







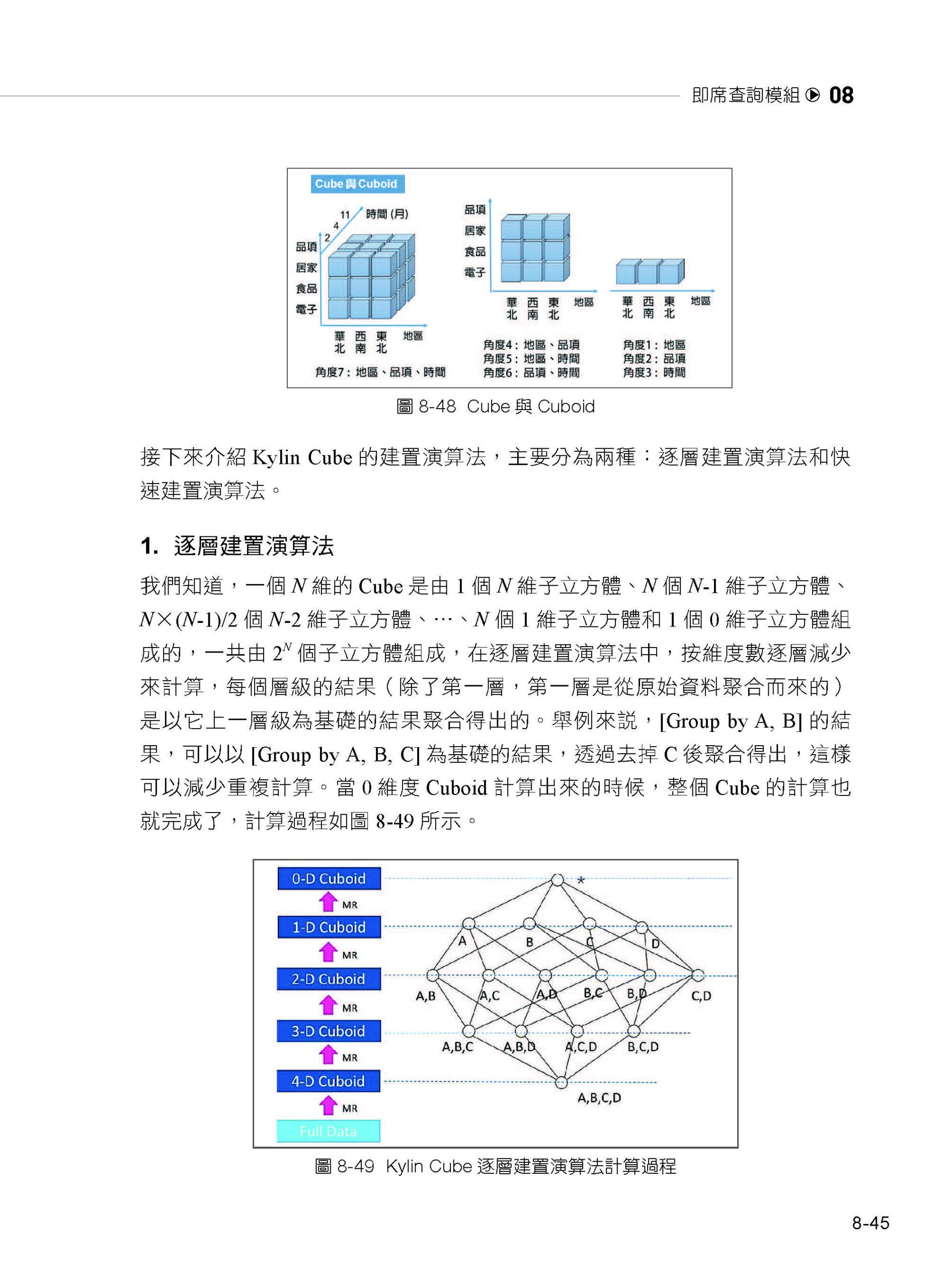
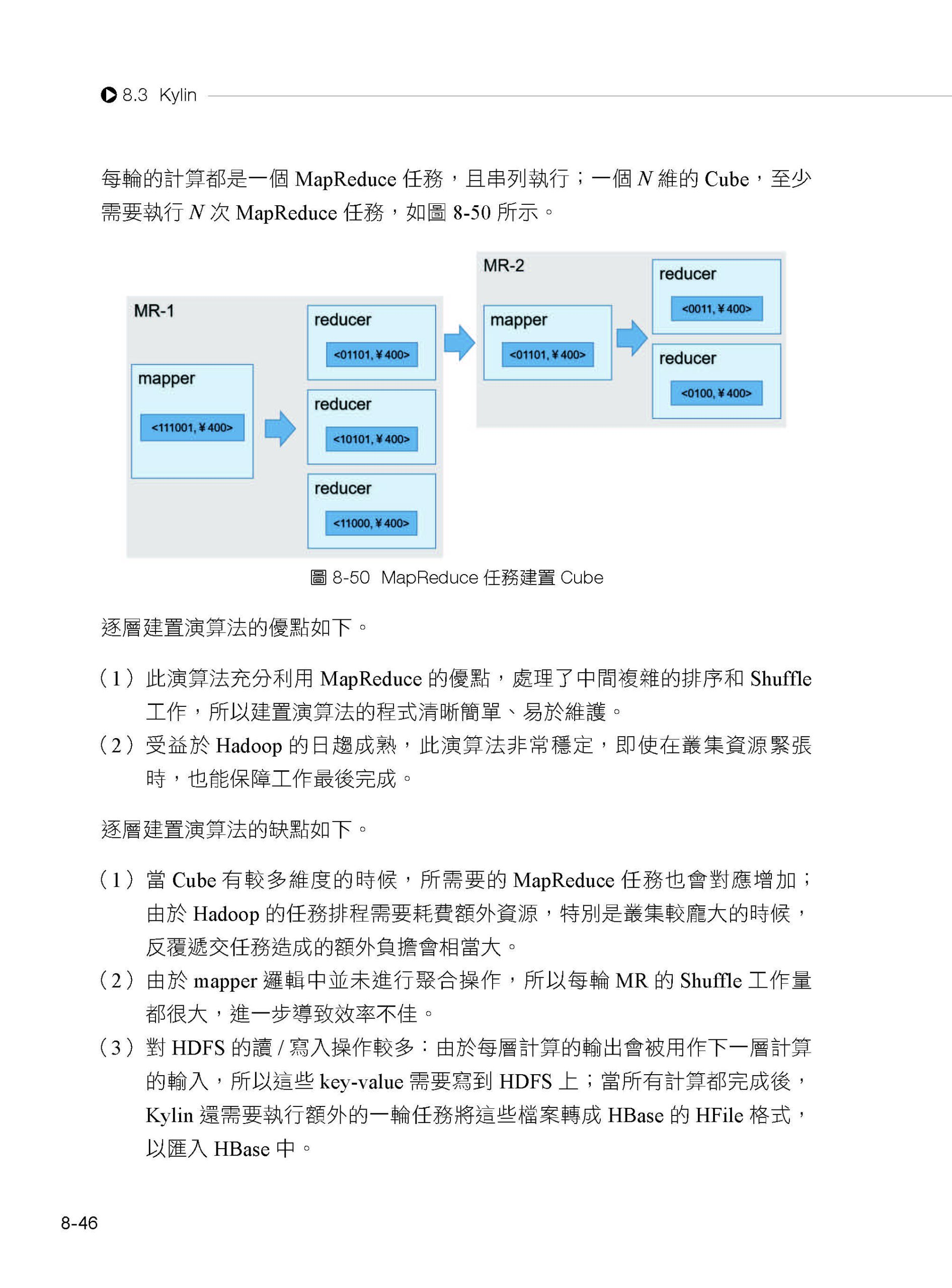
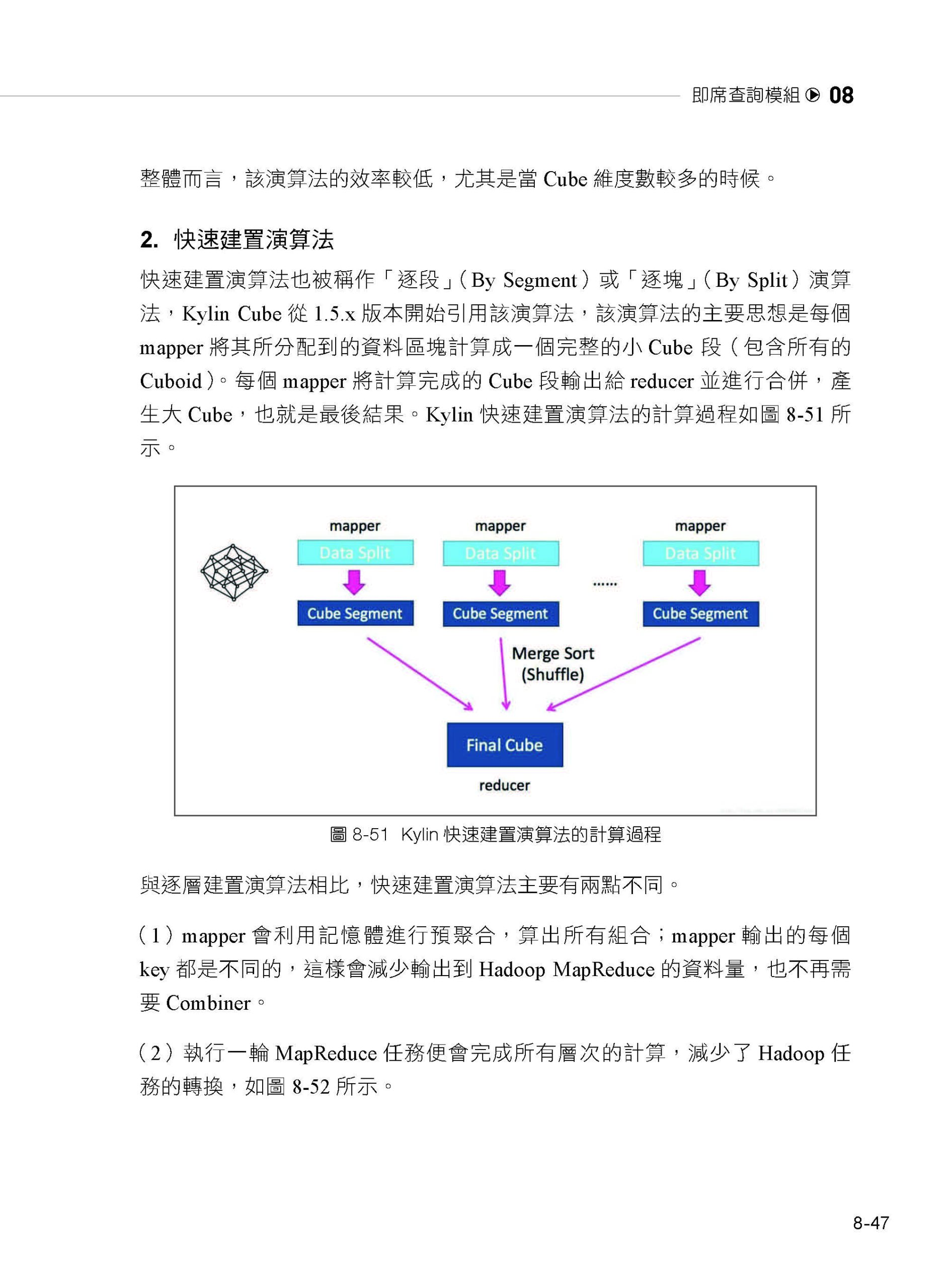
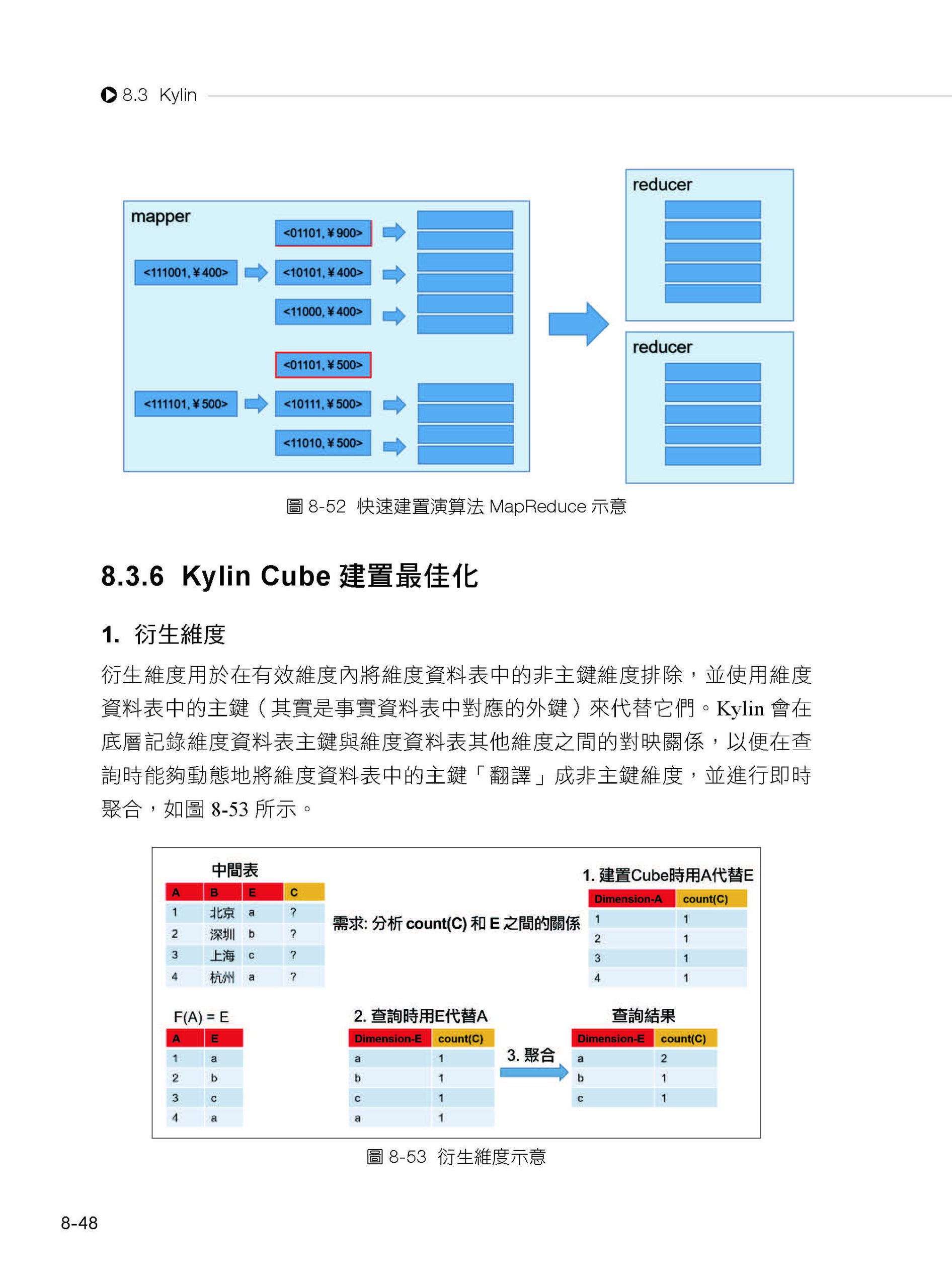


描述
- 別以為Hadoop熱潮已過,而是太成熟了!讓你親身體驗全世界最大的一流企業如何利用Hadoop生態圈實作真正電商資料庫架構。只會MySQL資料庫管理員,當心隨時被No-SQL時代淘汰!資料即現金,企業在儲存設備上的投資與日俱增,無不就是要將這些金砂給保存下來。但要處理這些大量的資料絕非易事。雖然Hadoop已經出現十多年,但其生態圈仍是企業處理巨量資料的主流。目前Hadoop生態圈的產品十分成熟,而圍繞著Hadoop生態圈的應用也越來越多。你所熟知的電商,都早就把這些技術完全用在自己的平台上了。世界一流企業的超強科技目前也下放到平民百姓家,這本書就是最好的例子。電商的資料表從來都是企業最高的機密,本書也將這些資料庫、資料表用Hadoop生態圈的技術完全實作出來。巨量資料時代,PB級的資料處理將是每個資料庫管理員都會面對的難題,先學先贏,不落人後。
- 內容簡介
本書按照需求規劃、需求實現、需求視覺化的流程進行編排,遵循專案開發的實際流程,全面介紹了資料倉庫的架設過程。在整個資料倉庫的架設過程中,本書介紹了主要元件的安裝部署過程、需求實現的實際思路、各種問題的解決方案等,並在其中穿插了許多與大數據和資料倉庫相關的理論知識,包含大數據概論、資料倉庫概論、電子商務業務概述、資料倉庫理論準備、資料倉庫建模等。
本書從邏輯上可以分為三部分:第一部分是大數據與資料倉庫概論及專案需求描述,主要介紹了資料倉庫的概念、應用場景和架設需求;第二部分是專案部署的環境準備,介紹了如何從零開始架設一個完整的資料倉庫環境;第三部分是需求模組實現,針對不同需求分模組進行實現,是本書的重點部分。
- 適合讀者
本書適合具有一定的程式設計基礎並對大數據有興趣的讀者閱讀。透過閱讀本書,讀者可以快速瞭解資料倉庫,全面掌握資料倉庫的相關技術。
作者簡介
尚矽谷IT教育
尚矽谷IT教育是一家專業的IT培訓機構,一直以「讓天下沒有難學的技術」為己任,至今已累計發布了上萬集視頻教程,廣受讚譽,並透過線下實訓培養了數萬名學員走上了軟體開發之路。
本書為尚矽谷研究院,集合多年教學、研究的經驗,出版的系列專業技術圖書之一。
目錄
01 巨量資料與資料倉儲概論
1.1 巨量資料概論
1.2 資料倉儲概論
1.3 學前導讀
1.4 本章歸納
02 專案需求描述
2.1 任務概述
2.2 業務描述
2.3 系統執行環境
2.4 本章歸納
03 專案部署的環境準備
3.1 Linux 環境準備
3.2 Linux 環境設定
3.3 Hadoop 環境架設
3.4 本章歸納
04 使用者行為資料獲取模組
4.1 記錄檔產生
4.2 擷取記錄檔的Flume
4.3 訊息佇列Kafka
4.4 消費Kafka 記錄檔的Flume
4.5 擷取通道啟動、停止指令稿
4.6 本章歸納
05 業務資料獲取模組
5.1 電子商務業務概述
5.2 業務資料獲取
5.3 本章歸納
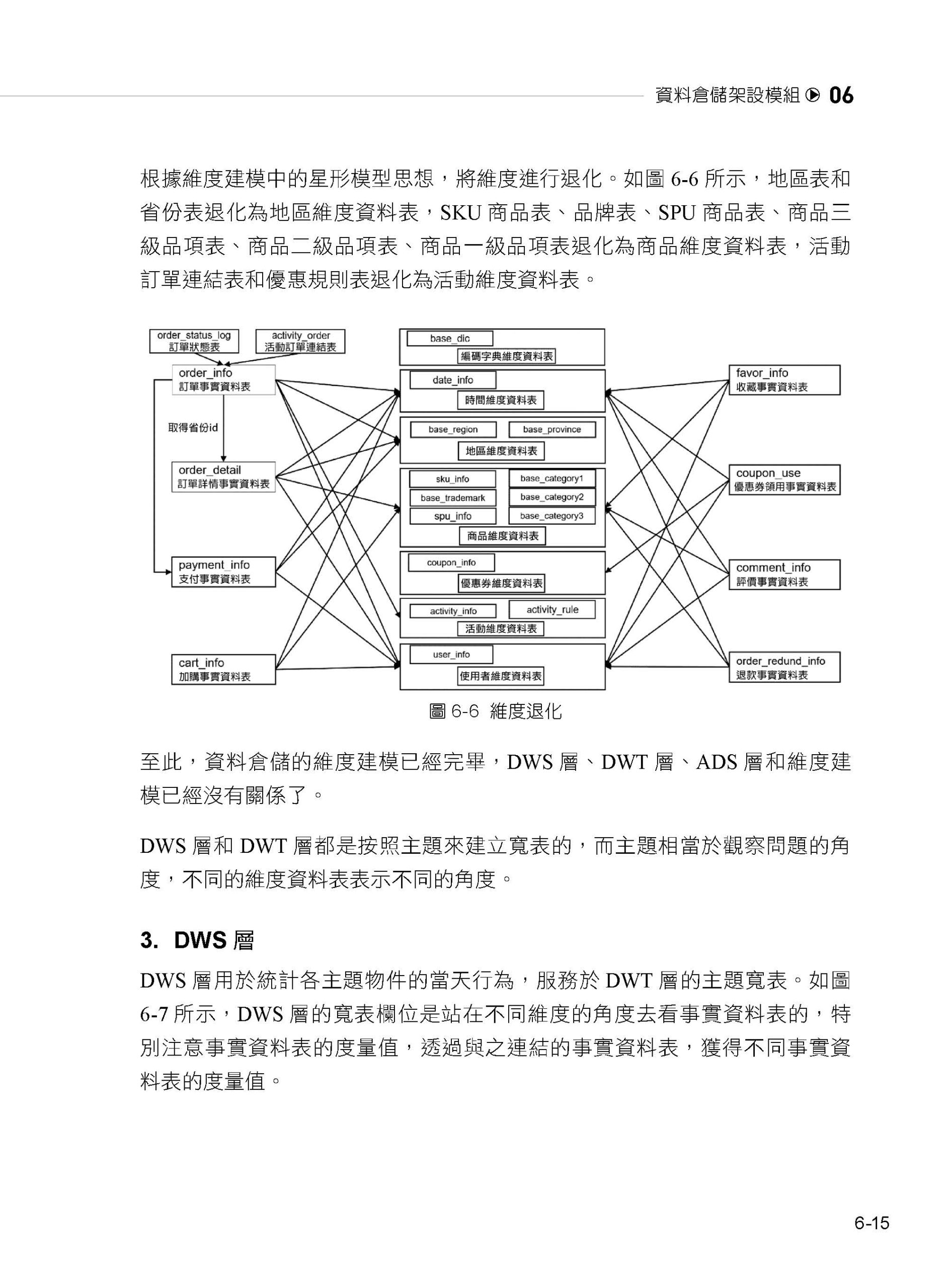
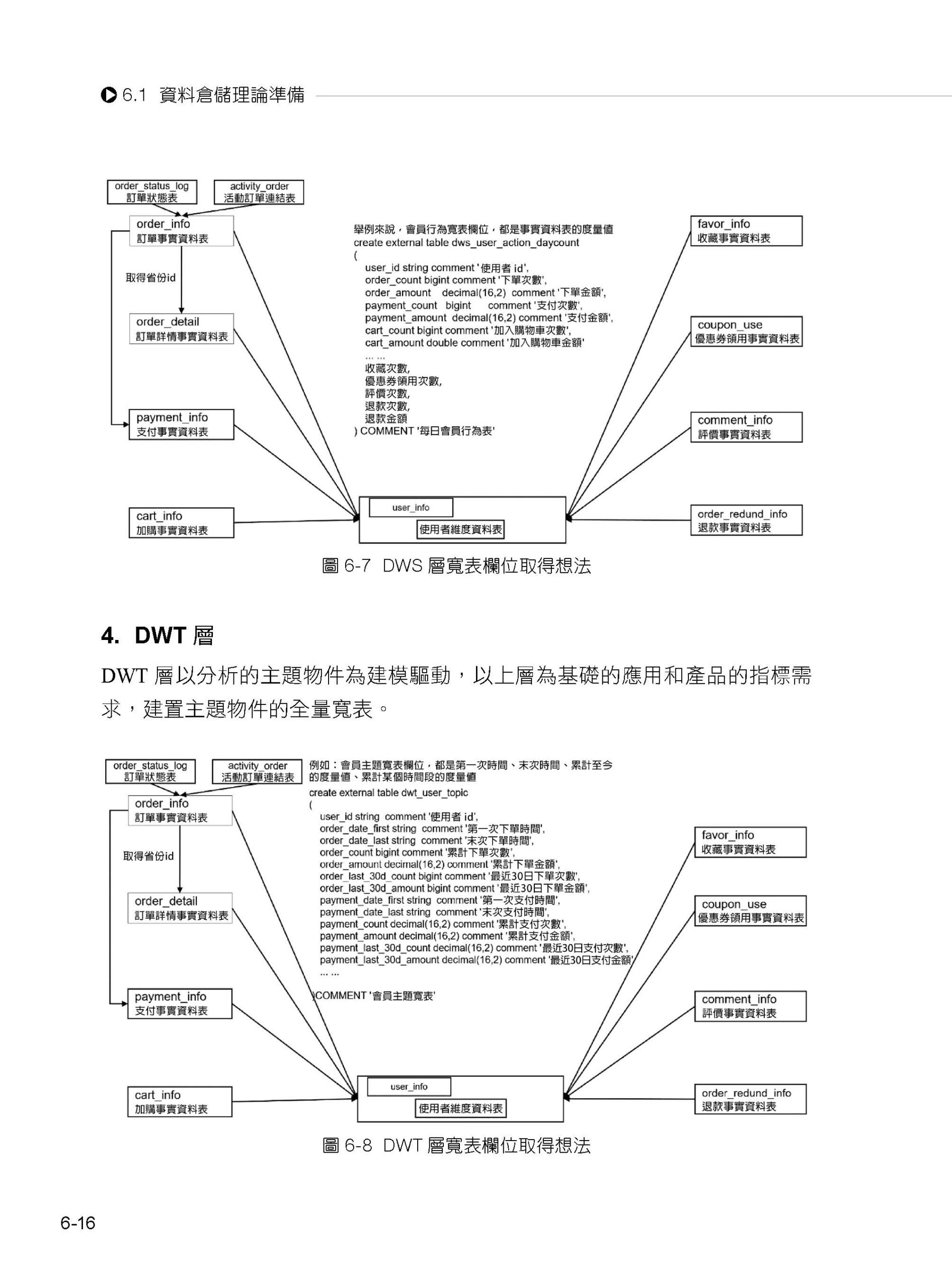
06 資料倉儲架設模組
6.1 資料倉儲理論準備
6.2 資料倉儲架設環境準備
6.3 資料倉儲架設—ODS 層
6.4 資料倉儲架設—DWD 層
6.5 資料倉儲架設—DWS 層
6.6 資料倉儲架設—DWT 層
6.7 資料倉儲架設—ADS 層
6.8 結果資料匯出指令稿
6.9 會員主題指標取得的全排程流程
6.10 本章歸納
07 資料視覺化模組
7.1 模擬視覺化資料
7.2 Superset 部署
7.3 Superset 使用
7.4 本章歸納
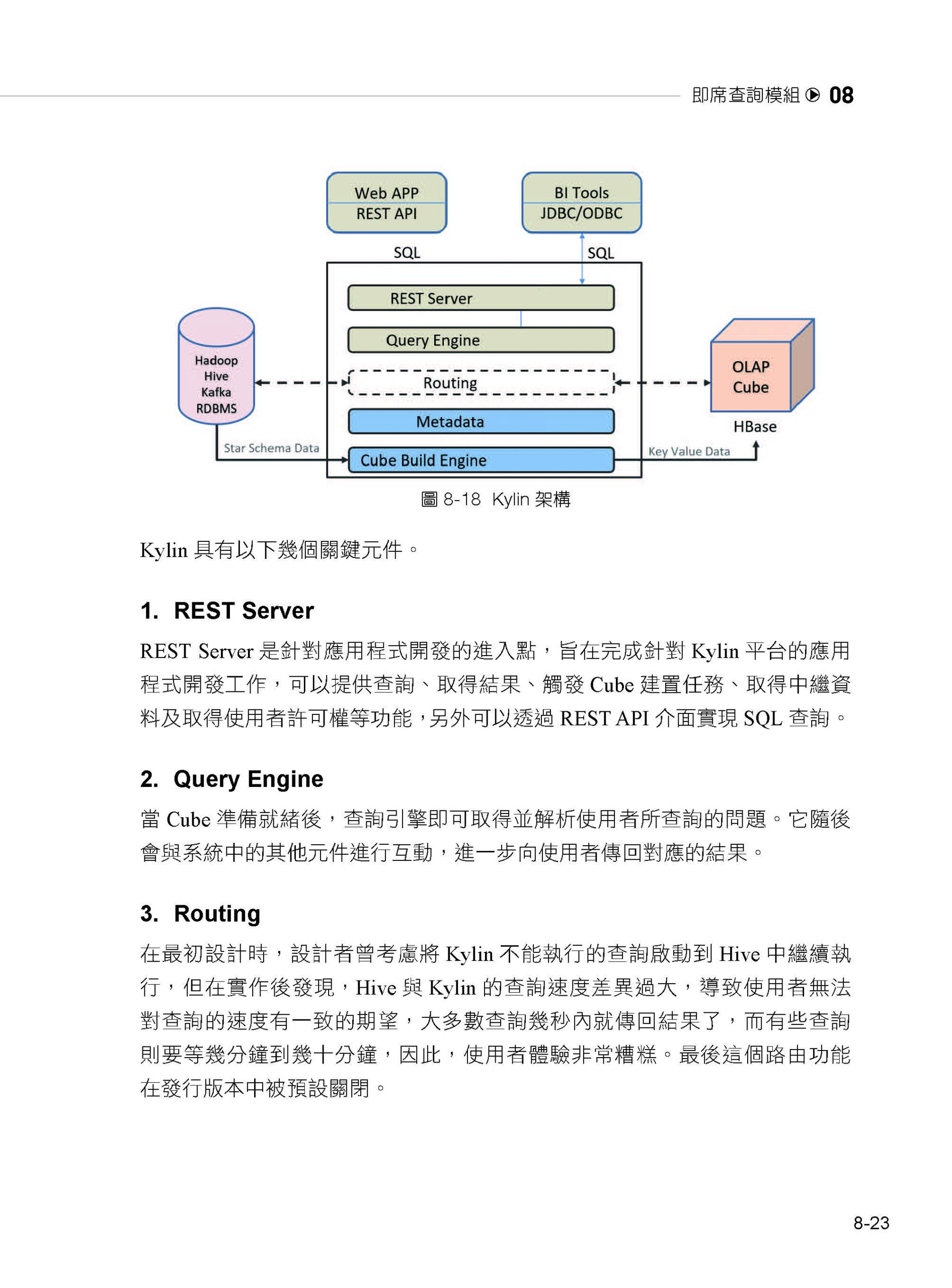
08 即席查詢模組
8.1 Presto
8.2 Druid
8.3 Kylin
8.4 即席查詢架構比較
8.5 本章歸納
09 中繼資料管理模組
9.1 Atlas 入門
9.2 Atlas 安裝及使用
9.3 Atlas 介面檢視及使用
9.4 本章歸納
序
前言
巨量資料發展至今,早已不是一個新興詞語,巨量資料的應用已經無處不在。在巨量資料時代,我們面臨的不僅是巨量的資料,更重要的是巨量資料所帶來的資料的擷取、儲存、處理等各方面的問題。為了更快速、更全面地展示巨量資料的實作應用,本書以一個資料倉儲專案為切入點,帶領讀者一步步揭開巨量資料的面紗。
資料倉儲專案是學習巨量資料的重要基礎。本書以資料倉儲的架設為主線,從架設之初的架構選型、資料服務的整體策劃到資料的流向,資料的擷取、儲存和計算,循序漸進,一步步地展開,進行細緻剖析。在對資料傳輸過程的說明中,穿插了資料倉儲的相關理論知識及巨量資料關鍵架構元件的說明,務求讓讀者對巨量資料有更深刻的了解,更加全面地了解巨量資料生態系統。
本書共9 章,包含巨量資料與資料倉儲概論、專案需求描述、專案部署的環境準備、使用者行為資料獲取模組、業務資料獲取模組、資料倉儲架設模組、資料視覺化模組、即席查詢模組、中繼資料管理模組。
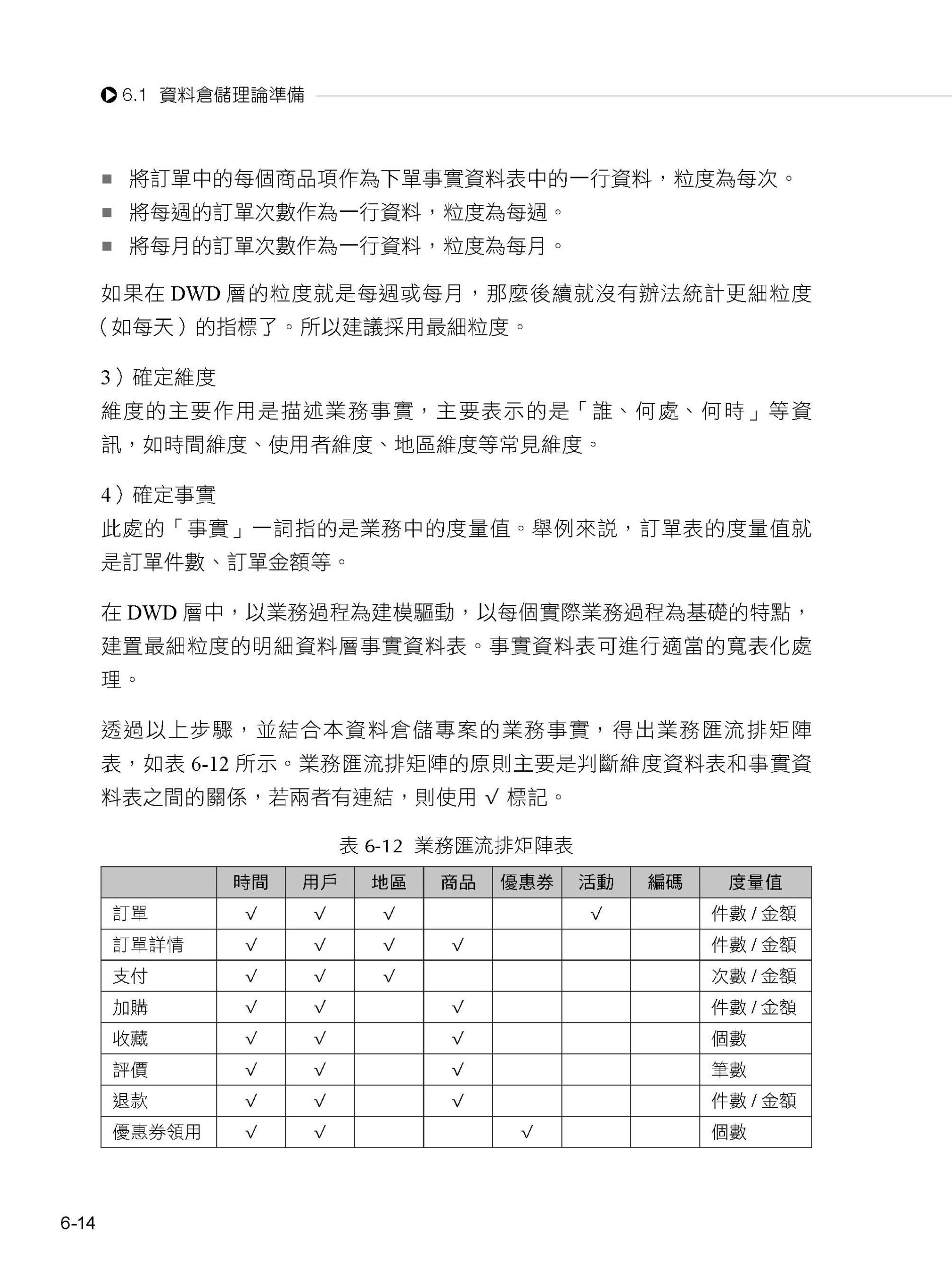
本專案採用主流的資料倉儲建模方式(確定業務過程、宣告粒度、確定維度、確實事實),覆蓋目前主流架構——擷取,Flume/Kafka/Sqoop;儲存,MySQL/Hadoop/HBase; 計算,Hive/Tez; 查詢,Presto/Druid/Kylin; 視覺化,Superset;任務排程,Azkaban;中繼資料管理,Atlas;指令稿,Shell。整套專案包含業務指標近100 個、Shell 指令稿40 多個、使用者行為原始表11 張,業務原始表24 張、資料倉儲總表近100 張。閱讀本書要求讀者具有一定的程式設計基礎,至少掌握一種程式語言(如Java)及SQL 查詢語言。








