








描述
內容簡介
| 【內容特點】
✯快速上手:專為 Python 開發者打造,用熟悉思維無縫接軌 Rust ✩解鎖高效能:掌握所有權與生命週期,根除記憶體錯誤並突破 GIL ✯PyO3 實戰:從零開始教你撰寫 Rust 擴充套件,解決 Python 運算瓶頸 ✩AI 落地應用:駕馭 Candle 與 Burn 框架,實現輕量化推論與模型移植 ✯工程化思維:涵蓋模組化設計、自動化測試到效能分析的完整實踐
【本書獻給不願在效能與開發效率間妥協的你】 ✯資料科學家:受夠了 Pandas 在大數據下的龜速,想尋找更高效的運算替 代方案。 ✩資料工程師:需要建構高吞吐量、低延遲且穩健可靠的 ETL 管線,徹底告 別執行期錯誤,讓資料流動不再阻塞。 ✯ MLOps 工程師:致力於模型生產環境部署,追求在有限算力下達到極致的 推論速度。 ✩進階 Python 開發者:不滿足於語法糖,想深入理解底層運作與並行程式設 計,大幅擴張技術守備範圍。 |
作者簡介
| 顏志穎
現任外商科技公司資料工程師,專精於大規模資料處理與 MLOps 架構設計。 曾獲 iThome 鐵人賽 AI & Data 組佳作,熱衷於透過文字梳理技術脈絡。 長期沉浸於 Python 生態系,近年積極探索 Rust 在資料工程領域的實務應用,並樂於將這些「雙刀流」的實戰經驗轉化為文字,與社群共同成長。 工作之餘,是個相信吸貓能提升程式碼品質的快樂鏟屎官。 |
目錄
| ▌Part I Rust 的攀登之路
►第1 章 建立新思維:Rust 的基本功與工具鏈 1.1 踏入Rust 世界:為何它值得Pythonista 注目? 1.2 安裝Rust 與設定開發環境 1.2.1 安裝rustup 1.2.2 驗證安裝 1.2.3 更新Rust 1.2.4 開發環境建議 1.3 Pythonista 的第一行Rust:Hello, Performance! 1.3.1 建立專案資料夾與檔案 1.3.2 編譯與執行 1.4 核心工具Cargo 1.4.1 使用Cargo 建立新專案 1.4.2 建構與執行 Cargo 專案 1.4.3 Cargo 的常用指令 1.5 告別動態型別:認識變數與原始型別 1.5.1 資料的綁定:變數、常數與可變性 1.5.2 萬物的基礎:原始型別 (Primitive Types) 1.5.3 數值的計算:基礎運算 1.6 組織程式碼:函式 (Functions) 與表達式 1.6.1 函式簽章 (Function Signature) 1.6.2 函式本體:陳述式 vs. 表達式 1.6.3 萬物皆表達式 (Almost) 1.7 揭秘 !:函式的近親,巨集 (Macros) 1.7.1 為什麼Rust 需要巨集? 1.7.2 常用的內建巨集 1.7.3 println! 的格式化功能 1.8 做出決策:if、else 與 match 1.8.1 if、else if 與 else 1.8.2 更強大的分支:match 1.9 重複的藝術:loop、while 與 for 1.9.1 loop:無限迴圈 1.9.2 while:條件迴圈 1.9.3 for:走訪集合 巢狀迴圈與標籤 (Loop Labels) 1.10超越原始型別:三大常用集合 (Collections) 1.10.1 向量 (Vector) 1.10.2 字串 (String) 1.10.3 雜湊映射 (HashMap) 1.11專業風範:程式碼風格與文件化 1.11.1 註解 1.11.2 文件註解 1.11.3 模組與 Crate 文件 1.11.4 命名規範 (Naming Conventions) 1.12第一章的登山口:整備行囊與心態
►第2 章 Rust 風格的物件導向:Struct、Enum 與 Trait 2.1 結構體 (Struct):定義資料的藍圖 2.1.1 經典結構體:我們的第一個自訂型別 2.1.2 建立實例的便利語法 2.1.3 結構體的其他形式 2.2 Impl ( 實作區塊):為資料賦予行為 2.2.1 方法 (Methods):&self 的初登場 2.2.2 關聯函式 (Associated Functions):Rust 的「 建構子」 2.3 列舉 (Enum):定義「多選一」的狀態 2.3.1 從簡單列舉開始 2.3.2 攜帶資料的變體:Enum 的真正力量 2.3.3 match 窮舉:絕不遺漏任何情況 2.4 Option<T>:Rust 的空值處理方案 2.4.1 None 的問題,Option 的解法 2.4.2 if let:match 的語法糖 2.5 Trait ( 特徵):定義共通的「能力」 2.5.1 什麼是 Trait ? 2.5.2 實作 Trait:賦予型別新能力 2.5.3 使用 Trait 實現多型:泛型 (Generics) 2.5.4 #[derive]:讓編譯器為我們工作 2.5.5 常見的標準庫 Trait:From 與 Into 2.6 第二章的路線圖:辨識地形與規劃路徑
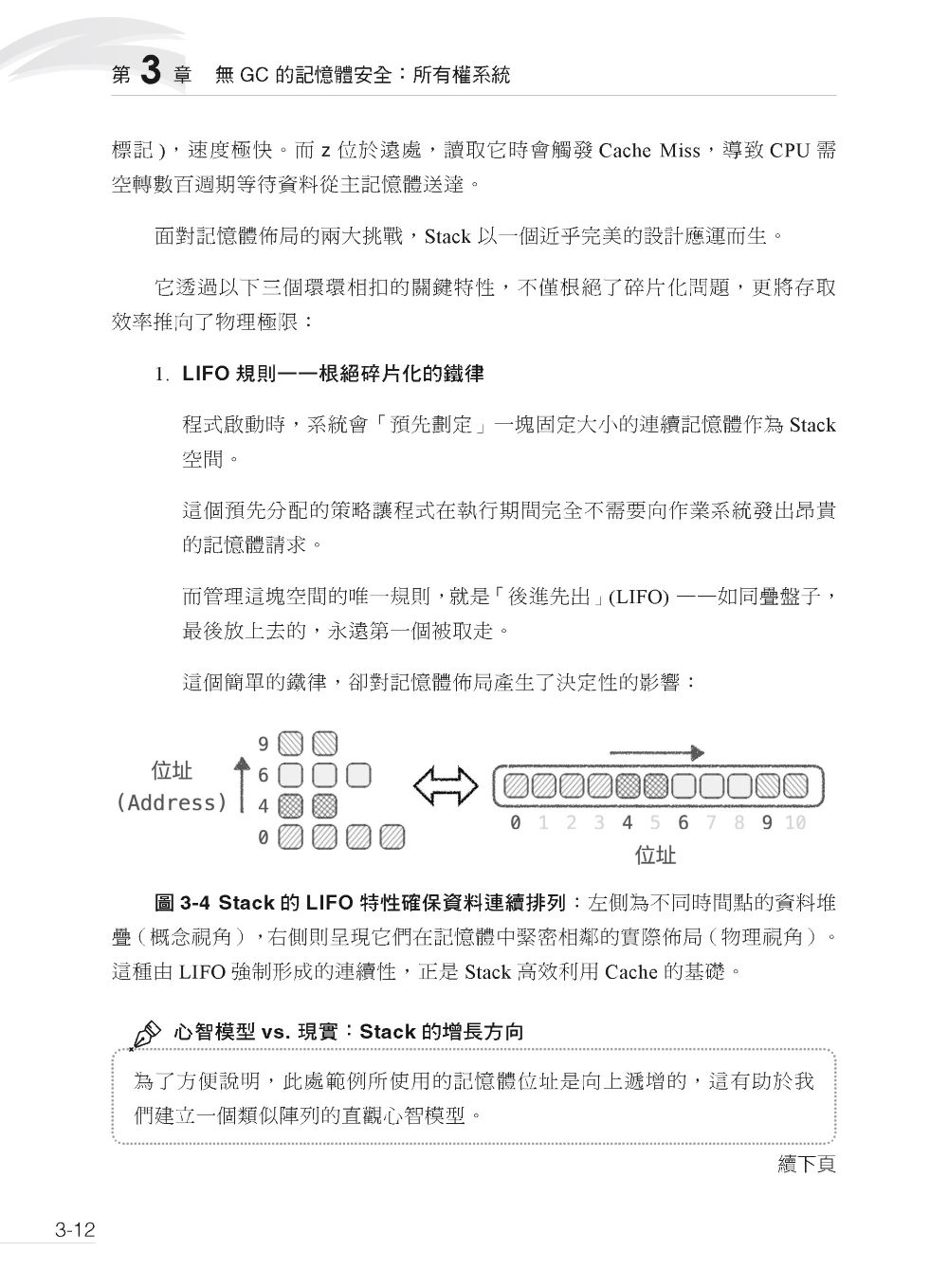
►第3 章 無 GC 的記憶體安全:所有權系統 3.1 記憶體小學堂 3.1.1 基礎概念:記憶體的組織方式 3.1.2 中階概念:記憶體的座標系統 3.1.3 進階概念:記憶體的雙核心管理方式 3.1.4 Stack 的誕生:解決記憶體管理的兩大挑戰 3.1.5 Heap 的崛起:突破作用域與編譯期的大小限制 3.1.6 所有權問題的浮現 3.2 所有權:Rust 記憶體管理的核心原則 3.2.1 所有權的轉移:移動 (Move) vs. 複製 (Copy) 3.2.2 所有權的訪問:借用 (&) 與參考 (Reference) 3.2.3 解參考 (*):讀取參考背後的值 3.3 駕馭所有權:常見模式與實戰場景 3.3.1 函式與資料的互動模式 3.3.2 結構體與方法的設計模式 3.3.3 錯誤診斷室:學會與編譯器對話 3.3.4 所有權問題的思維框架 3.4 所有權試煉 試煉 3-1:報告的歸檔 試煉 3-2:狀態訊息的顯示 試煉 3-3:使用者的暱稱 3.5 第三章的陡峭岩壁:攀越所有權的考驗
►第4 章 優雅的資料處理:閉包與迭代器 4.1 什麼是閉包 (Closures) ?— 捕捉環境的匿名函式 4.1.1 閉包的語法:從函式到閉包 4.1.2 捕捉環境:閉包的核心威力 4.2 閉包如何捕捉環境:所有權的三種模式 4.2.1 自動推論:不可變借用、可變借用與取得所有權 4.2.2 move 關鍵字:強迫閉包取得所有權 4.3 什麼是迭代器 (Iterator) ?處理序列的「惰性」方法 4.3.1 迭代器的「惰性」 4.3.2 迭代器的三種模式:.iter(), .iter_mut(), .into_iter() 4.4 Iterator Trait:迭代器的「契約」 4.4.1 核心方法:.next() 4.4.2 消耗配接器 (Consuming Adaptors) 4.4.3 迭代配接器 (Iterator Adaptors) 4.5 組合應用:Option 也能用函數式風格 4.5.1 心智模型:將 Option 視為「長度 0 或 1」的集合 4.5.2 常用組合器 (Combinators) 4.6 第四章的高速索道:串起流暢的資料管線
►第5 章 穩健的程式碼:Result 與 Panic 5.1 兩類錯誤:不可復原 vs. 可復原 5.1.1 不可復原的錯誤:panic! 5.1.2 可復原的錯誤:Result<T, E> 5.2 panic!:當一切都已無可挽回 5.2.1 拆解 (Unwind) vs. 中止 (Abort) 5.2.2 追蹤 panic! 的根源:Backtrace 5.3 Result:明確處理「可能」的失敗 5.3.1 Result 的本質:一個列舉 5.3.2 處理 Result 的基本功:match 5.4 告別巢狀match:Result 的組合器 5.4.1 使用 .unwrap_or_else 簡化 match 5.4.2 快速原型開發:.unwrap() 與 .expect() 5.5 錯誤傳播 (Propagating):? 運算子 5.5.1 傳統的錯誤傳播 ( 手動 match 與 return) 5.5.2 現代的錯誤傳播:? 的魔力 5.5.3 讓 main 函式回傳 Result 5.6 建立自己的錯誤型別 5.6.1 建構子 (Constructor) 最佳實踐 5.6.2 使用 enum 窮舉錯誤 5.6.3 讓 enum 成為「真正」的錯誤 5.6.4 終極捷徑:thiserror & anyhow Crate 5.7 第五章的風險管理:應對濃霧與突發坍方
►第6 章 擴展程式規模:模組化與測試 6.1 程式碼的「三層架構」:Packages, Crates, 與 Modules 6.1.1 Package ( 套件):Cargo 的專案單位 6.1.2 Crate:編譯的最小單位 6.1.3 Module ( 模組):Crate 內部的組織單位 6.2 定義模組:mod 關鍵字與檔案系統 6.2.1 內嵌模組:最直接的封裝 6.2.2 拆分到檔案 (External File Modules) 6.3 控制可見性:pub 關鍵字與私有性 6.3.1 預設私有 6.3.2 pub 關鍵字:打開對外的那扇窗 6.3.3 pub struct vs. pub enum:一個微妙的陷阱 6.3.4 pub(crate):內部的「公開」 6.4 將項目引入作用域:use 關鍵字 6.4.1 建立捷徑 6.4.2 絕對路徑 vs. 相對路徑 6.4.3 路徑管理:as 與 pub use 6.5 撰寫與組織測試 6.5.1 測試的組織:內部實作 vs. 公開 API 6.5.2 撰寫基本測試:#[test] 與驗證 6.5.3 測試特殊情況:panic 與 Result 6.6 執行測試:cargo test 的選項 6.6.1 執行特定測試 6.6.2 控制測試執行 6.6.3 忽略測試:#[ignore] 6.6.4 cargo-nextest:更強大的測試執行器 6.7 第六章的前進營地:建立營區與設立檢查點
►第7 章 參考的有效期限:生命週期 7.1 為何需要生命週期?一切的起點:迷途參考 7.1.1 一個無法編譯的程式:迷途參考的誕生 7.1.2 拆解問題:作用域 (Scope) vs. 生命週期 (Lifetime) 7.2 泛型生命週期:當編譯器需要我們幫忙 7.2.1 函式簽章:連結輸入與輸出的生命週期 7.2.2 在資料結構中保存參考 7.2.3 impl 區塊:為帶有生命週期的型別實作方法 7.3 喘口氣:生命週期省略規則(Lifetime Elision Rules) 7.4 特殊生命週期:'static 7.5 集大成:泛型、Trait 與生命週期 7.6 第七章的補給線:精算參考的安全期限
►第8 章 無懼的並行:執行緒、共享與同步 8.1 建立執行緒:thread::spawn 8.1.1 thread::spawn 與 JoinHandle 8.1.2 move 關鍵字:執行緒的所有權 8.2 執行緒通訊 (1):訊息傳遞 (Message Passing) 8.2.1 mpsc 通道 8.2.2 crossbeam-channel 與 MPMC 通道 8.3 智慧指標:為共享狀態做準備 8.3.1 Box<T>:單一所有權的 Heap 指標 8.3.2 Rc<T>:單一執行緒的多重所有權 8.3.3 內部可變性:Cell<T> 與 Copy 型別 8.3.4 內部可變性:RefCell<T> 與執行時借用 8.3.5 經典組合:Rc<RefCell<T>> 8.3.6 Arc<T>:執行緒安全的多重所有權 8.4 執行緒通訊 (2):共享狀態 Mutex<T> 8.4.1 Mutex<T> ( 互斥鎖) 8.4.2 經典組合:Arc<Mutex<T>> 8.5 Rust 的終極保證:Send 與 Sync 8.5.1 Send Trait:允許「所有權」跨執行緒轉移 8.5.2 Sync Trait:允許「參考」跨執行緒共享 8.6 第八章的同步攻頂:從單人攀登到團隊協作
▌Part II 實戰應用!從 Python 擴充到 AI框架的完整旅程
►第9 章 PyO3:打造高效能的 Python 擴充套件 9.1 動機剖析:Python 為何需要 Rust 的力量? 9.1.1 優異的編譯器與開發工具 9.1.2 透過程序式巨集,弭平語言隔閡 9.1.3 為沒有 GIL 的未來做好準備 9.2 環境設置:打造現代化的 PyO3 開發流程 9.2.1 準備兩端的語言環境 9.2.2 安裝建置工具 maturin 9.2.3 建立 PyO3 專案 9.2.4 第一次接觸:手動編譯與測試 9.2.5 建立自動化測試流程 9.2.6 深入探索:專案結構與核心設定檔 9.3 思維轉換:從 Python 物件到 Rust 型別 9.4 定義 Python 的入口:打造可 import 的模組 9.4.1 基礎作法:以函式作為模組入口 9.4.2 組織巢狀結構:子模組 (Submodule) 9.4.3 更簡潔的選擇:用 mod 區塊宣告模組 9.5 打造工具:將 Rust 函式化為 Python 函式 9.5.1 微調 Python 介面:#[pyo3] 屬性 9.5.2 打造靈活的參數介面 9.5.3 從Python 到 Rust:FromPyObject 特徵 9.5.4 全域直譯器鎖 (GIL) 與安全的物件操作 9.5.5 從 Rust 到 Python:IntoPyObject 特徵 9.5.6 PyO3 的智慧指標體系:Py<T>、Bound<T> 與 Borrowed<T> 9.5.7 錯誤處理:當 Result 遇上 Exception 9.5.8 核心觀念回顧 9.6 塑造物件:將 Rust 自訂型別化為 Python 類別 9.6.1 第一步:用 #[pyclass] 勾勒藍圖輪廓 9.6.2 千變萬化的 Enum:從狀態標籤到複合容器 9.6.3 安全通關:進入 Python 世界的三個前提 9.6.4 第二步:用 #[pymethods] 加裝操作功能 9.6.5 物件的誕生:定義建構子 9.6.6 開放內部資料:欄位的存取與修改 9.6.7 工具箱與工廠:無需實例也能呼叫的方法 9.6.8 跨越語言的繼承:讓 Rust 結構體也能開枝散葉 9.6.9 行為的覆寫:在子類別中與父類別互動 9.6.10 #[pyclass] 旅程小結 9.7 跨越 GIL 的限制:Rust 的並行處理與 Free-threaded Python 9.7.1 並行處理的兩種途徑:處理程序與執行緒 9.7.2 Python 的現狀:在 GIL 下的權衡取捨 9.7.3 打造 Rust 並行引擎:釋放多核心的潛能 9.7.4 釋放 GIL 的安全前提 9.7.5 精準的 GIL 管理:最小化鎖定時間 9.7.6 在 Rust 執行緒間共享 Python 物件 9.7.7 擁抱 Free-threaded Python 的未來 9.8 從 GIL 到無懼並行:為何 Python 更需要 Rust ?
►第10 章 Hugging Face Candle:點亮輕量化推論的極速火花 10.1 返璞歸真:從 Tensor 開始的 MNIST 訓練生活 10.1.1 打好地基:專案初始化與模組規劃 10.1.2 從雲端到記憶體:建構 MnistDataset 10.1.3 手刻線性層:理解 Candle 的參數管理哲學 10.1.4 建立漸進式重構工作台 10.1.5 使用 candle_nn::loss::cross_entropy 重構:從手動計算到最佳踐 10.1.6 使用 candle_nn::{Linear, Module} 重構:從手刻結構到慣用模式 10.1.7 使用 candle_nn::optim 重構:從手動更新到自動化迭代 10.1.8 整合與升級:使用 Batcher 打造現代化訓練迴圈 10.1.9 實戰演練:打造 LeNet-5 卷積神經網路 10.1.10 啟用硬體加速:釋放 GPU 的力量 10.1.11 打造流暢的資料管線:apply 鏈式呼叫 10.1.12 模型的保存與載入:延續訓練成果 10.1.13 打完收工:從手刻到框架的修煉之路 10.2 站在巨人的肩膀上:移植 PyTorch 模型 10.2.1 攤開巨人的藍圖:從 DistilBERT 開始 10.2.2 搭建施工鷹架:專案結構與模組規劃 10.2.3 萬丈高樓平地起:實作基礎元件庫 nn.rs 10.2.4 按圖施工:對應 transformers 原始碼 10.2.5 訂定施工規格:實作模型設定檔 config.rs 10.2.6 破土動工:實作輸入嵌入層 embeddings.rs 10.2.7 賦予專注力:實作多頭自注意力機制 attention.rs 10.2.8 打造標準樓層:實作單層 Transformer layer.rs 10.2.9 堆疊樓層成塔:實作 Transformer 編碼器 encoder.rs 10.2.10 從思緒到語言:實作 MLM 預測頭部 head.rs 10.2.11 竣工收尾:組裝完整 DistilBERT 模型 distilbert.rs 10.2.12 驗收成果:在 main.rs 中執行推論 10.3 燭光遍照:從單點模型到完整生態系
►第11 章 Burn:燃起 AI 研究與工程的熊熊烈焰 11.1 研製第一艘火箭:用 MNIST 演練從設計到升空的完整流程 11.1.1 發射台整備:專案初始化與架構藍圖 11.1.2 認識箭體材質:Burn 張量的特性與操作 11.1.3 打造燃料輸送帶:定義 Dataset 與 Dataloader 11.1.4 組裝箭體與酬載:定義 Burn 的模型結構 (Module 與 Config) 11.1.5 倒數計時與點火:實作訓練迴圈與 Learner 11.1.6 第二節推進:理解 Backend 並切換至 GPU 加速 11.1.7 封存航行日誌:模型的儲存 11.1.8 來自天際的應答:載入模型並驗證推論成果 11.1.9 章節總結:第一艘火箭的誕生 11.2 停靠太空站:匯入跨框架模型 (ONNX & Safetensors) 11.2.1 選擇你的對接口:架構生成 vs. 權重裝填 11.2.2 航線 A:ONNX - 自動化模型生成 11.2.3 航線 B:Safetensors - 手動對接與權重裝填 11.2.4 排除對接故障:處理框架不匹配問題 11.2.5 總結:擴展你的 Burn 艦隊 11.3 從火花到烈焰:Burn 與 Candle 的設計哲學,航向 AI 的無垠宇宙
►第12 章 效能分析工具箱:讓 Rust 跑得更快 12.1 效能的度量衡:使用 cargo bench 建立基準 12.1.1 建立我們的第一個 Benchmark 12.2 找出效能熱點:兩大視覺化利器 12.2.1 火焰圖 (Flamegraph) 的基本概念 12.2.2 如何閱讀火焰圖? 12.2.3 利器一號:經典 cargo-flamegraph 12.2.4 效能分析的陷阱:採樣到的是誰? 12.2.5 利器二號:現代 samply 12.2.6 解讀 samply 的多重視圖 12.3 記憶體:隱形的效能殺手 12.3.1 記憶體配置的成本 (Allocation Cost) 12.3.2 跨平台的 Rust Heap 分析器:Dhat 12.3.3 Dhat 之外:平台原生分析工具 12.3.4 超越演算法:CPU 快取的影響 12.4 效能思維:從量測到效能調校的完整循環
►附錄A :打造高效 Rust 開發環境(VS Code 篇) A.1 必備工具鏈 rust-analyzer CodeLLDB A.2 輔助工具 Even Better TOML ErrorLens Dependi ( 前身為 Crates) A.3 風格主題 Catppuccin
►附錄B :找回熟悉的開發節奏:設定Rust REPL 與Jupyter B.1 終端機 REPL B.1.1 evcxr_repl B.1.2 IRust B.2 Jupyter 整合 B.2.1 安裝 evcxr Jupyter Kernel B.2.2 在 Jupyter 中使用 Rust B.2.3 IRust Kernel B.3 超越 REPL:Rustacean 的工作流
|
序
| 前言
歡迎來到《從 Pythonista 到 Rustacean:資料從業者的第一本 Rust 指南》!
我是一個在資料科學領域工作多年的工程師。我的職業生涯始於Python,至今它仍然是我日常工作的主力語言。 和許多Pythonista 一樣,我曾深受效能瓶頸與記憶體壓力的困擾。大約兩年前,我為了尋找突破點而開始接觸Rust。 起初,我只是驚艷於它的執行速度;但真正觸動我的,是它在不犧牲效能的前提下,透過所有權系統提供的「記憶體安全保證」。 當我意識到編譯器能在執行前就幫我攔截掉那些在Python 中最棘手的None錯誤、資料競爭(Data Race) 或記憶體洩漏時,我體會到了一種前所未有的「安心感」。 我開始在工作中將Rust 整合進Python 工作流程。無論是將關鍵的資料處理瓶頸改用Rust 重寫,或是建構高效能的模型推論服務,Rust 都確實地解決了許多過去棘手的問題。 這份「原來程式可以寫得又快又安全」的感動,就是我撰寫這本書的初衷。 我深信Rust 與Python 的結合是資料科學的未來。這本書便是我分享這份經驗的成果,希望能幫助更多和我有過相同困擾的Pythonista,找到一條新的、通往高效能與高穩定性的路徑。
本書宗旨
首先,必須澄清一點:這本書不是要您拋棄 Python。 Python 在資料科學領域的地位是不可動搖的,其豐富的生態系統、簡潔的語法、以及龐大的社群支援,都是無可替代的優勢。我自己也是Python 的忠實使用者,並且深信它仍會是資料科學的主要語言。 那為什麼要學Rust ?因為Rust 能成為Python 最好的夥伴。 當Python 遇到效能瓶頸時,Rust 可以接手;當您需要建構高並行的資料管線時,Rust 能提供安全保證;當您想要部署輕量級的模型服務時,Rust 能提供接近C 的效能,卻不用擔心記憶體錯誤。 簡單來說,這本書要傳達的是如何在正確的時機,選擇正確的工具。 市面上不乏優秀的 Rust 入門書,但本書的定位有些許不同。 這並非一本鉅細靡遺的Rust 語法大全,而是專為Pythonista 量身打造的實戰指南,其獨特之處在於: 1.從 Pythonista 的熟悉場景出發 2.目標導向的兩階段結構 Part I:Rust 的攀登之路 ( 第 1-8 章 )。 Part II:實戰應用! ( 第 9-12 章 )。 3.特有的「雙視角」標記系統 🐍 Pythonista 視角、🦀 Rustacean 思維 4.銜接更廣闊的 Rust 生態
準備好了嗎?
如果您已經迫不及待,那就讓我們翻到第一章,開始您的 Rust 之旅吧。 學習一門新的程式語言,本質上是在學習一種新的思考方式。 Rust 的某些概念( 尤其是所有權系統) 初期可能會帶來挑戰,這很正常。 但當您跨過這個門檻,理解了其設計背後的取捨,便會體會到它在安全與效能之間取得的巧妙平衡。 請保持耐心,專注於理解每個概念背後的「為什麼」。 讓我們開始吧。 顏志穎 |










