















描述
內容簡介
| .從GCN到RDNA的架構演進,完整剖析AMD顯示卡的核心技術與分類
.釐清CPU與GPU硬體差異,拆解SIMT、SIMD、SMT與CU的並行模型 .解析硬體圖形管線,比較IMR、TBR、TBDR三種低功耗渲染策略 .深入顯示記憶體的內部結構、分類,以及ECC檢測與糾正機制 .梳理DRI1~DRI3的演進,串接X、Wayland、SurfaceFlinger的合成顯示 .講透Linux KMS送顯架構,並前瞻雲端化著色與手遊雲端運行趨勢 .對照DirectX、OpenGL、Vulkan三大圖形API,詳解Vulkan整體架構 .完整呈現Mesa、Gallium3D與RADV的使用者空間著色驅動框架 .拆解DRM子系統與AMDGPU驅動:IP模組、軔體與PM4命令佇列 .說明GPU任務排程器:job、Fence、DMA-BUF與排程執行緒的運作 .闡明GEM/TTM記憶體管理,以及GPUVM位址空間與VMID頁表機制 .涵蓋功率控制、超頻、DVFS與ROCm平行計算及大模型訓練實務
【書籍簡介】 本書共分 10 章,並附 1 個附錄。第一章說明顯示卡的硬體結構,從 AMD 的 GCN/RDNA 歷史、計算硬體(SIMT、SIMD、CU)談到硬體圖形管線、記憶體結構與顯示輸出。第二章是合成與顯示,涵蓋 DRI1~DRI3、X 與 Wayland、FrameBuffer 送顯,以及 Linux KMS 與雲端化著色趨勢。第三章是三維圖形著色管線,介紹三維座標、模型檔案,並比較 DirectX、OpenGL、Vulkan 與 Vulkan 對 AMDGPU 的功能映射。第四章是使用者空間著色驅動,深入 Mesa、Gallium3D、RADV、軟管線與 FrameGraph。第五章是 DRM 與 AMDGPU 驅動,講解 KMS/GEM/TTM、IP 模組、軔體與 PM4 命令佇列、中斷與異常。第六章是 GPU 任務排程器,剖析 job、Fence、DMA-BUF 與排程執行緒。第七章是 GEM、TTM 與 AMDGPU 物件,說明記憶體類型、BO 建立與 Evict 交換機制。第八章是 GPUVM 位址空間,闡述 VMID、頁表與 BO 狀態機。第九章是功率控制,包含結溫、功耗散熱、電壓頻率、超頻與 DVFS。第十章是顯示卡的平行計算與大模型計算,介紹 ROCm、MPI、AI 模型與跨卡跨機分散式訓練。附錄 A 則整理 AMDGPU 術語。 |
作者簡介
| 劉京洋
騰訊技術專家,任職於騰訊前沿技術中心,負責集群渲染與集群AI計算相關工作;熱愛對硬件的極致性能發揮,從事Linux內核研發工作十餘年,以第一作者發明專利三十餘個,著有《深入Linux內核架構與底層原理》(第2版)。
趙新達 從事GPU領域研發18年,熱愛對GPU軟硬件的極致探索,專注於GPU、Display、2D、3D圖形處理以及虛擬化方向研究,上至用戶態和圖形渲染管線優化,下至內核態的GPU指令分發和調度。 |
目錄
| 第1 章 顯示卡的硬體結構
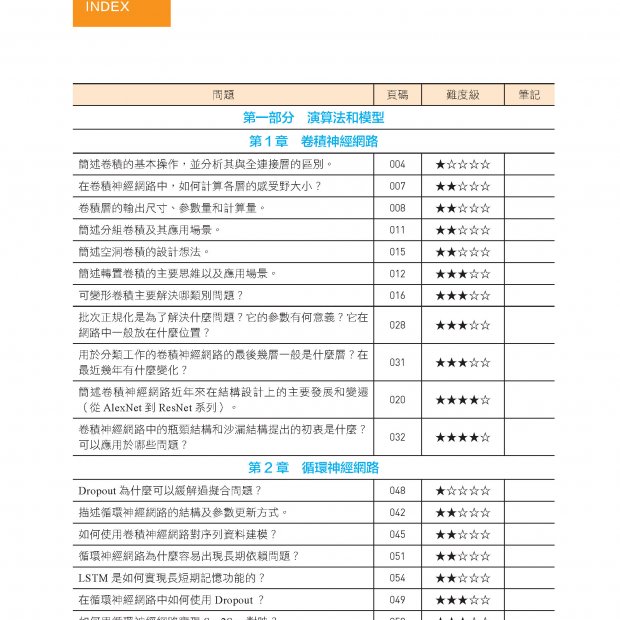
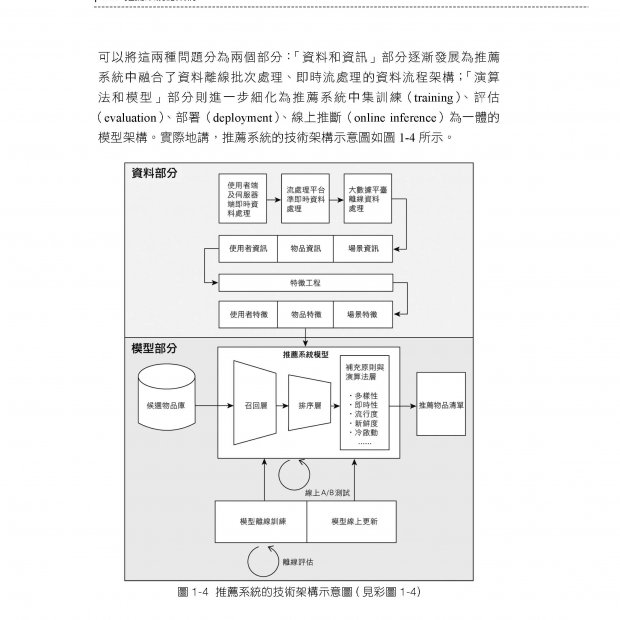
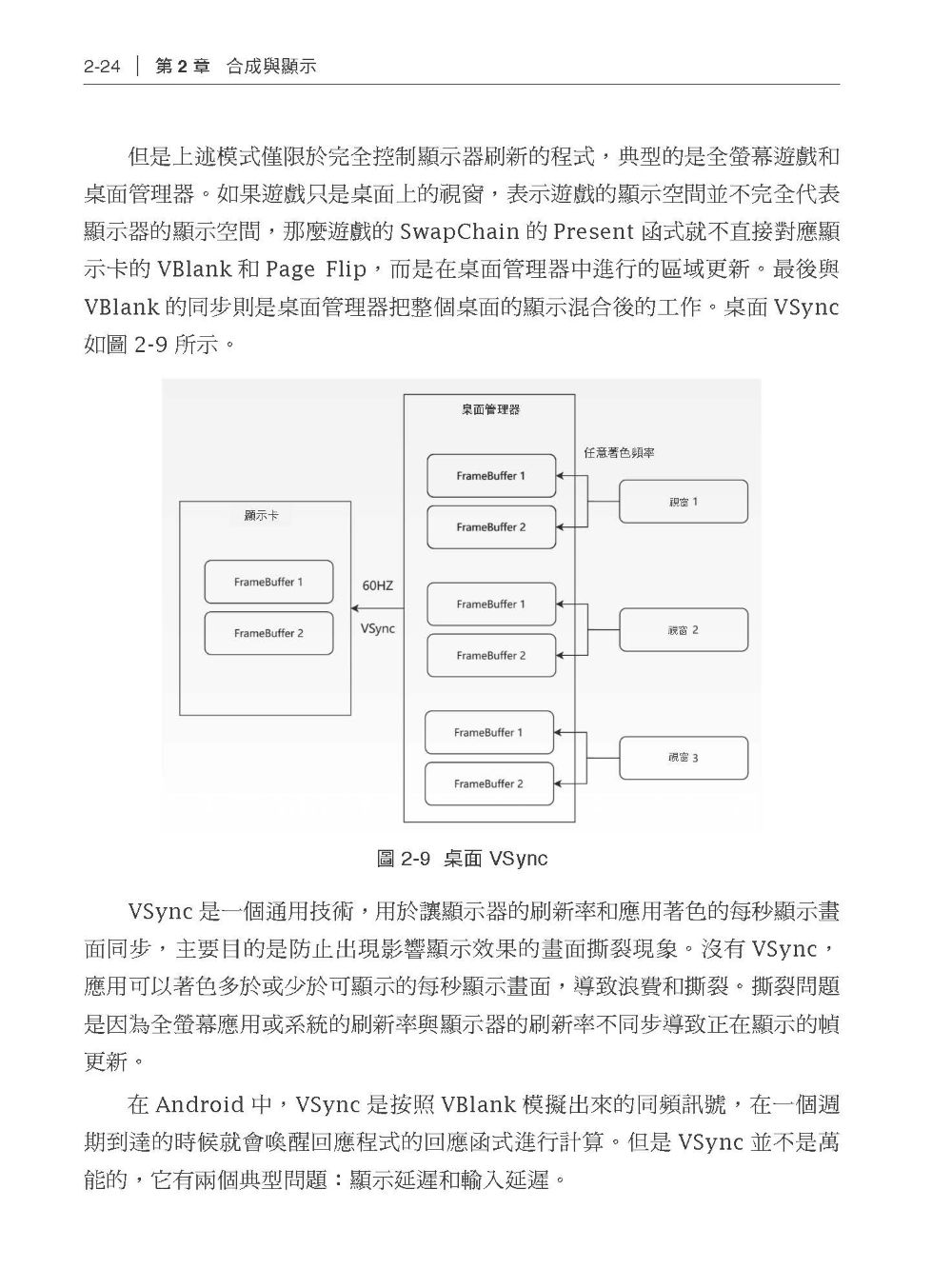
1.1 AMD 顯示卡的歷史與核心技術 1.1.1 GCN 與RDNA 1.1.2 顯示卡的分類 1.1.3 AMD 顯示卡的主要技術 1.2 顯示卡的計算硬體結構 1.2.1 CPU 與GPU 的硬體區別 1.2.2 著色器的執行硬體 1.2.3 顯示卡指令集 1.2.4 SIMT、SIMD 與SMT 1.2.5 SPU、SIMD 與CU 1.2.6 執行緒、Wave 與工作群組 1.2.7 GCN 的平行問題和RDNA 的解決辦法 1.2.8 SE 1.2.9 顯示卡平行的效能問題 1.3 顯示卡的硬體圖形管線 1.3.1 圖形管線 1.3.2 硬體管線的低功耗:IMR、TBR 與TBDR 1.3.3 顯示卡的壓縮紋理 1.3.4 硬體圖形管線的計算著色器通用化 1.4 顯示卡的記憶體硬體結構 1.4.1 獨立顯示卡與整合顯示卡的顯示記憶體區別 1.4.2 顯示卡內部的記憶體結構 1.4.3 顯示記憶體的分類 1.4.4 記憶體的檢測和糾正 1.5 顯示卡的顯示輸出 1.5.1 顯示方式 1.5.2 DCC 與EDID 第2 章 合成與顯示 2.1 DRI 2.1.1 非直接著色 2.1.2 DRI1 2.1.3 DRI2 2.1.4 DRI3 2.2 X、Wayland、SurfaceFlinger 與WindowManager 2.2.1 X 2.2.2 Wayland 2.2.3 SurfaceFlinger 與WindowManager 2.3 FrameBuffer 與送顯 2.3.1 FrameBuffer 2.3.2 Android 的FrameBuffer 管理 2.3.3 送顯與DC 2.4 合成與DPU、VPU 2.5 Linux 核心的合成與送顯:KMS 2.5.1 KMS 與送顯 2.5.2 KMS 的主要元件 2.5.3 KMS 送顯結構的建立 2.6 DRI 在未來雲端化著色的新挑戰與趨勢 2.6.1 暫存圖著色的發展 2.6.2 Android 手遊的雲端執行 第3 章 三維圖形著色管線 3.1 三維著色中的三維座標與模型檔案表示 3.1.1 座標系統 3.1.2 頂點表示與obj 模型檔案的格式 3.2 DirectX、OpenGL 與Vulkan 3.2.1 DirectX 3.2.2 OpenGL 3.2.3 Vulkan 3.3 Vulkan API 的整體架構 3.3.1 Vulkan 管理元件 3.3.2 Vulkan 管線元件 3.3.3 Vulkan 資源群元件:VkBuffer 與VkImage 3.3.4 Vulkan 同步元件 3.4 Vulkan 與AMD GPU 驅動之間的功能映射關係 3.4.1 Vulkan:著色硬體的使用者空間驅動介面 3.4.2 顯示卡與佇列 3.4.3 VkDeviceMemory 3.4.4 BO 與Vulkan 資源的使用:管線拓撲 3.4.5 job 與VkCommandBuffer 3.4.6 Vulkan 通用計算與AMD 顯示卡的硬體平行結構 第4 章 使用者空間著色驅動 4.1 OpenGL 與Vulkan 的執行時期 4.1.1 OpenGL 與EGL 4.1.2 Vulkan 4.2 libdrm與KMS 使用者空間介面 4.2.1 libdrm 4.2.2 KMS 使用者空間介面 4.3 使用者空間著色驅動:Mesa 4.3.1 使用者空間著色驅動框架:Gallium3D 4.3.3 其他著色API 實現 4.3.4 著色器 4.4 軟管線:swrast 與SwiftShader 4.4.1 Mesa 的軟管線:swrast 4.4.2 Google 的軟管線:SwiftShader 4.4.3 SwiftShader 與Lavapipe 的對比 4.5 著色API 的自動化生成:FrameGraph 4.5.1 RenderPass 與FrameGraph 的產生 4.5.2 FrameGraph 下的Vulkan 使用方式 第5 章 DRM 與AMD GPU 顯示卡驅動 5.1 DRM 子系統 5.1.1 KMS、GEM 與TTM、SCHED 5.1.2 DRM ioctl 標準介面 5.1.3 DRM 的模組參數 5.1.4 DRM 與閉源驅動的現狀 5.2 AMD 顯示卡驅動AMD GPU 5.2.1 AMD 顯示卡驅動 5.2.2 AMD GPU 的使用者空間介面 5.3 IP 模組與顯示卡韌體 5.3.1 IP 模組 5.3.2 顯示卡韌體 5.4 顯示卡命令執行佇列 5.4.1 PM4 資料封包與CP 5.4.2 PM4 的格式 5.5 中斷與異常 5.5.1 AMD 顯示卡的中斷結構 5.5.2 顯示卡的異常處理:GPU Reset 5.6 AMD GPU 使用的Linux 公共子框架 5.6.1 感測器與硬體監控框架 5.6.2 PCIe BAR 第6 章 GPU 任務排程器 6.1 job 與GPU 任務排程器 6.1.1 job 與GPU 任務排程器的概念 6.1.2 Entity 與Entity 優先順序佇列 6.1.3 GPU 任務排程器 6.2 Fence、DMA Reservation 與DMA-BUF 6.2.1 Fence 6.2.2 DMA Reservation 6.2.3 DMA-BUF 6.3 job 的下發:GPU 排程器執行緒 6.3.1 GPU 排程器執行緒的主要回呼函式 6.3.2 GPU 排程器執行緒的主體邏輯 6.3.3 DRM Sched Fence 與job 異常處理 6.3.4 AMD GPU 的Entity 擴充 6.4 job 的產生 6.4.1 GPU 排程器執行緒負載平衡 6.4.2 job 的ioctl 入口 6.5 GPU 任務排程器的內部結構 6.5.1 GPU 排程器執行緒的主要資料結構 6.5.2 AMD GPU 的排程上下文 第7 章 GEM、TTM 與AMD GPU 物件 7.1 GEM 與TTM 的整體概念 7.1.1 GEM 與TTM 7.1.2 BO 的類型與關係 7.1.3 用於CPU 著色的VGEM 7.2 顯示記憶體類型:GEM Domain 與TTM Place 7.2.1 GEM Domain 7.2.2 TTM Place 7.3 GEM BO、TTM BO 與AMD GPU BO 7.3.1 GEM BO 7.3.2 TTM BO 7.3.3 AMD GPU BO 7.4 TTM BO 的建立與記憶體分配 7.4.1 TTM BO 的建立 7.4.2 TTM 記憶體分配管理器 7.4.3 TTM 系統記憶體的非固定映射管理器:struct ttm_tt 7-28 7.5 TTM 的顯示記憶體交換機制:Evict 7.5.1 Evict 的作用 7.5.2 Evict 的流程 7.6 BO 的CPU 映射存取 7.6.1 GEM BO 的mmap 映射 7.6.2 TTM BO 的CPU 記憶體存取操作 7.6.3 Resizable BAR 第8 章 應用使用的顯示卡位址空間:GPUVM 8.1 GPU 的位址空間:GPUVM 與VMID 8.1.1 前IOMMU 時代:UMA 與GART 8.1.2 現代AMD GPU 的記憶體存取:GPUVM 8.1.3 GPUVM 的位址空間:VMID 8.1.4 PASID 與VMID 的映射 8.2 VMID 頁表與BO 狀態機 8.2.1 VMID 頁表 8.2.2 BO 狀態機 第9 章 功率控制 9.1 結溫與溫度牆 9.1.1 結溫與溫度牆的定義 9.1.2 硬體之間的協作防撞溫度牆 9.1.3 軟體與硬體協作防撞溫度牆 9.2 功耗與散熱 9.2.1 功耗的組成:靜態功耗與動態功耗 9.2.2 散熱的原理 9.3 電壓與頻率 9.3.1 供電電壓 9.3.2 執行電壓 9.3.3 頻率 9.3.4 製造製程的頻率電壓價值 9.4 顯示記憶體存取的吞吐與延遲 9.4.1 顯示記憶體的結構 9.4.2 吞吐與延遲 9.4.3 RAS 9.5 顯示卡超頻 9.5.1 超頻的原理 9.5.2 AMD GPU 超頻 9.6 動態功耗調整 9.6.1 DVFS 與DPM 9.6.2 功能開關的功耗控制技術 9.6.3 其他的顯示卡功耗控制技術 9.7 VBIOS 與Atom BIOS 9.7.1 VBIOS 9.7.2 Atom BIOS 第10 章 顯示卡的平行計算與大模型計算 10.1 顯示卡的平行結構 10.1.1 顯示卡的平行計算硬體 10.1.2 AMD 顯示卡的平行計算框架:ROCm 10.2 平行計算API 與集合通訊 10.2.1 硬體從著色卡到計算卡 10.2.2 平行計算的分類 10.2.3 MPI 10.3 AI 模型的統一架構 10.3.1 AI 模型的通用概念 10.3.2 模型的顯示記憶體佔用 10.4 大模型訓練的跨卡跨機計算 10.4.1 平行訓練模型 10.4.2 分散式訓練最佳化策略 附錄A AMD GPU 術語 軟體 硬體 其他 |
序
| 近年來,隨著AI 大模型的出現,對顯示卡的需求出現了爆炸性的增長。
在這之前,顯示卡市場的主要驅動因素是遊戲。遊戲在發展的過程中逐漸地從基於固定管線的計算向基於著色器的可程式化管線發展,並且可程式化管線的自由度越來越高,部分著色計算也逐漸向基於著色器的通用計算靠近。新的圖形API Vulkan 甚至希望使用著色器替代OpenCL 來做平行計算。 遊戲對畫質的追求上限很高,不斷驅動著色技術和顯示卡硬體的進步。伴遊戲驅動產生的顯示卡通用計算能力也開始發揮更大的作用。在計算的核心逐步從CPU 向GPU 轉移的過程中,以獨立顯示卡為核心產品線的NVIDIA 以其敏銳的洞察力獲得了最大的先發優勢,其發展之迅猛從10 年300 多倍的股價漲幅上可見一斑。 遊戲畫質和通用計算在推動GPU 性能不斷發展的同時,以Intel 和AMD為主導的CPU 性能的發展速度顯得較為緩慢,反而是ARM 這種行動端晶片在終端市場攻城掠地,甚至有進軍PC 和伺服器市場的趨勢。低功耗與高性能這兩個本來互相矛盾的需求在現代第一次被同時強烈需求,算效比越來越得到重視。 AMD 在CPU 市場曾經長期是Intel 的追隨者,在顯示卡市場也長期是NVIDIA 的追隨者。但是AMD 卻有集CPU、GPU、FPGA 於一身的綜合能力,並且各方面都沒有明顯缺陷。因此,AMD 率先將現代大規模晶片所需的Chiplet 技術充分應用,使得CPU、GPU、FPGA 可以形成一個有機整體。AMD 在CPU 和GPU 的C/P 值上長期都高於Intel 和NVIDIA,並且其結合CPU 和GPU 的APU 形態成為兼顧邏輯與計算能力的典範。 更重要的是,AMD 一直保持活力。在伺服器CPU 上,EPYC 從Intel 手中奪取了越來越多的市佔率。在與三星的合作中,AMD 成為唯一將現代獨立顯示卡的GPU 核心技術整合到手機晶片中,並獲得一定成功的公司,這也代表了AMD 在兼顧顯示卡性能與低功耗能力上逐漸成熟。在當前的AI 計算浪潮中,AMD 同樣反應迅速。Instinct 系列的通用計算GPU 再一次以高C/P值的定位出現,並且逐漸成為AMD 的核心利潤引擎。 在這個過程中,AMD 引領了獨立顯示卡驅動的開放原始碼浪潮。將高性能的獨立顯示卡驅動開放給廣大社區,不但為AMD 節省了大量的研發經費,而且使得AMD 顯示卡的使用者有更多的針對自己業務的最佳化空間和問題的快速修復能力。開放原始碼的力量第一次在獨立顯示卡領域展現,為AMD 顯示卡帶來了勃勃生機。同時,AMD 顯示卡的開放原始碼給一向欠缺獨立顯示卡驅動支持的Linux 核心注入了極大的活力。 本書中,第1 章主要介紹了顯示卡的硬體結構。顯示卡發展至今,硬體結構逐漸趨於統一。AMD 與NVIDIA 雖然對不同硬體模組的稱呼方式不同,但是硬體模組的功能和組織都是大同小異的。本章首先介紹了AMD 顯示卡硬體技術的發展歷史,然後分別從計算、圖形、顯示記憶體、顯示四個方面對顯示卡硬體進行了原理性介紹。 第2 章主要介紹了合成與顯示,因為任何計算系統都需要一個將計算結果呈現給使用者的方式,這個呈現方式也是使用者對整個計算系統最直觀的認識。對於著色,顯示卡的呈現方式就是桌面系統的顯示框架。本章首先介紹了Linux 桌面顯示的DRI 的發展過程和工作原理,然後介紹了主要的DRI 的實現:X、Wayland、SurfaceFlinger。這些不同的實現也代表了Linux DRI的發展過程和Android 對顯示框架新的設計思考。對於任何顯示框架,都需要基礎的FrameBuffer 管理與送顯的下層支持。因此本章逐步展開介紹了FrameBuffer 與送顯、合成與相關硬體、Linux 的顯示框架KMS 對上下層的銜接,以及暫存圖著色的未來可能發展趨勢。 第3 章介紹了常見的圖形著色管線的關係、原理與發展, 主要包括DirectX、OpenGL 與Vulkan, 重點介紹了新一代的顯示驅動API:Vulkan,並且說明了Vulkan 使用者空間驅動與AMD 顯示卡驅動之間的功能關係。 第4 章介紹了使用者空間驅動的具體實現,主要使用Linux 下較為通用的Mesa 驅動,基於Mesa 介紹了OpenGL、Vulkan 驅動的實現方式和軟管的工作原理。 第5 章系統性地介紹了AMD 顯示卡核心空間驅動的整體結構,主要包括顯示卡的硬體IP 劃分和功能、顯示卡韌體的管理、顯示卡命令執行佇列的管理、顯示卡的中斷與異常處理,以及顯示卡驅動與Linux 核心通用框架之間的關係。 第6 章介紹的是控制使用者空間的著色和計算指令如何下發到顯示卡硬體上的功能部分,該部分為顯示卡運行負載的排程,是直接服務於顯示卡執行功能的部分,因此性能比較敏感。本章主要介紹了顯示卡任務的抽象物件:job的產生與排程方式,以及核心的Fence 與顯示卡硬體Fence 之間的工作關係。 第7 章和第8 章進入顯示記憶體管理的介紹。使用者空間使用著色API產生的所有需要佔據顯示記憶體資源的物件都需要透過顯示卡的核心空間驅動來分配和管理顯示記憶體。由於顯示卡可以同時存取顯示記憶體和系統記憶體,並且有獨立的顯示卡位址空間,因此顯示卡的顯示記憶體格外複雜。Linux 核心為顯示記憶體物件抽象了用於物件管理的GEM 和用於顯示記憶體管理的TTM 兩種有繼承關係的物件。AMD 顯示卡驅動中也進一步繼承抽象了AMD GPU。 第7 章主要介紹了不同物件的概念和記憶體分配方式,以及物件的CPU 映射存取。而第8 章則主要介紹了顯示卡的位址空間GPUVM 的工作原理。第9 章主要介紹了顯示卡的功率控制。由於硬體的功率控制原理與做法對於不同廠商甚至不同的硬體種類都有類似的方式,因此本章的內容具有普適性,如可以用於理解CPU 的功率控制原理。由於顯示卡的功耗和散熱能力有上限,因此功耗和溫度很容易成為阻礙顯示卡性能實際發揮的因素。本章分析了顯示卡的溫度牆與功耗牆的原理,電壓、頻率與功耗的關係和顯示卡動態調頻原理,顯示記憶體存取的延遲與吞吐,以及顯示卡的超頻原理。本章最後介紹了顯示卡功耗設定的VBIOS。本章是希望發揮顯示卡極限性能的讀者必讀的原理基礎。第10 章介紹了顯示卡的新用途:AI 計算。首先介紹了顯示卡進行AI 計算的平行計算硬體基礎,然後介紹了AI 計算中必要的平行計算API 與集合通訊的原理和顯示卡的支援方式,最後介紹了現代大規模AI 計算在大規模叢集上的跨卡跨機計算方式與性能最佳化。 我的工作內容主要是在Linux 核心的各個子系統進行性能最佳化,也包括GPU 子系統。在圖形專家趙新達的幫助下,我對Linux 核心的顯示卡驅動做了很多最佳化,降低了著色成本。得益於AMD 的開放原始碼驅動,主要的最佳化結果都是在AMD 平臺上獲得的。 非常感謝AMD 的開放原始碼驅動,無論是使用者空間的著色驅動還是核心空間的顯示卡驅動。在不進行最佳化的情況下,AMD 的硬體都能獲得較高的C/P 值。在深入最佳化後,可以進一步獲得更大的成本優勢,並且可以利用開放原始碼驅動提供的知識開發很多監測和修復工具。最讓我印象深刻的是Steam 公司開發的AMD 著色器編譯器——ACO,其表現出了卓越的性能。 AMD 將舞臺讓給了社區,也讓企業可以充分地降低叢集計算成本。這也是我和趙新達決定寫這本書的原因。我們希望可以透過AMD 的開放原始碼驅動,展示整個Linux 的著色結構,也希望越來越多的人參與到顯示卡驅動技術的討論中。由於顯示卡驅動之前長期處於封閉狀態,因此網際網路上缺少相關資料,本書中的很多專業術語也只出現在驅動程式中。希望讀者可以以本書為引,親自閱讀具體程式。 最後,我個人使用的遊戲電腦的AMD 7900XTX 顯示卡驅動來自我自己的編譯和設定。AMD 顯示卡驅動提供了很多設定能力,可以讓硬體經過調整獲得更高的C/P 值。本書中有很多原理介紹可以輔助最佳化,希望讀者開卷有益。 劉京洋 |