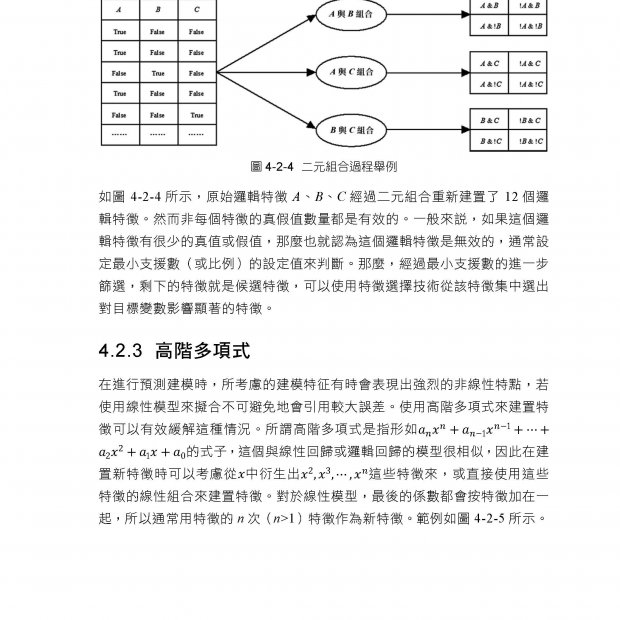








描述
內容簡介
| ►128 GB 統一記憶體,桌上跑 120B 大型語言模型,不需要雲端
►七大推論引擎完整實測:Ollama、vLLM、TRT-LLM、SGLang、NIM、llama.cpp、LM Studio ►實作 Andrej Karpathy 的 Autoresearch 架構 ►ComfyUI 圖片影片生成、語音合成、AI 音樂,多媒體 AI 全部本機完成 ►五種微調框架實戰比較:LoRA、QLoRA、Unsloth、LLaMA Factory、NeMo ►從零預訓練 BERT、GPT、Embedding 模型,走過語言模型訓練全流程 ►RAG、知識圖譜、多代理聊天、AI Agent 沙箱,企業級應用完整部署 ►RAPIDS 加速資料科學、JAX、金融最佳化、基因體分析,跨領域一台搞定 ►全書用 Claude Code 操作,自然語言驅動 AI 超級電腦 ►跑本地端OpenClaw,NV專屬NemoClaw ►完整覆蓋 NVIDIA 官方全部 Playbook,每章附實測與程式碼
【書籍簡介】 NVIDIA DGX Spark 是第一台放在桌上的 AI 超級電腦。Grace Blackwell 超級晶片搭配 128 GB 統一記憶體,讓過去只能在資料中心執行的 AI 工作負載,現在一個人就能在書桌上完成。本書從開箱、系統建置開始,帶你一步步把這台機器的所有能力都發揮出來。全書 25 章、7 大篇、5 個附錄,完整覆蓋 NVIDIA 官方提供的所有 Playbook,每一章都有實際在 DGX Spark 上執行的程式碼和操作記錄。從第 5 章開始,所有操作都透過 Claude Code 用自然語言完成,展示 AI 時代的全新開發方式。
前三篇涵蓋七大推論引擎的完整實測。從最簡單的 Ollama 一行指令跑模型,到 vLLM 的高吞吐量服務、TensorRT-LLM 的 NVIDIA 原生加速、SGLang 的推測性解碼,再到 NIM 企業級微服務,每個引擎都在 128 GB 記憶體上做了極限測試。第四篇進入多媒體生成,用 ComfyUI 跑 FLUX 和 Wan 2.2 生成圖片與影片,用 Qwen3-TTS 做語音合成,用 ACE-Step 生成音樂。第五篇是微調與預訓練,從 LoRA、QLoRA、Unsloth、LLaMA Factory 到 NeMo,五種框架完整比較,還包含從零預訓練 BERT 和 GPT 模型的完整流程。
後兩篇聚焦在進階應用和系統擴展。多模態推論結合視覺語言模型做即時影像理解,RAG 和知識圖譜讓模型能讀你的文件,AI Agent 搭配安全沙箱在本機自主執行任務。RAPIDS 和 JAX 把 GPU 加速帶到資料科學和數值計算領域,金融最佳化和單細胞基因體分析展示跨領域的應用潛力。最後,透過 200GbE 高速網路把多台 DGX Spark 串聯成叢集,用 256 GB 以上的記憶體跑 235B 參數的超大模型做分散式推論。無論你是 AI 研究者、軟體工程師還是資料科學家,這本書都能幫你把 DGX Spark 的每一分效能轉化為實際的生產力。 |
作者簡介
| 胡嘉璽
研究領域為 LLM、Vibe Coding、Agent、量子電腦、虛擬化及容器。 聯絡方式:github/joshhu |
目錄
| ▍第一篇 硬體與系統建置
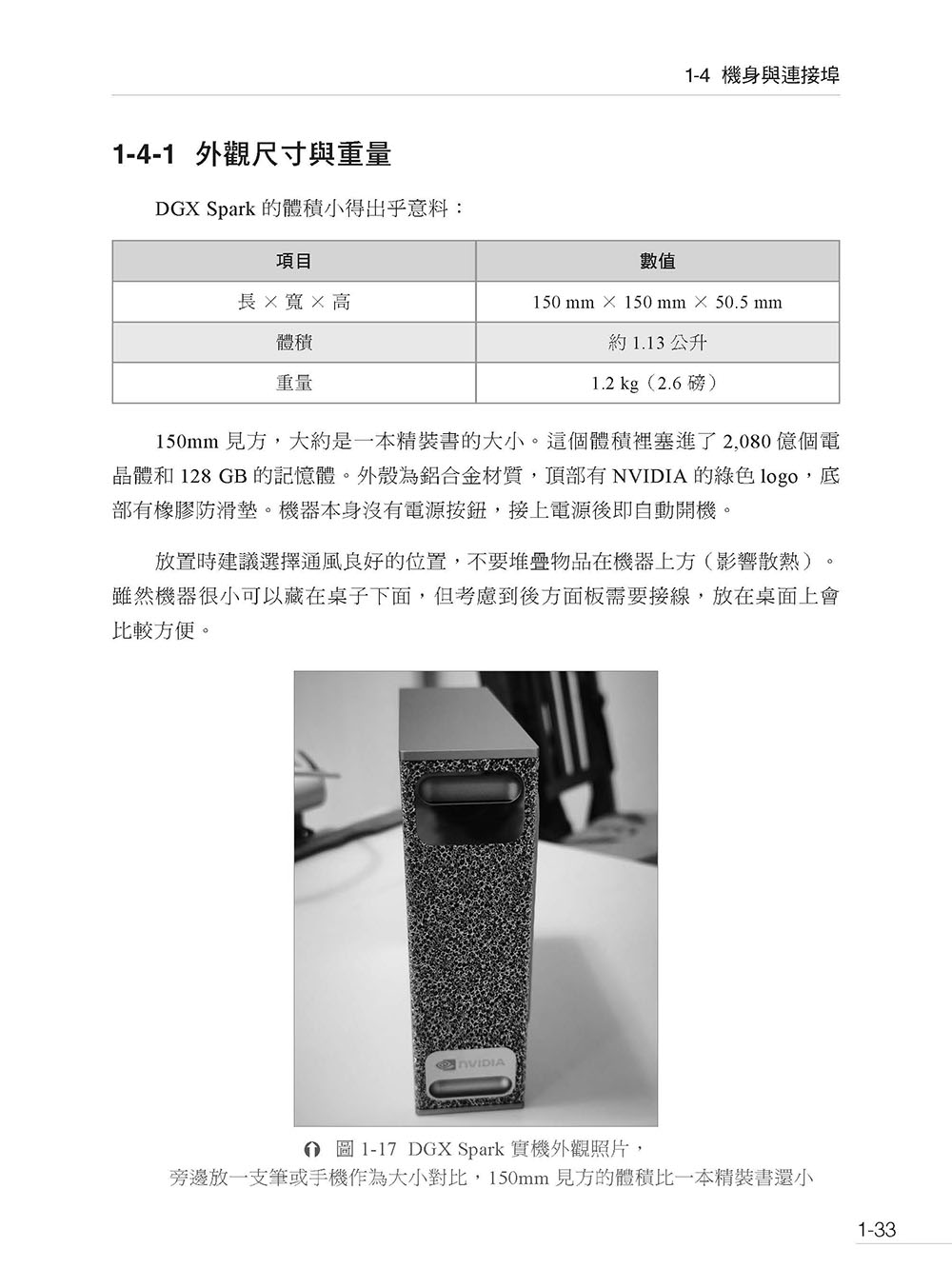
第1 章 DGX Spark 硬體總覽 1-1 DGX Spark 是什麼 1-2 GB10 Grace Blackwell 超級晶片 1-3 128 GB 統一記憶體:改變遊戲規則的關鍵 1-4 機身與連接埠 1-5 開箱前的準備清單 1-6 本章小結
第2 章 DGX OS 安裝與首次開機 2-1 首次開機設定 2-2 DGX OS 概觀 2-3 系統更新 2-4 系統還原與救援模式 2-5 NVIDIA Sync 客戶端 2-6 本章小結
第3 章 Linux 環境建置與 Claude Code 安裝 3-1 Shell 環境 3-2 套件管理工具 3-3 多媒體與系統工具 3-4 安裝 Claude Code 3-5 本書的 Claude Code 操作模式 3-6 本章小結
第4 章 遠端桌面與網路存取 4-1 桌面環境安裝 4-2 VNC 遠端桌面 4-3 區域網路設定 4-4 外部存取:Tailscale VPN 4-5 系統監控與 DGX Dashboard 4-6 多節點叢集監控:DGX Spark Dashboard 4-7 備份整個環境 4-8 本章小結
▍第二篇 LLM 推論入門 第5 章 Ollama—在128 GB 上跑超大模型 5-1 用 Claude Code 安裝 Ollama 5-2 用 Docker 執行 Ollama 5-3 下載與執行超大模型 5-4 多模態模型實測:Qwen3.5 122B 5-5 將 Ollama 開放成遠端服務 5-6 讓 Claude Code 使用本機 Ollama 模型 5-7 本章小結
第6 章 Open WebUI—瀏覽器裡的AI 助手 6-1 用 Claude Code 部署 Open WebUI 6-2 模型管理與基本對話 6-3 RAG:讓模型讀你的文件 6-4 Tool Calling:讓模型使用工具 6-5 更新與維護 6-6 本章小結
第7 章 LM Studio—Headless 模型服務 7-1 在 DGX Spark 上安裝 LM Studio GUI 7-2 用 Claude Code 安裝 llmster 7-3 模型管理 7-4 啟動 API 服務 7-5 LM Link:跨網路存取 7-6 llmster vs. Ollama:何時用哪個 7-7 進階操作 7-8 模型載入優化:榨出最大效能 7-9 本章小結
第8 章 llama.cpp 與Nemotron—輕量原生推論 8-1 llama.cpp 基礎 8-2 用 Claude Code 編譯 llama.cpp 8-3 下載 Nemotron-3-Nano 模型 8-4 啟動 llama-server 8-5 效能調校與 Speculative Decoding 8-6 Nemotron-3-Nano vs. 其他工具的Nemotron 8-7 清理與移除 8-8 llama.cpp 的最新發展 8-9 本章小結
▍第三篇 LLM 推論進階 第9 章 vLLM — 高吞吐量推論伺服器 9-1 vLLM 架構與特色 9-2 支援的模型 9-3 用 Claude Code 部署 vLLM 9-4 部署超大模型:Qwen3.5-122B 和 GPT-OSS-120B 9-5 效能調校 9-6 vLLM vs. Ollama vs. llama.cpp 9-7 清理與移除 9-8 網路流言 91t/s 的模型真的假的? 9-9 本章小結
第10 章 TensorRT-LLM — NVIDIA 原生加速引擎 10-1 TRT-LLM 架構與支援模型 10-2 單機部署 10-3 整合 Open WebUI 10-4 單機清理 10-5 疑難排解 10-6 本章小結
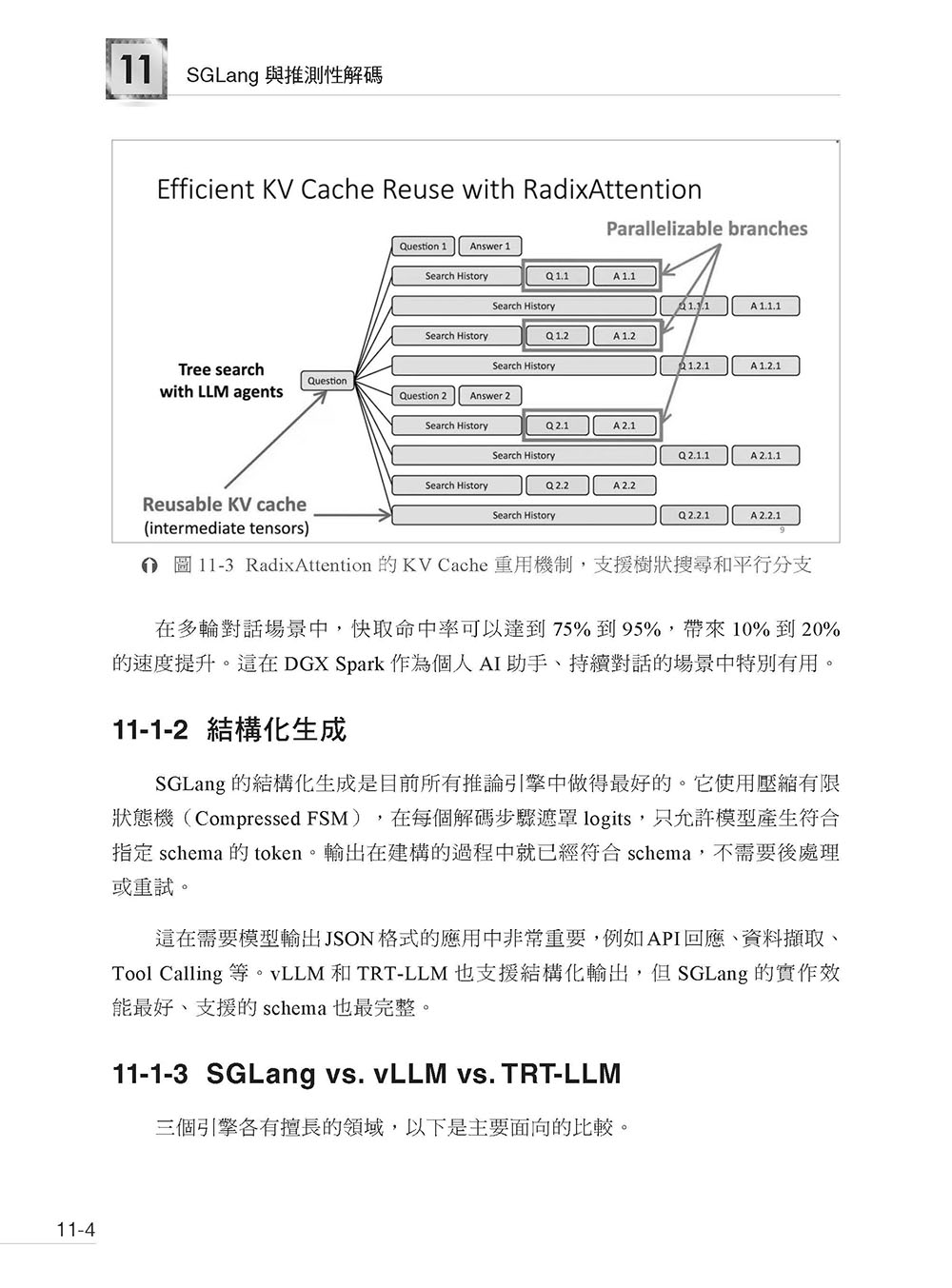
第11 章 SGLang 與推測性解碼 11-1 SGLang 推論框架 11-2 部署 SGLang 11-3 推測性解碼 11-4 疑難排解 11-5 本章小結
第12 章 NIM 推論微服務與引擎總比較 12-0 申請 ngc 帳號 12-1 NIM 概觀 12-2 部署 NIM 12-3 七大推論引擎總比較 12-4 疑難排解 12-5 本章小結
▍第四篇 多媒體AI 生成 第13 章 圖片與影片生成 13-1 用現有的工具體驗圖片 AI 13-2 ComfyUI 基礎 13-3 安裝 ComfyUI 13-4 Text-to-Image 工作流程 13-5 Text-to-Video:文字生影片 13-6 NVFP4 加速 13-7 清理 13-8 疑難排解 13-9 本章小結
第14 章 音訊、語音與音樂 AI 14-1 語音合成(Text-to-Speech) 14-2 語音辨識(Speech-to-Text) 14-3 AI 音樂生成 14-4 音訊處理工具鏈 14-5 常見問題與疑難排解 14-6 本章小結
▍第五篇 模型微調與訓練 第15 章 LoRA / QLoRA 微調實戰—DGX Spark 128 GB 全面比較 15-1 微調概念與 DGX Spark 的優勢 15-2 實驗環境建立 15-3 GPU 基線效能測量 15-4 資料集準備 15-5 六種 PEFT 方法微調 Qwen3-8B 15-6 文字模型結果比較 15-7 推論測試 15-9 NVIDIA 官方微調 Playbook 15-10 常見問題與疑難排解 15-11 本章小結
第16 章 Unsloth — 最快的微調框架 16-1 Unsloth 介紹與安裝 16-2 QLoRA 微調實戰:Qwen3-8B 16-3 推論測試 16-4 模型匯出與部署 16-5 Loss 曲線分析 16-6 進階:微調 120B 大模型 16-7 NVIDIA 官方 Unsloth Playbook 16-8 Unsloth vs. 標準 PEFT 比較 16-9 常見問題與疑難排解 16-10 本章小結
第17 章 LLaMA Factory、NeMo 與 PyTorch 微調 17-1 LLaMA Factory 17-2 NeMo AutoModel 17-3 PyTorch 原生微調 17-4 三大框架比較 17-5 常見問題與疑難排解 17-6 本章小結
第18 章 影像模型微調 — FLUX Dreambooth LoRA 18-1 影像生成模型微調概念 18-2 環境建立與模型下載 18-3 準備訓練資料 18-4 Dreambooth LoRA 訓練 18-5 基礎模型 vs. 微調模型推論比較 18-6 進階技巧 18-7 常見問題與疑難排解 18-8 本章小結
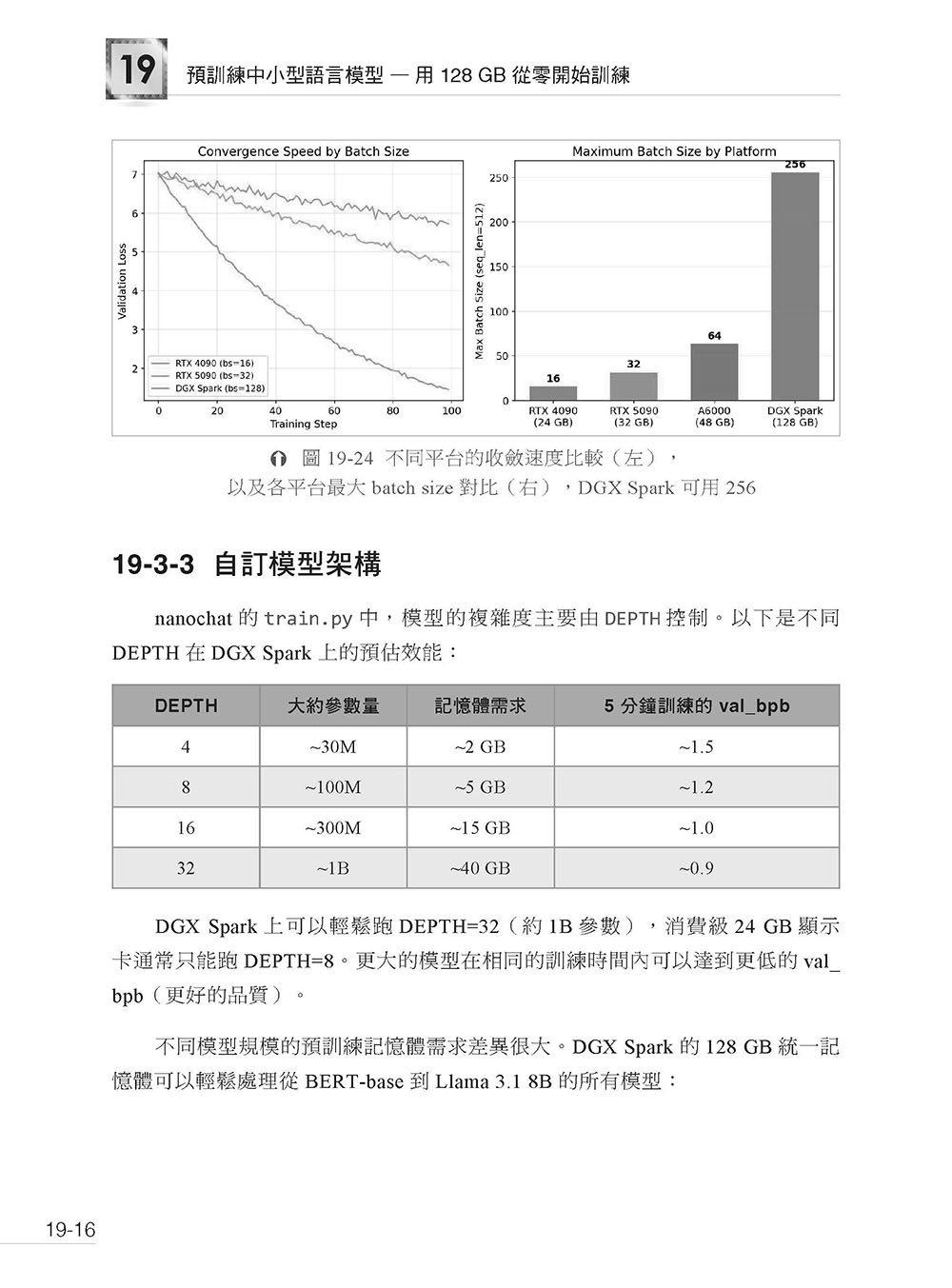
第19 章 預訓練中小型語言模型—用 128 GB 從零開始訓練 19-1 為什麼 DGX Spark 適合預訓練中小型模型 19-2 預訓練 BERT 系列模型 19-3 預訓練小型 GPT / Decoder-only 模型 19-4 autoresearch — 讓 AI 自動研究預訓練 19-5 NVFP4 預訓練 — 用 Blackwell 原生 FP4 加速訓練 19-6 預訓練 Embedding 模型 19-7 訓練監控與模型評估 19-8 本章小結
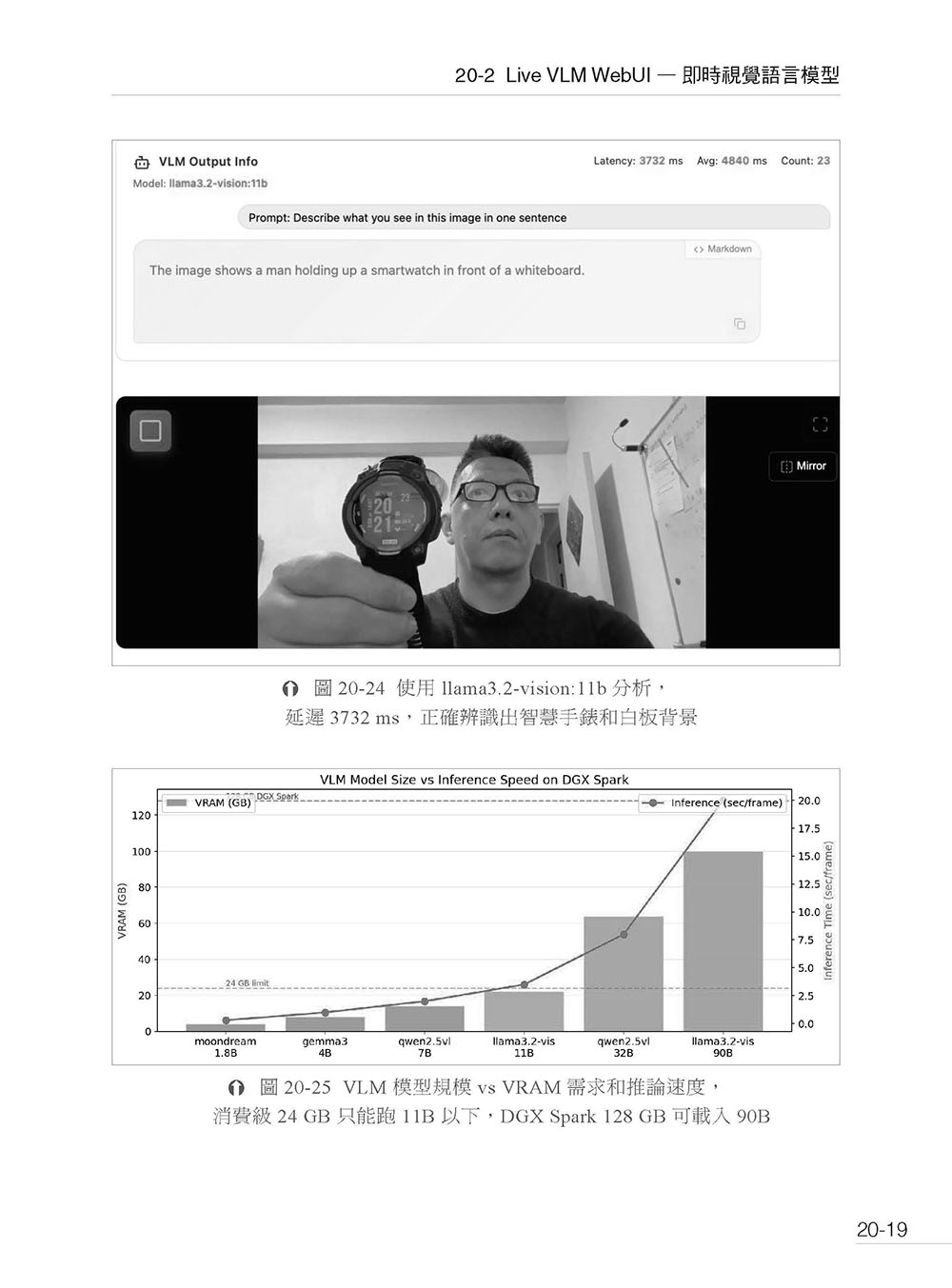
▍第六篇 多模態AI 與智慧代理 第20 章 多模態推論與即時視覺 AI 20-1 TensorRT 加速擴散模型推論 20-2 Live VLM WebUI — 即時視覺語言模型 20-3 同時跑生成和理解 20-4 常見問題與疑難排解 20-5 本章小結
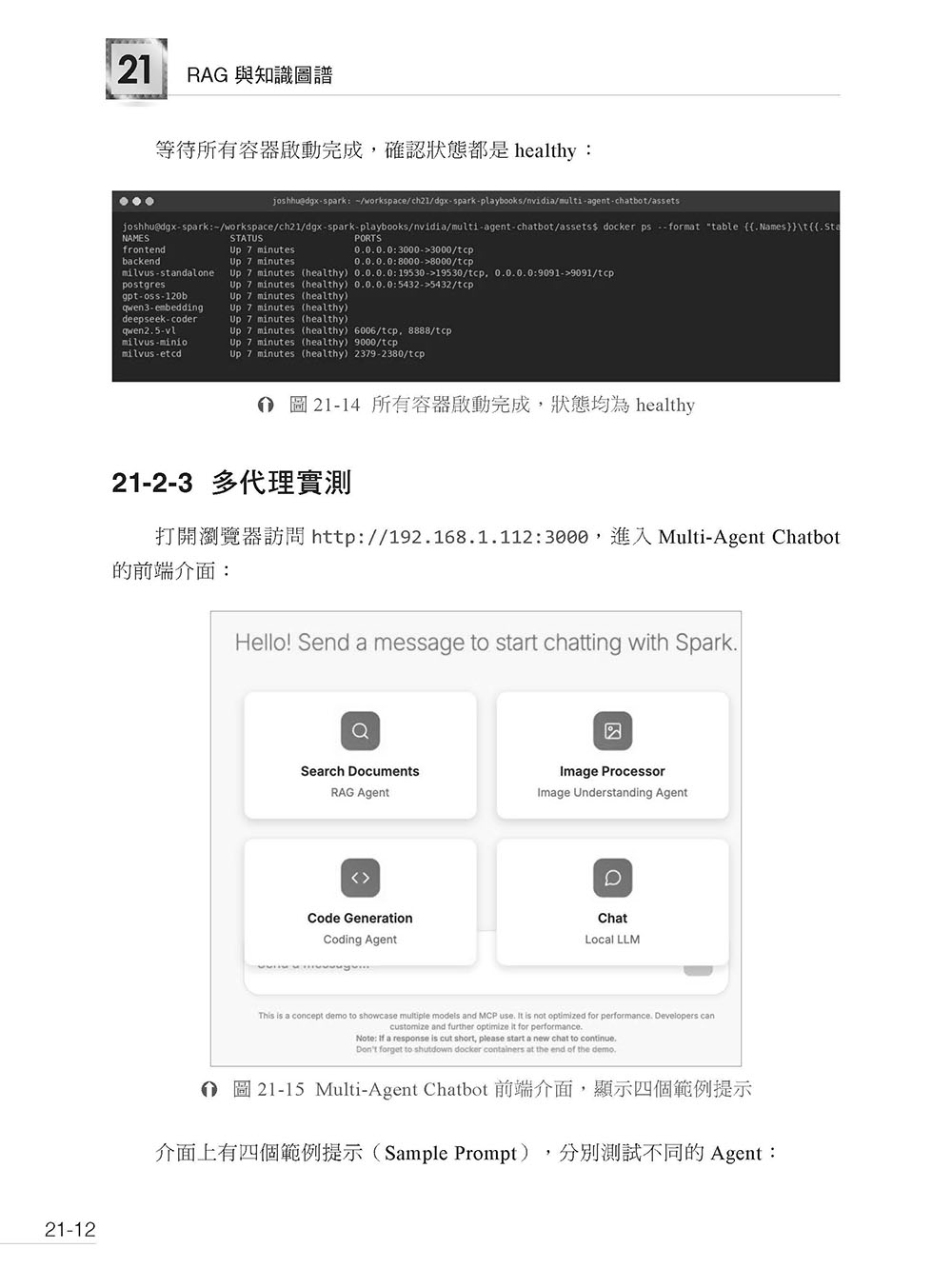
第21 章 RAG 與知識圖譜 21-1 RAG 檢索增強生成 21-2 Multi-Agent Chatbot — 多代理協作系統(Playbook: multi-agent-chatbot) 21-3 Text to Knowledge Graph — 文字轉知識圖譜 21-4 本章小結
第22 章 AI Agent 與安全沙箱 22-1 AI Agent 概觀 22-2 OpenClaw — 用 Ollama 一鍵部署本地 AI 代理 22-3 NemoClaw — Nemotron 驅動的企業級 Agent 22-4 OpenShell — AI Agent 安全沙箱 22-5 本章小結
▍第七篇 科學計算、開發工具與擴展 第23 章 CUDA-X 資料科學、JAX 與特殊領域應用 23-1 CUDA-X 資料科學(Playbook: cuda-x-data-science) 23-2 JAX on DGX Spark(Playbook: jax) 23-3 影片搜尋與摘要(Playbook: vss) 23-4 特殊領域應用 23-5 本章小結
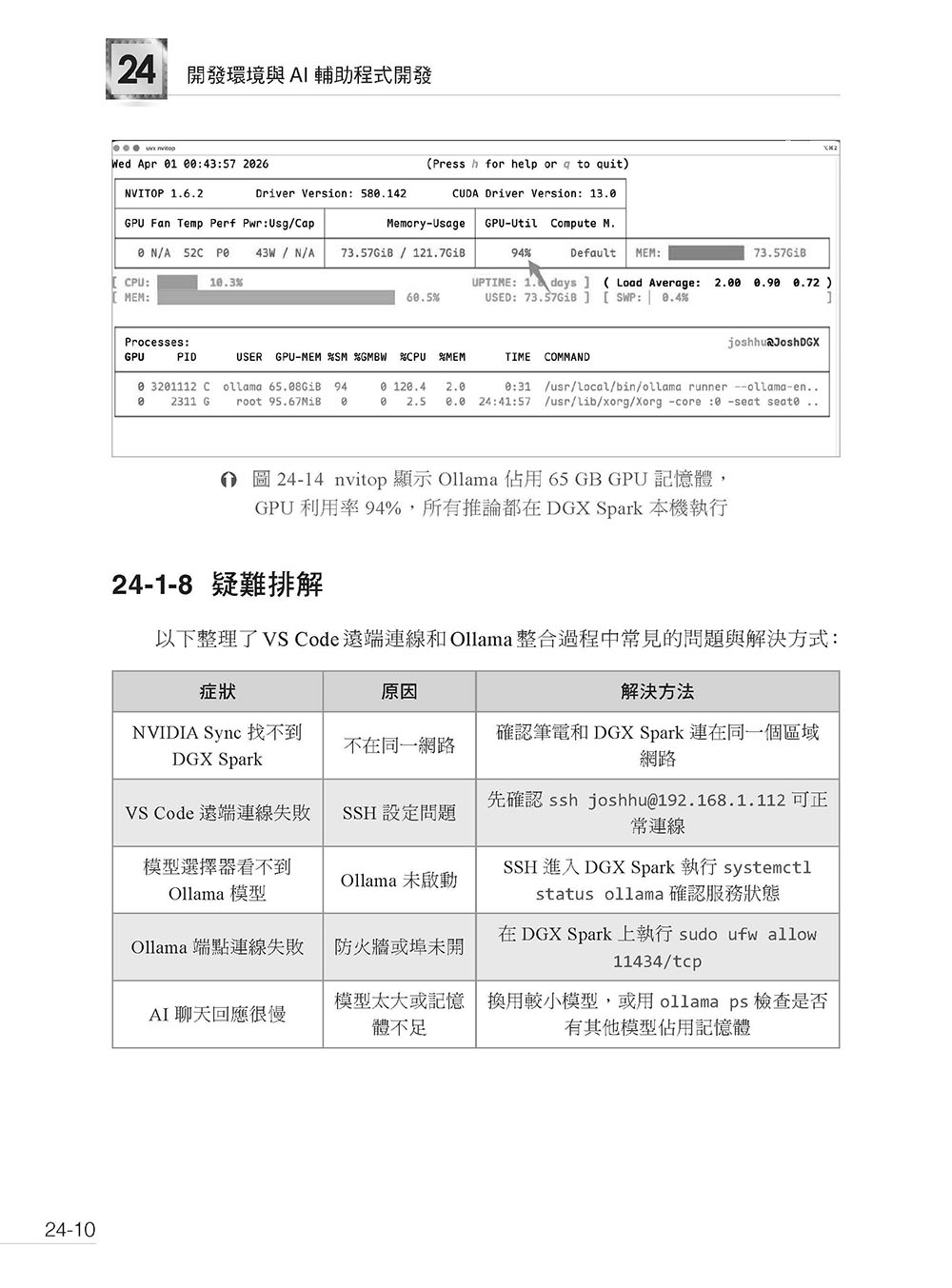
第24 章 開發環境與AI 輔助程式開發 24-1 VS Code 遠端開發與 Ollama 整合 24-2 Vibe Coding:用 Claude Code 搭配本機 Ollama 模型 24-3 本章小結
第25 章 多機互連與分散式運算 25-1 硬體準備 25-2 雙機直連 25-3 NCCL 分散式通訊 25-4 三機環狀互連 25-5 多機交換器互連 25-6 分散式推論實戰:雙機跑 235B 模型 25-7 三種拓撲比較 25-8 回復設定 25-9 本章小結
附錄A Claude Code 常用指令速查表 安裝與啟動 互動模式操作 搭配 Ollama 使用(第 24 章) 常見用法範例 CLAUDE.md 設定檔
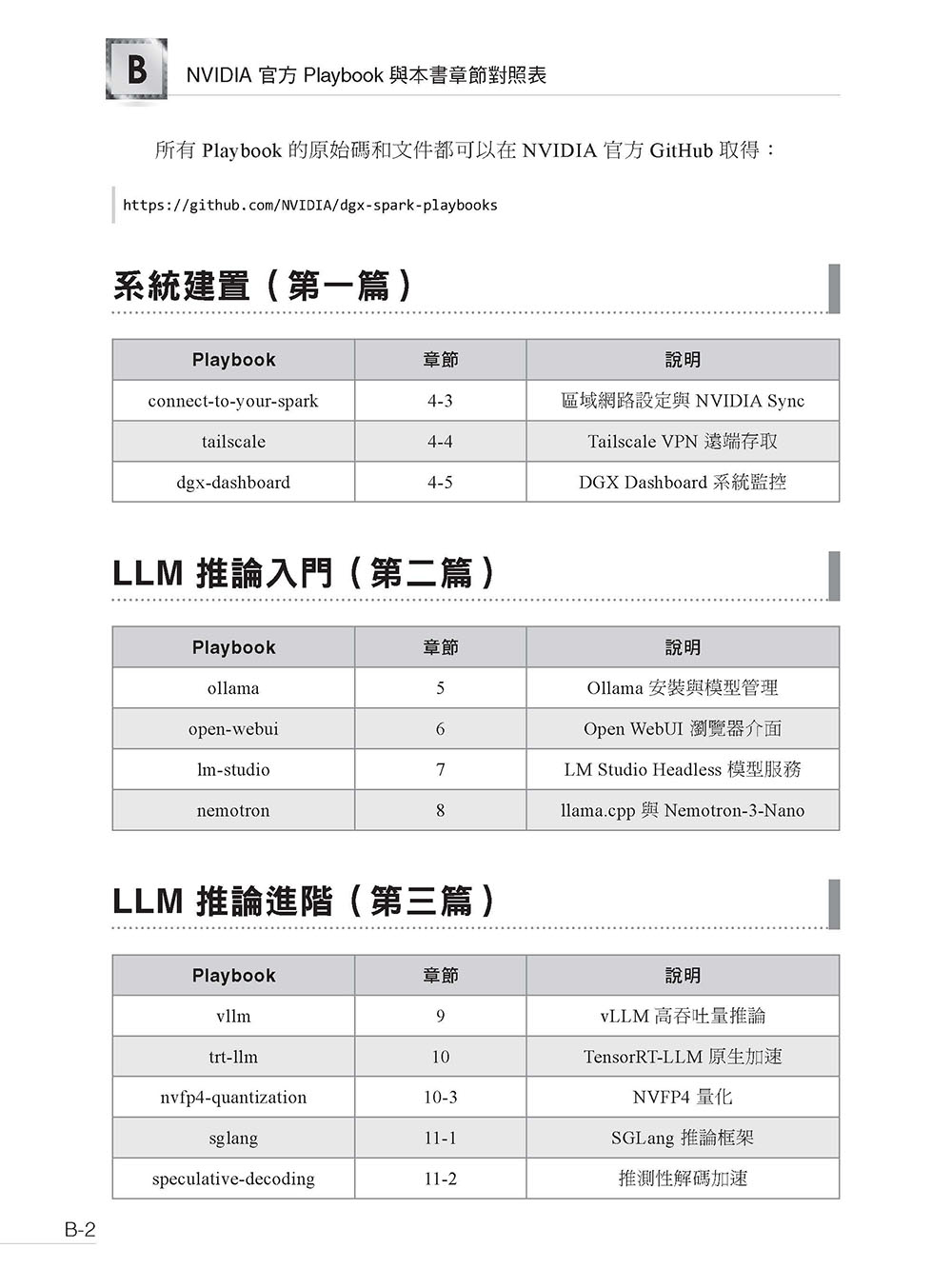
附錄B NVIDIA 官方 Playbook 與本書章節對照表 系統建置(第一篇) LLM 推論入門(第二篇) LLM 推論進階(第三篇) 多媒體 AI 生成(第四篇) 模型微調與訓練(第五篇) 多模態 AI 與智慧代理(第六篇) 多機互連(第七篇)
附錄C 推薦模型清單與效能基準數據 文字語言模型(LLM) 圖片生成模型 影片生成模型 語音與音訊模型 視覺語言模型(VLM) 128 GB 記憶體使用建議
附錄D 常見問題與故障排除(FAQ) GPU 與驅動相關 Docker 相關 Ollama 相關 網路與遠端存取 微調相關 多機互連
附錄E DGX Spark 硬體規格速查表 核心規格 GPU 運算能力 網路介面 連接埠 電力與散熱 軟體環境 外觀尺寸與消費級 GPU 比較 |
序
| 序言
2024 年底,我在 NVIDIA 的發表會上第一次看到 DGX Spark 的實機。一台比鞋盒大不多少的機器,裡面塞著 Grace Blackwell 超級晶片和 128 GB 統一 記憶體。當時我心裡想的是:如果這東西放在我書桌上,我還需要雲端 GPU 嗎? 答案是,大部分情況下不需要了。 過去三年,AI 的發展速度讓所有人都措手不及。GPT-4 證明了大型語言模型的能力,Stable Diffusion 讓每個人都能生成圖片,Sora 和 Wan 把影片生成從科幻變成現實。但這些技術有一個共同的門檻:你需要一張夠大的 GPU。消費級顯示卡的 24 GB 記憶體,連一個 70B 的模型都塞不下。想跑 120B ?請上雲端,按小時計費。 DGX Spark 改變了這個局面。128 GB 的統一記憶體,不是 CPU 和 GPU 各自獨立的 128 GB,而是兩者共享的同一塊記憶體。這代表一個 120B 參數的語言模型可以完整載入,不需要做模型分片、不需要量化到面目全非、不需要把一半權重放在 CPU 上慢慢搬。Blackwell 架構的 NVFP4 量化更是把可用的模型範圍再往上推了一個等級。 這 128 GB 帶來的不只是「能跑更大的模型」這麼簡單。它讓一整類過去只存在於資料中心的工作流程,變成你在書桌上就能完成的事:用 Ollama 跑 Qwen3.5 122B 和人對話, 回答品質不輸雲端 API。用ComfyUI 跑 FLUX 12B 生成圖片,再用 Wan 2.2 14B 生成影片,全部在本機完成。用 Unsloth 微調一個 8B 模型,從準備資料到推論測試不到一小時。 用 vLLM 部署推論服務,PagedAttention 讓多人同時使用也不會爆記憶體。用RAPIDS cuDF 處理 8 GB 的資料集,速度比 pandas 快幾十倍。甚至可以從零開始預訓練一個小型語言模型,看著 loss 曲線一路往下掉。 兩台 DGX Spark 用一條 QSFP 傳輸線直連,就有 256 GB 和 200Gbps 的節點間頻寬。這足以跑 235B 參數的模型做分散式推論,而整個「叢集」就放在你書桌上,功耗不到 500W。 這本書記錄了我在 DGX Spark 上實際操作的每一個步驟。從第 5 章開始,所有操作都透過 Claude Code 完成,不手動編輯設定檔、不手動下載模型、不手動寫 Docker Compose。你告訴 Claude Code 你要做什麼,它幫你搞定。這不是偷懶,而是 2026 年寫程式和部署 AI 服務的正確方式。 NVIDIA 為 DGX Spark 提供了完整的官方 Playbook,涵蓋從系統設定到多機互連的所有操作。本書的 25 章完整覆蓋了每一個 Playbook,並且加入了大量實測截圖和效能數據。如果你拿到一台 DGX Spark,翻開這本書,從頭到尾跟著做,就能把這台機器的每一分能力都發揮出來。 最後要感謝的是 AI 本身。這本書的寫作過程大量使用了 Claude Code,從章節規劃、內容撰寫、程式碼測試到截圖生成,都有 AI 的參與。這不是為了炫技,而是親身示範本書的核心主張:AI 不是取代人,而是讓人能做到原本做不到的事。一個人加上一台 DGX Spark 加上 Claude Code,就能完成過去需要一整個團隊才能處理的工作量。 這就是 128 GB 放在桌上的意義。 Josh Hu 2026 年 4 月,台北 |