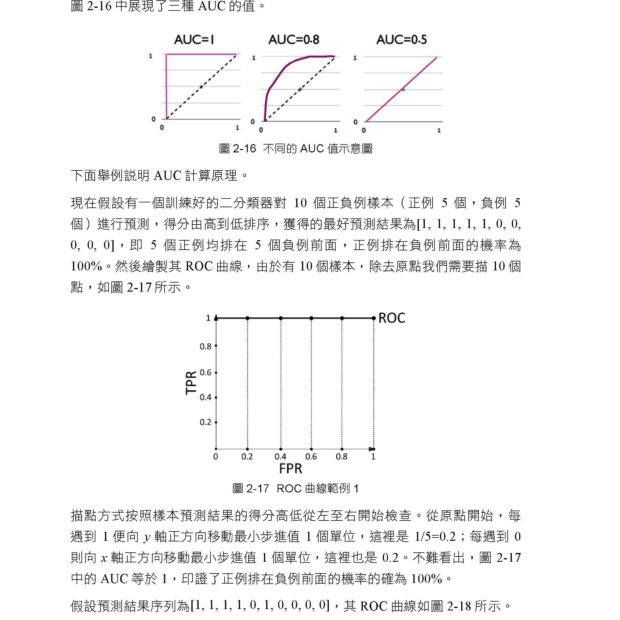








描述
內容簡介
Big Data + 機器學習,同時滿足儲存及運算,用Flink+Alink打造全智慧大數據平台
▌業界唯一
Flink是一個開放原始碼的分散式巨量資料處理引擎與計算框架。專門針對無界資料流程和有界資料流程進行統一處理,是業界唯一開放原始碼的分散式巨量資料處理引擎與計算框架。
▌最大特色
Flink最大的特色,就是能進行有狀態或無狀態的計算,對無界資料流程和有界資料流程進行統一處理,並且是一個開放原始碼的分散式巨量資料處理引擎與計算框架。
▌功能強大
Flink功能強大,可進行的資料處理包括即時資料處理、特徵工程、歷史資料(有界資料)處理、連續資料管道應用、機器學習、圖表分析、圖型計算、容錯的資料流程處理等。
市面上幾乎沒有介紹Flink的中文書籍,更別說Flink的最佳幫手機器學習Alink了。Alink號稱中文社區三大機器學習平台,擁有完整的生態系,本書最後兩章使用了Alink實作了一個推薦系統的實戰,這種只運用在巨型商業網站上的服務,現在也走入你我生活,讓我們也可以一窺高手養成的全貌,讓自己也邁向大師之列。
適合讀者
閱讀本書的讀者不需要具備巨量資料理論知識,也不需要懂得Hadoop、Spark、Storm 等巨量資料領域的知識,但是需要具備一定的Java 語言開發基礎(或至少使用過一種開發語言)。
作者簡介
龍中華
擁有10多年一線企業開發經驗。對多種技術有深入瞭解和研究,致力於用技術為公司業務創造利潤。
曾在多家公司擔任主程式設計師和系統架構師,現就職於某大數據研究機構,擔任技術顧問。
目錄
- 第 1 篇 入門篇
01 進入巨量資料和人工智慧世界
1.1 認識巨量資料和人工智慧
1.2 認識Flink
1.3 認識Alink
1.4 如何使用本書的原始程式
02 實例1:使用Flink 的4種API 處理無界資料流程和有界資料流程
2.1 創建Flink 應用程式
2.2 使用DataSet API 處理有界資料流程
2.3 使用DataStream API 處理無界資料流程
2.4 使用Table API 處理無界資料流程和有界資料流程
2.5 使用SQL 處理無界資料流程和有界資料流程
2.6 生成執行計畫圖
- 第 2 篇 基礎篇 ●
03 概覽Flink
3.1 了解流處理和批次處理
3.2 Flink 的整體架構
3.3 Flink 的程式設計介面
3.4 Flink 的專案依賴
3.5 了解分散式執行引擎的環境
04 Flink 開發基礎
4.1 開發Flink 應用程式的流程
4.2 處理參數
4.3 自訂函數
4.4 資料類型和序列化
05 Flink 的轉換運算元
5.1 定義鍵
5.2 Flink 的通用轉換運算元
5.3 Flink 的DataSet API 專用轉換運算元
5.4 Flink 的DataStream API 專用轉換運算元
5.5 認識低階流處理運算元
5.6 疊代運算
- 第 3 篇 進階篇 ●
06 使用DataSet API 實現批次處理
6.1 DataSet API 的資料來源
6.2 操作函數中的資料物件
6.3 語義註釋
6.4 認識分散式快取和廣播變數
07 使用DataStream API 實現流處理
7.1 認識DataStream API
7.2 視窗
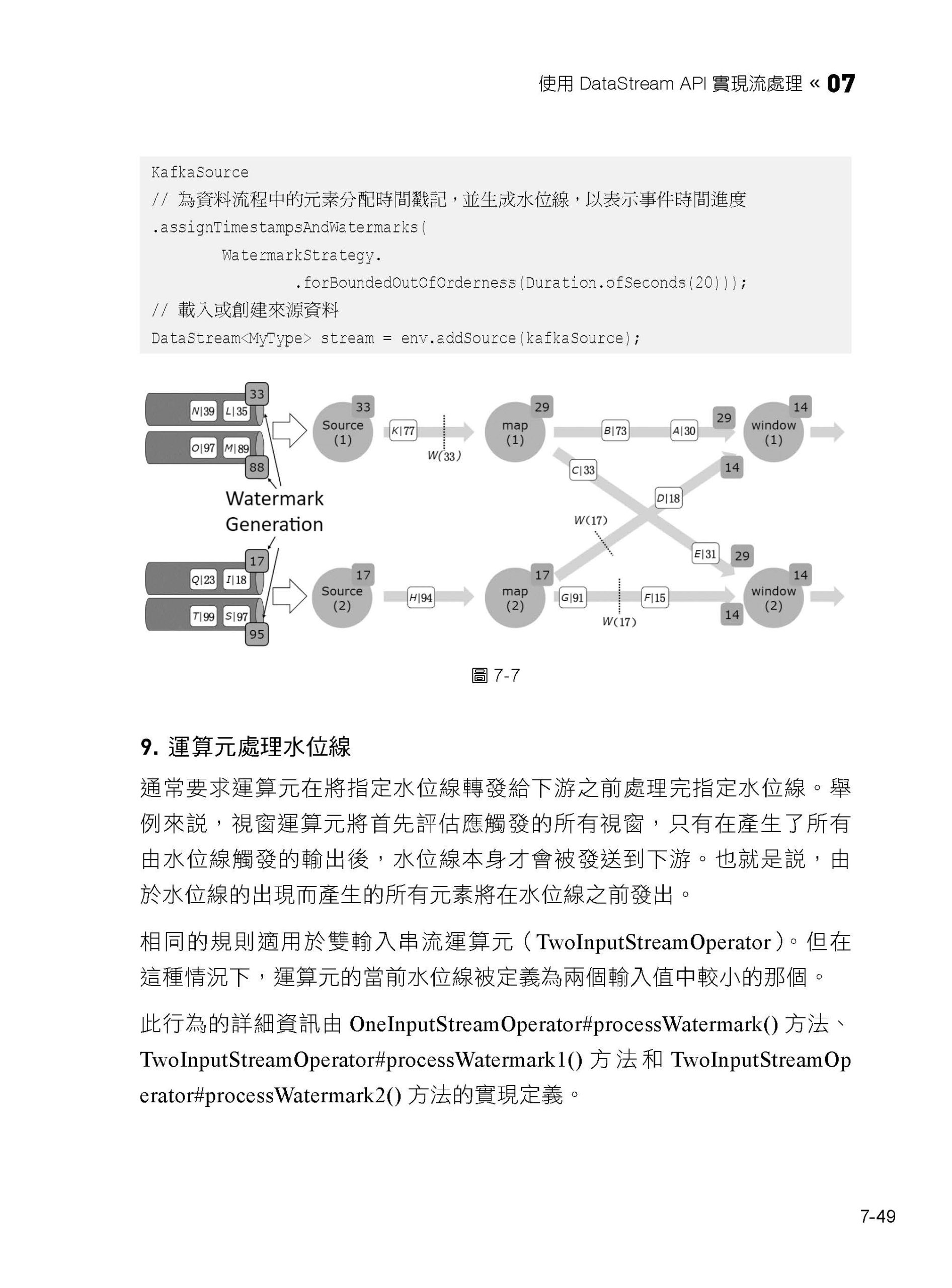
7.3 認識時間和水位線生成器
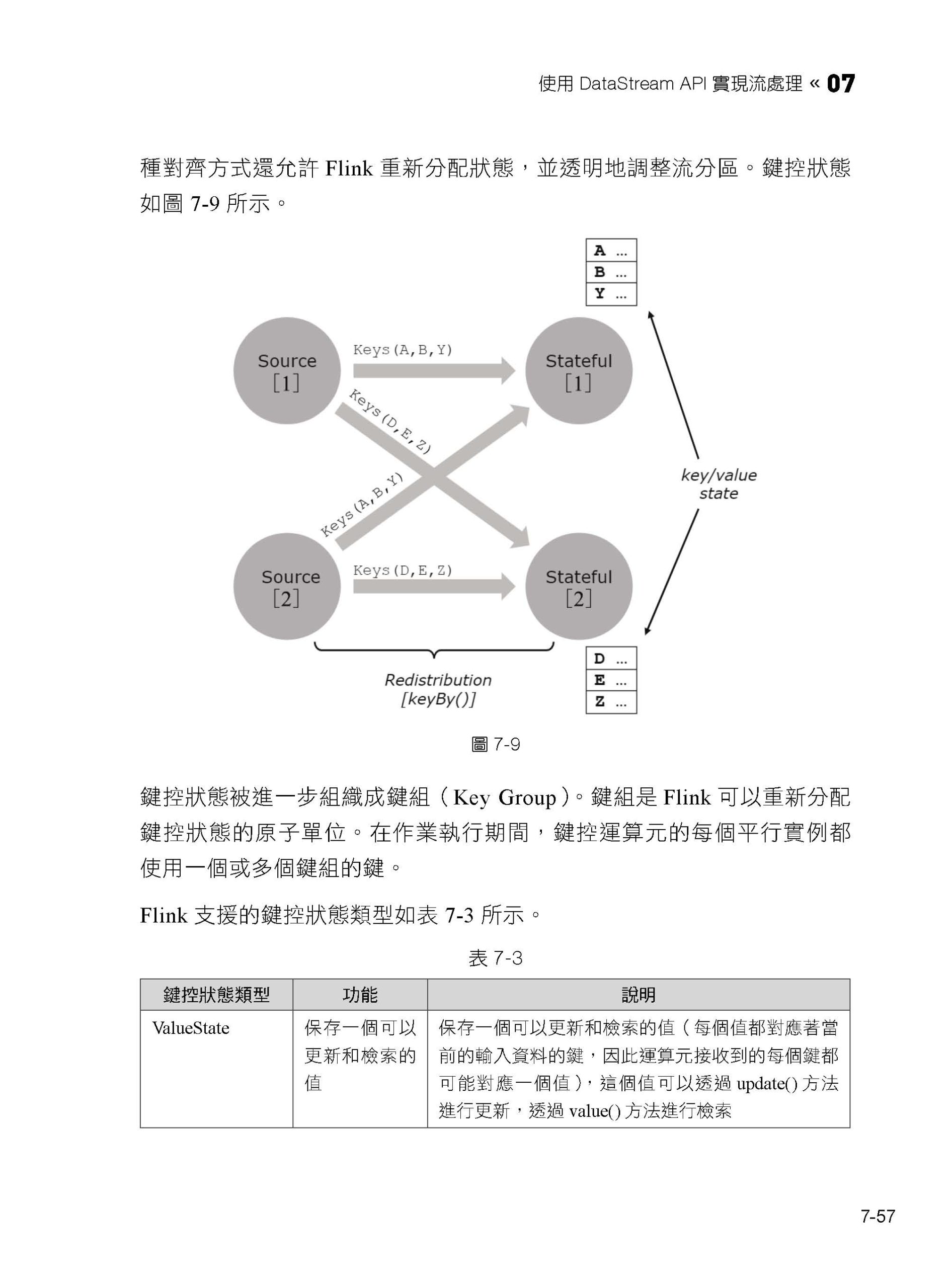
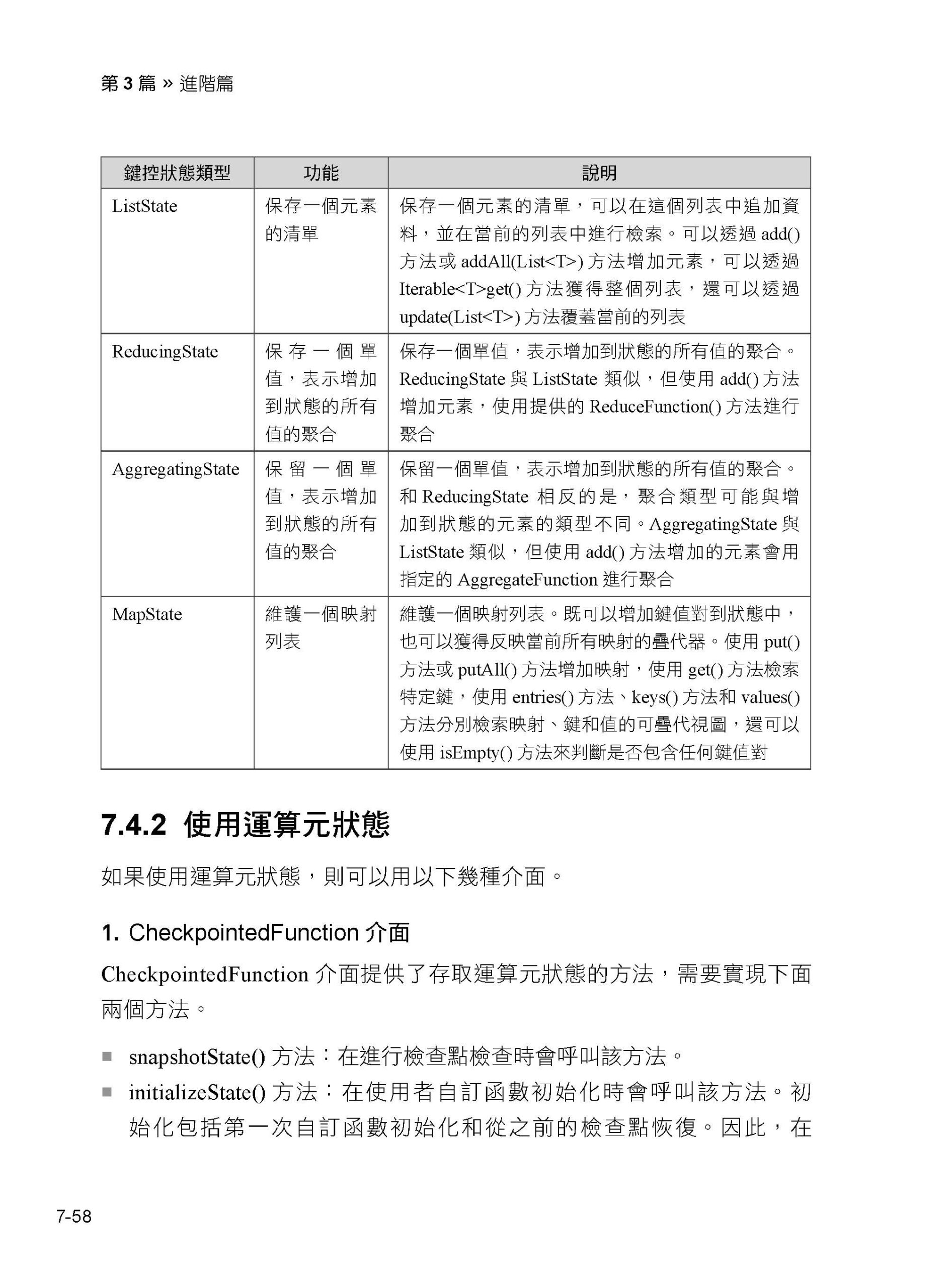
7.4 狀態
7.5 狀態持久化
7.6 旁路輸出
7.7 資料處理語義
7.8 實例33:自訂事件時間和水位線
08 使用狀態處理器API—State Processor API
8.1 認識狀態處理器API
8.2 將應用程式狀態映射到DataSet
8.3 讀取狀態
8.4 編寫新的保存點
8.5 修改保存點
8.6 實例34:使用狀態處理器API 寫入和讀取保存點
09 複雜事件處理函數庫
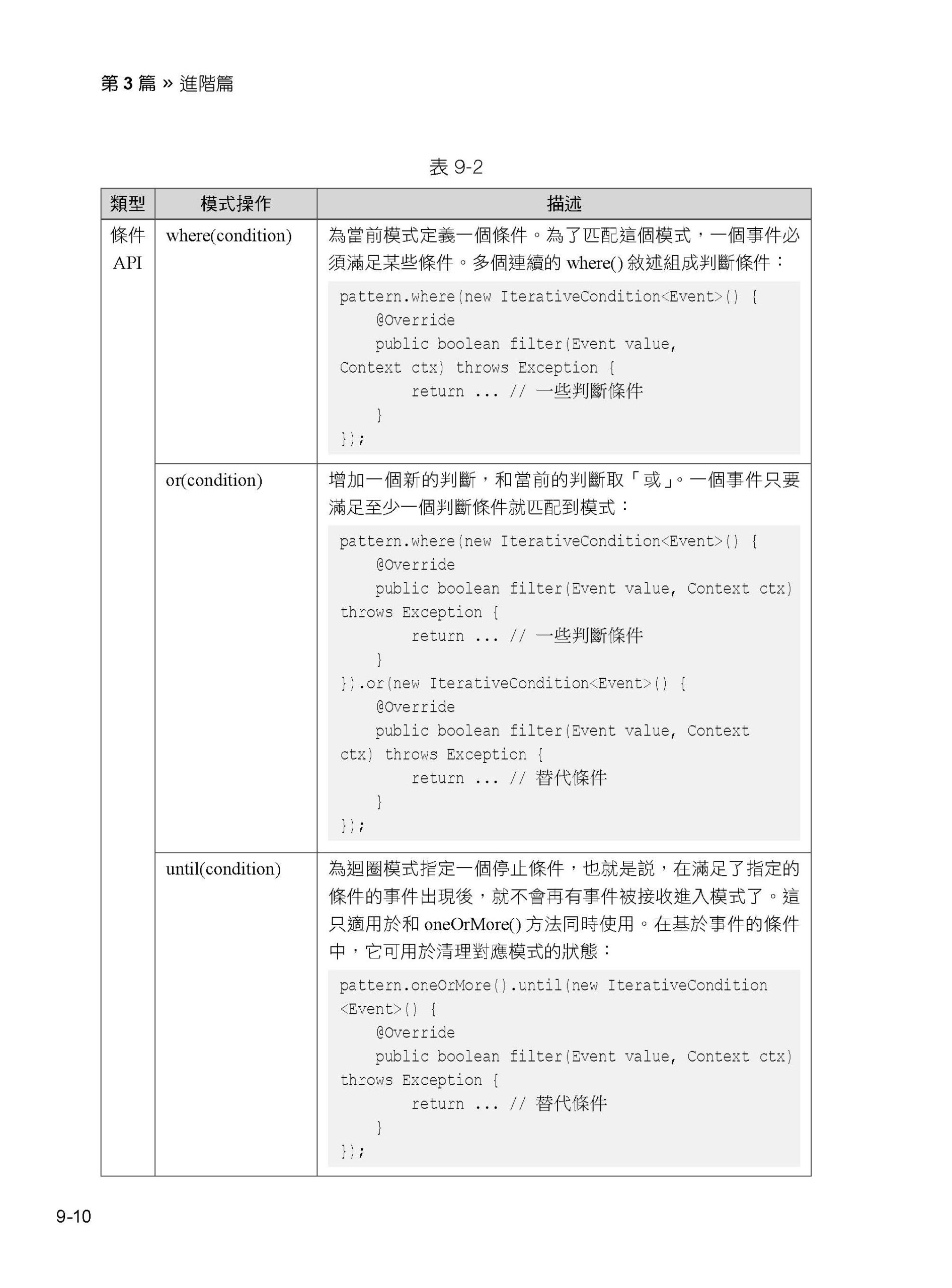
9.1 認識複雜事件處理函數庫
9.2 實例35:實現3 種模式的CEP 應用程式
9.3 認識模式API
9.4 檢測模式
9.5 複雜事件處理函數庫中的時間
10 使用Table API 實現流/批統一處理
10.1 Table API 和SQL
10.2 Table API 和SQL 的「流」的概念
10.3 Catalog
10.4 Table API、SQL 與DataStream和DataSet API 的結合
11 使用SQL 實現流/ 批統一處理
11.1 SQL 用戶端
11.2 SQL 敘述
11.3 變更資料獲取
11.4 認識流式聚合
11.5 實例43:使用DDL 創建表,並進行流式視窗聚合
12 整合外部系統
12.1 認識Flink 的連接器
12.2 非同步存取外部資料
12.3 外部系統拉取Flink 資料
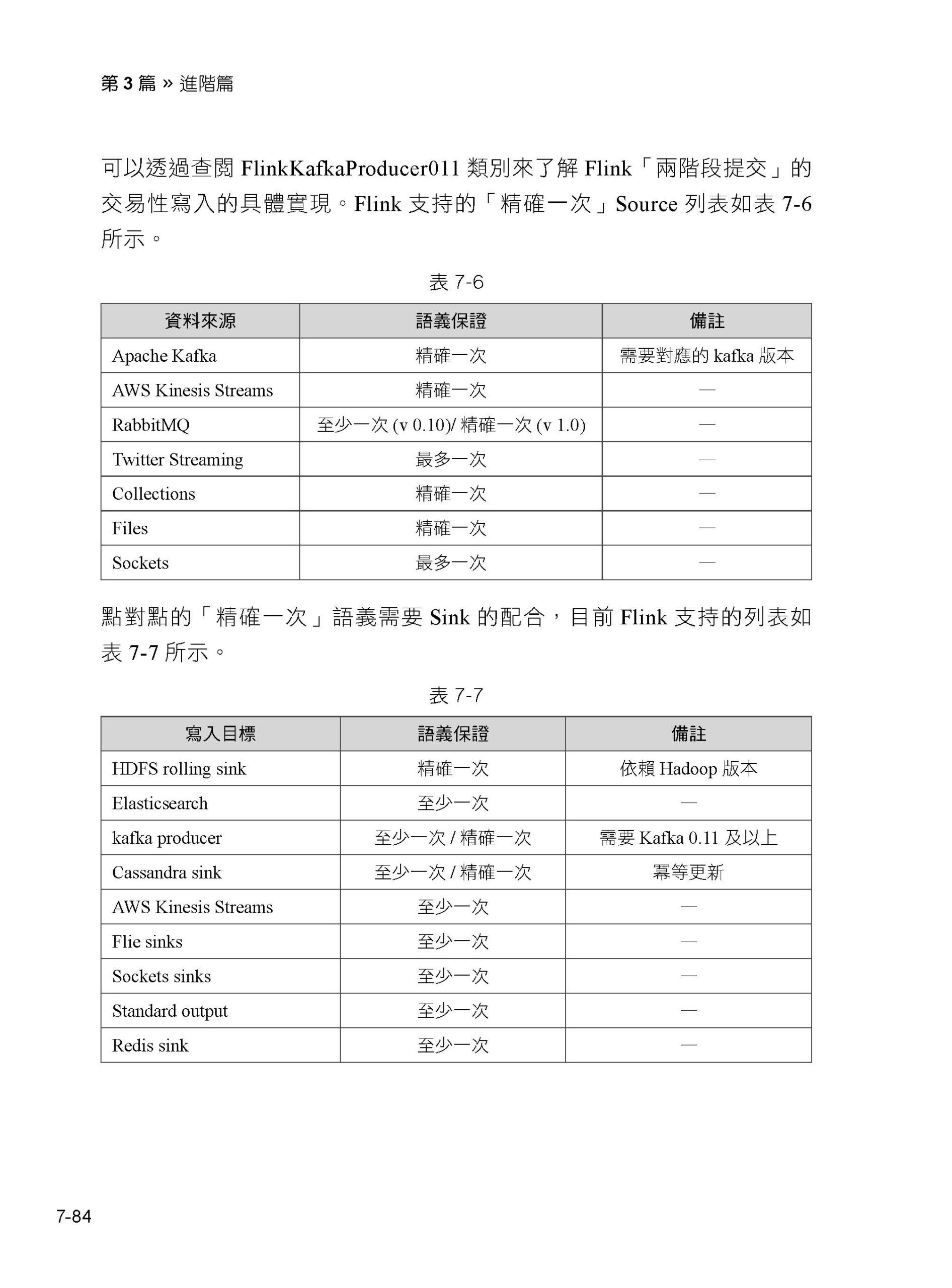
12.4 認識Flink 的Kafka 連接器
12.5 實例44:在Flink 中生產和消費Kafka 訊息
- 第 4 篇 機器學習篇
13 進入機器學習世界
13.1 學習人工智慧的經驗
13.2 認識機器學習
13.3 機器學習的主要任務
13.4 開發機器學習應用程式的基礎
13.5 機器學習的分類
13.6 了解機器學習演算法
13.7 機器學習的評估模型
14 流/ 批統一的機器學習框架(平台)Alink
14.1 認識Alink 的概念和演算法函數庫
14.2 實例45:以流/批方式讀取、取樣和輸出資料集
14.3 實例46:使用分類演算法實現資料的情感分析
14.4 實例47:實現協作過濾式的推薦系統
- 第 5 篇 專案實戰篇
15 實例48:使用巨量資料和機器學習技術實現一個廣告推薦系統
15.1 了解實例架構
15.2 了解推薦系統
15.3 認識線上學習演算法
15.4 實現機器學習
15.5 實現連線服務層
15.6 日誌打點和監測
A 附錄
A-1 難懂概念介紹
A-2 Flink 常見問題整理
A-3 Alink 常見問題整理
序
為了滿足企業巨量資料和人工智慧團隊的教育訓練需求,作者編寫了大量相關的教育訓練文件,但是這些文件主要是針對臨時需求製作的,內容較多,整體上較為零散,不利於企業新同事的系統化學習。另外,官方文件雖然編寫得很好,但基礎知識的遞進關係並不理想,並且晦澀難懂。因此,作者整理了這些教育訓練文件,並且反覆推敲章節的遞進關係,以及基礎知識的串聯方式、基礎知識與實例的實用性,最終完成了本書的編寫。
本書特色
■ 版本較新:針對 Flink 1.11 版本和 Alink 1.2 版本。
■ 實例科學:採用“基礎知識 + 實例"的形式編寫。
■ 實例豐富:47 個基礎實例 + 1 個專案實例。
■ 跨界整合:①講解了 4 種開發 Flink 應用程式的 API,即 DataSet API、
DataStream API、Table API 和SQL 相關知識;②講解了狀態處理器API、複雜事件處理庫,以及常用的訊息中介軟體Kafka;③講解了巨量資料和人工智慧的結合,以及機器學習框架Alink。
■ 編排講究:本書涉及的術語儘量做到有跡可循,每一個術語都盡可能在前面的章節中有所描述。章節遞進關係清楚,內容順序合理,從頭到尾邏輯連貫。
適合讀者
本書是否適合你,取決於你之前的知識、經驗儲備和學習目標。作者建議讀者根據本書目錄來進行判斷,閱讀本書的讀者不需要具備巨量資料理論知識,也不需要懂得Hadoop、Spark、Storm 等巨量資料領域的知識,但是需要具備一定的Java 語言開發基礎(或至少使用過一種開發語言)。
本書編寫環境
■ Flink 版本:1.11。
■ Alink 版本:1.2(基於 Flink 1.11)。
■ 開發工具:IntelliJ IDEA 付費版,以及社區版。
■ JDK 版本:8u211。
■ Maven 版本:3.6.1。
■ Zookeeper 版本:3.6.1。
■ Kafka 版本:2.6.0(基於 Scala 2.12)。
■ MySQL:8.0.21.0(需要支援 Binlog)。
致謝
感謝Flink 社區、Flink 中文社區開放原始碼貢獻者,以及Alink 開發團隊和開放原始碼貢獻者的奉獻。Flink 和Alink 的官方網站提供了豐富的文件和註釋詳盡的開原始程式碼,作者在編寫本書的過程中參考了很多相關的文件。巨量資料領域、Flink 和Alink 技術博大精深,由於本書篇幅有限,作者的精力和技術也有限,因此書中難免存在不足之處,敬請讀者們批評指正。聯絡作者請發電子郵件至363694485@qq.com。
龍中華