






描述
內容簡介
|
作者簡介
| 車萬翔
哈爾濱工業大學計算學部長聘教授 / 博士生導師、人工智慧研究院院長、國家級青年人才、龍江學者「青年學者」、史丹佛大學訪問學者。現任中國中文信息學會理事、計算語言學專業委員會副主任兼秘書長;國際計算語言學學會亞太分會(AACL)執委兼秘書長;國際頂級會議ACL 2025程序委員會共同主席。承擔國家自然科學基金重點項目和專項項目、2030「新一代人工智慧」重大項目課題等多項科研項目。曾獲AAAI 2013最佳論文提名獎、黑龍江省科技進步一等獎、黑龍江省青年科技獎等獎勵。 |
目錄
| ▌第一部分 基礎知識
第1章 緒論 1.1 自然語言處理的概念 1.2 自然語言處理的困難 1.3 自然語言處理任務系統 1.3.1 任務層級 1.3.2 任務類別 1.3.3 研究物件與層次 1.4 自然語言處理技術發展歷史
第2章 自然語言處理基礎 2.1 文字的表示 2.1.1 詞的獨熱表示 2.1.2 詞的分佈表示 2.1.3 詞嵌入表示 2.1.4 文字的詞袋表示 2.2 自然語言處理任務 2.2.1 自然語言處理基礎任務 2.2.2 自然語言處理應用任務 2.3 基本問題 2.3.1 文字分類問題 2.3.2 結構預測問題 2.3.3 序列到序列問題 2.4 評價指標 2.4.1 自然語言理解類任務的評價指標 2.4.2 自然語言生成類任務的評價指標 2.5 小結
第3章 基礎工具集與常用資料集 3.1 tiktoken 子詞切分工具 3.2 NLTK 工具集 3.2.1 常用語料庫和詞典資源 3.2.2 常用自然語言處理工具集 3.3 LTP 工具集 3.3.1 中文分詞 3.3.2 其他中文自然語言處理功能 3.4 PyTorch 基礎 3.4.1 張量的基本概念 3.4.2 張量的基本運算 3.4.3 自動微分 3.4.4 調整張量形狀 3.4.5 廣播機制 3.4.6 索引與切片 3.4.7 降維與升維 3.5 大規模預訓練資料集 3.5.1 維基百科資料 3.5.2 原始資料的獲取 3.5.3 語料處理方法 3.5.4 其他文字預訓練資料集 3.5.5 文字預訓練資料集討論 3.6 更多資料集 3.7 小結
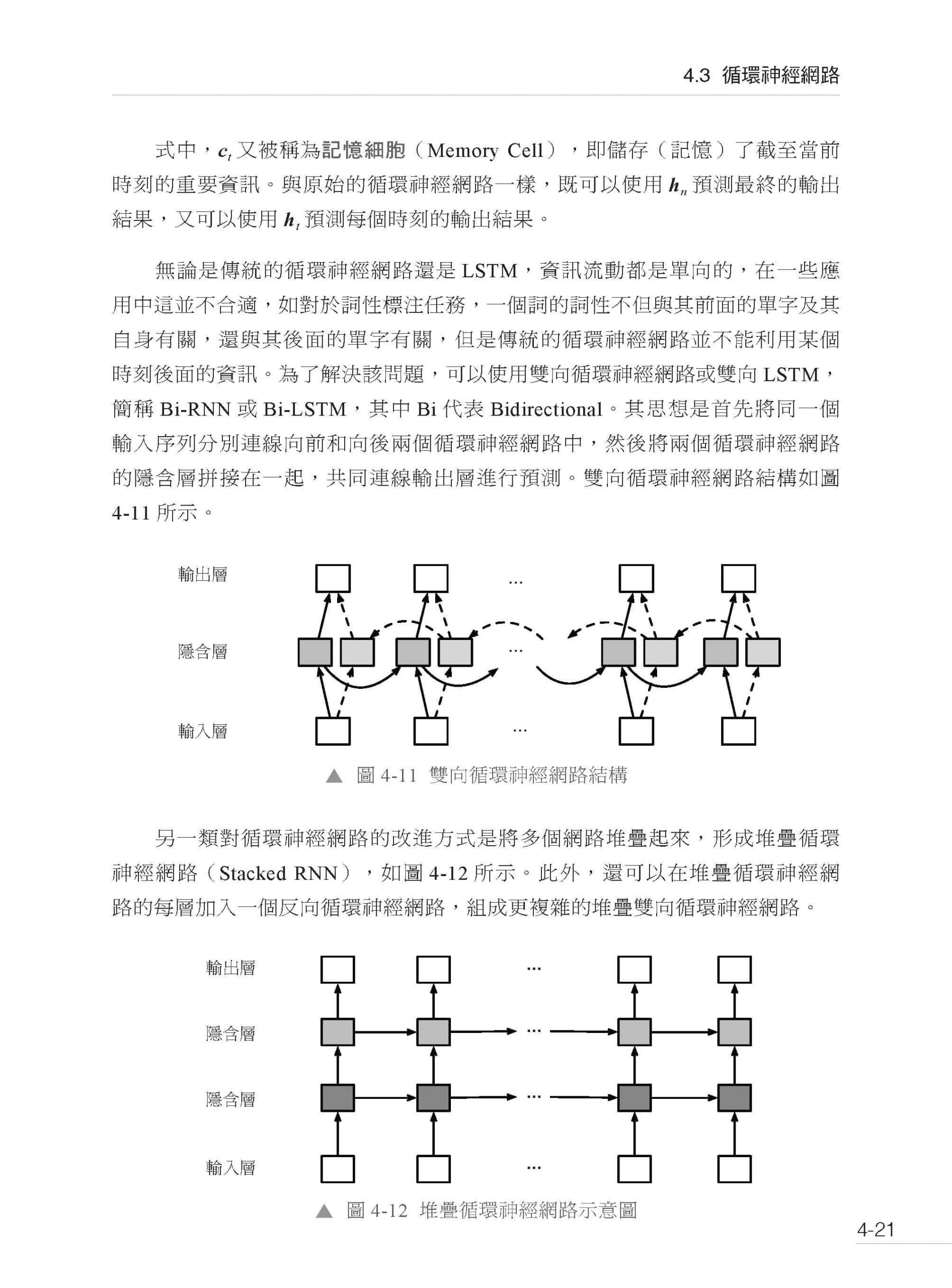
第4章 自然語言處理中的神經網路基礎 4.1 多層感知器模型 4.1.1 感知器 4.1.2 線性回歸 4.1.3 Logistic 回歸 4.1.4 Softmax 回歸 4.1.5 多層感知器 4.1.6 模型實現 4.2 卷積神經網路 4.2.1 模型結構 4.2.2 模型實現 4.3 循環神經網路 4.3.1 模型結構 4.3.2 長短時記憶網路 4.3.3 模型實現 4.3.4 基於循環神經網路的序列到序列模型 4.4 Transformer 模型 4.4.1 注意力機制 4.4.2 自注意力模型 4.4.3 Transformer 4.4.4 基於Transformer 的序列到序列模型 4.4.5 Transformer 模型的優缺點 4.4.6 PyTorch 內建模型實現 4.5 神經網路模型的訓練 4.5.1 損失函式 4.5.2 梯度下降 4.6 自然語言處理中的神經網路實戰 4.6.1 情感分類實戰 4.6.2 詞性標注實戰 4.7 小結
▌第二部分 預訓練語言模型
第5章 語言模型 5.1 語言模型的基本概念 5.2 N 元語言模型 5.2.1 N 元語言模型的基本概念 5.2.2 N 元語言模型的實現 5.2.3 N 元語言模型的平滑 5.3 神經網路語言模型 5.3.1 前饋神經網路語言模型 5.3.2 循環神經網路語言模型 5.3.3 Transformer 語言模型 5.3.4 基於神經網路語言模型生成文字 5.4 語言模型的實現 5.4.1 資料準備 5.4.2 前饋神經網路語言模型 5.4.3 循環神經網路語言模型 5.4.4 Transformer 語言模型 5.5 語言模型性能評價 5.6 小結
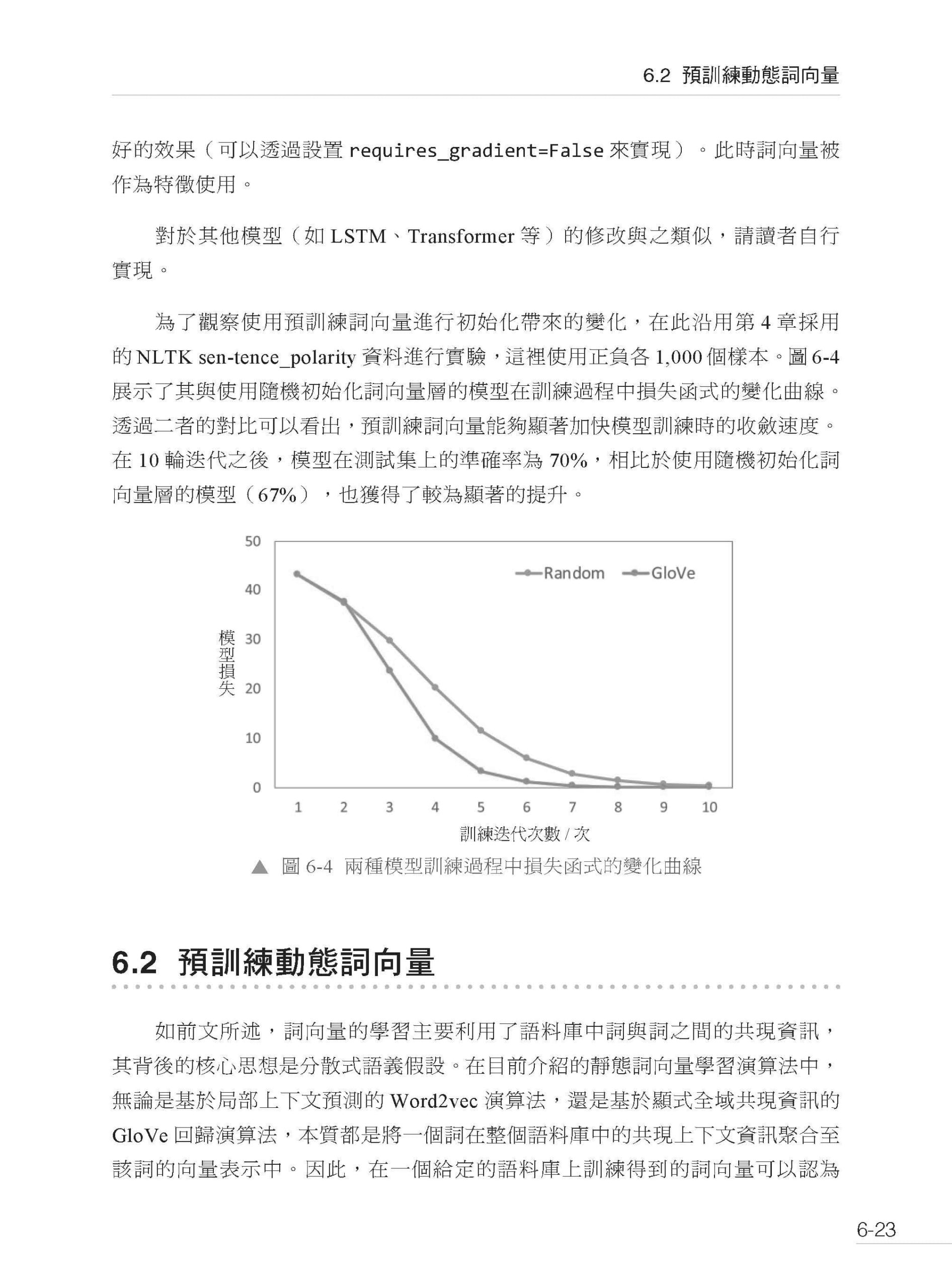
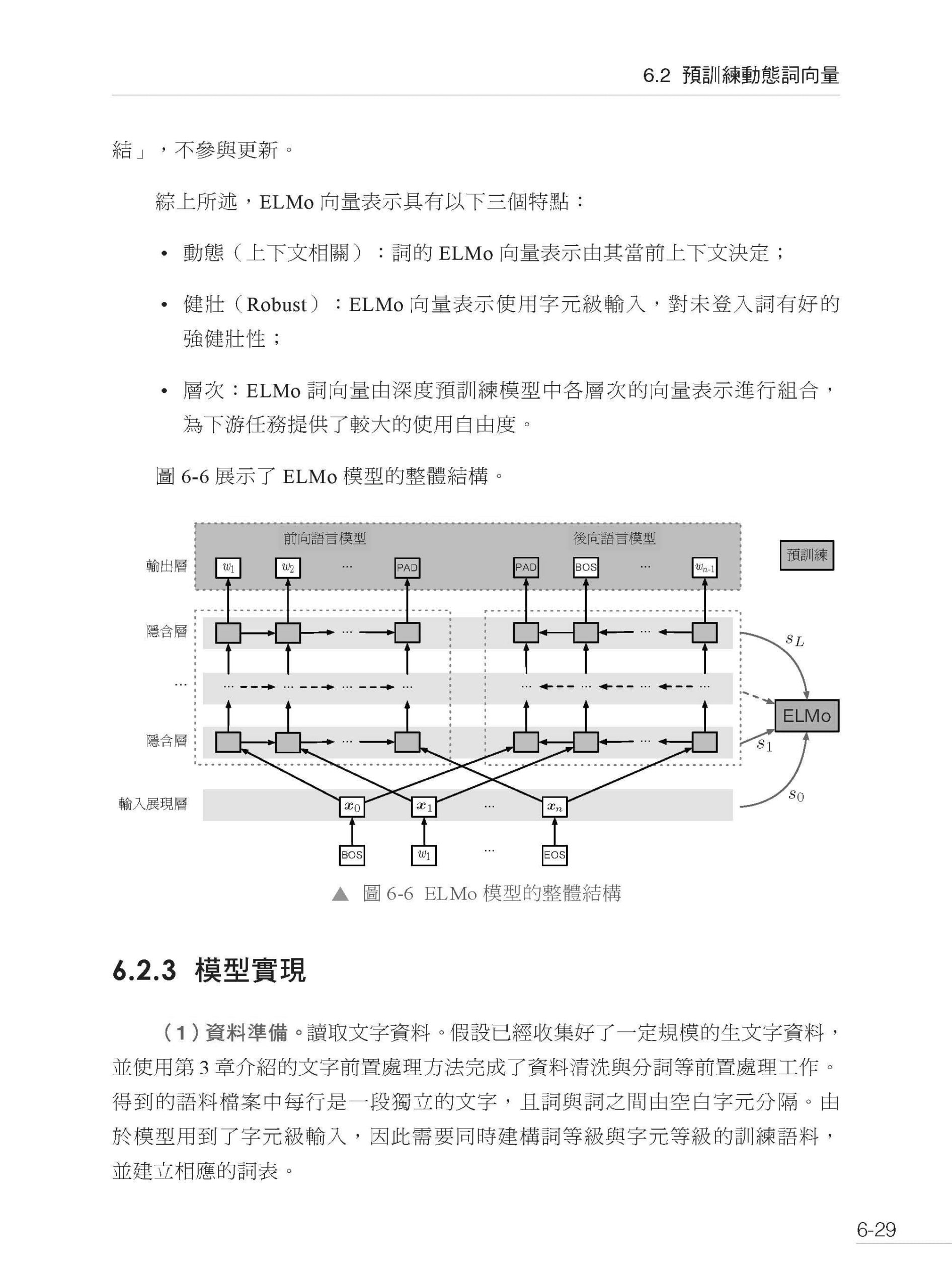
第6章 預訓練詞向量 6.1 預訓練靜態詞向量 6.1.1 基於神經網路語言模型的靜態詞向量預訓練 6.1.2 Word2vec 詞向量 6.1.3 負採樣 6.1.4 GloVe 詞向量 6.1.5 模型實現 6.1.6 評價與應用 6.2 預訓練動態詞向量 6.2.1 雙向語言模型 6.2.2 ELMo 詞向量 6.2.3 模型實現 6.2.4 評價與應用 6.3 小結
第7章 預訓練語言模型 7.1 概述 7.2 Decoder-only 模型 7.2.1 GPT 7.2.2 GPT-2 7.2.3 GPT-3 7.3 Encoder-only 模型 7.3.1 BERT 7.3.2 RoBERTa 7.3.3 ALBERT 7.3.4 ELECTRA 7.3.5 MacBERT 7.3.6 模型對比 7.4 Encoder-Decoder 模型 7.4.1 T5 7.4.2 BART 7.5 預訓練模型的任務微調:NLU 類 7.5.1 單句文字分類 7.5.2 句對文字分類 7.5.3 閱讀理解 7.5.4 序列標注 7.6 預訓練模型的任務微調:NLG 類 7.6.1 文字生成 7.6.2 機器翻譯 7.7 小結
▌第三部分 大語言模型
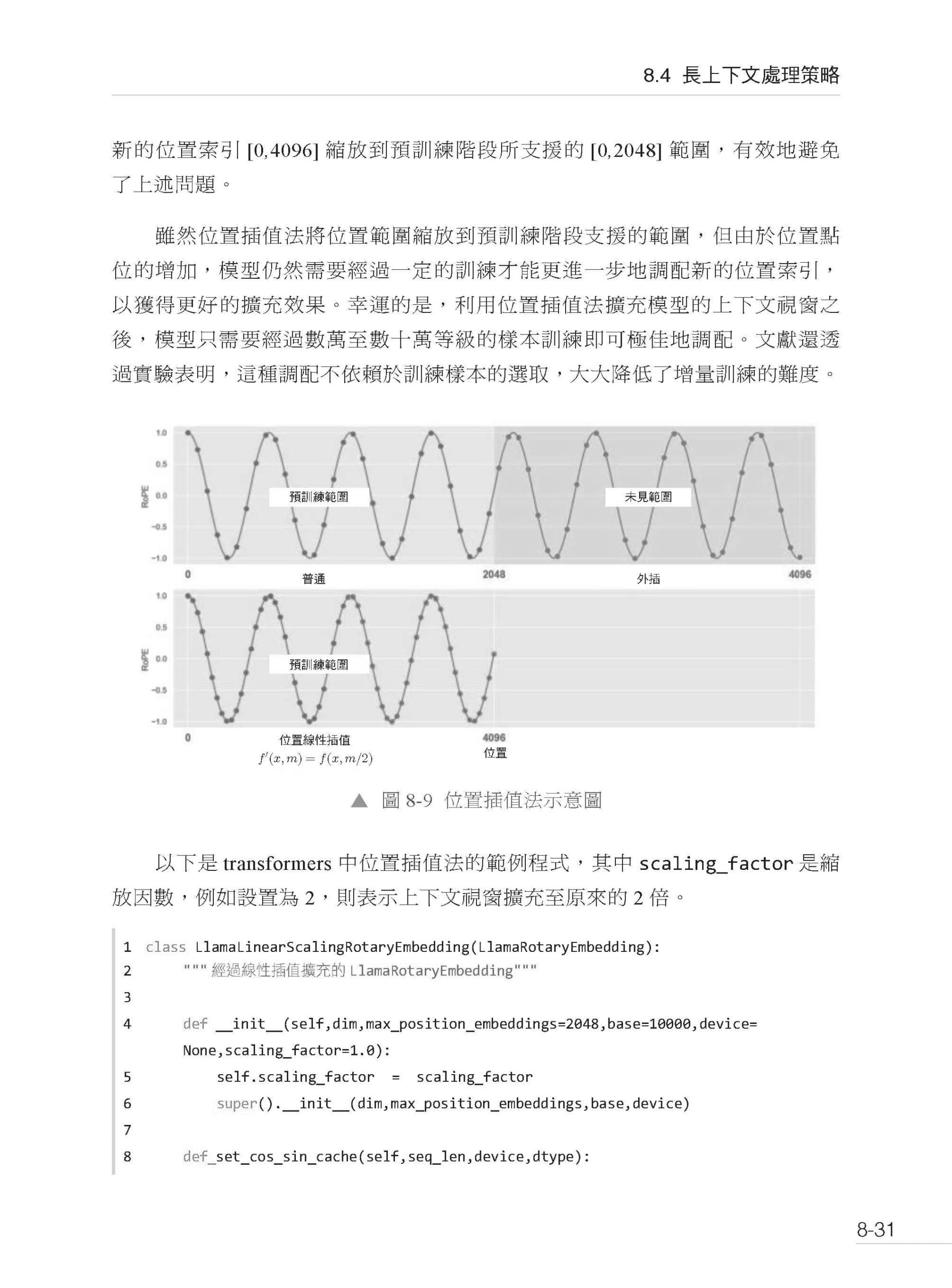
第8章 大語言模型的預訓練 8.1 大語言模型的基本結構 8.1.1 Llama 8.1.2 Mixtral 8.1.3 縮放法則 8.1.4 常見大語言模型對比 8.2 注意力機制的最佳化 8.2.1 稀疏注意力 8.2.2 多查詢注意力與分組查詢注意力 8.2.3 FlashAttention 8.3 位置編碼策略 8.3.1 RoPE 8.3.2 ALiBi 8.4 長上下文處理策略 8.4.1 位置插值法 8.4.2 基於NTK 的方法 8.4.3 LongLoRA 8.4.4 YaRN 8.5 並行訓練策略 8.5.1 資料並行 8.5.2 模型並行 8.5.3 管線並行 8.5.4 混合並行 8.5.5 零容錯最佳化 8.5.6 DeepSpeed 8.6 小結
第9章 大語言模型的調配 9.1 引言 9.2 基於提示的推斷 9.2.1 提示工程 9.2.2 檢索與工具增強 9.3 多工指令微調 9.3.1 現有資料集轉換 9.3.2 自動生成指令資料集 9.3.3 指令微調的實現 9.4 基於人類回饋的強化學習 9.4.1 基於人類回饋的強化學習演算法的原理 9.4.2 基於人類回饋的強化學習演算法的改進 9.4.3 人類偏好資料集 9.5 參數高效精調 9.5.1 LoRA 9.5.2 QLoRA 9.5.3 Adapter 9.5.4 Prefix-tuning 9.5.6 P-tuning 9.5.6 Prompt-tuning 9.6 大語言模型的中文調配 9.6.1 中文詞表擴充 9.6.2 中文增量訓練 9.7 大語言模型壓縮 9.7.1 知識蒸餾 9.7.2 模型裁剪 9.7.3 參數量化 9.8 小結
第10章 大語言模型的應用 10.1 大語言模型的應用範例 10.1.1 知識問答 10.1.2 人機對話 10.1.3 文字摘要 10.1.4 程式生成 10.2 生成指令資料 10.2.1 Self-Instruct 10.2.2 Alpaca 10.2.3 WizardLM 10.3 大語言模型的量化與部署 10.3.1 llama.cpp 10.3.2 transformers 10.3.3 vLLM 10.4 當地語系化開發與應用 10.4.1 LangChain 10.4.2 privateGPT 10.5 工具呼叫與自動化 10.5.1 AutoGPT 10.5.2 HuggingGPT 10.6 小結
第11章 大語言模型的能力評估 11.1 引言 11.2 通用領域及任務評估 11.2.1 語言理解能力 11.2.2 文字生成能力 11.2.3 知識與推理能力 11.3 特定領域及任務評估 11.3.1 數學 11.3.2 程式 11.4 模型對齊能力評估 11.4.1 有用性 11.4.2 無害性 11.4.3 安全性 11.4.4 真實性 11.5 大語言模型的評價方法 11.5.1 評價設置:調配 11.5.2 自動評價方法 11.5.3 人工評價方法 11.5.4 紅隊測試 11.6 小結
第12章 預訓練語言模型的延伸 12.1 多語言預訓練模型 12.1.1 多語言BERT 12.1.2 跨語言預訓練語言模型 12.1.3 多語言預訓練語言模型的應用 12.1.4 大規模多語言模型 12.2 程式預訓練模型 12.2.1 代表性程式預訓練模型 12.2.2 程式預訓練模型的對齊 12.2.3 程式預訓練模型的應用 12.3 多模態預訓練模型 12.3.1 遮罩影像模型 13.3.2 基於對比學習的多模態預訓練模型 12.3.3 圖到文預訓練模型 12.3.4 影像或影片生成 12.4 具身預訓練模型 13.5 小結
第13章 DeepSeek 系列模型原理簡介 13.1 DeepSeek 系列模型概述 13.2 模型架構最佳化 13.2.1 演算法最佳化 13.2.2 基礎設施最佳化 13.3 基於強化學習得推理能力 13.3.1 DeepSeek-R1-Zero:僅透過強化學習得推理能力 13.3.2 DeepSeek-R1:規範性和泛化性 13.3.3 蒸餾: 推理能力的遷移 13.4 小結
附錄A 參考文獻 術語表 |
序
|