






描述
內容簡介
|
本書是為「深度強化學習」的專家所提供的最佳參考書! 從 2013 年開始,深度強化學習已漸漸地以多種方式改變了我們的生活和世界,會下棋的AlphaGo技術展示了超過專業選手的理解能力的"圍棋之美"。
類似的情況也會發生在技術、醫療和金融領域。深度強化學習探索了一個人類最基本的問題:人類是如何透過與環境互動進行學習的?這個機制可能成為逃出“巨量資料陷阱”的關鍵因素,作為一條強人工智慧的必經之路,通向人類智慧尚未企及的地方。
本書由一群對機器學習充滿熱情的極強專家完成,展示深度強化學習的世界,透過實例和經驗介紹,加深對深度強化學習的理解。
本書覆蓋內容範圍之廣,從深度強化學習的基礎理論知識到包含程式細節的技術實現描述,是初學者和科學研究人員非常好的學習教材。
本書特色: ●深度學習精解 〇強化學習入門指引 ●深度Q網路,DQN、Double DQN、Actor-Critic 〇模仿學習 ●整合學習詳解 〇分層、多智慧體強化學習 ●平行計算 〇Learning to Run實作 ●圖型強化實作 〇模擬環境機器人實作 ●Arena多智慧體強化學習平台實作 〇強化學習技巧及最完整所有演算法說明實作 |
作者簡介
| 董豪
北京大學計算機學院、前沿計算研究中心助理教授、博士生導師,鵬城國家實驗室及浙江省北大資訊技術高等研究院雙聘成員。 於2019年獲得英國帝國理工學院博士學位,研究方向為計算機視覺和機器人。 致力於推廣人工智慧技術,是TensorLayer的創始人並獲得ACM MM最佳開源軟體獎。
丁子涵 英國帝國理工學院碩士。獲普林斯頓大學博士生全額獎學金,曾 在加拿大 Borealis AI、騰訊 Robotics X 實驗室有過工作經歷。大學就讀中 國科學技術大學,獲物理和電腦雙學位。研究方向主要涉及強化學習、機 器人控制、電腦視覺等。在 ICRA、NeurIPS、AAAI、IJCAI、Physical Review 等頂級期刊與會議發表多篇論文, 是 TensorLayer-RLzoo 、 TensorLet 和Arena 開放原始碼專案的貢獻者。
仉尚航 北京大學計算機學院助理教授、研究員。 於2018年博士畢業於美國卡內基梅隆大學,後於2020年初加入加州大學伯克利分校BAIR實驗室 (Berkeley AI Research Lab) 任博士後研究員。 研究方向主要為開放環境泛化機器學習理論與系統,同時在計算機視覺和強化學習方向擁有豐富研究經驗。 在人工智慧頂級期刊和會議上發表論文30餘篇,並申請5項美中專利。 榮獲世界人工智慧頂級會議AAAI'2021 最佳論文獎,美國2018 "EECS Rising Star",Adobe學術合作基金, Qualcomm創新獎提名等。 曾多次在國際頂級會議NeurIPS、ICML上組織Workshop,多次作為國際旗艦期刊和會議的審稿人或程式委員,擔任AAAI 2022 高級程式委員。 |
目錄
| 基礎部分
01 深度學習入門 1.1 簡介 1.2 感知器 1.3 多層感知器 1.4 啟動函數 1.5 損失函數 1.6 最佳化 1.7 正則化 1.8 卷積神經網路 1.9 循環神經網路 1.10 深度學習的實現範例
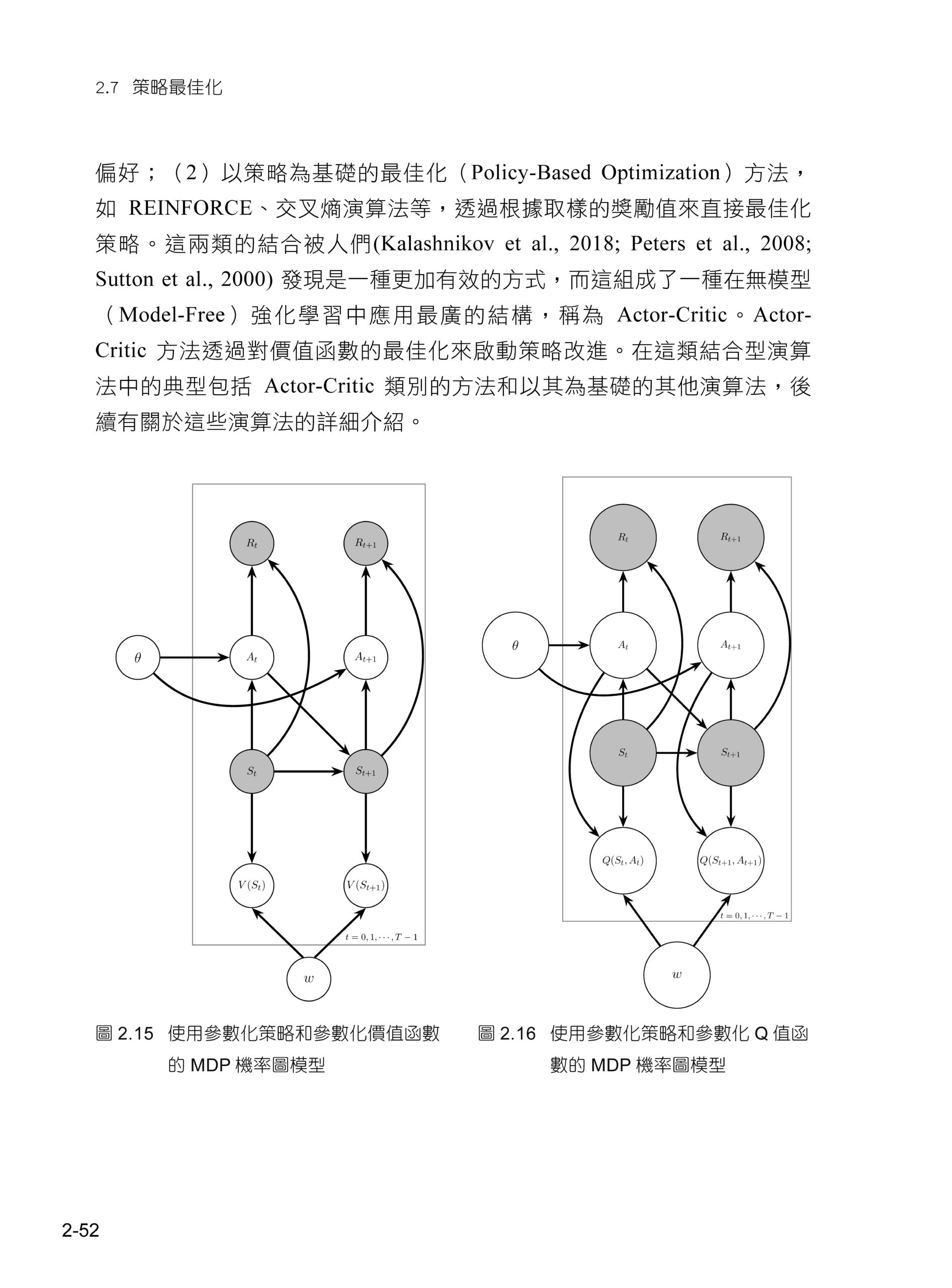
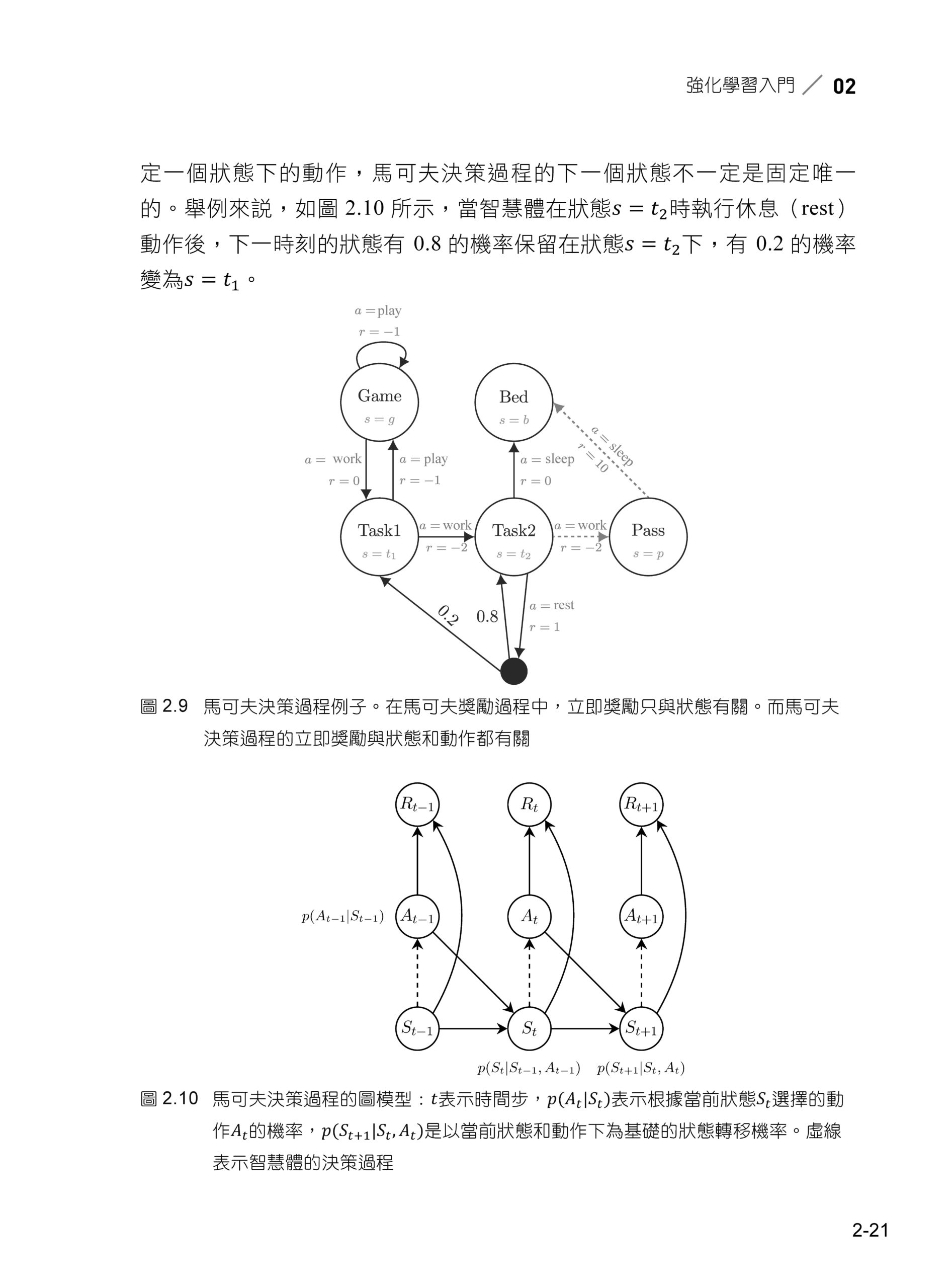
02 強化學習入門 2.1 簡介 2.2 線上預測和線上學習 2.3 馬可夫過程 2.4 動態規劃 2.5 蒙地卡羅 2.6 時間差分學習 2.7 策略最佳化
03 強化學習演算法分類 3.1 以模型為基礎的方法和無模型的方法 3.2 以價值為基礎的方法和以策略為基礎的方法 3.3 蒙地卡羅方法和時間差分方法 3.4 線上策略方法和離線策略方法
04 深度Q 網路 4.1 Sarsa 和 Q-Learning 4.2 為什麼使用深度學習:價值函數逼近 4.3 DQN 4.4 Double DQN 4.5 Dueling DQN 4.6 優先經驗重播 4.7 其他改進內容:多步學習、雜訊網路和值分佈強化學習 4.8 DQN 程式實例
05 策略梯度 5.1 簡介 5.2 REINFORCE:初版策略梯度 5.3 Actor-Critic 5.4 生成對抗網路和Actor-Critic 5.5 同步優勢Actor-Critic 5.6 非同步優勢Actor-Critic 5.7 信賴域策略最佳化 5.8 近端策略最佳化 5.9 使用Kronecker 因數化信賴域的Actor-Critic 5.10 策略梯度程式例子
06 深度Q 網路和Actor-Critic 的結合 6.1 簡介 6.2 深度確定性策略梯度演算法 6.3 孿生延遲DDPG 演算法 6.4 柔性Actor-Critic 演算法 6.5 程式例子
研究部分 07 深度強化學習的挑戰 7.1 樣本效率 7.2 學習穩定性 7.3 災難性遺忘 7.4 探索 7.5 元學習和表徵學習 7.6 多智慧體強化學習 7.7 模擬到現實 7.8 大規模強化學習 7.9 其他挑戰
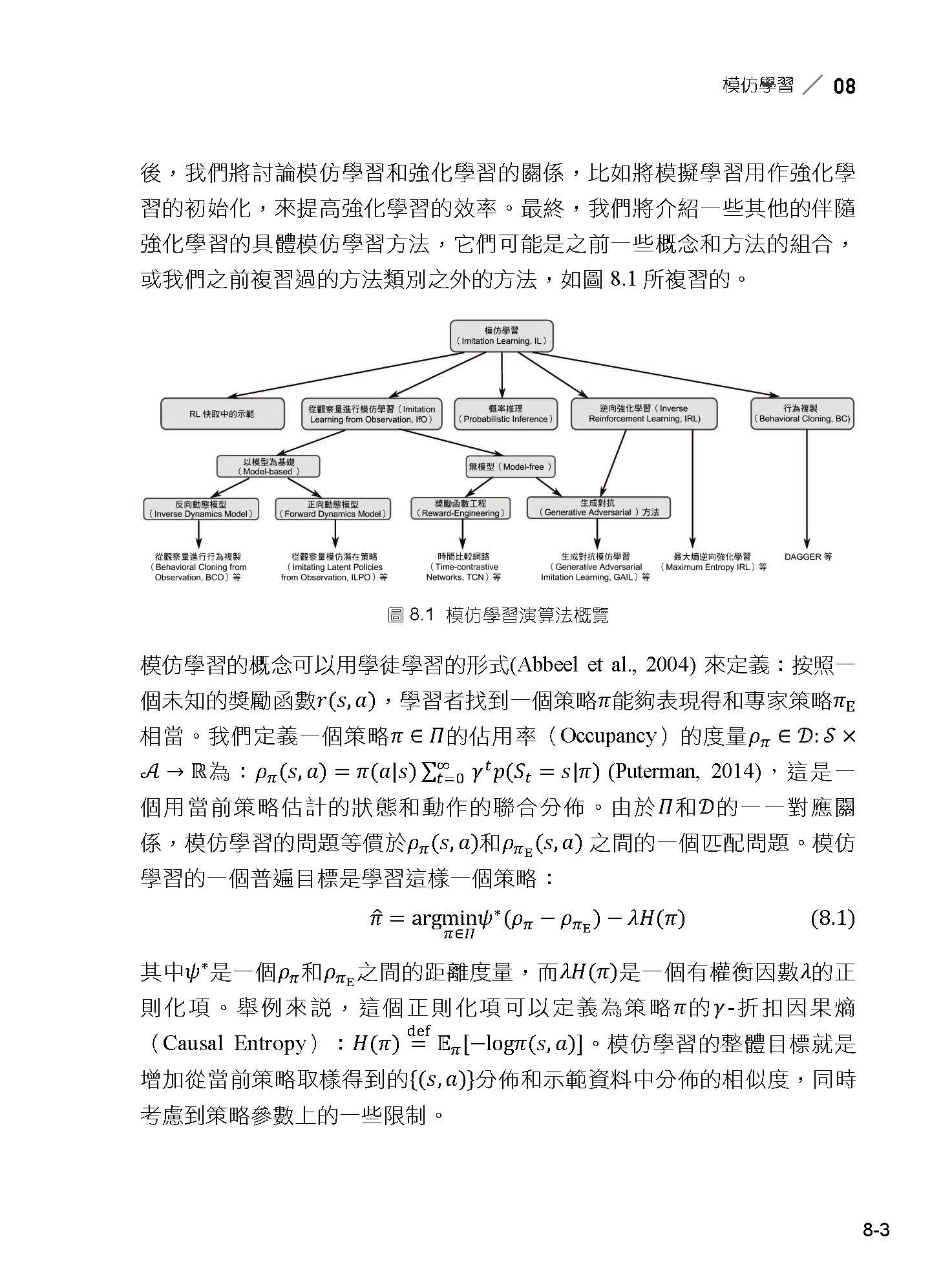
08 模仿學習 8.1 簡介 8.2 行為複製方法 8.3 逆向強化學習方法 8.4 從觀察量進行模仿學習 8.5 機率性方法 8.6 模仿學習作為強化學習的初始化 8.7 強化學習中利用示範資料的其他方法
09 整合學習與規劃 9.1 簡介 9.2 以模型為基礎的方法 9.3 整合模式架構 9.4 以模擬為基礎的搜索
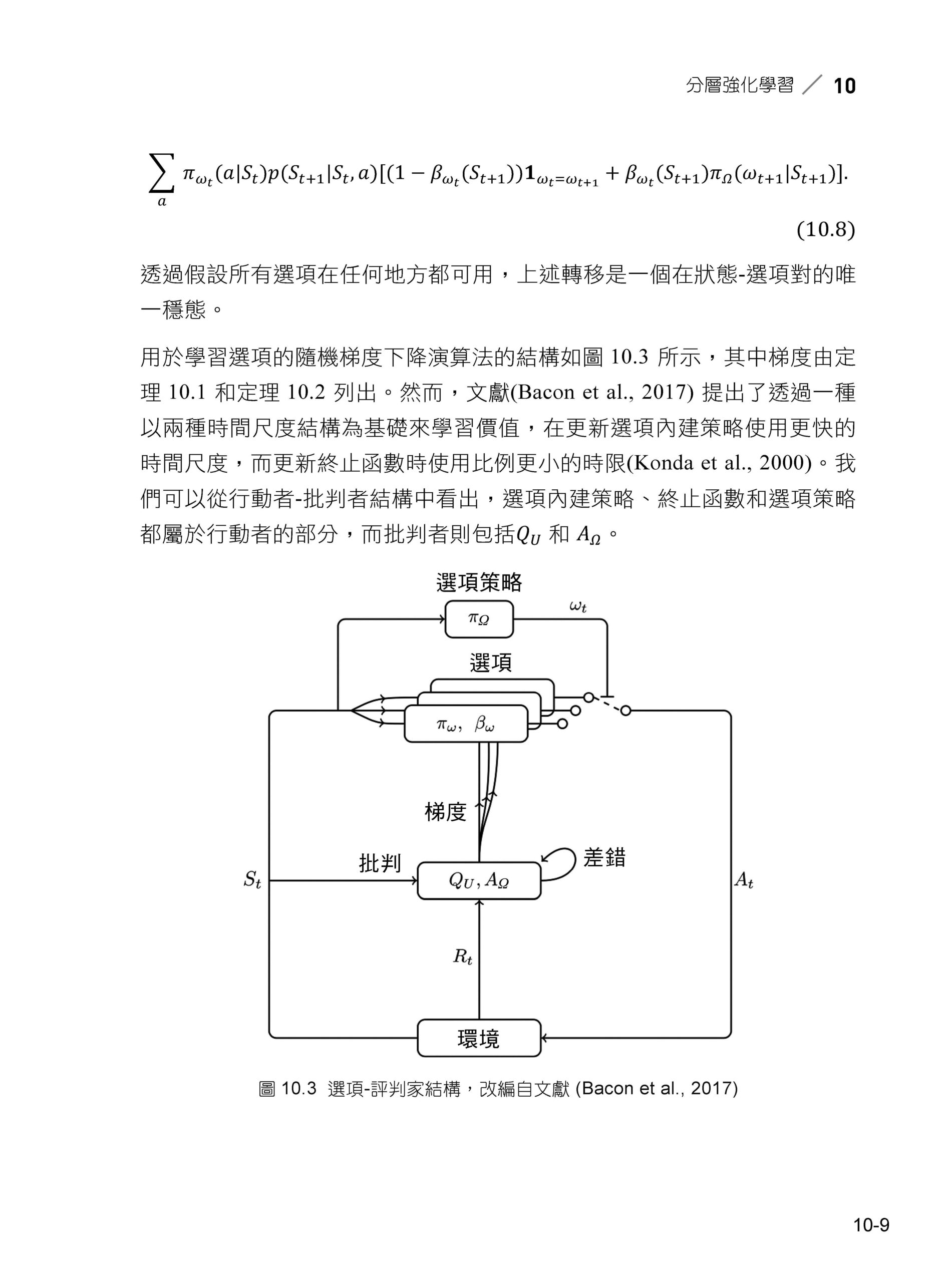
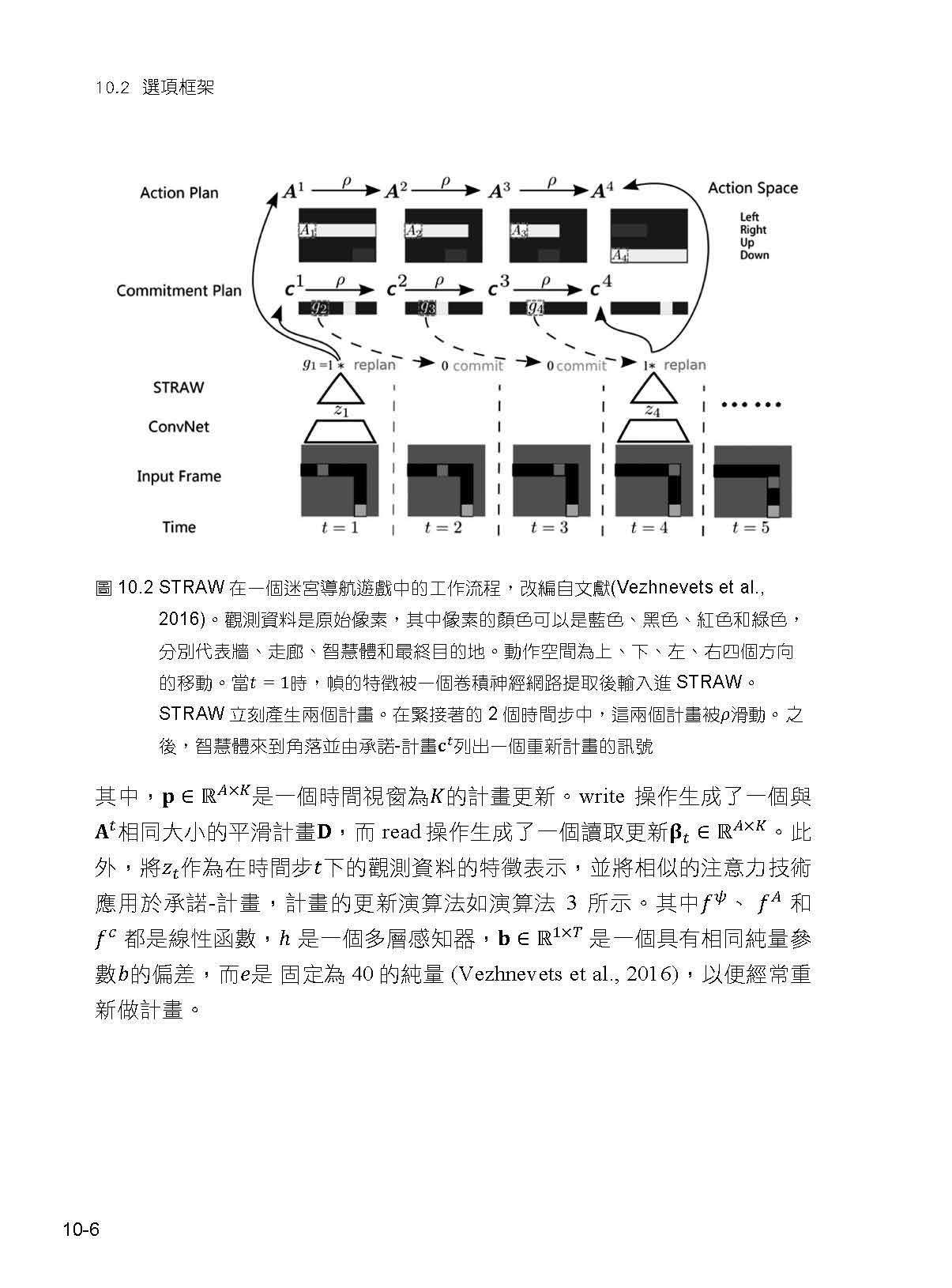
10 分層強化學習 10.1 簡介 10.2 選項框架 10.3 封建制強化學習 10.4 其他工作
11 多智慧體強化學習 11.1 簡介 11.2 最佳化和均衡 11.3 競爭與合作
12 平行計算 12.1 簡介 12.2 同步和非同步 12.3 平行計算網路 12.4 分散式強化學習演算法 12.5 分散式運算架構
應用部分 13 Learning to Run 13.1 NeurIPS 2017 挑戰:Learning to Run 13.2 訓練智慧體
14 堅固的圖型增強 14.1 圖型增強 14.2 用於堅固處理的強化學習
15 AlphaZero 15.1 簡介 15.2 組合博弈 15.3 蒙地卡羅樹搜索 15.4 AlphaZero:棋類遊戲的通用演算法
16 模擬環境中機器人學習 16.1 機器人模擬 16.2 強化學習用於機器人學習任務
17 Arena:多智慧體強化學習平台 17.1 安裝 17.2 用Arena 開發遊戲 17.3 MARL訓練
18 深度強化學習應用實踐技巧 18.1 概覽:如何應用深度強化學習 18.2 實現階段 18.3 訓練和偵錯階段
複習部分 A 演算法複習表 參考文獻
B 演算法速查表 B.1 深度學習 B.2 強化學習 B.3 深度強化學習 B.4 高等深度強化學習
C 中英文對照表 |
序
| ▍ 為什麼寫作本書
人工智慧已經成為當今資訊技術發展的主要方向,深度強化學習將結合深 度學習與強化學習演算法各自的優勢來解決複雜的決策任務。近年來,歸 功於 DeepMind AlphaGo 和OpenAI Five 這類成功的案例,深度強化學習 受到大 量的關注,相關技術廣泛用於金融、醫療、軍事、能源等領域。為 此,學術界和產業界急需大量人才,而深度強化學習作為人工智慧中的智 慧決策部分,是理論與工程相結合的重要研究方向。本書將以通俗易懂的 方式講解相關技術,並輔以實踐教學。
▍ 本書主要內容 本書分為三大部分,以盡可能覆蓋深度強化學習所需要的全部內容。 第一部分介紹深度學習和強化學習的入門知識、一些非常基礎的深度強化 學習演算法及其實現 細節,請見第 1~6 章。 第二部分是一些精選的深度強化學習研究題目,請見第 7~12 章,這些內 容對準備開展深度強化學習研究的讀者非常有用。 為了幫助讀者更深入地學習深度強化學習,並把相關技術用於實踐,本書 第三部分提供了豐富的例子,包括 AlphaZero、讓機器人學習跑步等,請 見第 13~17 章。
▍ 如何閱讀本書 本書是為電腦科學專業背景、希望從零學習深度強化學習並開展研究課題 和實踐項目的學生準備的。本書也適用於沒有很強機器學習背景、但是希 望快速學習深度強化學習並把它應用到具體產品中的軟體工程師。 鑒於不同的讀者情況會有所差異(比如,有的讀者可能是第一次接觸深度 學習,而有的讀者可能已經對深度學習有一定的了解;有的讀者已經有一 些強化學習基礎;有的讀者只是想了解強化學習的概念,而有的讀者是準 備長期從事深度強化學習研究的),這裡根據不同的讀者情況給予不同的 閱讀建議。 1.要了解深度強化學習。 第 1~6 章覆蓋了深度強化學習的基礎知識,其中第 2 章是最關鍵、最 基礎的內容。如果您已經有深度學習基礎,可以直接跳過第 1 章。第 3 章、附錄A 和附錄B 複習了不同的演算法。 2.要從事深度強化學習研究。 除了深度學習的基礎內容,第 7 章介紹了當今強化學習技術發展遇到 的各種挑戰。您可以透過閱讀第 8~12 章來進一步了解不同的研究方 向。 3.要在產品中使用深度強化學習。 如果您是工程師,希望快速地在產品中使用深度強化學習技術,第 13 ~17 章是您關注的重點。您可以根據業務場景中的動作空間和觀測種 類來選擇最相似的應用例子,然後運用到您的業務中。 董豪 |