











描述
內容簡介
| 不止量化及LORA - 原生PyTorch性能及記憶體優化精解
✴︎深入介紹深度學習硬體,包括 CPU、GPU、記憶體與分散式系統。 ✴︎系統化學習 PyTorch 張量、運算元、自動微分與動態圖機制。 ✴︎提供 PyTorch 性能分析工具,幫助診斷與提升執行效率。 ✴︎優化資料載入與前處理,提升 Dataset 與 DataLoader 效能。 ✴︎介紹單卡 GPU 訓練最佳化,如 Batch Size 調整與同步減少。 ✴︎探討 GPU 記憶體管理,降低訓練時的記憶體佔用與浪費。 ✴︎解析分散式訓練,涵蓋資料平行、模型平行與多機多卡技術。 ✴︎涵蓋高級最佳化,如混合精度、自訂運算元與計算圖優化。 ✴︎深入解析 GPT-2 訓練最佳化,提供實戰經驗與效能提升。 ✴︎從程式碼到硬體調校,建立高效 PyTorch 訓練與開發流程。 |
作者簡介
|
目錄
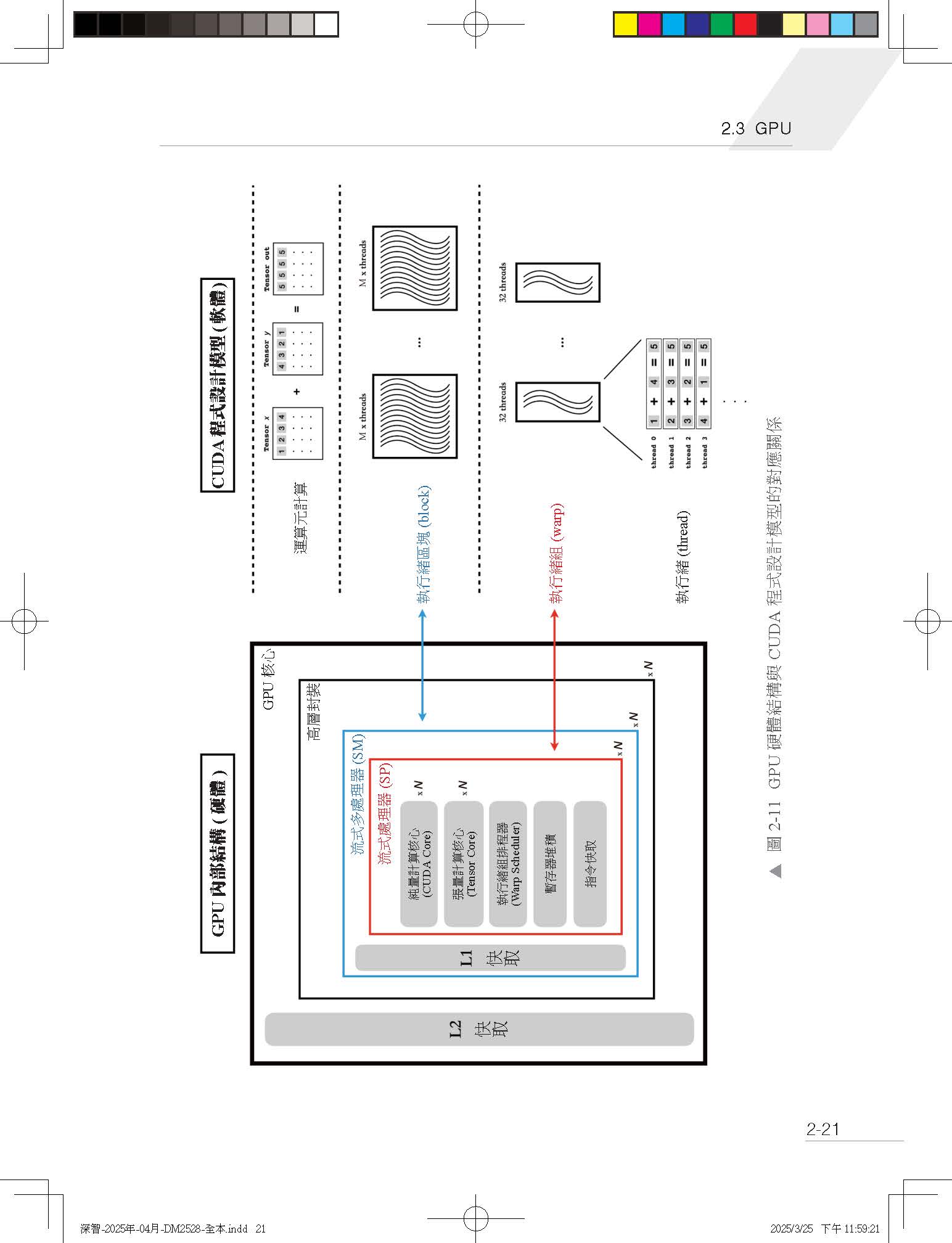
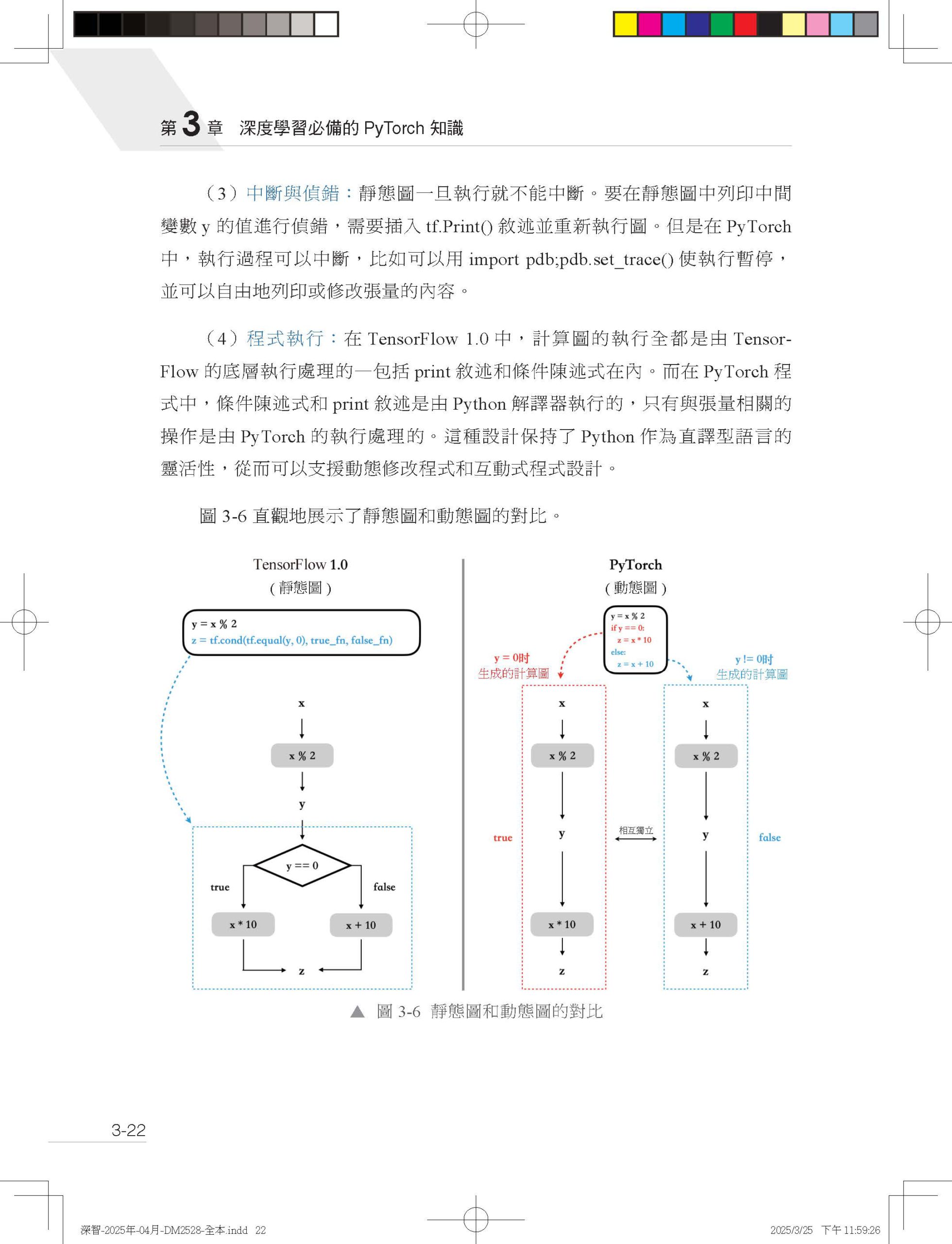
| 第 1 章 歡迎來到這場大模型競賽
1.1 模型規模帶來的挑戰 1.2 資料規模帶來的挑戰 1.3 模型規模與資料增長的應對方法 第 2 章 深度學習必備的硬體知識 2.1 CPU 與記憶體 2.1.1 記憶體 2.1.2 CPU 2.2 硬碟 2.3 GPU 2.3.1 CPU 的局限性 2.3.2 GPU 的硬體結構 2.3.3 GPU 程式設計模型及其硬體對應 2.3.4 GPU 的關鍵性能指標 2.3.5 顯示記憶體與記憶體間的資料傳輸 2.4 分散式系統 2.4.1 單機多卡的通訊 2.4.2 多機多卡的通訊 2.4.3 分散式系統的資料儲存 第 3 章 深度學習必備的 PyTorch 知識 3.1 PyTorch 的張量資料結構 3.1.1 張量的基本屬性及建立 3.1.2 存取張量的資料 3.1.3 張量的儲存方式 3.1.4 張量的視圖 3.2 PyTorch 中的運算元 3.2.1 PyTorch 的運算元函數庫 3.2.2 PyTorch 運算元的記憶體分配 3.2.3 運算元的呼叫過程 3.3 PyTorch 的動態圖機制 3.4 PyTorch 的自動微分系統 3.4.1 什麼是自動微分 3.4.2 自動微分的實現 3.4.3 Autograd 擴充自訂運算元 3.5 PyTorch 的非同步執行機制 第 4 章 定位性能瓶頸的工具和方法 4.1 配置性能分析所需的軟硬體環境 4.1.1 減少無關程式的干擾 4.1.2 提升PyTorch 程式的可重複性 4.1.3 控制GPU 頻率 4.1.4 控制CPU 的性能狀態和工作頻率 4.2 精確測量程式執行時間 4.2.1 計量CPU 程式的執行時間 4.2.2 程式預熱和多次執行取平均 4.2.3 計量GPU 程式的執行時間 4.2.4 精確計量GPU 的執行時間 4.3 PyTorch 性能分析器 4.3.1 性能分析 4.3.2 顯示記憶體分析 4.3.3 視覺化性能圖譜 4.3.4 如何定位性能瓶頸 4.4 GPU 專業分析工具 4.4.1 Nsight Systems 4.4.2 Nsight Compute 4.5 CPU 性能分析工具 4.5.1 Py-Spy 4.5.2 strace 4.6 本章小結 第 5 章 資料載入和前置處理專題 5.1 資料連線的準備階段 5.2 資料集的獲取和前置處理 5.2.1 獲取原始資料 5.2.2 原始資料的清洗 5.2.3 資料的離線前置處理 5.2.4 資料的儲存 5.2.5 PyTorch 與第三方函數庫的互動 5.3 資料集的載入和使用 5.3.1 PyTorch 的 Dataset 封裝 5.3.2 PyTorch 的 DataLoader 封裝 5.4 資料載入性能分析 5.4.1 充分利用CPU 的多核心資源 5.4.2 最佳化CPU 上的計算負載 5.4.3 減少不必要的CPU 執行緒 5.4.4 提升磁碟效率 5.5 本章小結 第 6 章 單卡性能最佳化專題 6.1 提高資料任務的平行度 6.1.1 增加資料前置處理的平行度 6.1.2 使用非同步介面提交資料傳輸任務 6.1.3 資料傳輸與GPU 計算任務平行 6.2 提高GPU 計算任務的效率 6.2.1 增大BatchSize 6.2.2 使用融合運算元 6.3 減少CPU 和GPU 間的同步 6.4 降低程式中的額外銷耗 6.4.1 避免張量的建立銷耗 6.4.2 關閉不必要的梯度計算 6.5 有代價的性能最佳化 6.5.1 使用低精度資料進行裝置間拷貝 6.5.2 使用性能特化的最佳化器實現 6.6 本章小結 第 7 章 單卡顯示記憶體最佳化專題 7.1 PyTorch 的顯示記憶體管理機制 7.2 顯示記憶體的分析方法 7.2.1 使用PyTorch API 查詢當前顯示記憶體狀態 7.2.2 使用PyTorch 的顯示記憶體分析器 7.3 訓練過程中的顯示記憶體佔用 7.4 通用顯示記憶體重複使用方法 7.4.1 使用原位操作運算元 7.4.2 使用共用儲存的操作 7.5 有代價的顯示記憶體最佳化技巧 7.5.1 跨批次梯度累加 7.5.2 即時重算前向張量 7.5.3 將GPU 顯示記憶體下放至CPU 記憶體 7.5.4 降低最佳化器的顯示記憶體佔用 7.6 最佳化Python 程式以減少顯示記憶體佔用 7.6.1 Python 垃圾回收機制 7.6.2 避免出現迴圈依賴 7.6.3 謹慎使用全域作用域 7.7 本章小結 第 8 章 分散式訓練專題 8.1 分散式策略概述 8.2 集合通訊基本操作 8.3 應對資料增長的平行策略 8.3.1 資料平行策略 8.3.2 手動實現資料平行算法 8.3.3 PyTorch 的DDP 封裝 8.3.4 資料平行的C/P 值 8.3.5 其他資料維度的切分 8.4 應對模型增長的平行策略 8.4.1 靜態顯示記憶體切分 8.4.2 動態顯示記憶體切分 8.5 本章小結 第 9 章 高級最佳化方法專題 9.1 自動混合精度訓練 9.1.1 浮點數的表示方法 9.1.2 使用低精度資料型態的優缺點 9.1.3 PyTorch 自動混合精度訓練 9.2 自訂高性能運算元 9.2.1 自訂運算元的封裝流程 9.2.2 自訂運算元的後端程式實現 9.2.3 自訂運算元匯入Python 9.2.4 自訂運算元匯入PyTorch 9.2.5 在Python 中使用自訂運算元 9.3 基於計算圖的性能最佳化 9.3.1 torch.compile 的使用方法 9.3.2 計算圖的提取 9.3.3 圖的最佳化和後端程式生成 9.4 本章小結 第 10 章 GPT-2 最佳化全流程 10.1 GPT 模型結構簡介 10.2 實驗環境與機器配置 10.3 顯示記憶體最佳化 10.3.1 基準模型 10.3.2 使用跨批次梯度累加 10.3.3 開啟即時重算前向張量 10.3.4 使用顯示記憶體友善的最佳化器模式 10.3.5 使用分散式方法降低顯示記憶體佔用—FSDP 10.3.6 顯示記憶體最佳化小結 10.4 性能最佳化 10.4.1 基準模型 10.4.2 增加 BatchSize 10.4.3 增加資料前置處理的平行度 10.4.4 使用非同步介面完成資料傳輸 10.4.5 使用計算圖最佳化 10.4.6 使用float16 混合精度訓練 10.4.7 (可選)使用自訂運算元 10.4.8 使用單機多卡加速訓練 10.4.9 使用多機多卡加速訓練 10.4.10 性能最佳化小結 結語 |
序
| 2022年底,由OpenAI 發佈的ChatGPT 展現了人工智慧(Artificial Intelligence,AI)與人類進行流暢對話和問答的專業能力,剛一發佈就引發了巨大關注。作為生成式AI 領域的第一個現象級產品,ChatGPT 已經在搜尋、程式設計、客服等多個領域顯著提升了人類的工作效率。人們不僅對AI 模型目前的能力感到驚訝,更對其跨行業多領域的應用潛力感到振奮,許多人甚至認為一個由人工智慧驅動的第四次工業革命已經拉開序幕。
ChatGPT 的成功不僅歸功於其出色的模型架構,還得益於其在工程方面的極致最佳化—這個龐大的模型基於巨量網際網路文字資料,在由超過一萬張GPU 組成的計算集群上進行了數月的訓練。這不僅需要在穩定性和性能方面對分散式訓練策略進行極致最佳化,還充分挑戰了當前軟體和硬體的極限,成為了AI 工程領域的里程碑。
AI 系統工程(AI Systems Engineering)是AI 演算法與系統的交叉領域。從訓練到部署,所有涉及軟體和計算叢集的部分幾乎都可以劃為AI 系統工程的範圍,包括持續最佳化的GPU 硬體架構、建立高速互聯的GPU 資料中心、開發使用者友善且可擴充的AI 框架等。目前市面上有許多關於AI 演算法和模型架構方面的書籍和課程,但關於AI 系統工程的資料卻非常缺乏。這些工程實踐技巧通常散落在使用者手冊、專家部落格,甚至GitHub 問題討論中,由於覆蓋面廣且基礎知識分散,新入行的工程師在系統性建構AI 系統工程知識 系統時面臨諸多挑戰。
因此,本書致力於實現以下兩個目標:
• 從深度學習訓練的角度講解AI 工程中必要的軟硬體元件,幫助讀者系統性地了解深度學習性能問題的根源。詳盡分析硬體參數和軟體特性對訓練效果的影響,並提供了一套從定位問題、分析問題到解決問題的流程。
• 深入探討應對資料和模型規模快速增長的具體策略。從顯示記憶體最佳化到訓練加速,從單機單卡到分散式訓練的最佳化,系統地介紹提升模型訓練規模和性能的多種途徑。我們希望讀者能夠理解這些策略各自的優勢與侷限,並根據實際情況靈活應用。
本書將透過PyTorch 程式實例演示不同的特性和最佳化技巧,儘量避免使用晦澀難懂的公式,透過簡單的例子講清問題的來龍去脈。然而,AI 系統工程是個非常寬泛的交叉領域,無論是書籍的篇幅還是筆者的實際經驗都有一定的局限性,因此本書很難面面俱到地涵蓋所有內容,比如:
• 本書不涉及模型架構的演算法講解。我們假定讀者已經對要解決的問題和可能使用的模型架構有所了解,甚至已經有一些可執行的雛形程式,以此作為性能或顯示記憶體最佳化的基礎。
• 本書通常不會介紹PyTorch 等工具的API 介面和參數設置細節,除非這些資訊與最佳化直接相關。這類資訊在各工具的官方文件中已有詳盡的描述和豐富的程式範例,且可能隨版本更新發生變化。如果讀者在使用這些介面時遇到問題,建議直接參考相關文件。本書的目標並不是成為這些文件的中文版本,而是闡釋其中的原理和想法,讓讀者能夠更靈活地使用這些工具。
• 本書不涵蓋專門針對推理部署設計的演算法、性能最佳化和專用加速晶片等知識。模型推理的技巧通常與特定應用緊密相關,有時為了追求極致的性能,甚至需要採用一些非常規的技巧。因此,模型推理不是本書的重點,我們將聚焦於更具通用性的訓練部分。
• 本書在討論自訂運算元時會簡要提及CUDA 語言,但不會深入講解如何使用CUDA 撰寫高性能運算元。CUDA 身為專業性很強的程式語言,需要對GPU 硬體架構和平行計算有深入了解。然而,即使沒有CUDA相關背景,也不影響對本書內容的理解和應用。希望深入研究CUDA的讀者,可以在網上找到大量高品質的書籍和教學。
致謝 在本書的寫作和審閱過程中,我們獲得了許多朋友的寶貴幫助和支援。在此,特向他們表示誠摯的感謝。在技術內容方面,羅雨屏對全書進行了全面的審閱和指導;張雲明對第1章和第2章提出了寶貴的建議;劉家愷對第1章至第6章提出了寶貴的意見;蘭海東細緻審閱並修改了第2、3、6、7章;王宇軒對第2章進行了細緻的審閱和最佳化;許珈銘對第2章和第6章提供了具有建設性的建議;路浩對第3章和第4章進行了細緻的修訂;嚴軼飛對第4章進行了詳細的校訂,確保內容準確;蔣毓和田野為第5章提供了寶貴的回饋和審閱;王雨順對第7章進行了深入的改進;申晗對第7章至第9章提出了建設性的修改建議;與PrithviGudapati 的討論修正了書中設置PyTorch隨機數種子的方法。
在圖書策劃方面,姚麗斌、申美瑩和欒大成在全書的策劃和編輯過程中給予了寶貴的建議;王承宸為本書生成了清晰美觀的程式圖;戴國浩提供了實驗用的機器,確保了實驗的順利進行。
此外,在本書的寫作過程中,筆者借助了ChatGPT 進行大量文字潤色工作,大大提升了寫作效率。書中的圖表主要使用Keynote和FigJam進行製作,程式範例使用基於Carbon的命令列工具carbon-now-cli生成,非常感謝社區提供的這些工具程式。
最後,本書的寫作時間以及筆者的經驗有限,書中如有錯誤和疏漏,懇請讀者批評指正。 |