




描述
內容簡介
| ☆全面迎戰 AI 2.0 時代,深度解析基座大模型訓練與選型策略。
★拆解硬核算力基礎,精準掌握 NVIDIA 與 AMD GPU 參數及選型。 ☆掌握應用程式開發核心,透析上下文學習與人類回饋對齊方法。 ★攻克文件前置處理難題,詳解分塊(Chunking)與詞元化策略。 ☆剖析向量資料庫底層,實作相似性演算法與主流產品整合。 ★突破高效微調技術瓶頸,運用開源工具打造專屬領域大模型。 ☆解密推理效能最佳化,精通模型壓縮與 FlashAttention 記憶體管理。 ★構建高併發部署環境,涵蓋 Web 服務、伺服器端與端側推理引擎。 ☆昇華提示工程(Prompt)技術,結合 Dify 等開發工具提升精準度。 ★深度實踐 RAG 與 Agent 架構,賦予大模型檢索與自主行動能力。 ☆橫掃三大主流編排框架,實作 LangChain、LlamaIndex 與 Semantic Kernel。 ★從環境準備到打包部署,完整解析真實大模型應用專案實戰範例。
◼本書共分 12 章,循序漸進地勾勒出大模型應用開發的完整藍圖。 第1至3章從 AI 2.0 時代的背景出發,說明基座大模型的預訓練與強化學習過程,並深度剖析 GPU 的底層知識與選型策略,奠定硬體與模型基礎。 第4至6章聚焦於資料與開發前置作業,涵蓋提示概念、文件分塊與詞元化處理,並詳細說明向量資料庫的相似性演算法與核心價值。 第7至9章直擊效能與工程部署,探討參數高效微調技術、推理效能最佳化(包含模型壓縮與多 GPU 並行化),並實作 Web 服務與伺服器/端側推理引擎的部署。 第10至12章則帶領讀者邁向應用巔峰,不僅解析提示工程的開發工具,更深度說明 RAG 與 Agent 架構的編排整合,涵蓋 LangChain 與 LlamaIndex 等主流框架,最後透過一個完整的應用範例,演示從環境準備到打包部署的實戰全過程。 |
作者簡介
| 李瀚
資深AI系統架構師。 長期從事AI平台及AI驅動的應用系統(推薦、搜索和大模型等)的架構設計與開發工作,在AI工程領域擁有深刻的認知和豐富的實戰經驗,曾設計並開發了企業級機器學習平台和大型模型應用開發平台等創新產品,服務多家世界500強企業AI轉型諮詢和項目落地。參與編寫《MLOps工程實踐:工具、技術與企業及應用》。
徐斌 擁有10年以上的網路安全經驗,在矽谷領先的網路安全公司從事數據分析平台的設計開發工作。精通網路安全防護、漏洞分析與滲透測試,尤其擅長結合數據分析和AI技術優化安全系統的檢測與應變能力,如通過深度學習、機器學習等AI技術分析大量的安全數據,實時發現潛在威脅,提升安全防護的效率。 |
目錄
| ▌第1 章 AI 2.0 時代到來
1.1 ChatGPT 旋風 1.1.1 ChatGPT 是什麼 1.1.2 豐富的應用 1.1.3 有喜有憂 1.2 認識AI 2.0 時代 1.2.1 何謂大模型 1.2.2 AI 1.0 時代與AI 2.0 時代特點分析 1.2.3 新「工業革命」來臨 1.3 本章小結
▌第2 章 基座大模型準備
2.1 大模型的歷史與未來 2.1.1 發展史 2.1.2 未來趨勢 2.2 基座大模型訓練過程 2.2.1 預訓練 2.2.2 人類回饋的強化學習 2.3 選擇合適的基座大模型 2.3.1 主流基座大模型介紹 2.3.2 選型標準 2.4 本章小結
▌第3 章 GPU 相關知識
3.1 基礎知識 3.1.1 顯示卡與GPU 3.1.2 GPU 與CPU 3.2 GPU 的優勢 3.2.1 GPU 與深度學習 3.2.2 CUDA 程式設計 3.3 準備合適的GPU 3.3.1 選擇合適的GPU(顯示卡)供應商 3.3.2 NVIDIA 與AMD 3.3.3 NVIDIA GPU 各項參數 3.3.4 選型建議 3.4 本章小結
▌第4 章 應用程式開發概覽
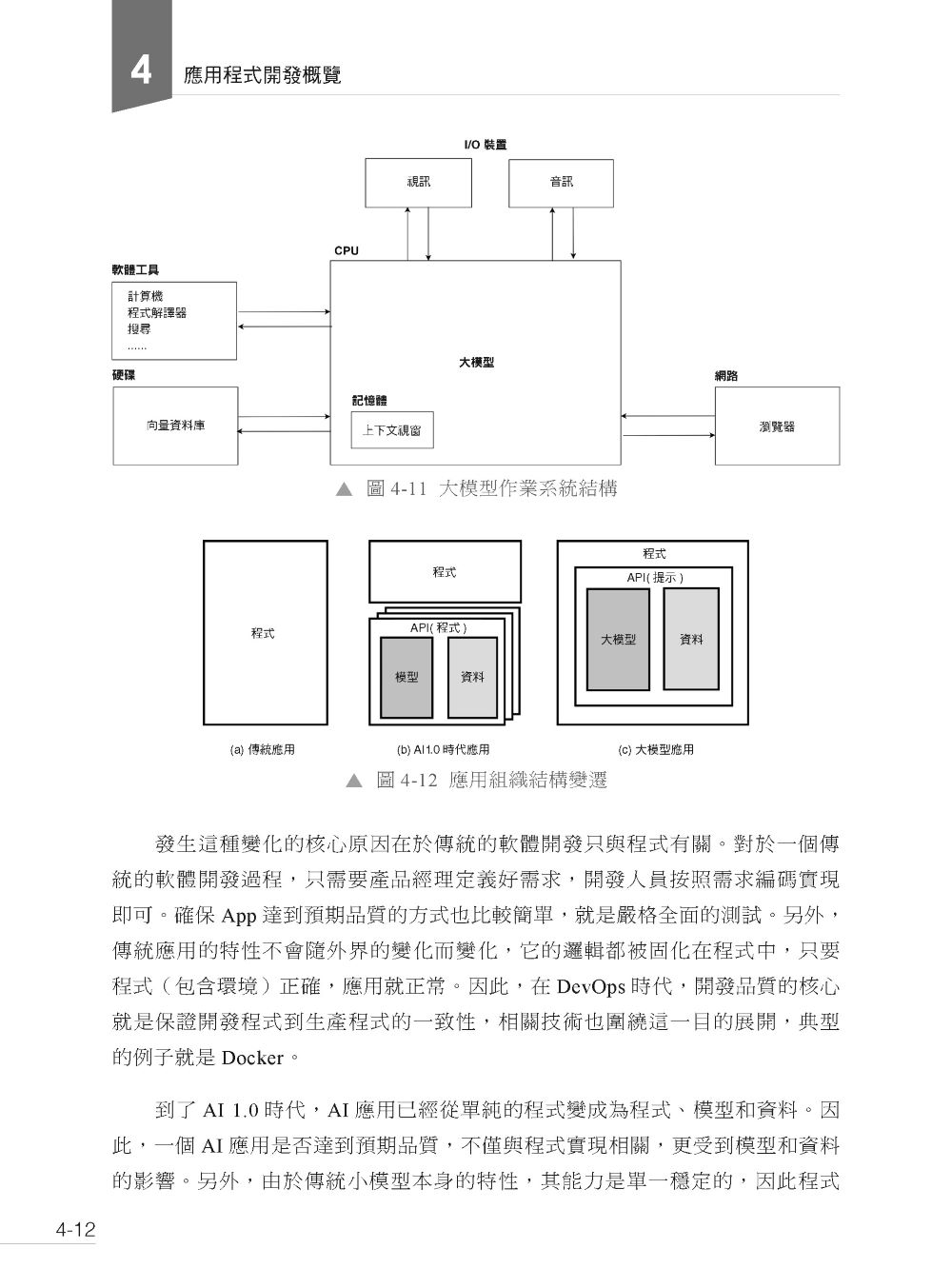
4.1 關鍵概念 4.1.1 提示 4.1.2 上下文學習 4.2 應用趨勢 4.2.1 趨勢變遷 4.2.2 產品形態 4.3 技術實現 4.3.1 對齊方法 4.3.2 優劣勢比較 4.3.3 應用流程 4.4 本章小結
▌第5 章 文件處理
5.1 分塊 5.1.1 分塊的作用 5.1.2 分塊的策略 5.1.3 策略選擇 5.2 詞元化 5.2.1 概念和方法 5.2.2 Token 採樣策略 5.3 嵌入 5.4 本章小結
▌第6 章 向量資料庫
6.1 基本概念 6.2 相關演算法 6.2.1 向量相似性演算法 6.2.2 工程中常用的向量搜索折中演算法 6.3 核心價值 6.4 定位 6.5 主流產品 6.6 本章小結
▌第7 章 微調
7.1 背景與挑戰 7.1.1 背景知識 7.1.2 技術挑戰 7.2 參數高效微調技術 7.3 工具實踐 7.3.1 開放原始碼工具套件 7.3.2 模型微調服務 7.4 本章小結
▌第8 章 推理最佳化概論
8.1 最佳化目標 8.2 理論基礎 8.2.1 模型大小的指標 8.2.2 模型大小對推理性能的影響 8.2.3 大模型相關分析 8.3 常見最佳化技術 8.3.1 模型壓縮 8.3.2 Offloading 8.3.3 多GPU 並行化 8.3.4 高效的模型結構 8.3.5 FlashAttention 8.3.6 PagedAttention 8.3.7 連續批次處理 8.4 本章小結
▌第9 章 部署推理工具
9.1 推理架構概述 9.2 Web 服務 9.2.1 Streamlit 與Gradio 9.2.2 FastAPI 與Flask 9.3 推理執行引擎 9.3.1 伺服器端推理 9.3.2 端側推理 9.4 推理服務 9.5 對話類系統 9.6 本章小結
▌第10 章 提示工程
10.1 理論與技術 10.1.1 提示的價值 10.1.2 應用領域 10.1.3 提示工程技術 10.2 開發工具 10.2.1 OpenAI Playground 10.2.2 Dify 10.2.3 PromptPerfect 10.3 本章小結
▌第11 章 編排與整合
11.1 相關理論 11.1.1 面臨的問題 11.1.2 核心價值 11.1.3 功能組成 11.2 典型架構模式 11.2.1 RAG 11.2.2 Agent 11.3 常見編排框架 11.3.1 LangChain 框架 11.3.2 LlamaIndex 框架 11.3.3 Semantic Kernel 框架 11.4 本章小結
▌第12 章 應用範例
12.1 整體架構 12.2 開發過程 12.2.1 環境準備 12.2.2 實現解析 12.2.3 打包部署 12.2.4 範例演示 12.3 本章小結
▌參考文獻 |
序
|