







描述
內容簡介
機器學習最強入門邁向AI高手王者歸來(全彩印刷)內容簡介 ★★★★★【數學原理 + 演算法 + 真實案例 + 專題實作】★★★★★ ★★★★★【數學 x機率 x 統計 x 演算法】★★★★★ ★★★★★【機器學習演算法 x AI專題】★★★★★
AI時代的學習革命:用最簡單的方式掌握機器學習。 機器學習已成為當今科技領域的核心技能,但艱澀的數學與複雜的概念常讓人望而卻步。本書以淺顯易懂的白話解釋,結合全彩圖表輔助教學,幫助讀者輕鬆入門、快速掌握機器學習的核心知識與應用技巧。
本書特色 ◎ 白話解釋機器學習:摒棄晦澀公式,以簡單明瞭的語言說明每個概念,配合豐富的全彩圖表,讓學習變得更輕鬆有趣。 ◎ 基礎數學起步,實現 AI 場景應用:從基礎數學概念講解機器學習,逐步導入 AI 在生活中的實際應用,橋接理論與實務。 ◎ 彩色圖解演算法,從小數據開始:用彩色圖像化的方式清晰呈現演算法的運作原理,並從簡單的小數據案例帶領讀者進入真實世界的應用。 ◎ 實用程式碼範例:提供完整的 Python 程式碼範例,將理論知識與實務結合,幫助讀者快速上手,並理解如何將理論轉化為可行的程式解決方案。 ◎ AI 專題實戰:涵蓋特徵選擇、模型選擇、超參數調整等進階主題,提供解決特定問題的策略與技巧,助力讀者邁向機器學習高手之路。
數學場景 × AI 實例 ◎ 方程式、一元到多元函數 ★餐廳經營、業務員績效、網路行銷 ... 等。 ◎ 最小平方法 ★國際證照考卷銷售、房價預測、便利店銷售 ... 等。 ◎ 機率與單純貝式理論 ★疾病分析、客戶購買意願、垃圾郵件 ... 等。 ◎ 指數、對數與激活函數 ★廣告效果、回購率分析 ... 等。 ◎ 基礎統計 ★超商數據、考試成績 ... 等。 ◎迴歸分析 ★臉書行銷、冰品銷售、網站購物 ... 等。 ◎向量與矩陣 ★網購行為分析、推薦系統、家庭用電預測 ... 等。
演算法原理 × AI 專題 ◎ 房價預測 ★ 波士頓房價 ☆ 加州房價 ◎ 葡萄酒專題 ★ 葡萄酒分類與評價 ◎ 醫療健康 ★ 糖尿病診斷 ☆ 乳腺癌檢測 ★ 醫療保險分析 ◎ 經典數據集 ★ 鐵達尼號生存分析 ☆ Telco 離網預測 ★ 零售數據分析 ◎ 信用風險與客戶分析 ★ 信用卡欺詐偵測 ☆ 購物中心客戶分群 ◎ 科學與工程 ★ 小行星撞地球風險預測 ☆ 汽車燃料效率分析 ◎ 文字與推薦系統 ★ 新聞分類 ☆ 情感分析 ★ 電影推薦與評論 ◎ 特色數據 ★ 鳶尾花分類 ☆ 蘑菇毒性判斷 ★ 玻璃性質分析 ◎ 圖像數據 ★ 手寫數字識別 ☆ 人臉數據分析 ◎ 農業與食品 ★ 小麥數據研究 ☆ 老實泉噴發分析 ◎ 體育與電子郵件 ★ 足球射門分析 ☆ 垃圾郵件過濾
將理論融入實際,從數據出發探索機器學習的多元應用,這是您邁向 AI 高手的最佳起點! |
作者簡介
|
目錄
| ▌第1章 機器學習基本觀念
1-1 人工智慧、機器學習、深度學習 1-2 認識機器學習 1-3 機器學習的種類 1-3-1 監督學習 1-3-2 無監督學習 1-3-3 強化學習 1-4 機器學習的應用範圍 1-5 深度學習
▌第2章 機器學習的基礎數學 2-1 用數字描繪事物 2-2 變數觀念 2-3 從變數到函數 2-4 用數學抽象化開餐廳的生存條件 2-4-1 數學模型 2-4-2 經營數字預估 2-4-3 經營績效的計算 2-4-4 情境分析 - 變數變化的影響 2-5 基礎數學的應用與總結 2-5-1 基礎數學的應用範例 2-5-2 基礎數學的總結
▌第3章 認識方程式、函數與座標圖形 3-1 認識方程式 3-2 方程式文字描述方法 3-3 一元一次方程式 3-4 函數 3-5 座標圖形分析 3-5-1 座標圖形與線性關係 3-5-2 斜率與截距的意義 3-5-3 細看斜率 3-5-4 細看y截距 3-5-5 細看x截距 3-6 將線性函數應用在機器學習 3-6-1 再看直線函數與斜率 3-6-2 機器學習與線性迴歸 3-6-3 相同斜率平行移動 3-6-4 不同斜率與相同截距 3-6-5 不同斜率與不同截距 3-7 二元函數到多元函數 3-7-1 二元函數基本觀念 3-7-2 二元函數的圖形 3-7-3 等高線圖 3-7-4 多元函數 3-8 Sympy 模組 3-8-1 定義符號 3-8-2 name 屬性 3-8-3 定義多個符號變數 3-8-4 符號的運算 3-8-5 將數值代入公式 3-8-6 將字串轉為數學表達式 3-8-7 Sympy 模組支援的數學函數 3-8-8 解一元一次方程式
▌第4章 從聯立方程式看機器學習的數學模型 4-1 數學觀念建立連接兩點的直線 4-1-1 基礎觀念 4-1-2 聯立方程式 4-1-3 使用加減法解聯立方程式 4-1-4 使用代入法解聯立方程式 4-1-5 使用Sympy 解聯立方程式 4-2 機器學習使用聯立方程式推估數據 4-2-1 推導餐廳經營績效函數 4-2-2 餐廳經營績效數據推估 4-2-3 聯立方程式在線性模型中的應用 4-3 從2 條直線的交叉點推估科學數據 4-3-1 雞兔同籠 4-3-2 達成業績目標 4-4 兩條直線垂直交叉 4-4-1 基礎觀念 4-4-2 求解座標某一點至一條線的垂直線 4-5 本章總結與下一步展望
▌第5章 從畢氏定理看機器學習 5-1 驗證畢氏定理 5-1-1 認識直角三角形 5-1-2 驗證畢氏定理 5-2 將畢氏定理應用在性向測試 5-2-1 問題核心分析 5-2-2 數據運算 5-3 將畢氏定理應用在三維空間 5-4 將畢氏定理應用在更高維的空間 5-5 電影分類 5-5-1 規劃特徵值 5-5-3 專案程式實作 5-5-4 電影分類結論 5-6 計算兩個向量的歐幾里德距離 5-7 本章總結與應用展望
▌第6章 聯立不等式與機器學習 6-1 聯立不等式與機器學習 6-2 再看聯立不等式的基本觀念 6-3 聯立不等式的線性規劃 6-3-1 案例分析 6-3-2 用聯立不等式表達 6-3-3 在座標軸上繪不等式的區域 6-3-4 目標函數 6-3-5 平行移動目標函數 6-3-6 將交叉點座標代入目標函數 6-4 Python 計算 6-5 聯立不等式的商業應用 6-5-1 廣告投入最佳分配 6-5-2 產品生產成本最小化 6-6 本章總結與應用展望
▌第7章 機器學習需要知道的二次函數 7-1 二次函數的基礎數學 7-1-1 解一元二次方程式的根 7-1-2 繪製一元二次方程式的圖形 7-1-3 一元二次方程式的最小值與最大值 7-1-4 一元二次函數參數整理 7-1-5 一元三次函數的圖形特徵 7-1-6 二次函數在機器學習中的應用價值 7-2 從一次到二次函數的實務 7-2-1 呈現好的變化 7-2-2 呈現不好的變化 7-3 認識二次函數的係數 7-4 使用3個點求解一元二次函數 7-4-1 手動求解一元二次函數 7-4-2 程式求解一元二次函數 7-4-3 繪製一元二次函數 7-4-4 使用業績回推應有的拜訪次數 7-5 一元二次函數的配方法 7-5-1 基本觀念 7-5-2 配方法 7-5-3 從標準式計算一元二次函數的最大值 7-5-4 從標準式計算一元二次函數的最小值 7-6 一元二次函數與解答區間 7-6-1 行銷問題分析 7-6-2 一元二次函數分析增加業績的臉書行銷次數 7-6-3 將不等式應用在條件區間 7-6-4 非實數根
▌第8章 機器學習的最小平方法 8-1 最小平方法基本觀念 8-1-1 基本觀念 8-1-2 數學觀點 8-2 簡單的企業實例 8-3 機器學習建立含誤差值的線性方程式 8-3-1 觀念啟發 8-3-2 三項和的平方 8-3-3 公式推導 8-3-4 使用配方法計算直線的斜率和截距 8-4 Numpy 實作最小平方法 8-5 線性迴歸 8-6 便利商店飲料銷售實務應用 8-7 模型評估指標 8-7-1 認識模型評估指標 8-7-2 手工計算與程式執行房價模型評估 8-7-3 用模型評估指標檢視便利商店飲料銷售
▌第9章 機器學習必須懂的集合 9-1 使用Python 建立集合 9-1-1 使用{ } 建立集合 9-1-2 集合元素是唯一 9-1-3 使用set( ) 建立集合 9-1-4 集合的基數(cardinality) 9-1-5 建立空集合要用set( ) 9-1-6 大數據資料與集合的應用 9-2 集合的操作 9-2-1 交集(intersection) 9-2-2 聯集(union) 9-2-3 差集(difference) 9-2-4 對稱差集(symmetric difference) 9-3 子集、宇集與補集 9-3-1 子集 9-3-2 宇集 9-3-3 補集
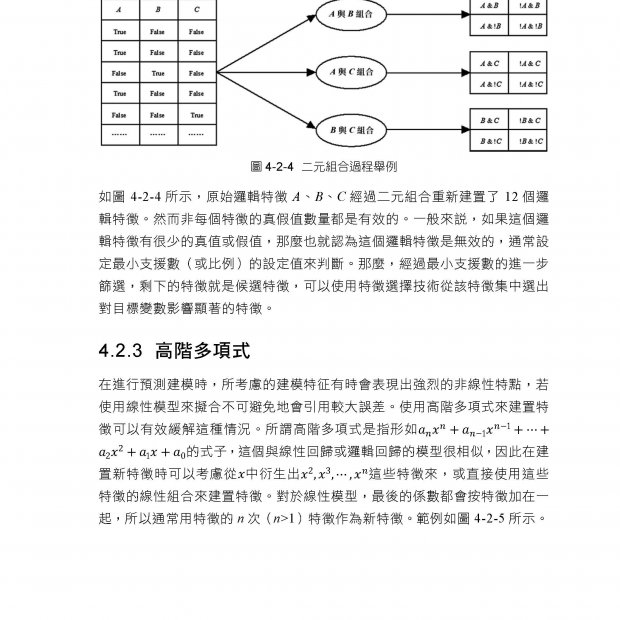
▌第10章 機器學習必須懂的排列與組合 10-1 排列基本觀念 10-1-1 實驗與事件 10-1-2 事件結果 10-1-3 機器學習應用場景 10-2 有多少條回家路 10-2-1 計算有多少條回家的路 10-2-2 回家的路於機器學習的應用場景 10-3 排列組合 10-4 階乘的觀念 10-5 重複排列 10-6 組合
▌第11章 機器學習需要認識的機率 11-1 機率基本觀念 11-2 數學機率與統計機率 11-3 事件機率名稱 11-4 事件機率規則 11-4-1 不發生機率 11-4-2 機率相加 11-4-3 機率相乘 11-4-4 常見的陷阱 11-4-5 Python 模擬事件重複發生的機率計算 11-5 抽獎的機率 – 加法與乘法綜合應用 11-6 餘事件與乘法的綜合應用 11-7 條件機率 11-7-1 基礎觀念 11-7-2 擲骰子的其他實例 11-8 貝氏定理 11-8-1 基本觀念 11-8-2 用實例驗證貝氏定理 11-8-3 疾病診斷模型 11-8-4 客戶購買意願預測 11-9 COVID-19 的全民普篩準確性推估 11-9-1 COVID-19 準確性推估 11-9-2 再看一個醫學實例 11-10 垃圾郵件篩選 11-10-1 貝氏定理篩選垃圾電子郵件基礎觀念 11-10-2 垃圾郵件分類專案實作
▌第12章 二項式定理 12-1 二項式的定義 12-2 二項式的幾何意義 12-3 二項式展開與規律性分析 12-4 找出xn-kyk 項的係數 12-4-1 基礎觀念 12-4-2 組合數學觀念 12-4-3 係數公式推導與驗證 12-5 二項式的通式 12-5-1 驗證頭尾係數比較 12-5-2 中間項係數驗證 12-6 二項式到多項式 12-7 二項分佈實驗 12-8 用二項式分析國際證照考試業務 12-9 二項式機率分佈Python 實作 12-10 Numpy 隨機數模組的binomial( ) 函數 12-10-1 視覺化模組Seaborn 12-10-2 Numpy 的二項式隨機函數binomial 12-11 二項分佈的創新應用與機器學習實踐 12-11-1 品質控制中的不良品檢測 12-11-2 臨床試驗中的藥物療效 12-11-3 廣告轉換率的預測 12-11-4 機器學習場景 - 二項分佈在二分類問題中的應用
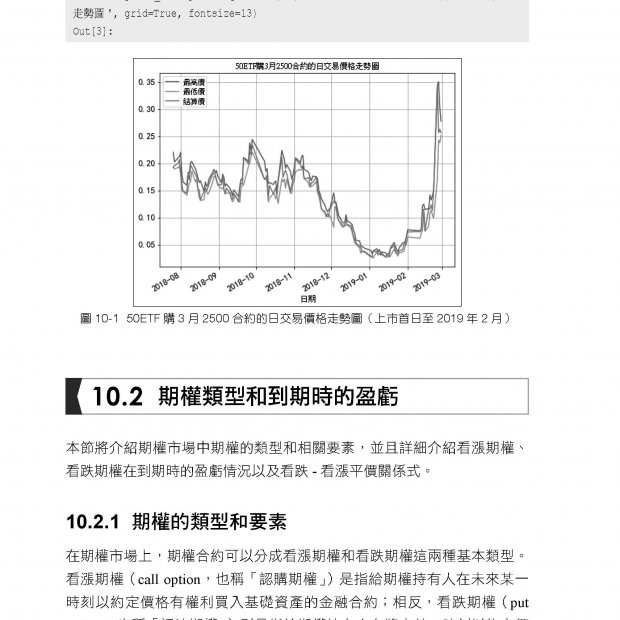
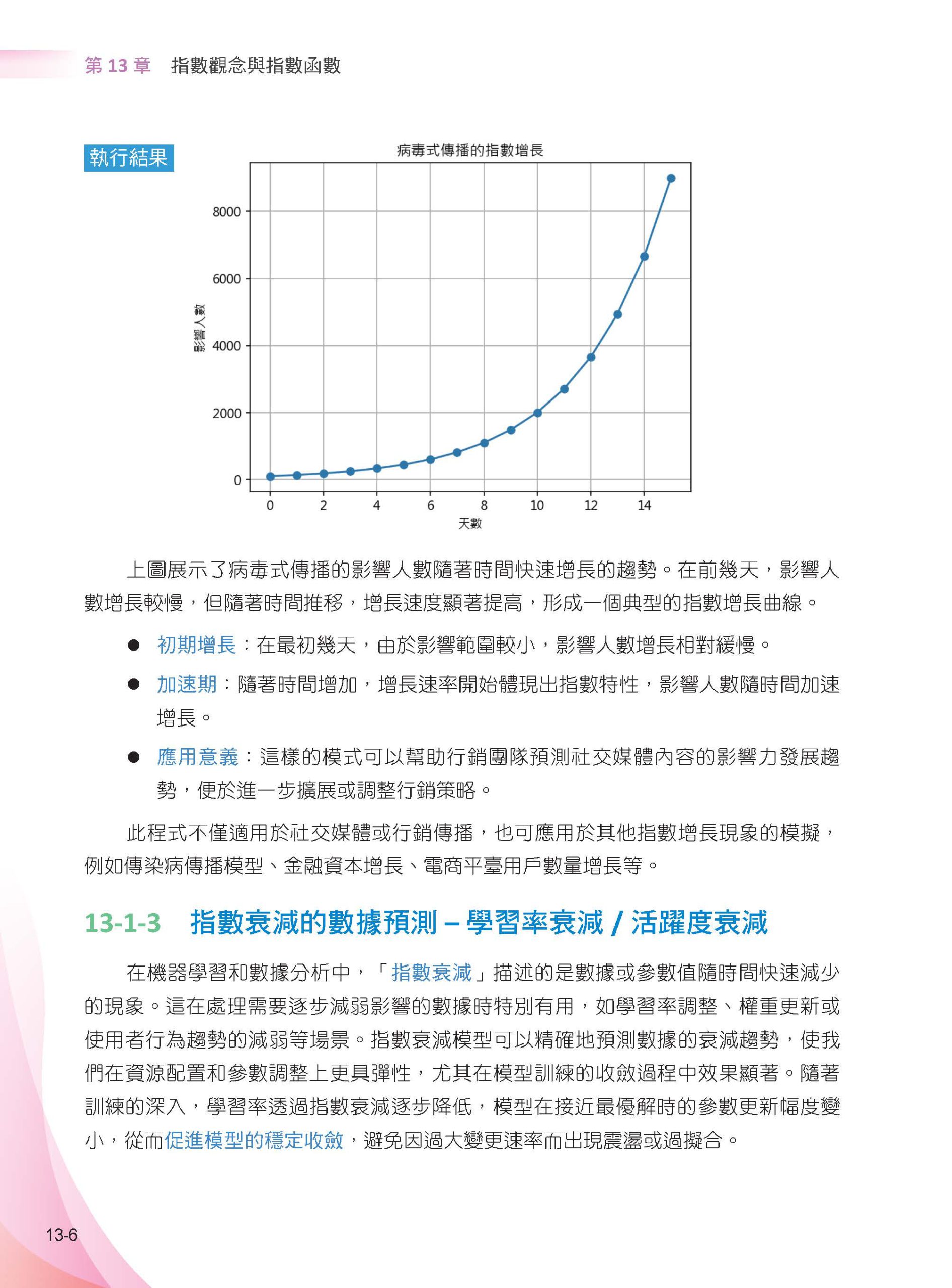
▌第13章 指數觀念與指數函數 13-1 認識指數函數 13-1-1 基礎觀念 13-1-2 指數增長的數據預測 – 用戶增長/ 病毒式行銷 13-1-3 指數衰減的數據預測 – 學習率衰減/ 活躍度衰減 13-1-4 用指數觀念看iPhone 容量 13-2 指數運算的核心規則與應用 13-2-1 指數運算規則 13-2-2 指數運算 - 數據標準化 13-2-3 指數運算 - 激活函數的應用 13-3 指數函數的圖形 13-3-1 底數是變數的指數函數圖形 13-3-2 指數冪是實數變數
▌第14章 機器學習中的對數運算與應用 14-1 機器學習中對數概念與應用背景 14-1-1 對數的由來 14-1-2 從數學看指數的運作觀念 14-1-3 再看對數函數 14-1-4 天文數字的處理 14-1-5 Python 的對數函數應用 14-1-6 機器學習 - 對數運算在特徵縮放中的應用 14-1-7 機器學習 - 對數變換處理異常值 14-1-8 機器學習 - 交叉熵損失函數中的對數應用 14-2 對數表的歷史與數據科學應用 14-2-1 對數表基礎應用 14-2-2 更精確的對數表 14-3 對數運算與指數問題的簡化 14-3-1 用指數處理相當數值的近似值 14-3-2 使用對數簡化運算 14-3-3 簡化大數據的乘法與指數操作 14-3-4 對數控制指數增長的數據範圍 14-4 對數特性與機器學習應用 14-5 對數的運算規則與驗證 14-5-1 等號兩邊使用對數處理結果不變 14-5-2 對數的真數是1 14-5-3 對數的底數等於真數 14-5-4 對數內真數的指數可以移到外面 14-5-5 對數內真數是兩數據相乘結果是兩數據各取對數後再相加 14-5-6 對數內真數是兩數據相除結果是兩數據先取對數後再相減 14-5-7 底數變換
▌第15章 指數函數與激活函數的應用 15-1 認識歐拉數 15-1-1 認識歐拉數 15-1-2 歐拉數的緣由 15-1-3 歐拉數使用公式做定義 15-1-4 計算與繪製歐拉數的函數圖形 15-1-5 指數衰減策略中的歐拉數應用 15-2 邏輯斯函數 15-2-1 認識邏輯斯函數 15-2-2 x 是正無限大 15-2-3 x 是0 15-2-4 x 是負無限大 15-2-5 繪製邏輯斯函數 15-2-6 Sigmoid 函數 15-3 logit 函數 15-3-1 認識Odds 15-3-2 從Odds 到logit 函數 15-3-3 繪製logit 函數 15-4 邏輯斯函數的應用 15-4-1 事件說明與分析 15-4-2 從邏輯斯函數到logit 函數 15-4-3 使用logit 函數獲得係數 15-4-4 邏輯斯函數在二元分類模型中的延伸應用 15-5 Softmax 函數的應用
▌第16章 機器學習數據處理與統計基礎 16-1 機器學習視角 - 母體與樣本 16-1-1 母體與樣本 16-1-2 機器學習視角看母體與樣本 16-2 數據加總與聚合操作 16-2-1 符號運算規則、驗證與活用 16-2-2 數據加總 16-2-3 數據的聚合操作 16-3 認識數據分佈與其在機器學習中的應用 16-3-1 認識數據分佈 16-3-2 數據分佈在機器學習中的應用 16-3-3 數據分佈與演算法選擇 16-3-4 對數轉換應用於偏態分佈數據 16-4 數據中心趨勢與機器學習應用 16-4-1 平均數(mean) 16-4-2 中位數(median) 16-4-3 眾數(mode) 16-4-4 機器學習角度執行工資數據分析 16-4-5 分數分佈圖 16-5 數據分散指標 – 變異數與標準差 16-5-1 變異數 16-5-2 標準差 16-5-3 數據分散指標的應用
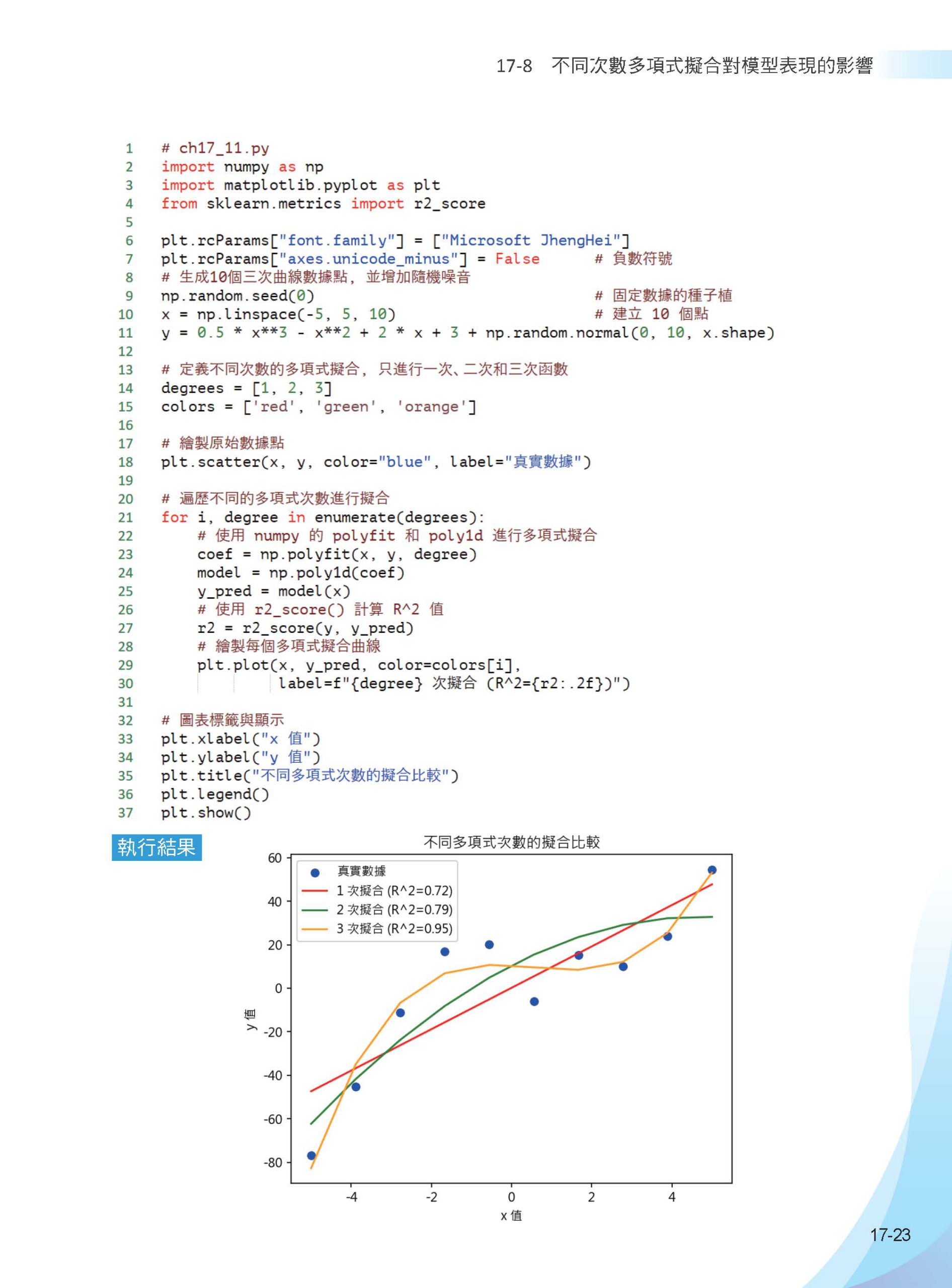
▌第17章 機器學習的迴歸分析 17-1 背景與概念介紹 17-2 相關係數(Correlation Coefficient) 17-2-1 認識相關係數 17-2-2 相關係數在迴歸模型中扮演的角色 17-3 建立線性迴歸模型與數據預測 17-3-1 建立迴歸模型 17-3-2 數據預測 17-4 二次函數的迴歸模型 17-5 三次函數的迴歸曲線模型 17-6 使用scikit-learn 模組評估迴歸模型 17-6-1 迴歸模型選擇的基礎觀念 17-6-2 更完整解釋評估模型與scikit-learn方法支援 17-6-3 預測估計時間的銷售預測 17-7 不適合的迴歸分析的實例 17-7-1 繪製三次函數迴歸線 17-7-2 計算R平方判定係數 17-8 不同次數多項式擬合對模型表現的影響
▌第18章 機器學習的向量 18-1 向量的基礎觀念 18-1-1 機器學習的向量知識 18-1-2 認識純量 18-1-3 認識向量 18-1-4 向量表示法 18-1-5 計算向量分量 18-1-6 相對位置的向量 18-1-7 不同路徑的向量運算 18-2 向量加法與機器學習的應用 18-2-1 認識向量加法規則 18-2-2 向量加法在機器學習的應用 18-3 向量的長度 18-4 向量方程式 18-4-1 直線方程式 18-4-2 Python 實作連接2點的方程式 18-4-3 使用向量建立迴歸方程式的理由 18-5 向量內積/餘弦相似度 – 推薦系統設計 18-5-1 協同工作的觀念 18-5-2 計算B所幫的忙 18-5-3 向量內積的定義 18-5-4 兩條直線的夾角 18-5-5 向量內積的性質 18-5-6 餘弦相似度 18-5-7 音樂推薦系統設計 18-5-8 向量內積的應用 18-6 皮爾遜相關係數原理 – 特徵篩選應用 18-6-1 網路購物問卷調查案例解說 18-6-3 向量內積計算係數 18-6-4 皮爾遜相關係數的應用
▌第19章 機器學習的矩陣 19-1 矩陣的表達方式與機器學習應用場景 19-1-1 矩陣的行與列方式 19-1-2 矩陣變數名稱 19-1-3 常見的矩陣表達方式 19-1-4 矩陣元素表達方式 19-1-5 行列的定義在機器學習中的應用 19-2 矩陣相加/相減與機器學習場景應用 19-2-1 基礎觀念 19-2-2 Python 定義矩陣 19-2-3 機器學習矩陣加法運算場景 19-2-4 機器學習矩陣減法運算場景 19-3 矩陣乘以實數與機器學習場景應用 19-4 矩陣乘法與在機器學習的場景 19-4-1 乘法基本規則 19-4-2 乘法案例 19-4-3 矩陣乘法規則 19-4-4 機器學習場景的應用 19-5 方形矩陣 19-6 單位矩陣 19-7 反矩陣與轉置矩陣 19-7-1 基礎觀念 19-7-2 用反矩陣解聯立方程式 19-7-3 轉置矩陣基礎觀念 19-7-4 轉置矩陣的規則 19-7-5 轉置矩陣與皮爾遜相關係數 19-8 深度學習框架的數據表示法 - 張量(Tensor)
▌第20章 向量、矩陣與多元線性迴歸 20-1 向量和矩陣在多元線性迴歸的重要性 20-2 向量應用在線性迴歸 20-3 向量應用在多元線性迴歸 20-4 矩陣應用在多元線性迴歸 20-5 將截距放入矩陣 20-6 簡單的線性迴歸 20-7 多元線性迴歸矩陣方程式的推導 20-8 專題 - 業績預測/用電量預測 20-8-1 廣告與銷售 20-8-2 家庭用電量預測
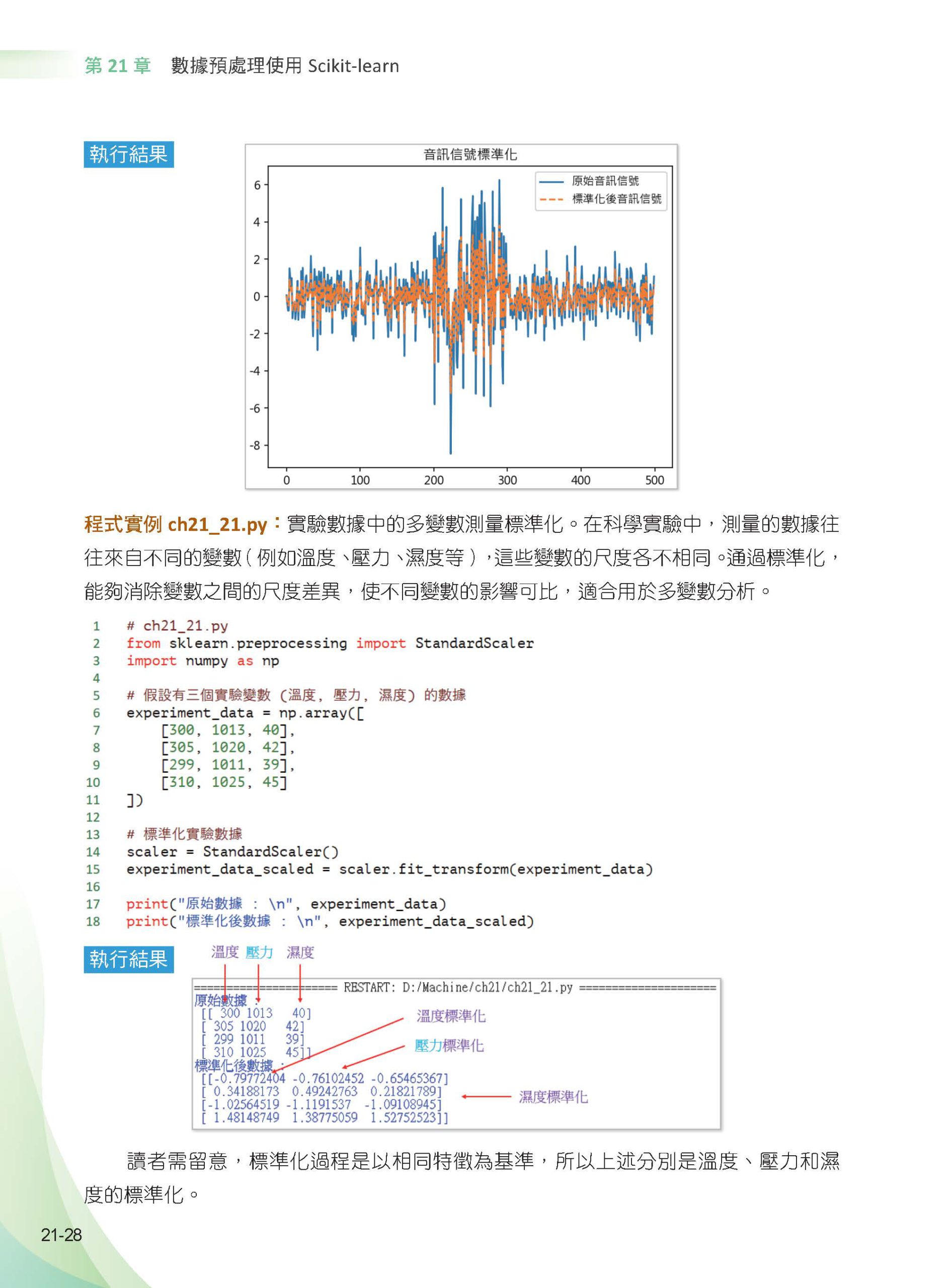
▌第21章 數據預處理使用Scikit-learn 21-1 Scikit-learn 的歷史 21-2 機器學習的數據集 21-2-1 Scikit-learn 內建的數據集 21-2-2 Kaggle 數據集 21-2-3 UCI 數據集 21-2-4 scikit-learn 函數生成數據 21-3 scikit-learn 生成數據實作 21-3-1 線性分佈數據 - make_regression 21-3-2 集群分佈數據 - make_blobs 21-3-3 交錯半月群集數據 - make_moons 21-3-4 環形結構分佈的群集數據– make_circles 21-3-5 產生n-class 分類數據集 21-4 Scikit-learn 數據預處理 21-4-1 標準化數據StandardScaler 21-4-2 設定數據區間MinMaxScaler 21-4-3 特殊數據縮放RobustScaler
▌第22章 機器學習使用Scikit-learn 入門 22-1 用Scikit-learn 處理線性迴歸 22-1-1 身高與體重的資料 22-1-2 線性擬合數據LinearRegression 22-1-3 資料預測predict 22-1-4 模型的儲存與開啟 22-1-5 計算線性迴歸線的斜率和截距 22-1-6 R 平方判定係數檢驗模型的性能 22-2 機器學習分類演算法 - 模型的性能評估 22-2-1 計算精確度accuracy_score 22-2-2 召回率recall_score 22-2-3 精確率precision_score 22-2-4 F1 分數f1_score 22-2-5 分類報告classification_report 22-2-6 混淆矩陣confusion_matrix 22-2-7 ROC_AUC 分數 22-3 機器學習必需會的非數值資料轉換 22-3-1 One-hot 編碼 22-3-2 特徵名稱由中文改為英文 22-3-3 資料對應map 方法 22-3-4 標籤轉換LabelEncoder 22-4 機器學習演算法 22-5 使用隨機數據學習線性迴歸 22-5-1 建立訓練數據與測試數據使用train_test_split 22-5-2 迴歸模型判斷 22-5-3 score 和r2_score 方法的差異
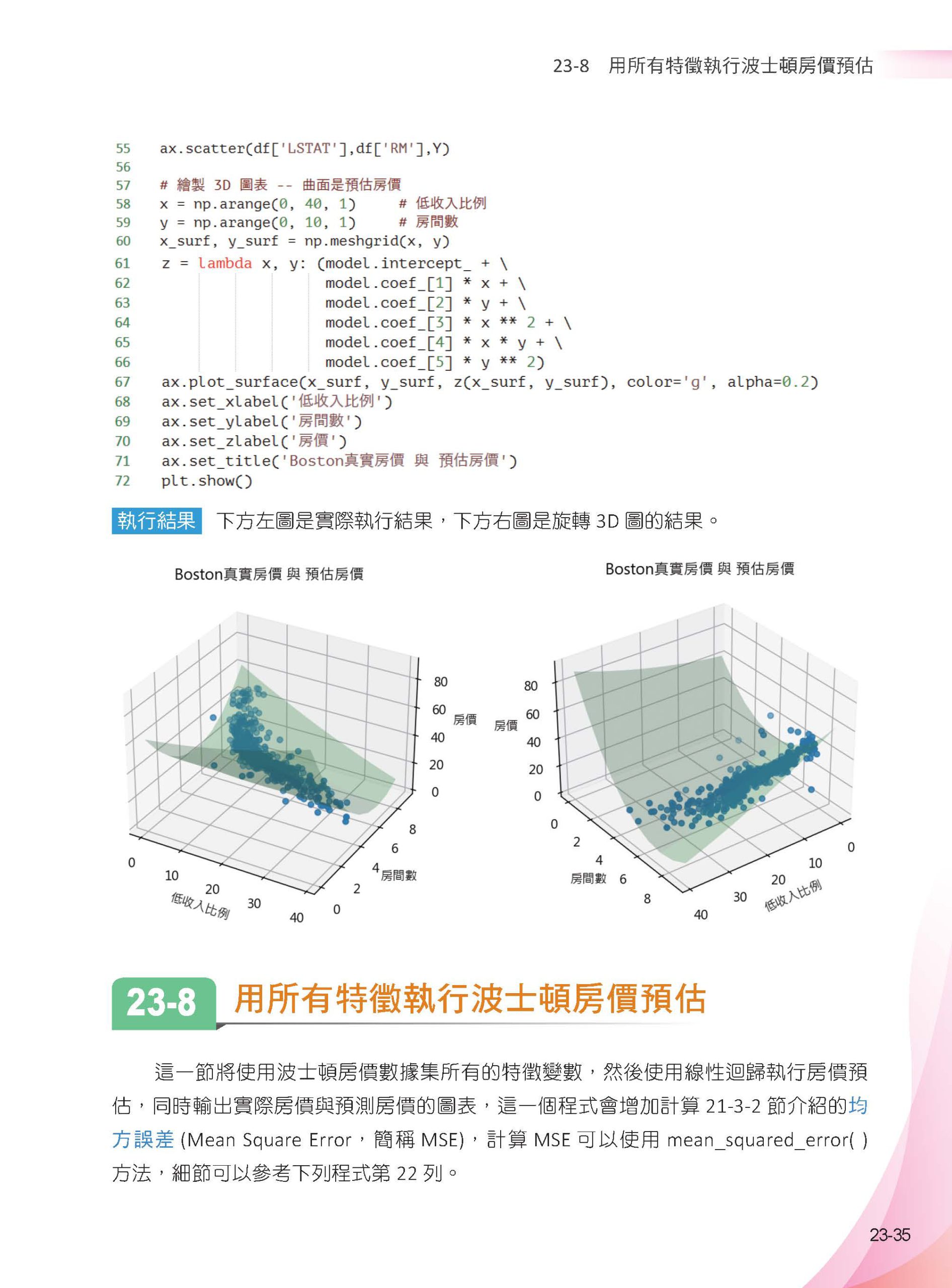
▌第23章 線性迴歸 - 波士頓房價 23-1 從線性迴歸到多元線性迴歸 23-1-1 簡單線性迴歸 23-1-2 多元線性迴歸 23-2 簡單資料測試 23-2-1 身高、腰圍與體重的測試 23-2-2 了解模型的優劣 23-3 波士頓房價數據集 23-3-1 認識波士頓房價數據集 23-3-2 輸出數據集 23-4 用Pandas 顯示與預處理數據 23-4-1 用Pandas 顯示波士頓房價數據 23-4-2 將房價加入DataFrame 23-4-3 數據清洗 23-5 特徵選擇 23-6 使用最相關的特徵做房價預估 23-6-1 繪製散點圖 23-6-2 建立模型獲得R 平方判定係數、截距與係數 23-6-3 計算預估房價 23-6-4 繪製實際房價與預估房價 23-6-5 繪製3D 的實際房價與預估房價 23-7 多項式迴歸 23-7-1 繪製散點圖和迴歸直線 23-7-2 多項式迴歸公式 23-7-3 生成一元二次迴歸公式的多個特徵項目 23-7-4 多項式特徵應用在LinearRegression 23-7-5 機器學習理想模型 23-7-6 多元多項式的迴歸模型 23-7-7 繪製3D 的實際房價與預估房價 23-8 用所有特徵執行波士頓房價預估 23-9 殘差圖(Residual plot) 23-10 梯度下降迴歸SGDRegressor 23-11 數據洩漏
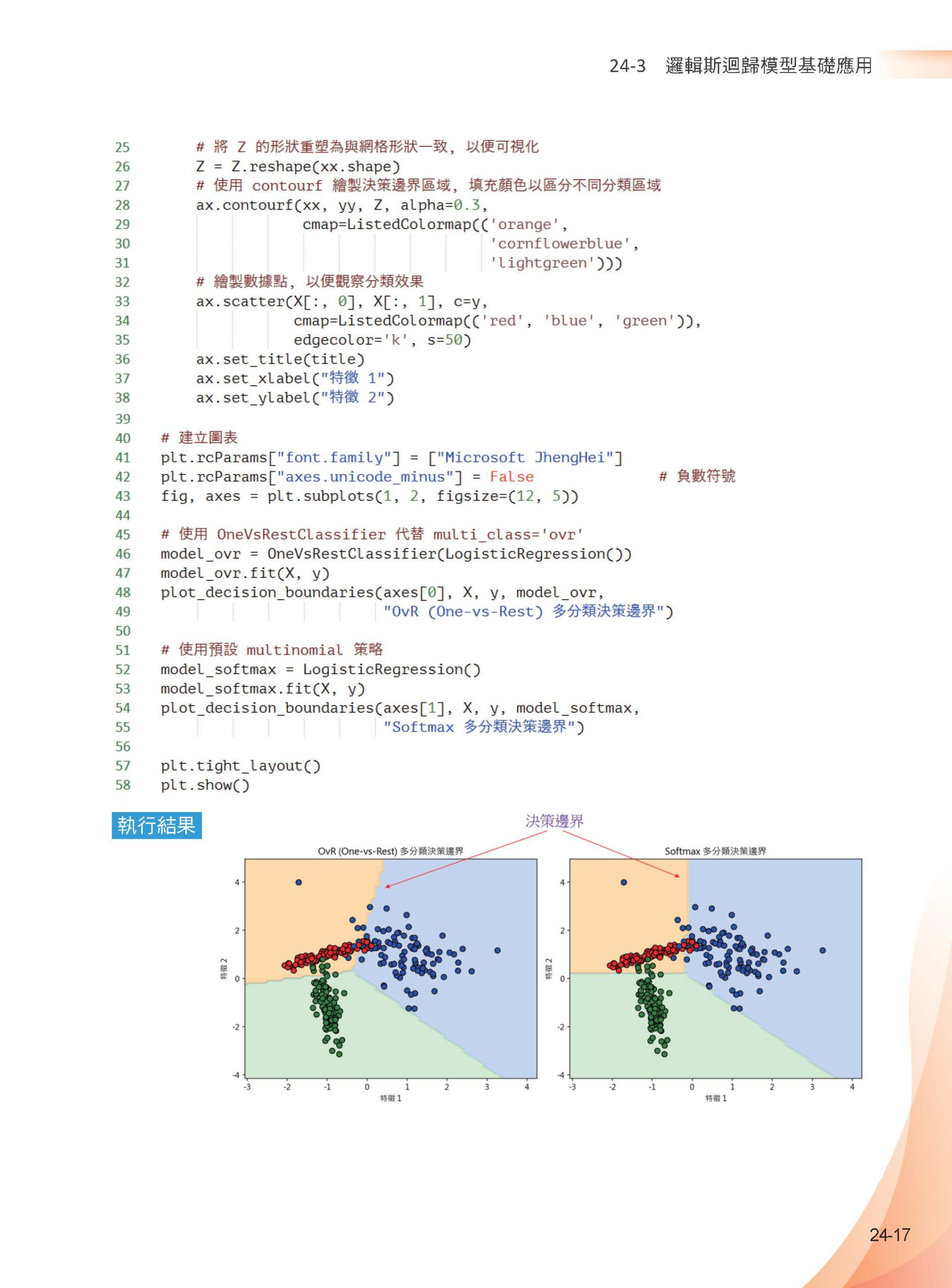
▌第24章 邏輯斯迴歸 - 信用卡/ 葡萄酒/ 糖尿病 24-1 淺談線性迴歸的問題 24-2 邏輯斯迴歸觀念回顧 24-2-1 基礎觀念複習 24-2-2 應用邏輯斯函數 24-2-3 線性迴歸與邏輯斯迴歸的差異 24-3 邏輯斯迴歸模型基礎應用 24-3-1 語法基礎 24-3-2 挽救可能流失的客戶 24-3-3 多分類演算法解說 24-4 台灣信用卡持卡人數據集 24-4-1 認識UCI_Credit_Card.csv 數據 24-4-2 挑選最重要的特徵 24-4-3 用最相關的2 個特徵設計邏輯斯迴歸模型 24-4-4 使用全部的特徵設計邏輯斯迴歸模型 24-5 葡萄酒數據 24-5-1 認識葡萄酒數據 24-5-2 使用邏輯斯迴歸演算法執行葡萄酒分類 24-6 糖尿病數據 24-6-1 認識糖尿病數據 24-6-2 缺失值檢查與處理 24-6-3 用直方圖了解特徵分佈 24-6-3 用箱形圖了解異常值 24-6-4 用所有特徵值做糖尿病患者預估 24-6-5 繪製皮爾遜相關係數熱力圖 24-6-6 用最相關的皮爾遜相關係數做糖尿病預估
▌第25章 決策樹 – 葡萄酒/ 鐵達尼號/Telco/Retail 25-1 決策樹基本觀念 25-1-1 決策樹應用在分類問題 25-1-2 分類問題的決策樹數學分割原理 25-1-3 決策樹應用在迴歸問題 25-1-4 決策樹在迴歸問題的數學原理 25-2 從天氣數據認識決策樹設計流程- 分類應用 25-2-1 建立決策樹模型物件 25-2-2 天氣數據實例 25-3 葡萄酒數據 - 分類應用 25-3-1 預設條件處理葡萄酒數據 25-3-2 進一步認識決策樹深度 25-3-3 繪製決策樹圖 25-4 鐵達尼號- 分類應用 25-4-1 認識鐵達尼號數據集 25-4-2 決策樹設計鐵達尼號生存預測 25-4-3 交叉分析 25-5 Telco 電信公司- 分類應用 25-5-1 認識WA_Fn-UseC_-Telco-Customer-Churn.csv 數據 25-5-2 決策樹數據分析 25-5-3 了解特徵對模型的重要性 25-5-4 交叉驗證 - 決策樹最佳深度調整 25-6 Retail Data Analytics - 迴歸應用 25-6-1 用簡單的數據預估房價 25-6-2 Retail Data Analytics 數據
▌第26章 隨機森林 – 波士頓房價/ 鐵達尼號/Telco/ 收入分析 26-1 隨機森林基本觀念 26-1-1 Bagging 技術 26-1-2 特徵隨機選擇 26-1-3 隨機森林的應用 26-1-4 隨機森林的優缺點 26-2 波士頓房價 - 迴歸應用 26-2-1 隨機森林RandomForestRegressor( )迴歸函數 26-2-2 隨機森林 - 波士頓房價應用 26-2-3 RandomForestRegressor 的屬性 feature_importances_ 26-3 鐵達尼號 – 分類應用 26-4 Telco 客戶流失 – 分類應用 26-5 美國成年人收入分析 – 分類應用 26-5-1 認識adult.csv 數據 26-5-2 使用決策樹處理年收入預估 26-5-3 決策樹特徵重要性 26-5-4 使用隨機森林處理adult.csv 檔案
▌第27章 KNN 演算法 – 鳶尾花/ 小行星撞地球 27-1 KNN 演算法基礎觀念 27-1-1 基礎觀念 27-1-2 K 值的影響 27-2 電影推薦/ 足球射門 - 分類應用 27-2-1 認識語法與簡單實例 27-2-2 電影推薦 27-2-3 足球射門是否進球 27-2-4 交叉驗證 27-2-5 繪製分類的決策邊界(Decision Boundary) 27-2-5 多分類模型的準確率分析 27-3 房價計算/ 選舉準備香腸 – 迴歸應用 27-3-1 認識語法與簡單實例 27-3-2 房價計算 27-3-3 選舉造勢與準備烤香腸數量 27-3-4 KNN 模型的迴歸線分析 27-4 鳶尾花數據 - 分類應用 27-4-1 認識鳶尾花數據集 27-4-2 輸出數據集 27-4-3 用Pandas 顯示鳶尾花數據 27-4-4 映射標籤 27-4-5 繪製特徵變數的散點圖 27-4-6 使用 KNN 演算法進行鳶尾花數據集的分類預測 27-4-7 繪製鳶尾花的決策邊界 27-4-8 計算最優的k 值 27-4-9 交叉驗證 27-5 小行星撞地球 – 分類應用 27-5-1 認識NASA:Asteroids Classification 27-5-2 數據預處理 27-5-3 預測小行星撞地球的準確率
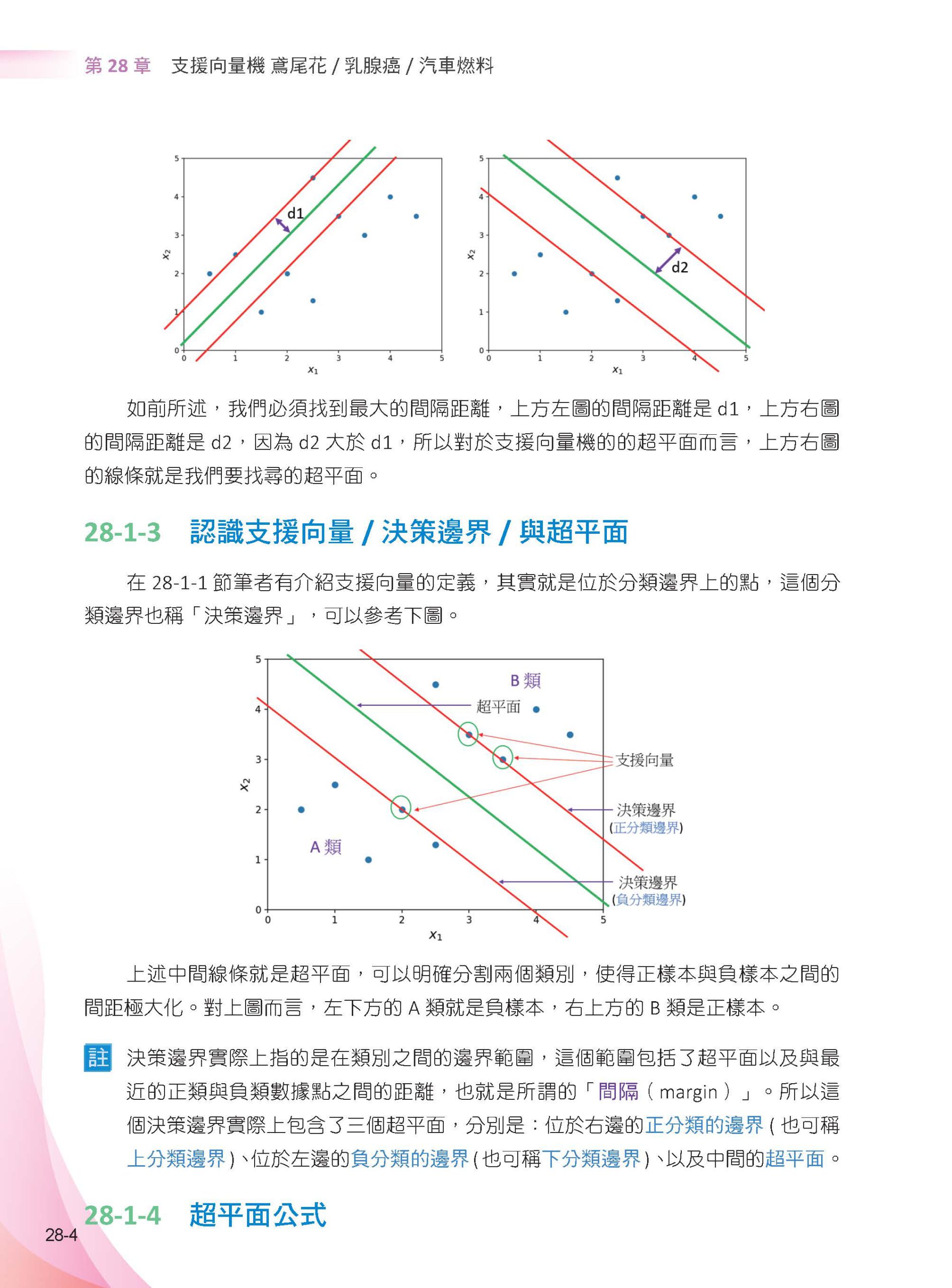
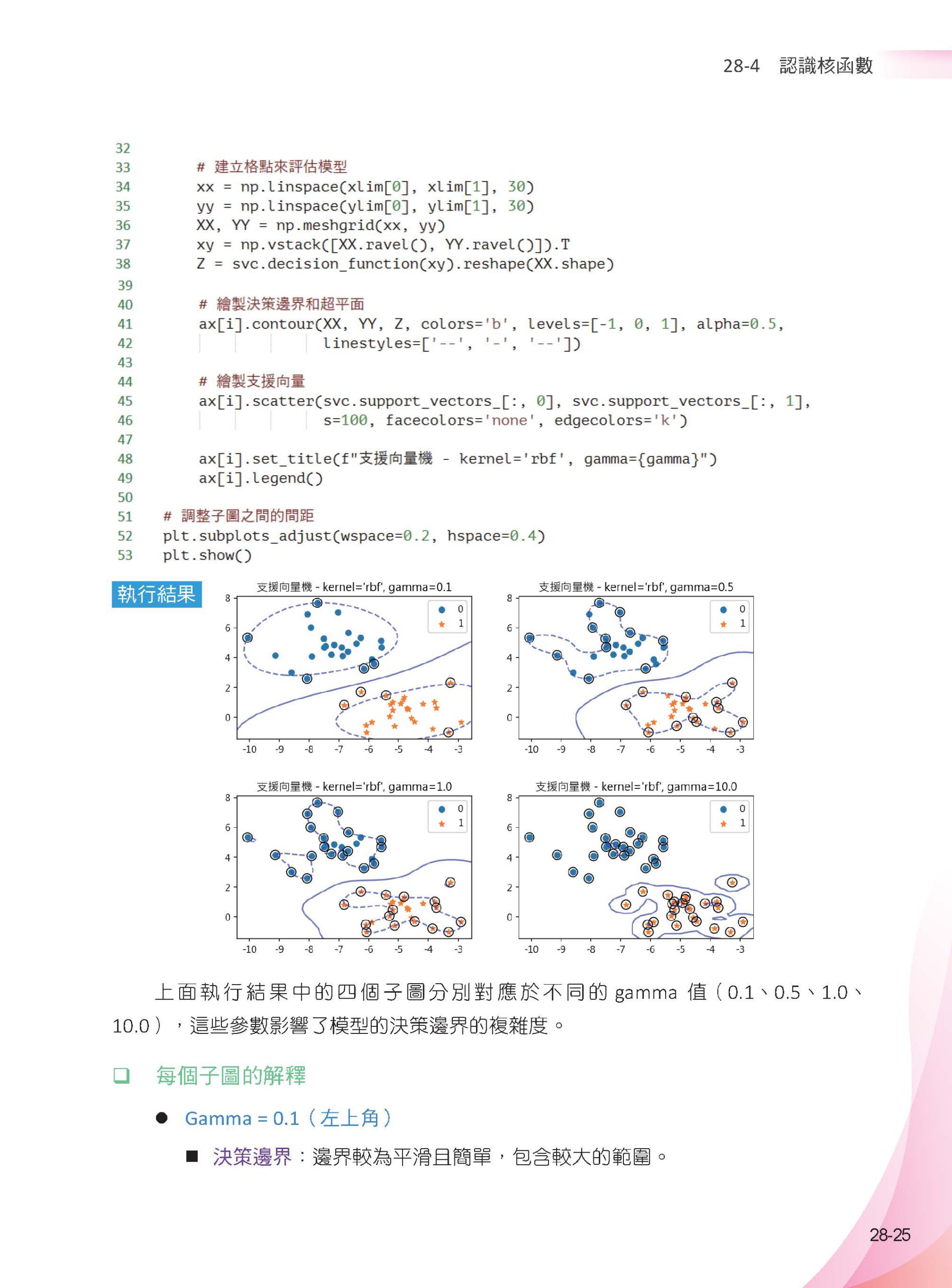
▌第28章 支援向量機 – 鳶尾花/ 乳癌/ 汽車燃料 28-1 支援向量機分類應用的基礎觀念 28-1-1 分類應用的基礎觀念 28-1-2 最大區間的分割 28-1-3 認識支援向量/ 決策邊界/ 與超平面 28-1-4 超平面公式 28-2 支援向量機 - 分類應用的基礎實例 28-2-1 繪製10 個數據點 28-2-2 支援向量機的語法說明 28-2-3 推導超平面的斜率 28-2-4 繪製超平面和決策邊界 28-2-5 數據分類 28-2-6 decision_function() 28-3 從2 維到3 維的超平面 28-3-1 增加數據維度 28-3-2 計算3 維的超平面公式與係數 28-3-3 繪製3 維的超平面 28-4 認識核函數 28-4-1 linear 28-4-2 徑向基函數(Radial Basic Function) - RBF 28-4-3 多項式函數(Polynomail function) - poly 28-4-4 支援向量機的方法 28-5 鳶尾花數據 - 分類應用 28-6 乳腺癌數據 - 分類應用 28-6-1 認識數據 28-6-2 線性支援向量機預測乳腺癌數據 28-6-3 不同核函數應用在乳腺癌數據 28-7 支援向量機 – 迴歸應用的基礎實例 28-7-1 SVR() 語法說明 28-7-2 簡單數據應用 28-7-3 電視購物廣告效益分析 28-8 汽車燃耗效率數據集 - 迴歸分析 28-8-1 認識汽車燃耗效率(MPG) 數據集 28-8-2 使用SVR() 預測汽車燃料數據
▌第29章 單純貝式分類 – 垃圾郵件/ 新聞分類/ 電影評論 29-1 單純貝式分類原理 29-1-1 公式說明 29-1-2 簡單實例說起 29-1-3 拉普拉斯平滑修正 29-2 詞頻向量模組 - CountVerctorizer 29-3 多項式單純貝式模組 - MultinomialNB 29-3-1 語法觀念 29-3-2 文章分類實作 29-3-3 垃圾郵件分類 29-4 垃圾郵件分類 – Spambase 數據集 29-4-1 認識垃圾郵件數據集Spambase 29-4-2 垃圾郵件分類預測 29-5 新聞郵件分類 – 新聞數據集20newsgroups 29-5-1 認識新聞數據集20newsgroups 29-5-2 新聞分類預測 29-5-3 TfidfVectorizer 模組 - 文件事前處理TF-IDF 29-5-4 輸入文件做新聞分類 29-6 情感分析 – 電影評論IMDB Dataset分析 29-6-1 基礎觀念實例 29-6-2 電影評論IMDB Dataset 數據集 29-7 單純貝式分類於中文的應用 29-7-1 將中文字串應用在CountVectorizer模組 29-7-2 jieba - 結巴 29-7-3 jieba 與CountVectorizer 組合應用 29-7-4 簡單中文情感分析程式 29-8 今日頭條數據集 29-8-1 認識數據集 29-8-2 今日頭條數據集實作
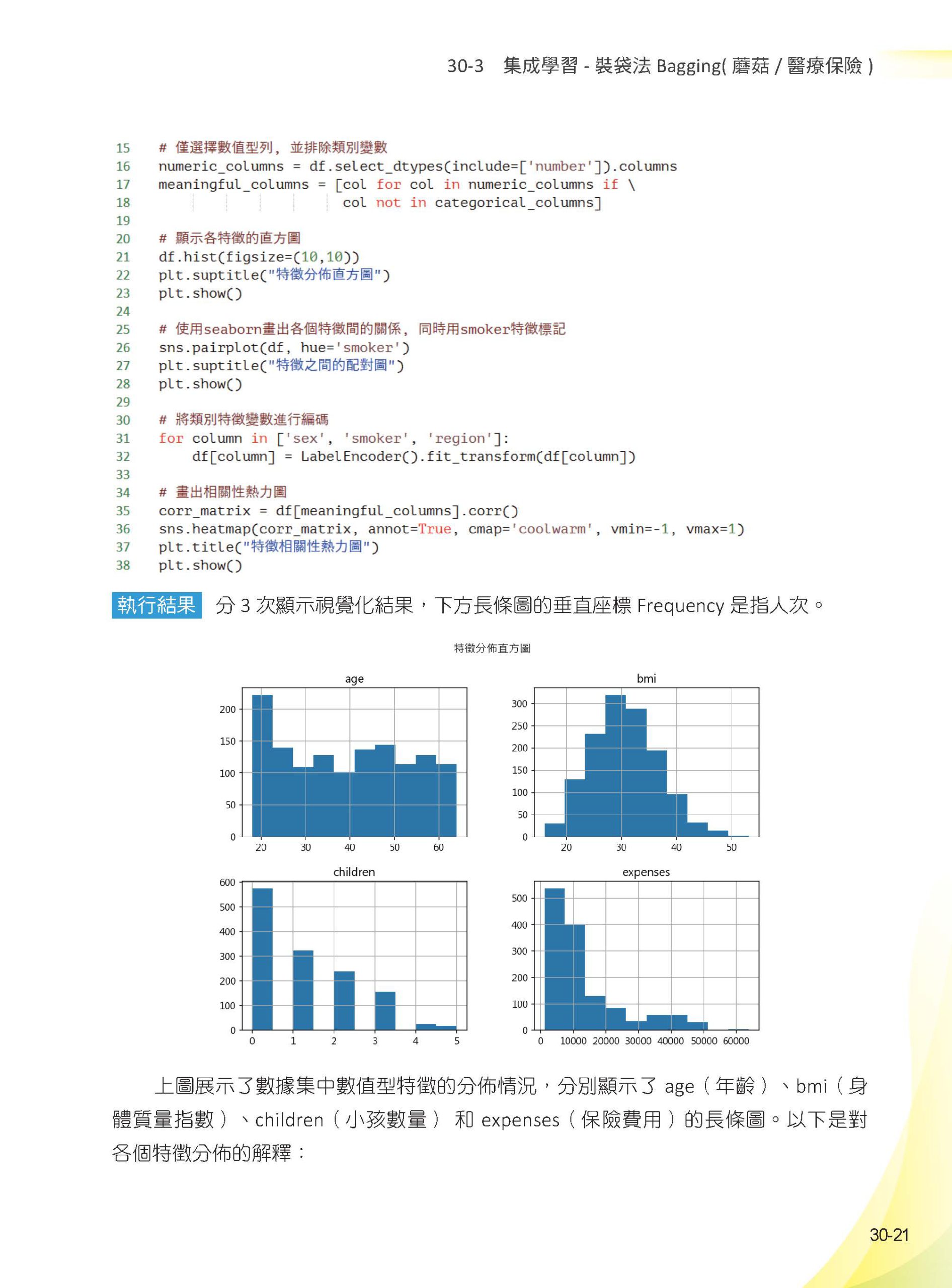
▌第30章 集成機器學習 – 蘑菇/ 醫療保險/ 玻璃/ 加州房價 30-1 集成學習的基本觀念 30-1-1 基本觀念 30-1-2 集成學習效果評估 30-2 集成學習 - 投票法Voting( 鳶尾花/ 波士頓房價) 30-2-1 投票法 - 分類應用 30-2-2 投票法 - 迴歸應用 30-3 集成學習 - 裝袋法Bagging( 蘑菇/ 醫療保險) 30-3-1 裝袋法 – 分類應用語法說明 30-3-2 蘑菇數據分類應用 30-3-3 裝袋法 – 迴歸應用語法說明 30-3-4 醫療保險數據迴歸應用 30-4 集成學習 - 適應性提升法AdaBoost 30-4-1 AdaBoost 提升法 - 分類應用語法說明 30-4-2 AdaBoost 提升法 - 迴歸應用語法說明 30-5 集成學習 - 梯度提升法Gradient Boosting 30-5-1 Gradient Boosting - 分類應用語法說明 30-5-2 玻璃數據集分類的應用 30-5-3 Gradient Boosting – 迴歸應用語法說明 30-5-4 加州房價數據集迴歸應用 30-6 集成學習 – 堆疊法Stacking 30-6-1 StackingClassifier - 分類應用語法說明 30-6-2 RidgeCV( ) 30-6-3 StackingRegressor – 迴歸應用語法說明
▌第31章 K-means 分群 – 購物中心消費/ 葡萄酒評價 31-1 認識無監督學習 31-1-1 回顧監督學習數據 31-1-2 無監督學習數據 31-1-3 無監督學習與監督學習的差異 31-1-4 無監督學習的應用 31-2 K-means 演算法 31-2-1 演算法基礎 31-2-2 Python 硬功夫程式實作 31-3 Scikit-learn 的KMeans 模組 31-3-1 KMeans 語法 31-3-2 分群的基礎實例 31-3-3 數據分群的簡單實例 31-4 評估分群的效能 31-4-1 群內平方和(WCSS) 31-4-2 輪廓係數(Silhouette Coefficient) 31-4-3 調整蘭德係數(Rand Index, ARI) 31-5 最佳群集數量 31-5-1 肘點法(Elbow Method) 31-5-2 輪廓分析(Silhouette Analysis) 31-6 消費分析 - 購物中心客戶消費數據 31-6-1 認識Mall Customer Segmentation Data 31-6-2 收入與消費分群 31-6-3 依據性別分析「年收入 vs 消費力」 31-6-4 依據年齡層分析「年收入 vs 消費力」 31-7 價格 vs 評價 - 葡萄酒Wine Reviews 31-7-1 認識Wine Reviews 數據
▌第32章 PCA 主成份分析 – 手寫數字/ 人臉數據 32-1 PCA 基本觀念 32-1-1 基本觀念 32-1-2 PCA 方法與基礎數據實作 32-1-3 數據白化whiten 32-2 鳶尾花數據的PCA 應用 32-2-1 鳶尾花數據降維 32-2-2 SVC 與PCA 在鳶尾花的應用 32-2-3 PCA 主成份與原始特徵的分析 32-3 數字辨識 - 手寫數字digits dataset 32-3-1 認識手寫數字數據集digits dataset 32-3-2 決策樹與隨機森林辨識手寫數字 32-3-3 PCA 與手寫數字整合應用 32-4 人臉辨識 – 人臉數據Labeled Faces in the Wild 32-4-1 認識人臉數據LFW 32-4-2 人臉辨識預測 32-4-3 加上PCA 的人臉辨識
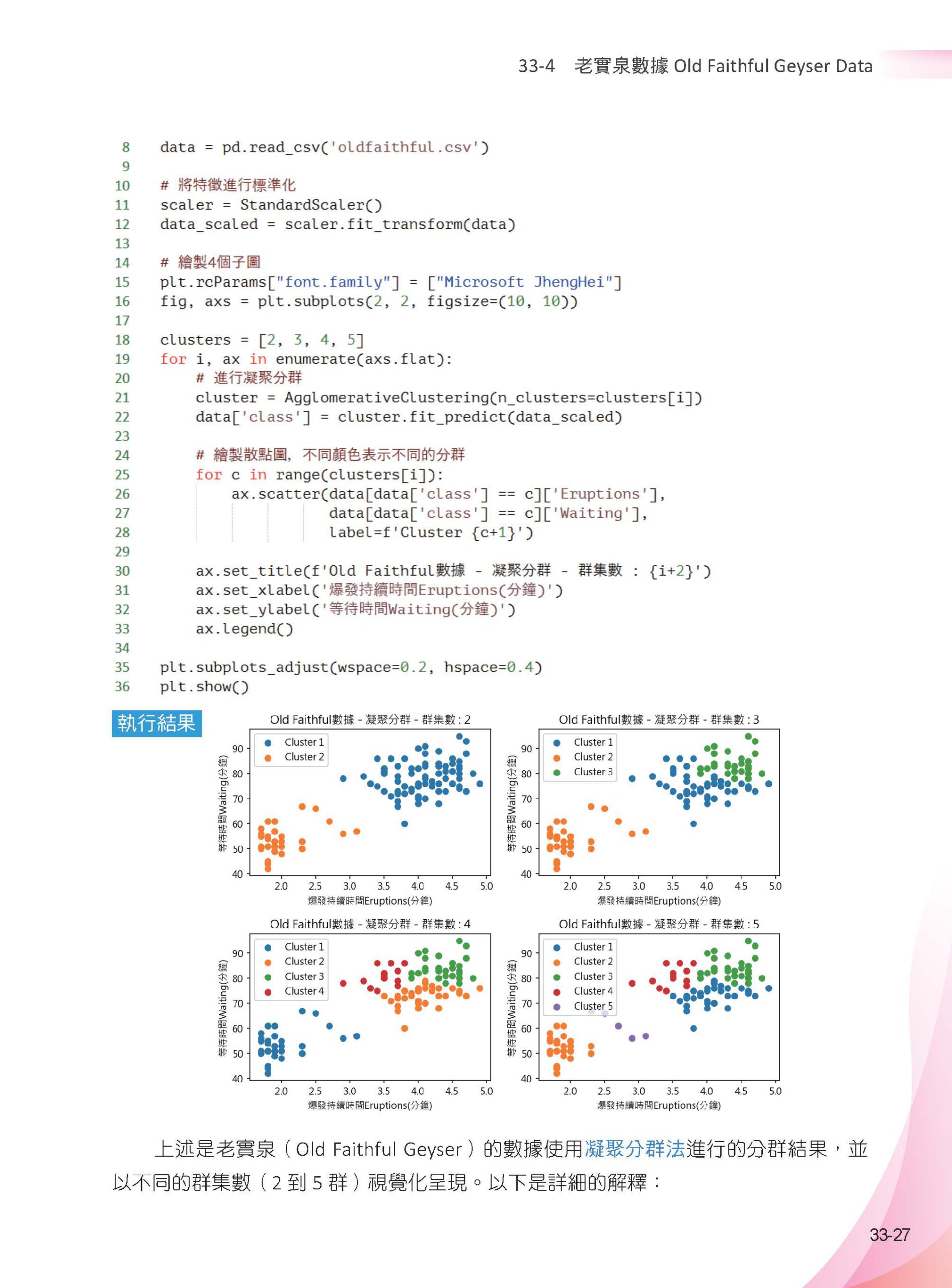
▌第33章 階層式分群 – 小麥數據/ 老實泉 33-1 認識階層式分群 33-2 凝聚型(Agglomerative) 分群 33-2-1 凝聚型分群定義 33-2-2 簡單實例解說linkage( ) 方法 33-2-3 單鏈接法(Single Linkage) 說明 33-2-4 簡單實例解說分群方法 33-2-5 分群方法ward( ) 33-2-6 分群數量的方法 33-2-7 凝聚型分群AgglomerativeClustering 33-3 小麥數據集Seeds dataset 33-3-1 認識數據集Seeds dataset 33-3-2 凝聚型分群應用在Seeds dataset 33-4 老實泉數據Old Faithful Geyser Data 33-4-1 認識老實泉數據集 33-4-2 繪製樹狀圖 33-4-3 凝聚型分群應用在老實泉數據
▌第34章 DBSCAN 演算法 – 購物中心客戶分析 34-1 DBSCAN 演算法 34-1-1 DBSCAN 演算法的參數觀念 34-1-2 點的定義 34-1-3 演算法的步驟 34-2 scikit-learn 的DBSCAN 模組 34-2-1 DBSCAN 語法 34-2-2 DBSCAN 演算法基礎實例 34-3 消費分析 - 購物中心客戶消費數據
附錄A 函數與方法索引表 |
序
|