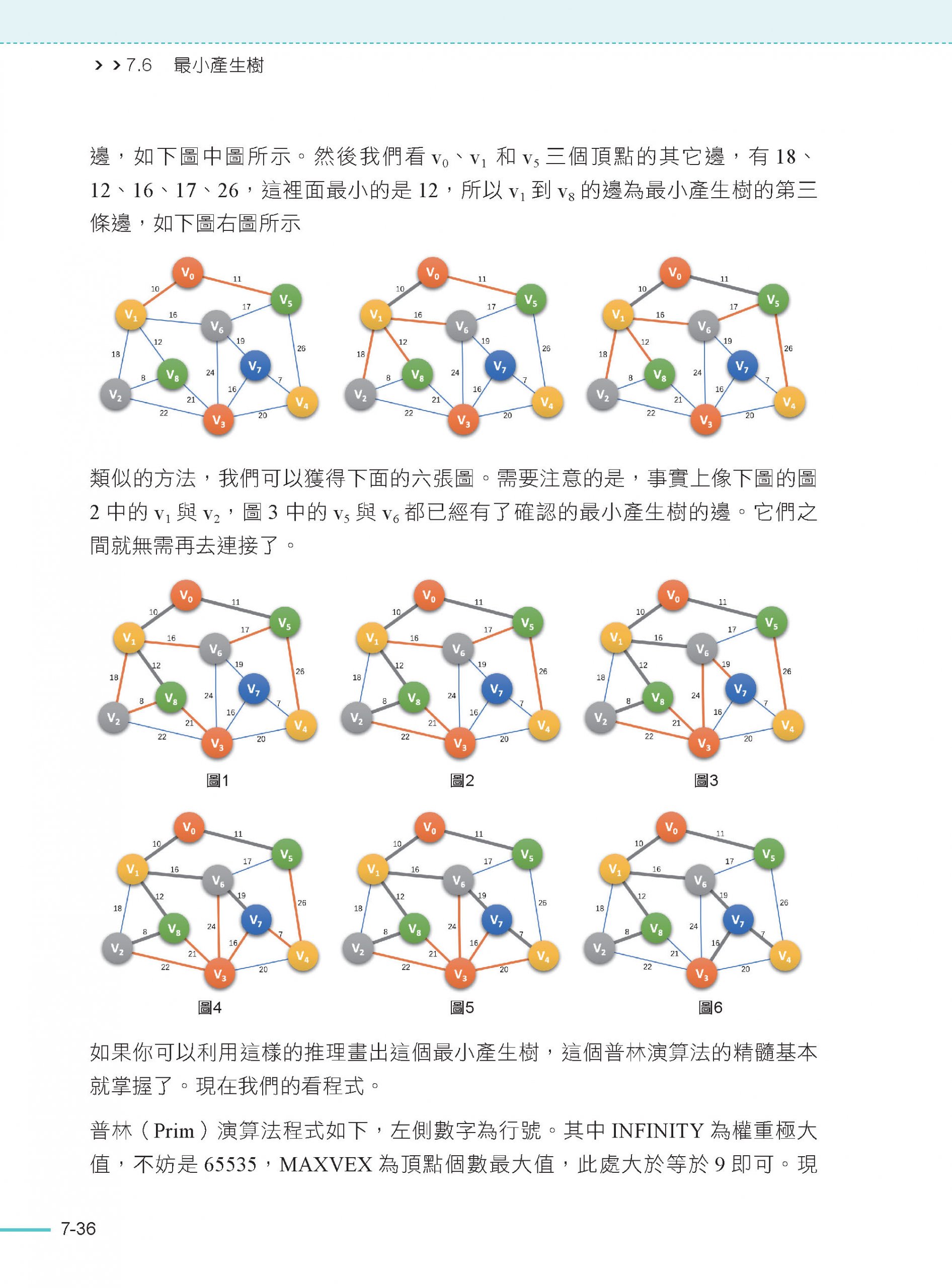
7.6 最小產生樹
7.7 最短路徑
7.8 拓撲排序
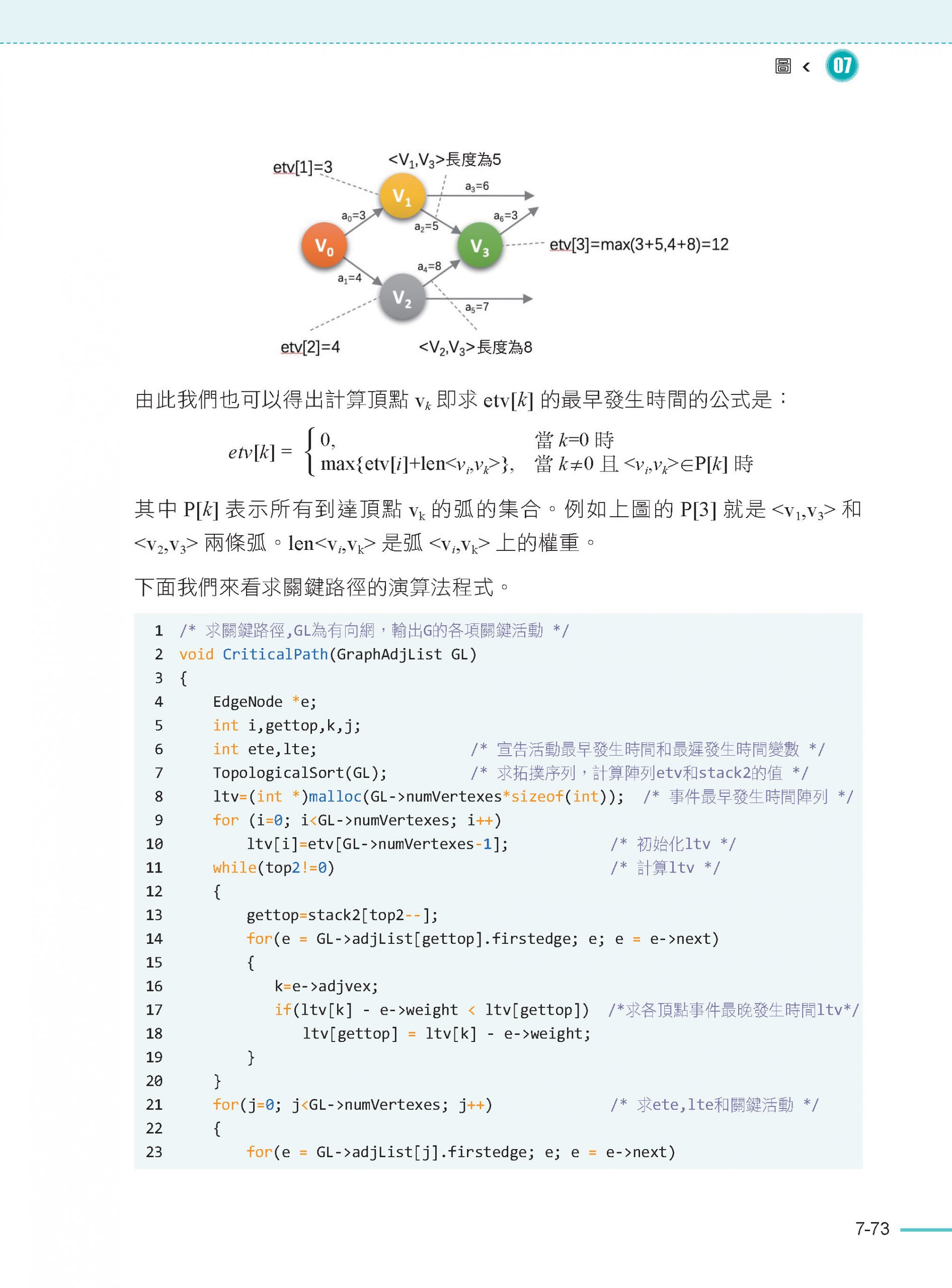
7.9 關鍵路徑顧
7.10 歸納回顧
7.11 結尾語
08 搜尋
8.1 開場白
8.2 搜尋概論
8.3 循序串列搜尋
8.4 有序串列搜尋
8.5 線性索引搜尋
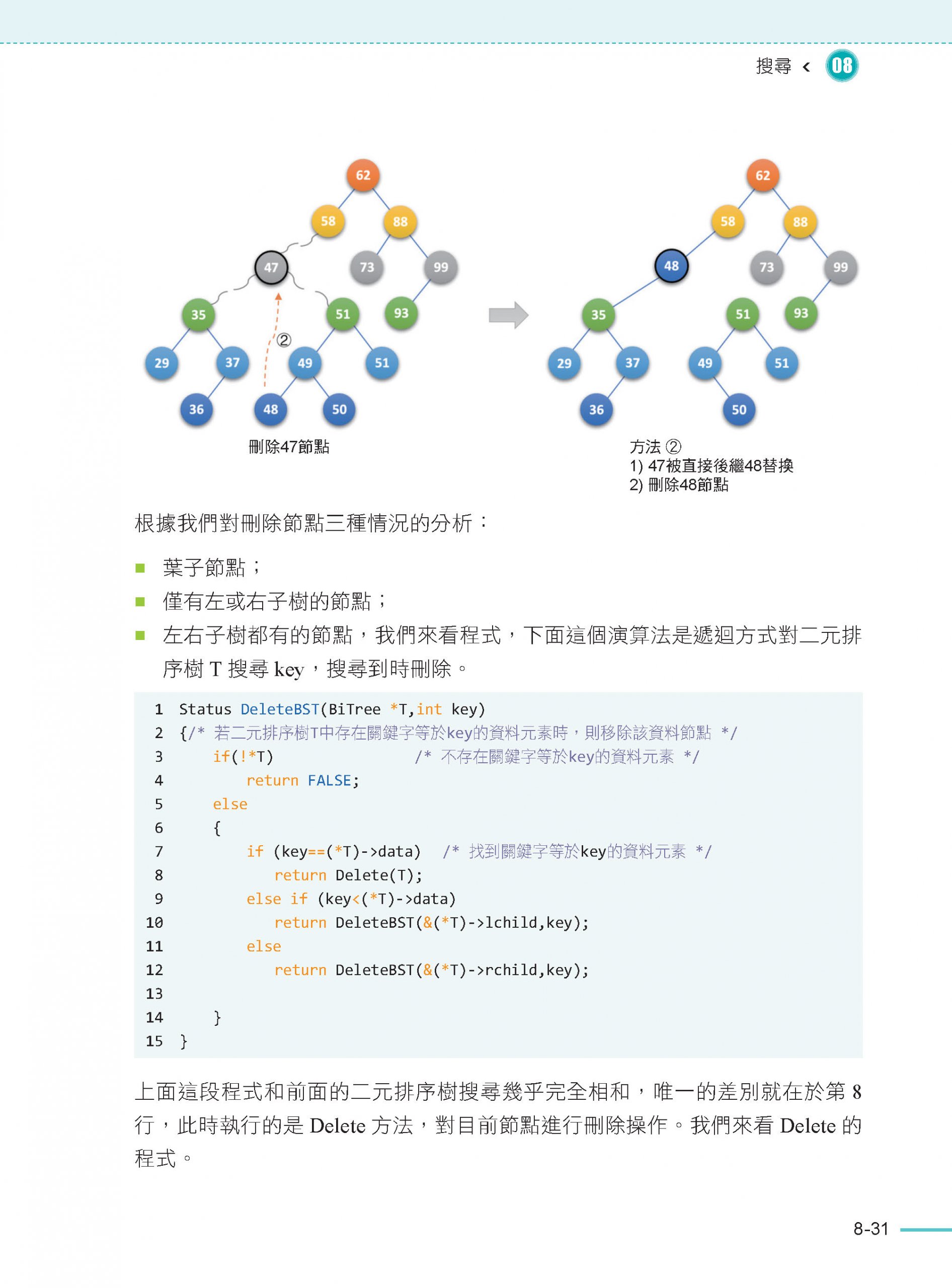
8.6 二元排序樹
8.7 平衡二元樹(AVL 樹)
8.8 多路搜尋樹(二元樹)
8.9 雜湊表搜尋(雜湊表)概述
8.10 雜湊函數的建構方法
8.11 處理雜湊衝突的方法
8.12 雜湊表搜尋實現
8.13 歸納回顧
8.14 結尾語
09 排序
9.1 開場白
9.2 排序的基本概念與分類
9.3 上浮排序
9.4 簡單選擇排序
9.5 直接插入排序
9.6 希爾排序
9.7 堆積排序
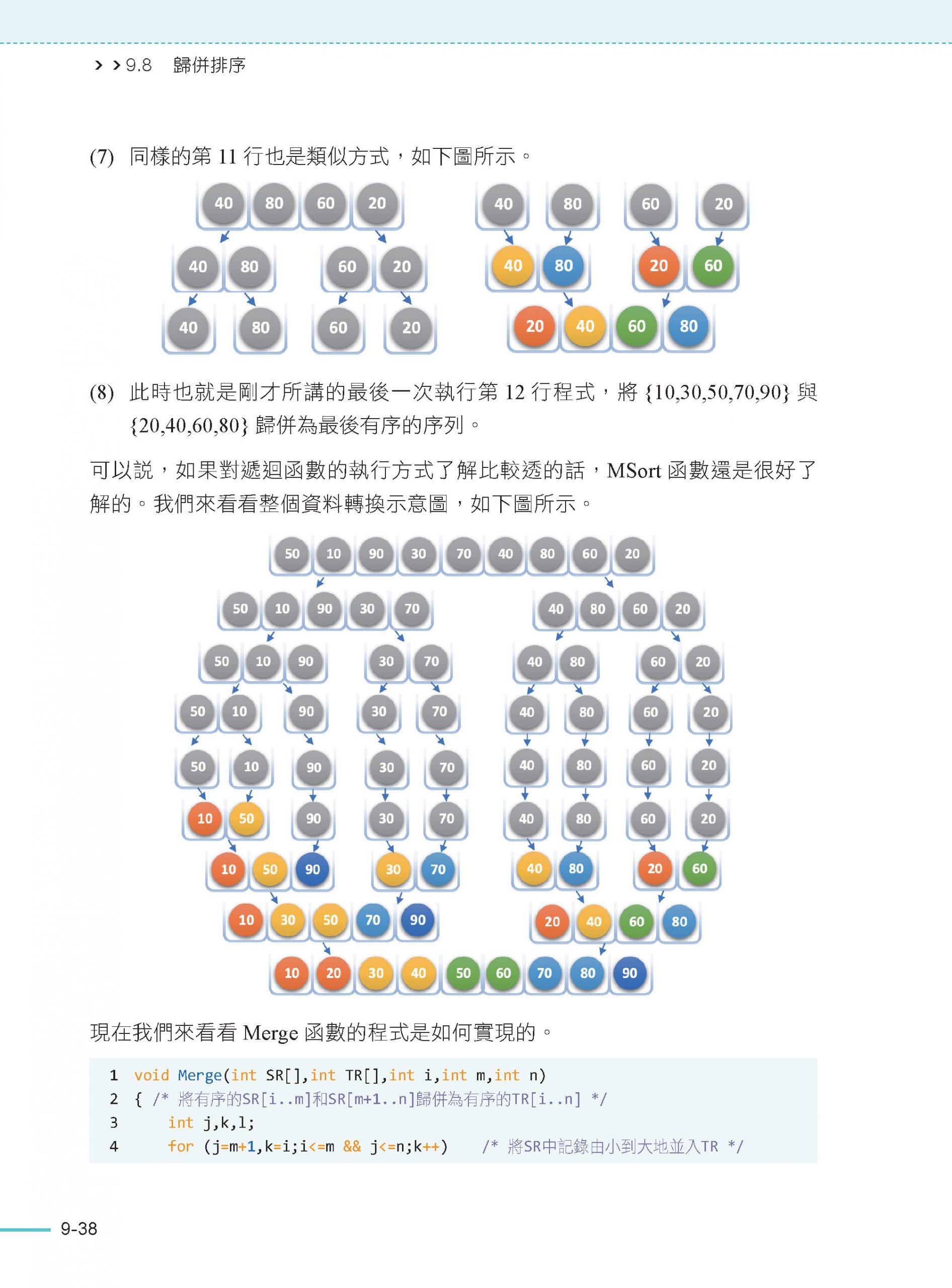
9.8 歸併排序
9.9 快速排序
9.10 歸納回顧
9.11 結尾語
序
前言
本書起因
大家好!我是《大話設計模式》(2008 年出版)的作者,承蒙讀者們的厚愛,《大話設計模式》獲得極大的成功。在噹噹網,截止本文寫作時,就已經有1073 次評論,705 次5 星評價,位居五星圖書榜電腦/ 網路類的累計總榜第二名。
對於這樣一個自己喜歡做、可以做得好,而且已經獲得了市場廣泛認可,為很多朋友提供幫助的事情,我沒有理由不去繼續做下去。這就是我準備再寫書的原因。
我曾做過調查,資料結構的學習者大多都有這樣的感慨:資料結構很重要,一定要學好,但資料結構比較抽象,有些演算法了解起來很困難,學得很累。但我更希望傳達這樣的資訊:資料結構非常有趣,很多演算法是智慧的結晶,學習它是去感受電腦程式設計技術的魅力,在了解掌握它的同時,整個過程都是一種愉悅的精神感受,而非枯燥乏味的一種課程。因此我決定寫作一本關於資料結構有趣的書。
不過現實總比理想來得更「現實」。要想把書寫好,談何容易,我需要突破很多困難……!不管如何,現在您看到了本書,那就說明我已經克服了困難戰勝了自己。希望您可以喜歡上這本書。
本書定位
本書的定位就是一本適合讀者自學資料結構的書籍,它有別於教材,希望給大家另一種閱讀體驗。
通常說明資料結構的圖書都是以教材的方式呈現。在寫作前,我購買或在圖書館借閱了十幾本非常好的資料結構相關教材用來為寫作本書做準備。但經過認真閱讀後,我發現,它們大多不是一本好的「自學」讀物。
我沒有輕視這些好書的意思,不過教材和自學讀物,所針對的讀者是完全不同的。
好的教材應該是提綱挈領、重點突出,一定要留出思考的空間,否則就沒必要再聽老師上課了。很多內容的說明是由老師在課堂完成,教材中有練習、課後習題、思考題等,這些大多可以透過老師來解答。例如我們中學時的語文、數學課本,很薄的一本書通常要用一學期、甚至一年的時間來學習,這就是因為它們是教材而非自學讀物。如果是小說,可能一兩天就讀完了。
好的自學讀物的目標是讓初學者「獨自」全盤掌握知識,需要強調「獨自」一詞,這就說明讀者在閱讀時,是完全依靠自己的力量來向未知發出挑戰。因此書中內容,要麼不寫,寫了就應該寫透。如果讀者在閱讀時總是疑惑重重,那麼這本書就有很大的問題了。
我也就是在以這樣的自覺為基礎寫作,決心將《大話資料結構》寫成一本真正關於資料結構和演算法的自學讀物。









