










描述
內容簡介
| ►回顧對話機器人歷史,從人機交流到現代語言模型
►解析人工智慧發展,聚焦通用人工智慧(AGI) ►指導大型語言模型私有化部署,涵蓋環境建置 ►介紹語言模型核心理論,從統計方法到Transformer ►解析Hugging Face與Transformers函數庫應用 ►介紹高效微調技術,如Prompt Tuning與LoRA ►實作LoRA與QLoRA微調GLM-4,提升效能 ►探討提示工程,提升模型推理與應用能力 ►解析多角色對話與AI Agent的運作模式 ►介紹LangChain框架,涵蓋Chain與Agents ►展示垂直領域模型應用,以紅十字會資料實作 ►解析檢索增強生成(RAG),結合LLM與知識庫
本書第一章回顧對話機器人的發展,探討人工智慧的演進與未來趨勢。第二章介紹大型語言模型的私有化部署,包括CUDA環境建置、PyTorch安裝與GLM-4模型執行。第三章解析語言模型的理論基礎,涵蓋統計語言模型、Transformer架構與Attention機制。第四章說明Hugging Face與Transformers函數庫的應用,幫助讀者開發與微調LLM。第五章介紹高效微調技術,如Prompt Tuning、LoRA、QLoRA等方法,提升模型效能。第六章進一步探討LoRA微調GLM-4的實戰應用與量化技術。第七章解析提示工程,說明Few-shot、Chain of Thought等推理增強技術。第八章介紹AI Agent與多角色對話模式,並探討Function Calling的應用。第九章深入LangChain框架,涵蓋Chain、Memory與Agents的實作,並整合資料庫與檢索增強生成(RAG)技術。第十章展示大型模型在垂直領域的應用,例如微調GLM-4處理紅十字會資料,提供完整的實戰示範。 |
目錄
| ▍第1章 從零開始大型模型之旅
1.1 對話機器人歷史 1.1.1 人機同頻交流 1.1.2 人機對話發展歷史 1.2 人工智慧 1.2.1 從感知到創造 1.2.2 通用人工智慧 1.2.3 發展方向 1.2.4 本書焦點 1.3 本章小結
▍第2章 大型模型私有化部署 2.1 CUDA 環境準備 2.1.1 基礎環境 2.1.2 大型模型執行環境 2.1.3 安裝顯示卡驅動 2.1.4 安裝CUDA 2.1.5 安裝cuDNN 2.2 深度學習環境準備 2.2.1 安裝Anaconda 環境 2.2.2 伺服器環境下的環境啟動 2.2.3 安裝PyTorch 2.3 GLM-3 和GLM-4 2.3.1 GLM-3 介紹 2.3.2 GLM-4 介紹 2.4 GLM-4 私有化部署 2.4.1 建立虛擬環境 2.4.2 下載GLM-4 專案檔案 2.4.3 安裝專案相依套件 2.4.4 下載模型權重 2.5 執行GLM-4 的方式 2.5.1 基於命令列的互動式對話 2.5.2 基於Gradio 函數庫的Web 端對話應用 2.5.3 OpenAI 風格的API 呼叫方法 2.5.4 模型量化部署 2.6 本章小結
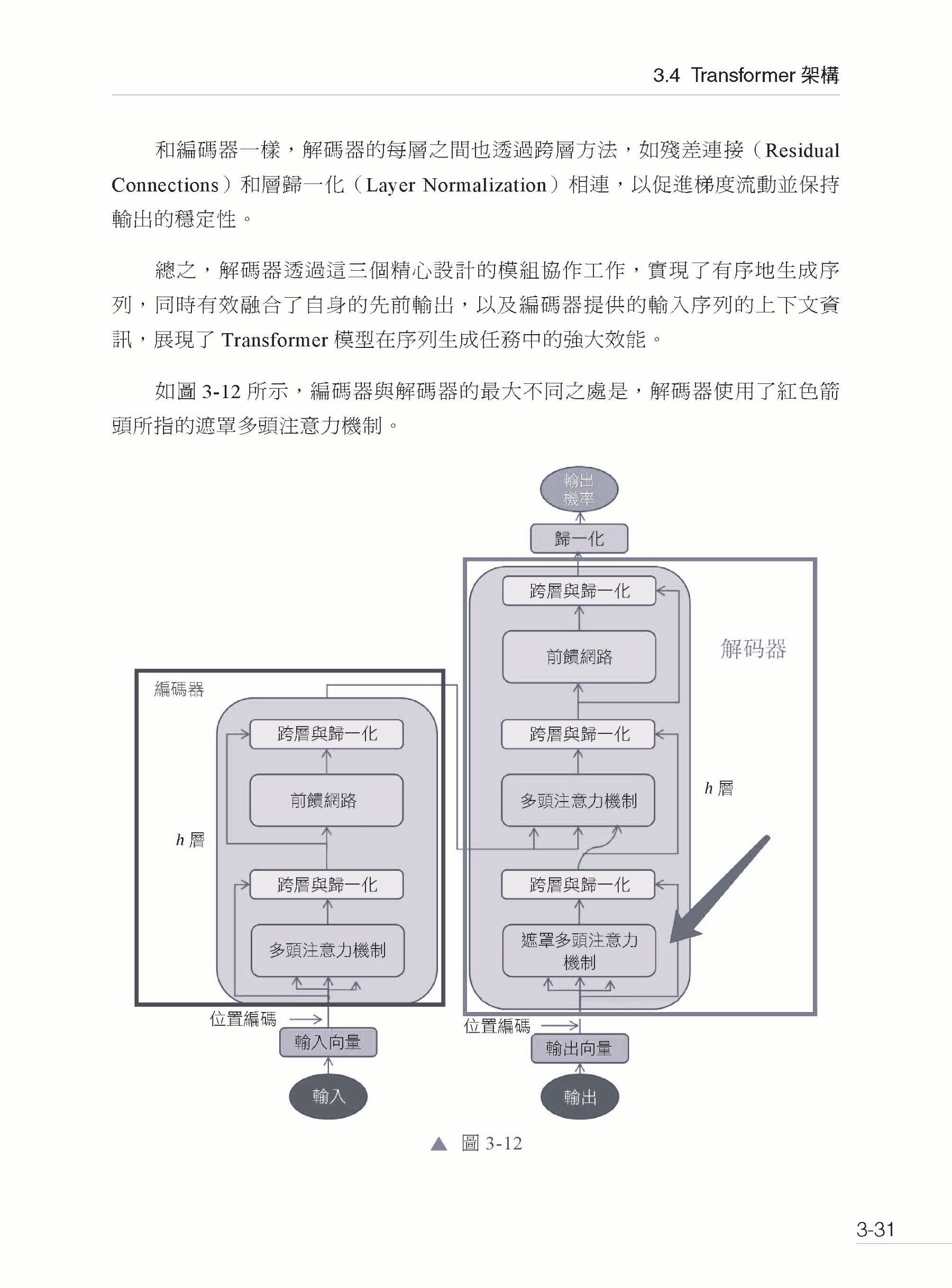
▍第3章 大型模型理論基礎 3.1 自然語言領域中的資料 3.1.1 時間序列資料 3.1.2 分詞 3.1.3 Token 3.1.4 Embedding 3.1.5 語義向量空間 3.2 語言模型歷史演進 3.2.1 語言模型歷史演進 3.2.2 統計語言模型 3.2.3 神經網路語言模型 3.3 注意力機制 3.3.1 RNN 模型 3.3.2 Seq2Seq 模型 3.3.3 Attention 注意力機制 3.4 Transformer 架構 3.4.1 整體架構 3.4.2 Self-Attention 3.4.3 Multi-Head Attention 3.4.4 Encoder 3.4.5 Decoder 3.4.6 實驗效果 3.5 本章小結
▍第4章 大型模型開發工具 4.1 Huggingface 4.1.1 Huggingface 介紹 4.1.2 安裝Transformers 函數庫 4.2 大型模型開發工具 4.2.1 開發範式 4.2.2 Transformers 函數庫核心設計 4.3 Transformers 函數庫詳解 4.3.1 NLP 任務處理全流程 4.3.2 資料轉換形式 4.3.3 Tokenizer 4.3.4 模型載入和解讀 4.3.5 模型的輸出 4.3.6 模型的儲存 4.4 全量微調訓練方法 4.4.1 Datasets 函數庫和Accelerate 函數庫 4.4.2 資料格式 4.4.3 資料前置處理 4.4.4 模型訓練的參數 4.4.5 模型訓練 4.4.6 模型評估 4.5 本章小結
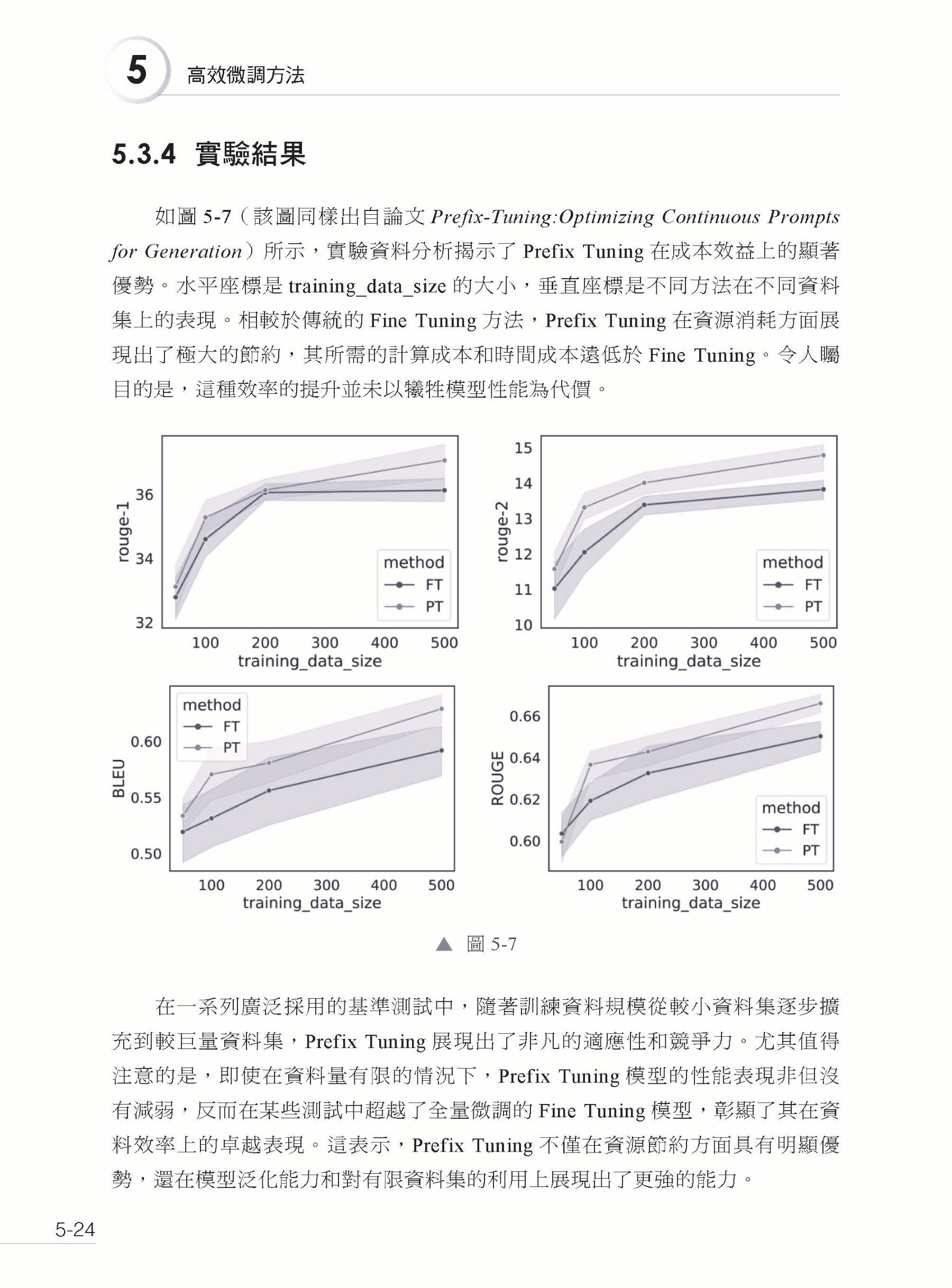
▍第5章 高效微調方法 5.1 主流的高效微調方法介紹 5.1.1 微調方法介紹 5.1.2 Prompt 的提出背景 5.2 PEFT 函數庫快速入門 5.2.1 介紹 5.2.2 設計理念 5.2.3 使用 5.3 Prefix Tuning 5.3.1 背景 5.3.2 核心技術解讀 5.3.3 實現步驟 5.3.4 實驗結果 5.4 Prompt Tunin 5.4.1 背景 5.4.2 核心技術解讀 5.4.3 實現步驟 5.4.4 實驗結果 5.5 P-Tuning 5.5.1 背景 5.5.2 核心技術解讀 5.5.3 實現步驟 5.5.4 實驗結果 5.6 P-Tuning V2 5.6.1 背景 5.6.2 核心技術解讀 5.6.3 實現步驟 5.6.4 實驗結果 5.7 本章小結
▍第6章 LoRA 微調GLM-4 實戰 6.1 LoRA 6.1.1 背景 6.1.2 核心技術解讀 6.1.3 LoRA 的特點 6.1.4 實現步驟 6.1.5 實驗結果 6.2 AdaLoRA 6.2.1 LoRA 的缺陷 6.2.2 核心技術解讀 6.2.3 實現步驟 6.2.4 實驗結果 6.3 QLoRA 6.3.1 背景 6.3.2 技術原理解析 6.4 量化技術 6.4.1 背景 6.4.2 量化技術分類 6.4.3 BitsAndBytes 函數庫 6.4.4 實現步驟 6.4.5 實驗結果 6.5 本章小結
▍第7章 提示工程入門與實踐 7.1 探索大型模型潛力邊界 7.1.1 潛力的來源 7.1.2 Prompt 的六個建議 7.2 Prompt 實踐 7.2.1 四個經典推理問題 7.2.2 大型模型原始表現 7.3 提示工程 7.3.1 提示工程的概念 7.3.2 Few-shot 7.3.3 透過思維鏈提示法提升模型推理能力 7.3.4 Zero-shot-CoT 提示方法 7.3.5 Few-shot-CoT 提示方法 7.4 Least-to-Most Prompting(LtM 提示方法) 7.4.1 Least-to-Most Prompting 基本概念 7.4.2 Zero-shot-LtM 提示過程 7.4.3 效果驗證 7.5 提示使用技巧 7.5.1 B.R.O.K.E 提示框架 7.5.2 C.O.A.S.T 提示框架 7.5.3 R.O.S.E.S 提示框架 7.6 本章小結
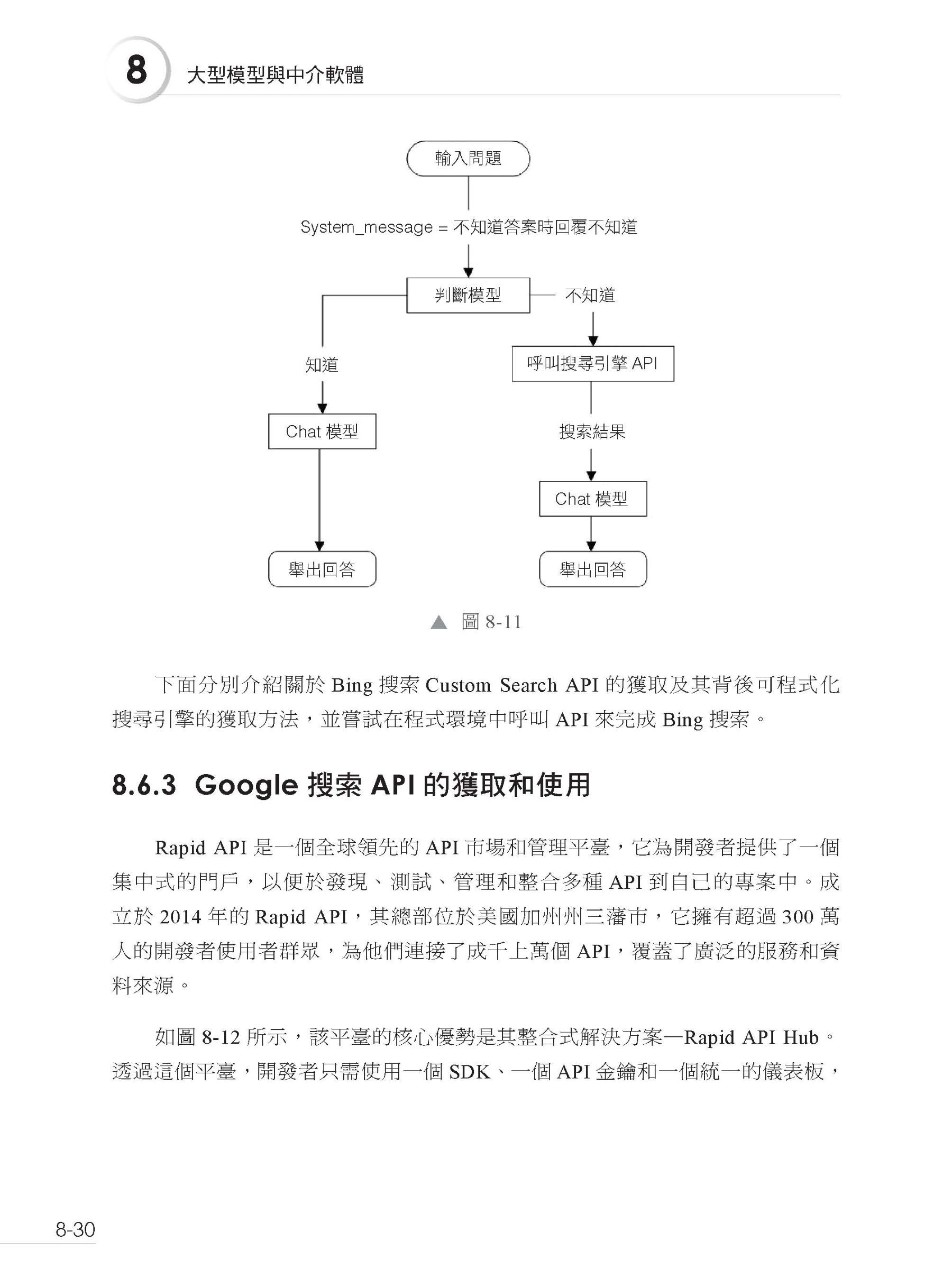
▍第8章 大型模型與中介軟體 8.1 AI Agent 8.1.1 從AGI 到Agent 8.1.2 Agent 概念 8.1.3 AI Agent 應用領域 8.2 大型模型對話模式 8.2.1 模型分類 8.2.2 多角色對話模式 8.3 多角色對話模式實戰 8.3.1 messages 參數結構及功能解釋 8.3.2 messages 參數中的角色劃分 8.4 Function Calling 功能 8.4.1 發展歷史 8.4.2 簡單案例 8.5 實現多函數 8.5.1 定義多個工具函數 8.5.2 測試結果 8.6 Bing 搜索嵌入LLM 8.6.1 曇花一現的Browsing with Bing 8.6.2 需求分析 8.6.4 建構自動搜索問答機器人 8.7 本章小結
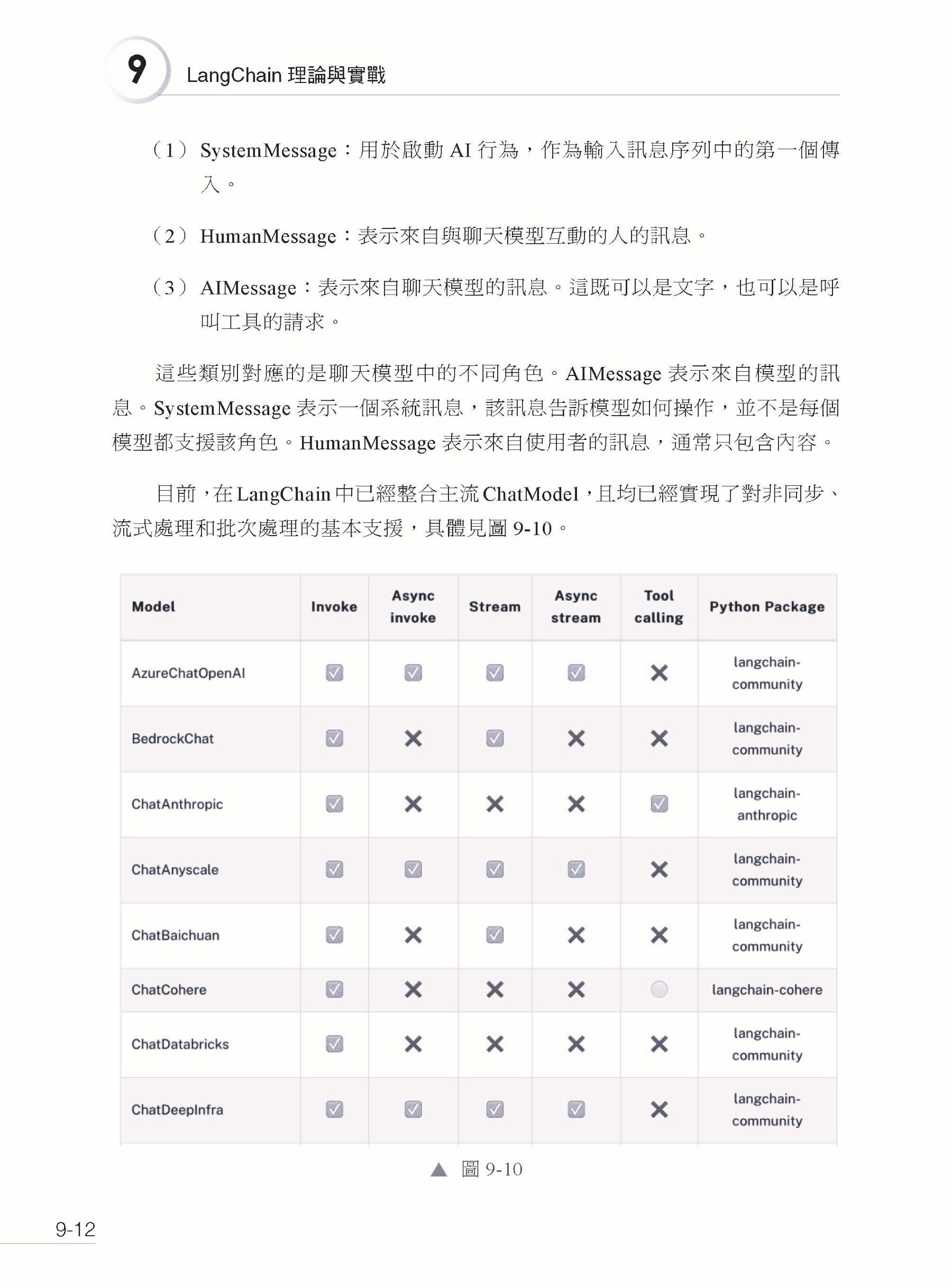
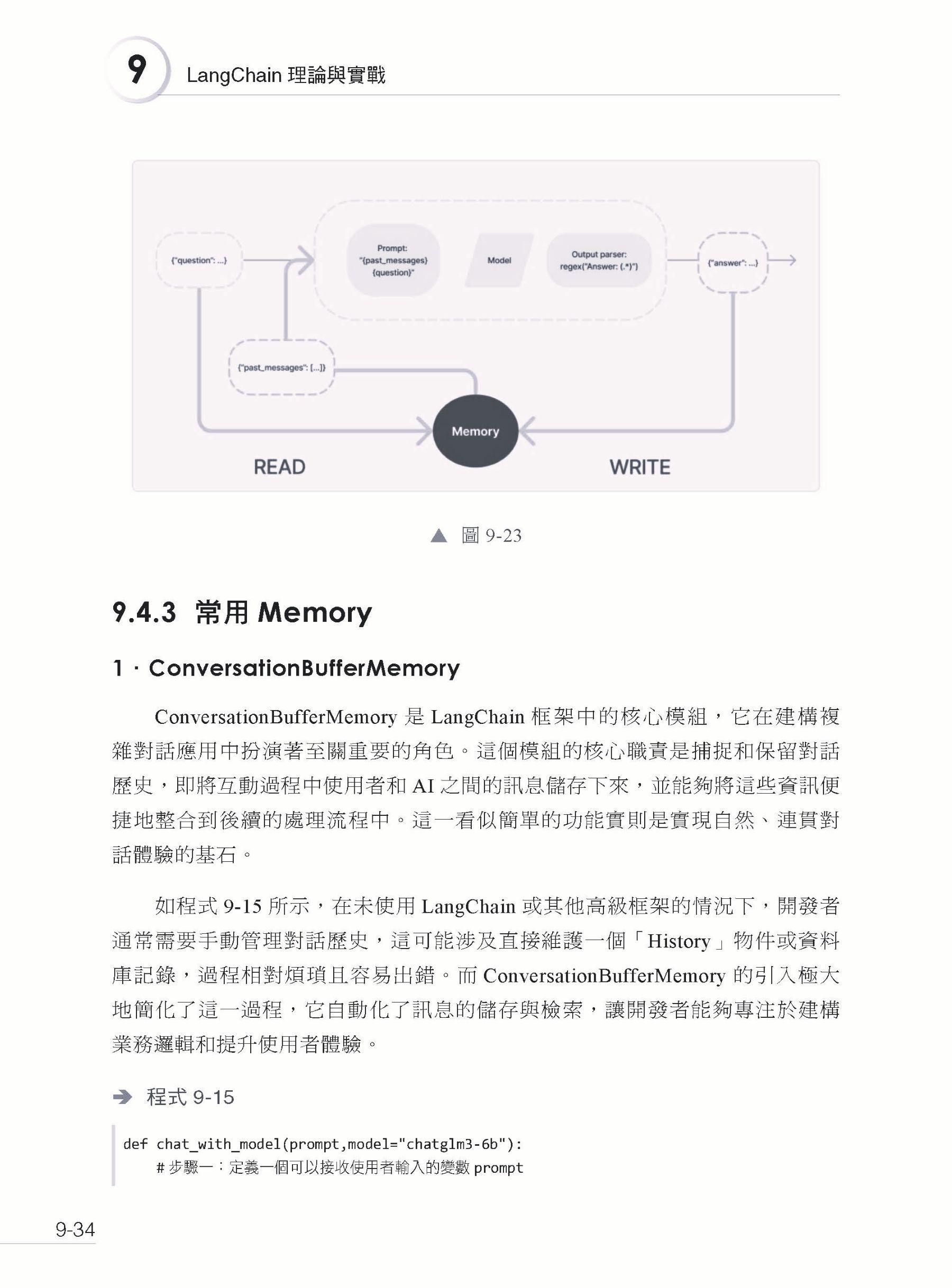
▍第9章 LangChain 理論與實戰 9.1 整體介紹 9.1.1 什麼是LangChain 9.1.2 意義 9.1.3 整體架構 9.2 Model I/O 9.2.1 架構 9.2.2 LLM 9.2.3 ChatModel 9.2.4 Prompt Template 9.2.5 實戰:LangChain 連線本地GLM 9.2.6 Parser 9.3 Chain 9.3.1 基礎概念 9.3.2 常用的Chain 9.4 Memory 9.4.1 基礎概念 9.4.2 流程解讀 9.4.3 常用Memory 9.5 Agents 9.5.1 理論 9.5.2 快速入門 9.5.3 架構 9.6 LangChain 實現Function Calling 9.6.1 工具定義 9.6.2 OutputParser 9.6.3 使用 9.7 本章小結
▍第10章 實戰:垂直領域大型模型 10.1 QLoRA 微調GLM-4 10.1.1 定義全域變數和參數 10.1.2 紅十字會資料準備 10.1.3 訓練模型 10.2 大型模型連線資料庫 10.2.1 大型模型挑戰 10.2.2 資料集準備 10.2.3 SQLite3 10.2.4 獲取資料庫資訊 10.2.5 建構tools 資訊 10.2.6 模型選擇 10.2.7 效果測試 10.3 LangChain 重寫查詢 10.3.1 環境配置 10.3.2 工具使用 10.4 RAG 檢索增強 10.4.1 自動化資料生成 10.4.2 RAG 架設 10.5 本章小結
▍參考文獻 |
序
| 前言
我們需要什麼樣的大型模型 面對未來的浪潮,我們不禁思考:何種大型模型將引領時代?這是一個值得我們深入探討的課題。隨著AI(Artificial Intelligence,人工智慧)技術的迅猛發展,AI 是否會成為未來的主導力量?隨著AI 技術的高速進步,一個常見的問題是:這股力量是否將取代人類的位置? 答案並非如此簡單。AI 的確在以驚人的速度學習和進步,它在各個企業中的應用也獲得了顯著的成功。大型模型的應用已成為推動各領域突破性進展的關鍵動力。特別是在醫療、法律、金融等特定垂直領域,大型模型的微調面臨著獨特的挑戰和需求。 本書旨在深入探討大型模型的微調與應用的核心技術,為讀者揭示企業前端,特別注意兩個熱門的應用方向:大型模型的知識專業性和時效性。我們將剖析垂直領域模型訓練的背景及意義,探討模型在垂直領域的遷移學習、應用部署與效果評估等核心內容。透過實際案例的深入淺出解析,我們將揭示每個環節的關鍵問題和解決方案,引領讀者了解企業內最新的研究趨勢,並便捷地將這些知識應用到各個企業中。 比爾.蓋茲是微軟的聯合創始人,他預見性地指出,像ChatGPT 這樣的AI聊天機器人將與個人電腦和網際網路一樣,成為不可或缺的技術里程碑。 英偉達總裁黃仁勳則將ChatGPT 比作AI 領域的iPhone,它預示著更多偉大事物的開始。ChatGPT 的誕生在社會上引起了巨大的轟動,因為它代表了大型模型技術和預訓練模型在自然語言處理領域的重要突破。它不僅提升了人機互動的能力,還為智慧幫手、虛擬智慧人物和其他創新應用開啟了新的可能性。 本書專為對AI 感興趣的讀者而設計。即讓讀者沒有深厚的電腦知識背景,但只要具備相關的基礎知識,便能跟隨本書中的步驟,在個人電腦上輕鬆實踐案例操作。我們精心準備了完整的程式範例,旨在幫助讀者將抽象的理論知識轉化為手頭的實際技能。 本書獨樹一幟的講解風格,將深奧的技術術語轉化為簡潔明了的語言,案例敘述既嚴謹又充滿趣味,確保讀者在輕鬆愉快的閱讀體驗中自然而然地吸收和理解AI 知識。 AI 時代已經到來,取代我們的不會是AI,而是那些更擅長利用AI 力量的人。讓我們攜手邁進這個新時代,共同揭開AI 的無限潛能。 在本書的撰寫過程中,我們深感榮幸地獲得了許多科學研究同行的鼎力相助與無私奉獻。特別感謝中國科學院大學的劉宜松,他負責了本書程式的撰寫,並為程式的精確性與實用性付出了巨大努力。王凱、孫翔宇和張明哲對程式進行了細緻入微的審閱,確保了程式的品質與可靠性。 中國礦業大學的劉威為本書的圖文並茂貢獻良多,他負責的圖片製作工作極大地提升了讀者的閱讀體驗。 我們還要感謝以下企事業單位的慷慨支援:東莞市紅十字會分享了他們珍貴的企業資料,為本書的研究提供了實證支援;英特爾(中國)有限公司的張晶為我們提供了技術測試,確保了書中技術的先進性與實用性;廣東創新科技職業學院的創始人方植麟提供了大型模型態資料,為本書的研究深度與廣度提供了堅實基礎。 在出版流程中,電子工業出版社的秦淑靈編輯給予了我們極大的幫助與支援,她的專業意見和辛勤工作使得本書得以順利面世。 在此,我們對所有貢獻者表示最誠摯的感謝!我們相信,這本書將成為一盞明燈,指引我們深入探索AI 的奧妙,共同開啟AI 世界的無限可能。 我們誠摯地邀請讀者和專家們不吝賜教,您的寶貴意見將幫助我們不斷完善。歡迎您將建議發送至電子郵件:aidg0769@sina.com。 作者 |