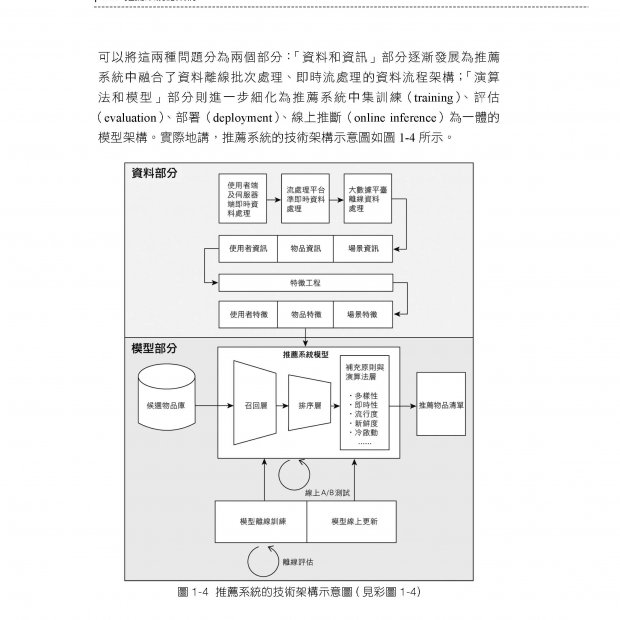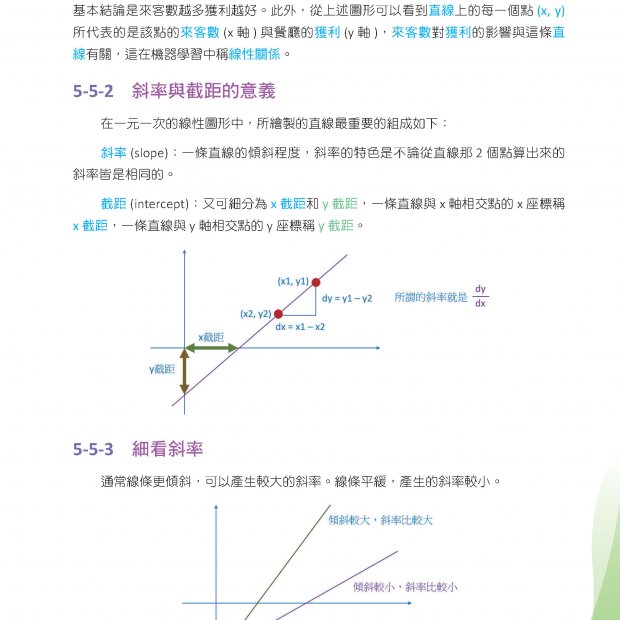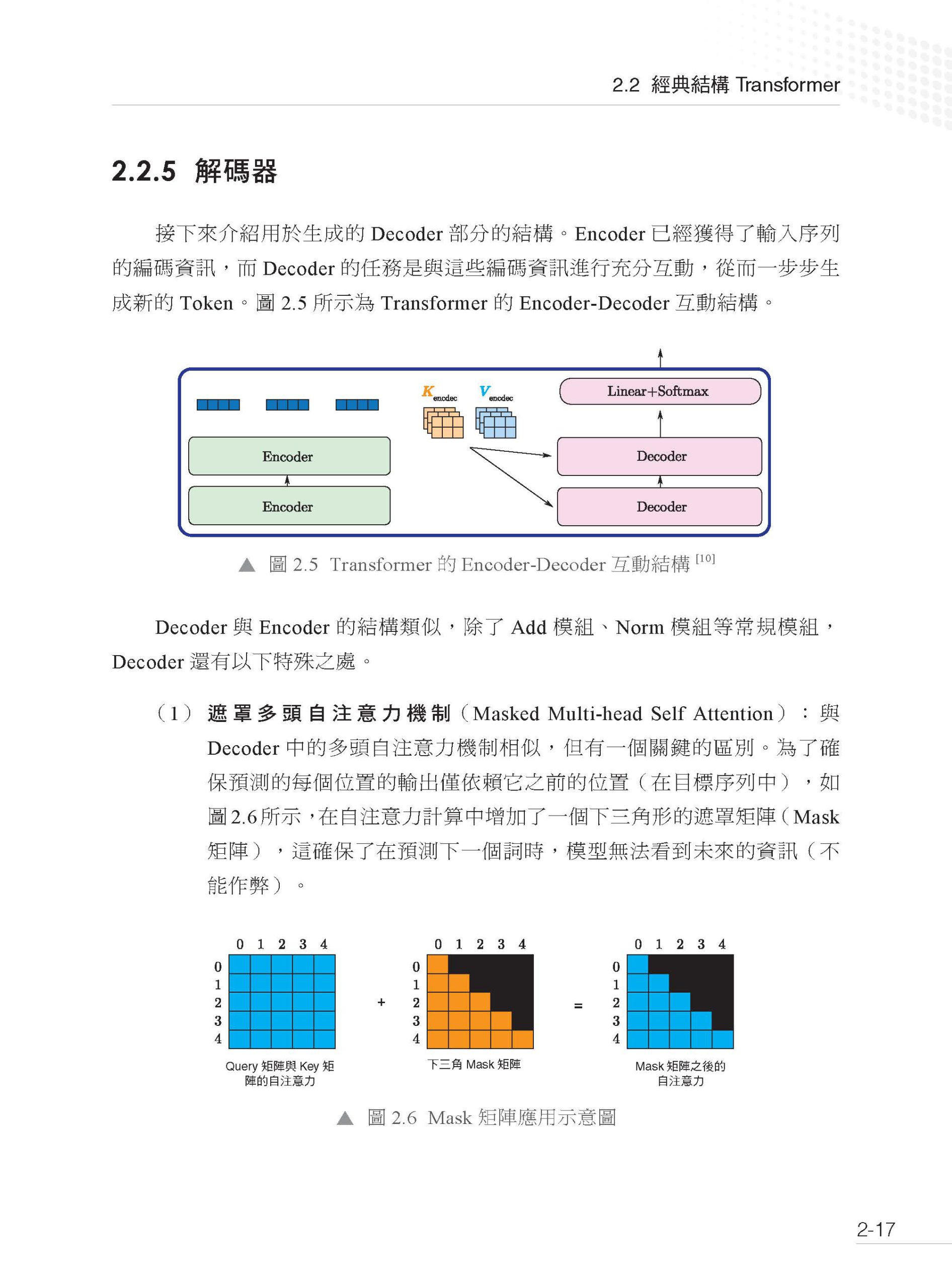
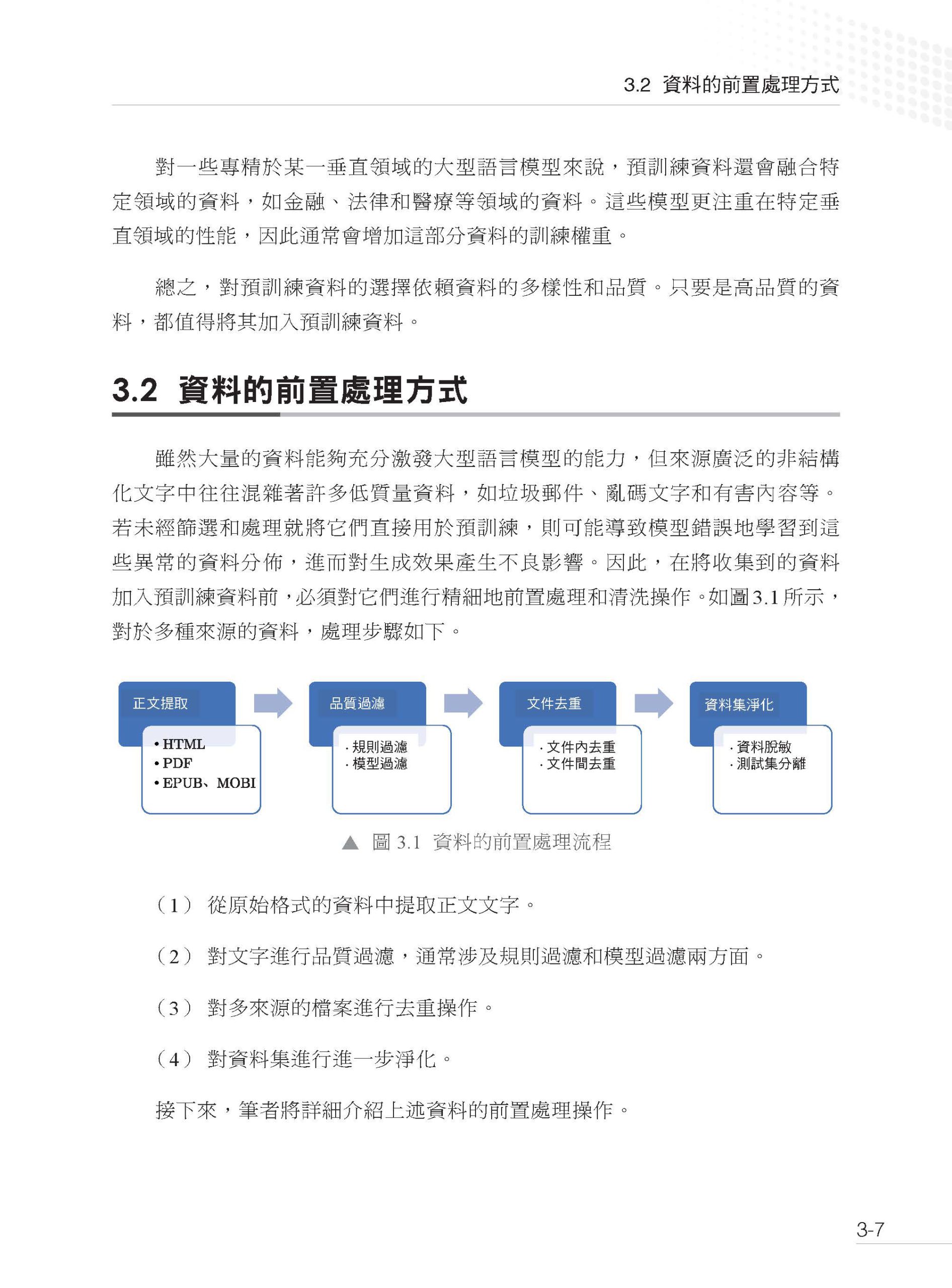



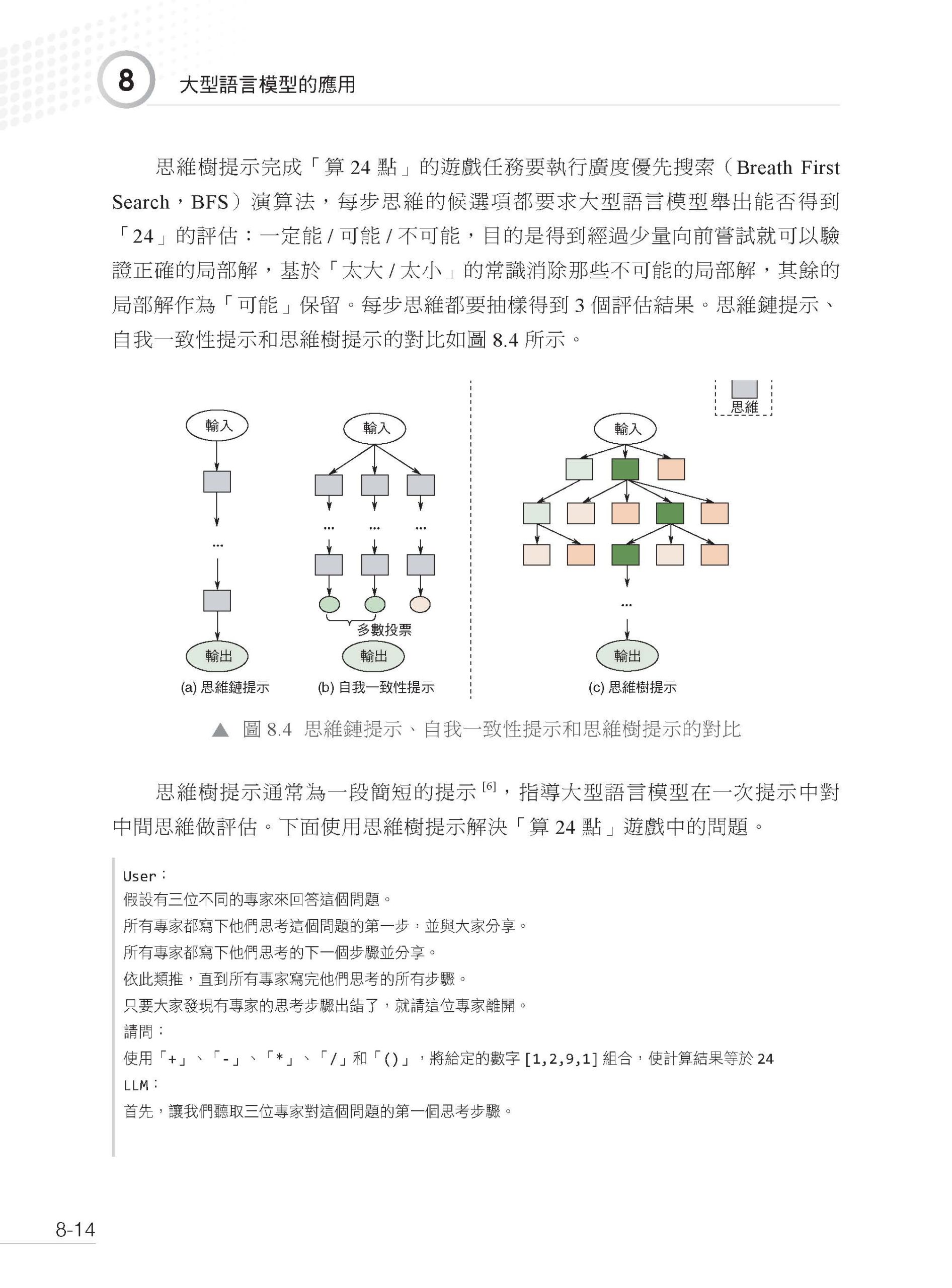
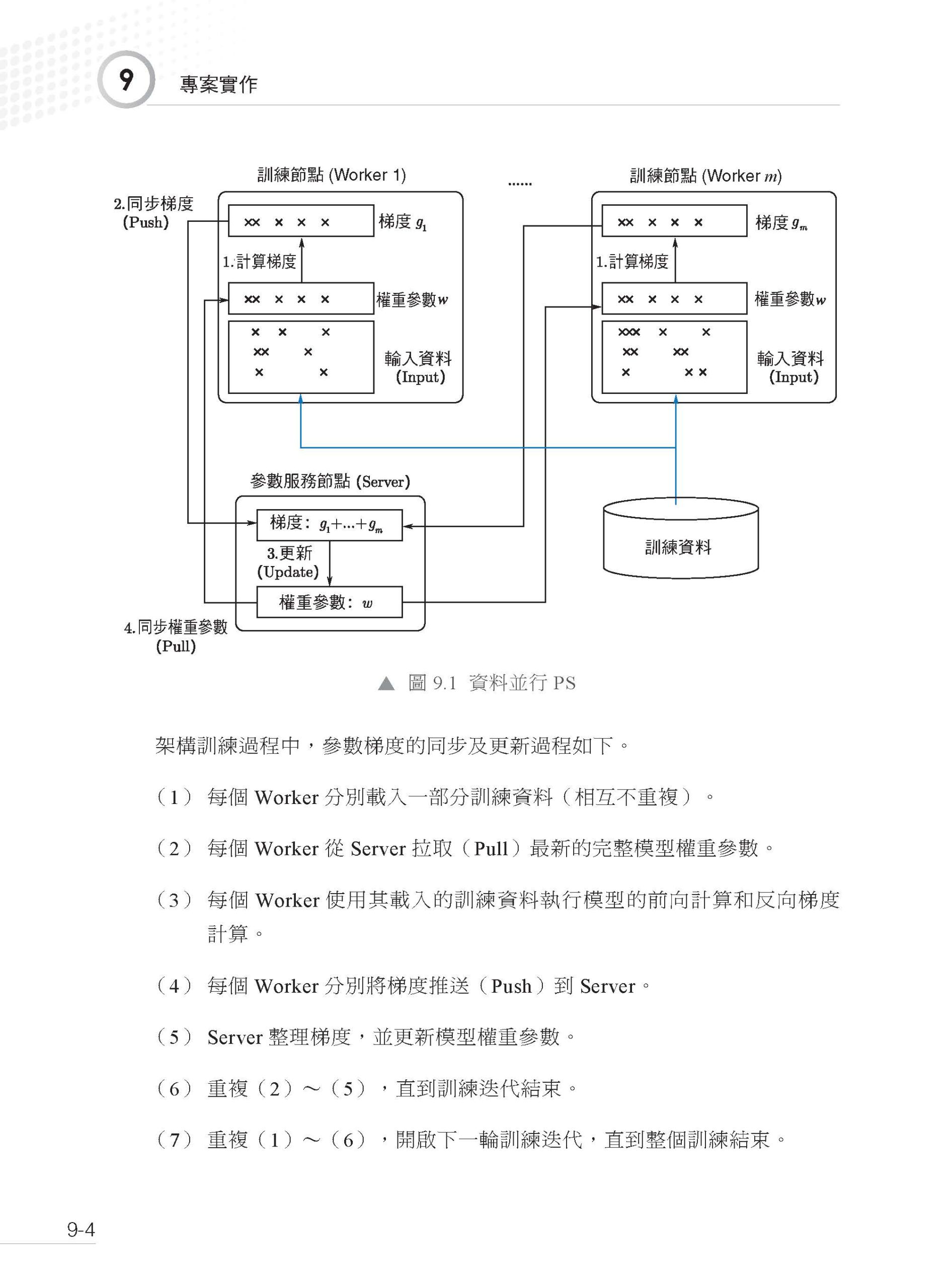
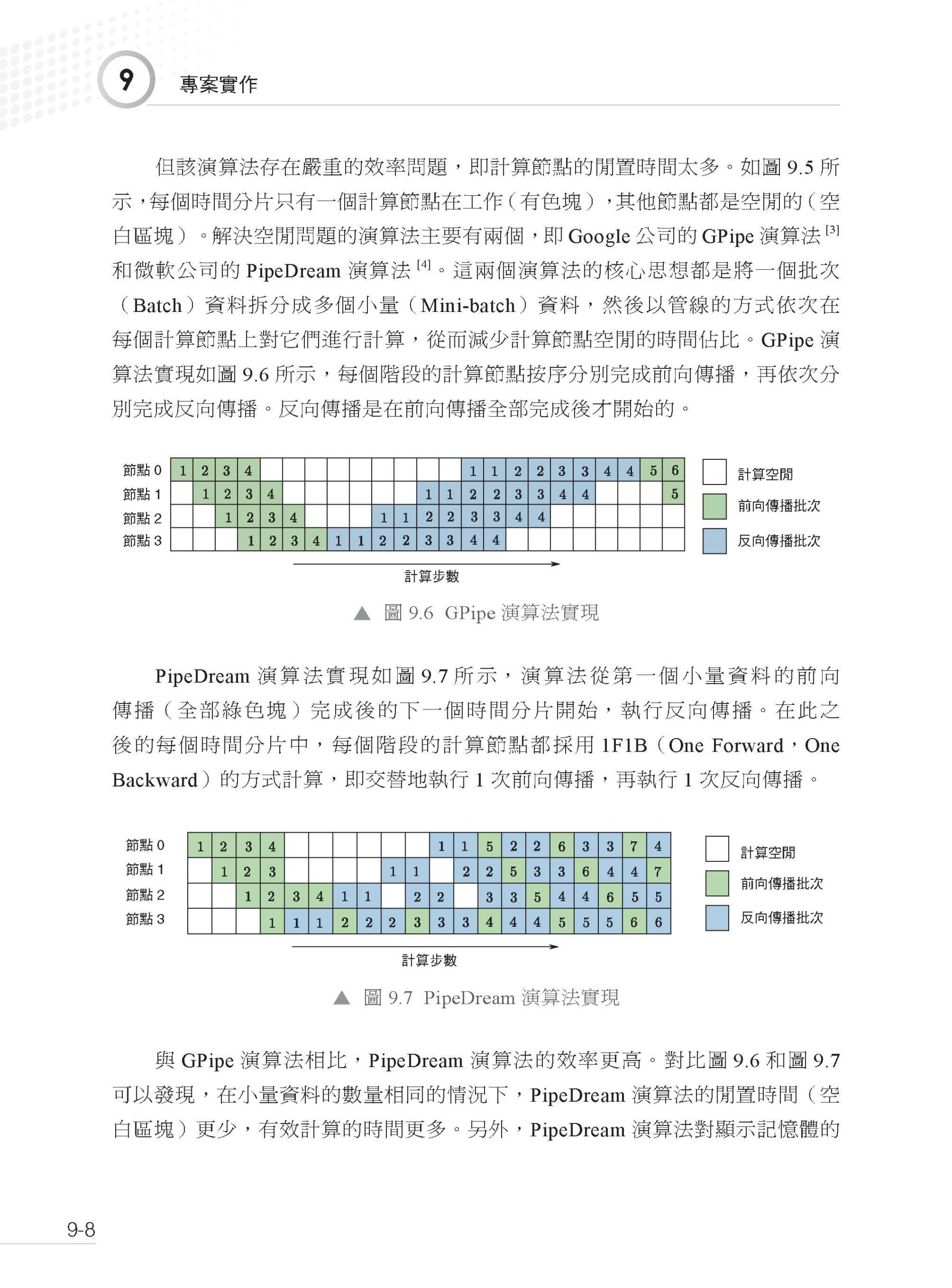
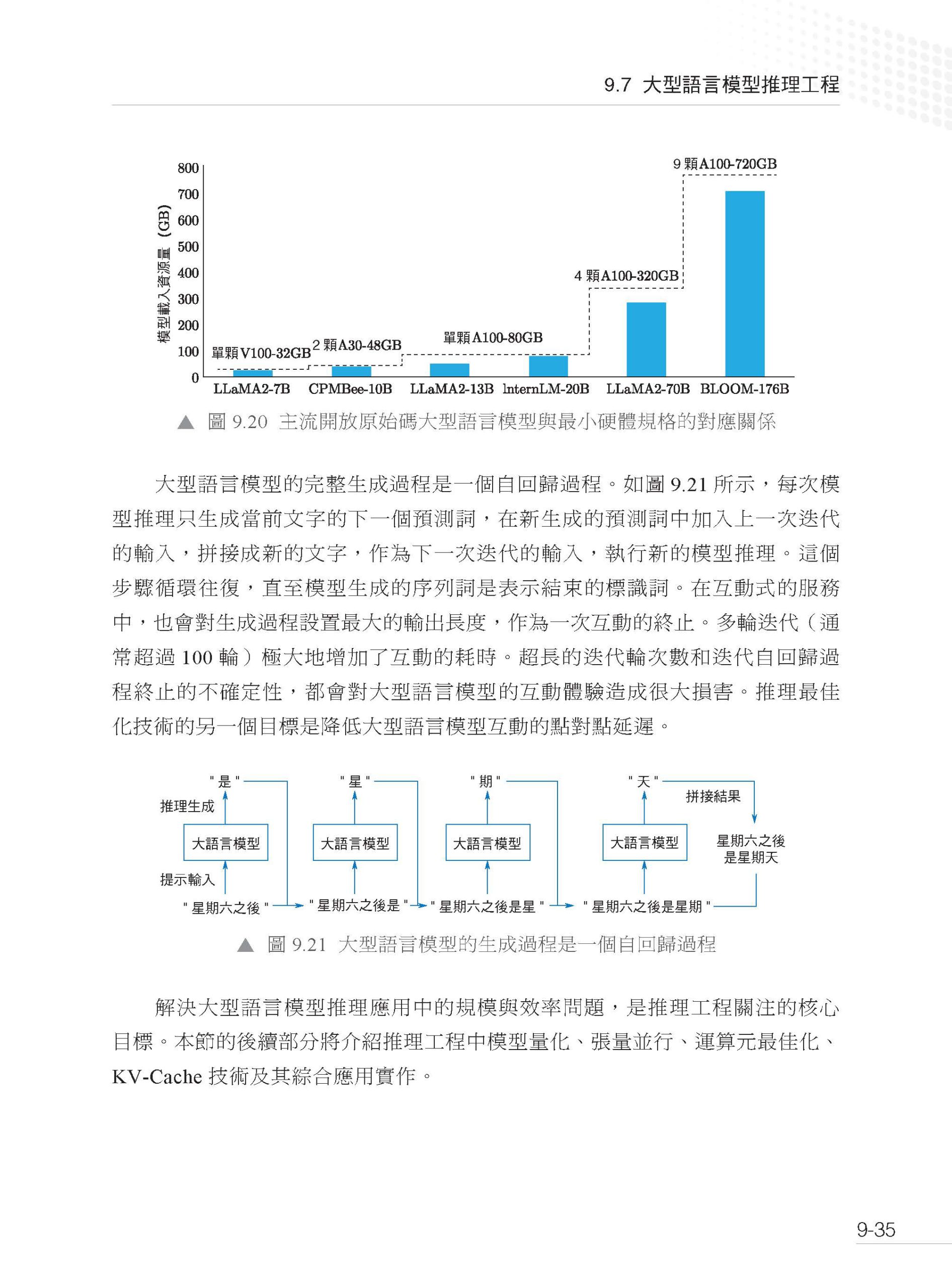

描述
內容簡介
| ☆大型語言模型的白話文介紹
☆大型語言模型技術有什麼? ☆預訓練資料的建立(語料庫) ☆大型語言模型從頭來 – 預訓練 ☆挖掘大型語言模型潛能:有監督微調 ☆大型語言模型強化學習對齊 ☆大型語言模型的評測標準 ☆大型語言模型的重要應用 ☆動手做大型語言模型 ☆自己訓練一個7B的大型語言模型
本書涵蓋大型語言模型的全貌,從基礎概念到實際應用。第一章介紹大型語言模型的基本概念。第二章深入解析其基礎技術,包括自然語言資料表示、Transformer架構以及BERT和GPT等預訓練模型,並以InstructGPT和LLaMA系列為例展示實用成果。第三章探討預訓練資料的類別、來源和處理方式。第四章詳細介紹大型語言模型的預訓練過程,包括不同架構和訓練策略。第五章解釋有監督微調的定義、用途和應用場景,以及微調資料建構和技巧。第六章介紹強化學習的基礎知識及在大型語言模型中的應用,特別是基於人類回饋的強化學習(RLHF),並展望其未來發展。第七章介紹大型語言模型的評測方法,包括微調後的對話能力和安全性評測,並探討通用人工智慧的評價。第八章展示提示詞技術在引導大型語言模型方面的應用,介紹搜索增強生成技術和推理協作技術,使模型能逐步分解並解決問題。第九章探討從訓練到任務完成的專案最佳化技術和實作案例,以提高模型的效率和可擴充性。第十章提供微調大型語言模型的關鍵步驟和程式範例,便於實際應用。 |
作者簡介
|
目錄
| 第1 章 解鎖大型語言模型
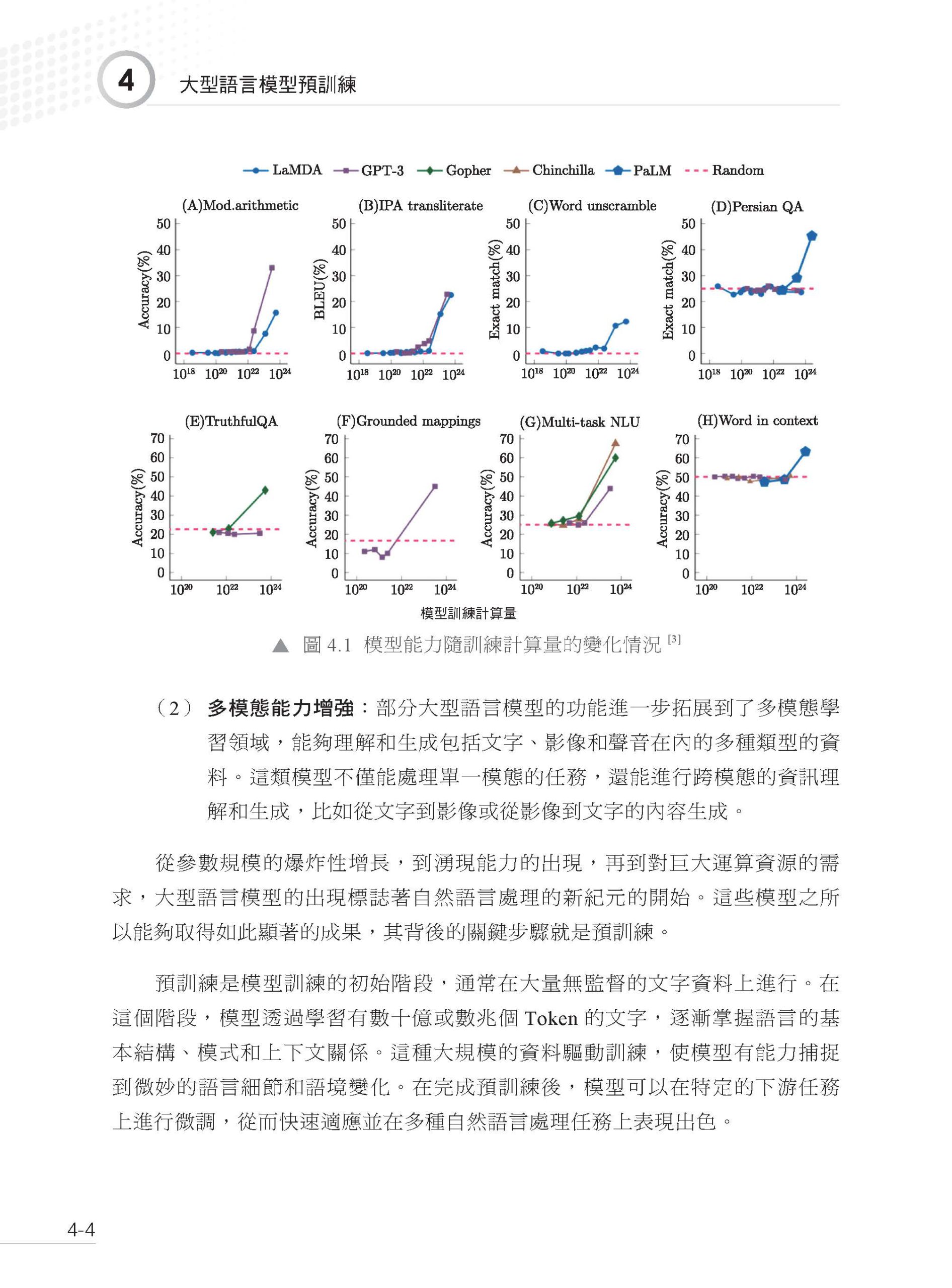
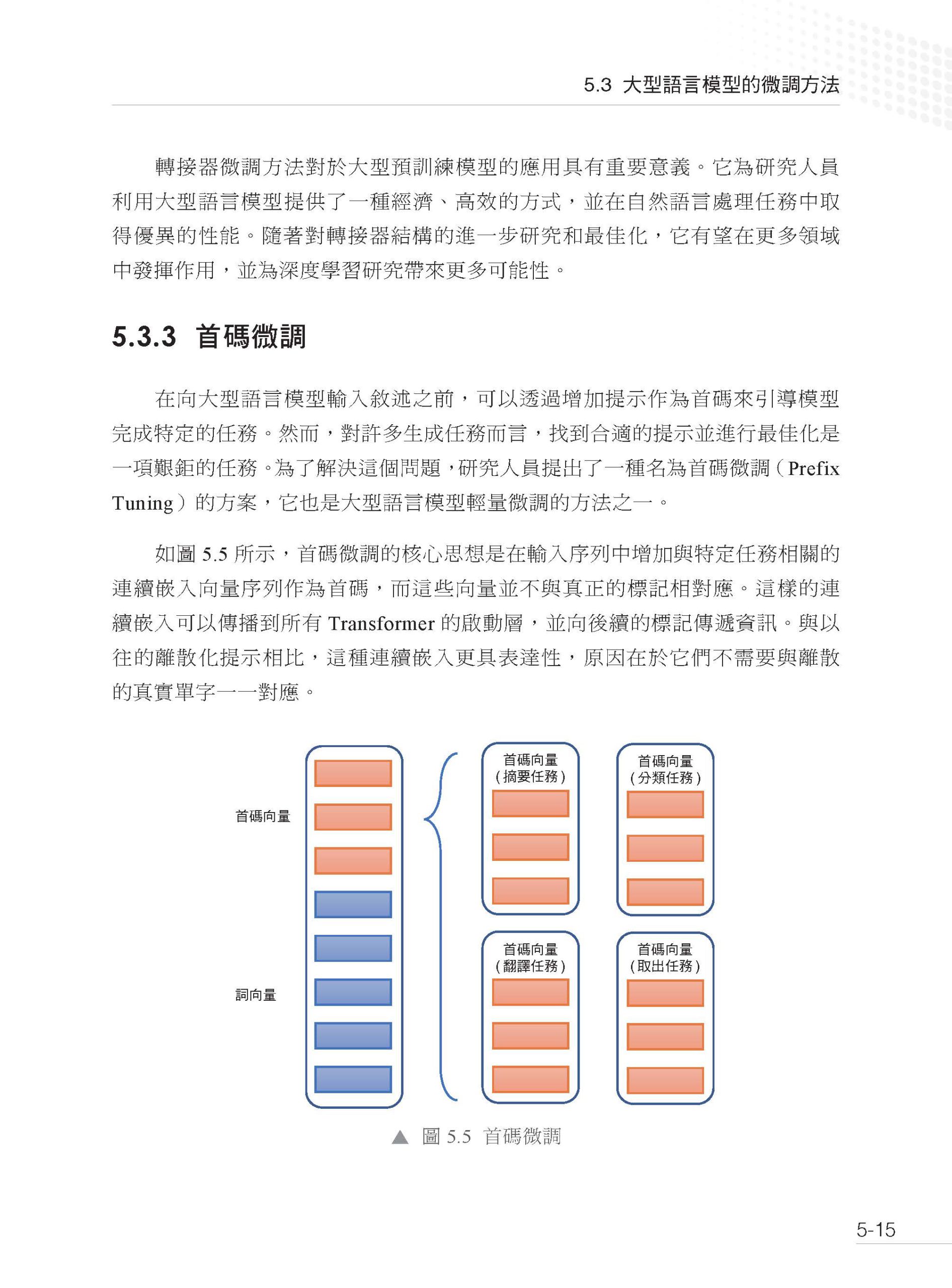
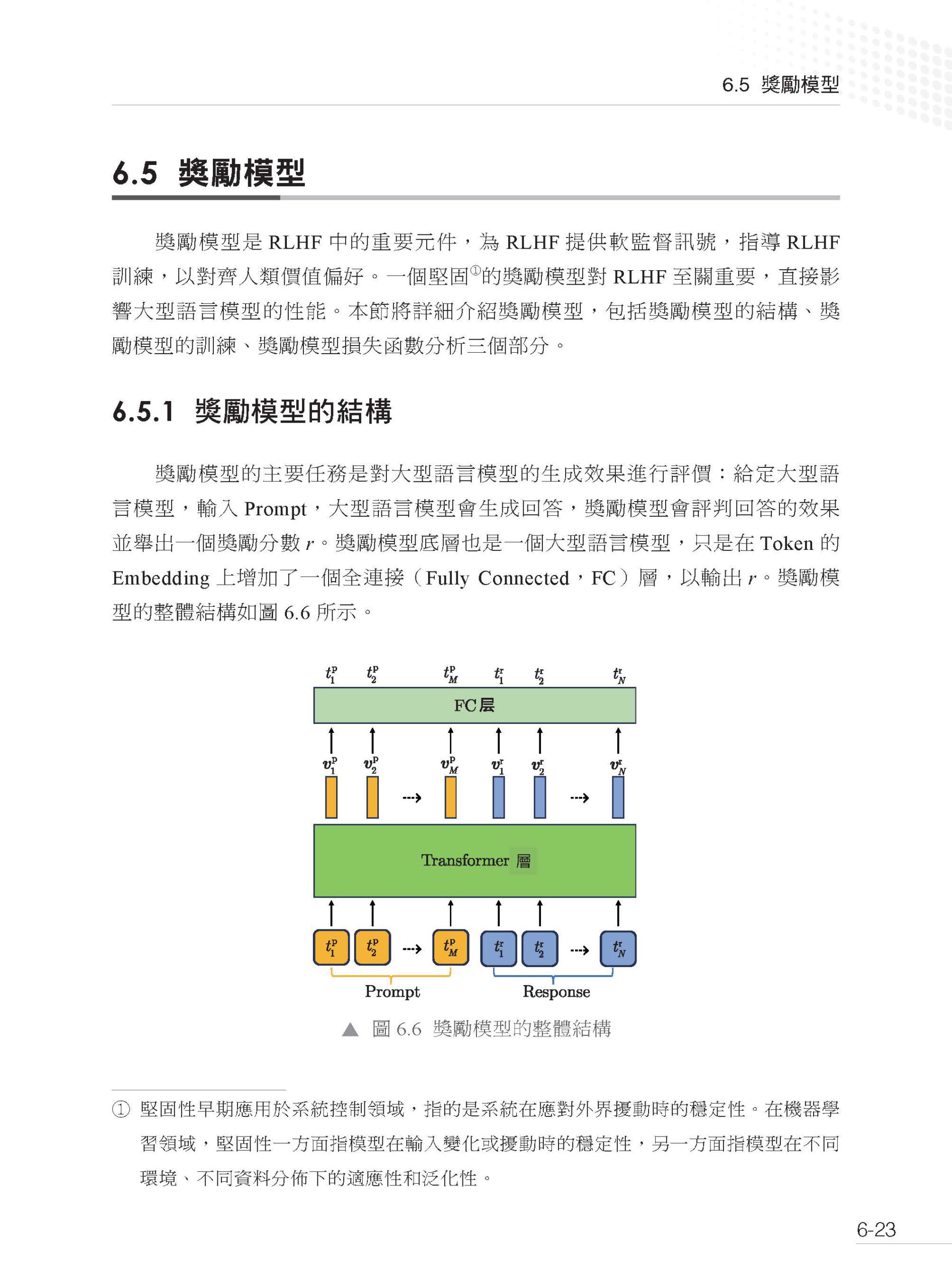
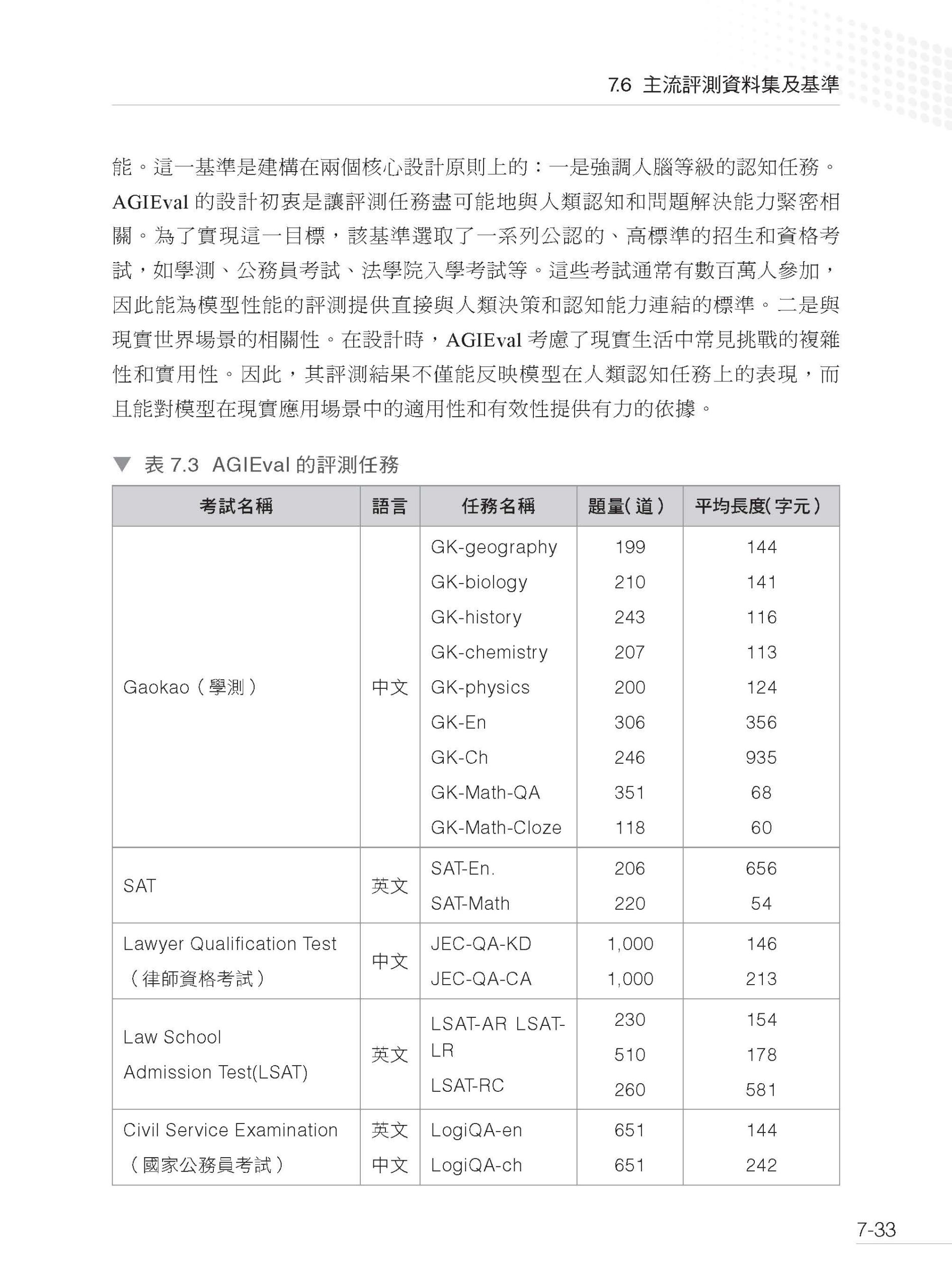
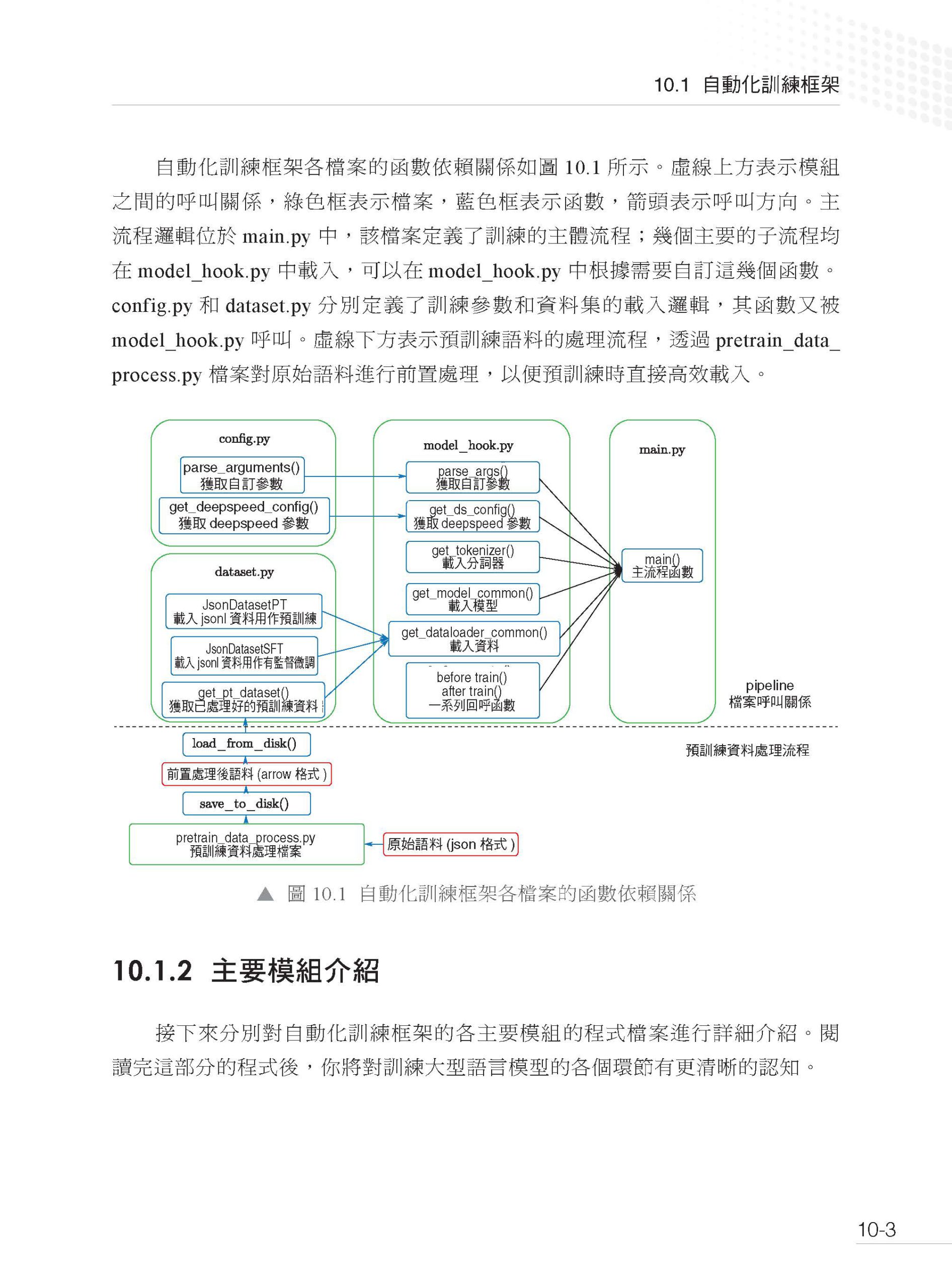
1.1 什麼是大型語言模型 1.2 語言模型的發展 1.3 GPT 系列模型的發展 1.4 大型語言模型的關鍵技術 1.5 大型語言模型的湧現能力 1.6 大型語言模型的推理能力 1.7 大型語言模型的縮放定律 參考文獻 第2 章 大型語言模型基礎技術 2.1 語言表示介紹 2.1.1 詞表示技術 2.1.2 分詞技術 2.2 經典結構Transformer 2.2.1 輸入模組 2.2.2 多頭自注意力模組 2.2.3 殘差連接與層歸一化 2.2.4 前饋神經網路 2.2.5 解碼器 2.3 預訓練語言模型 2.3.1 Decoder 的代表:GPT 系列 2.3.2 Encoder 的代表:BERT 2.4 初探大型語言模型 2.4.1 InstructGPT 2.4.2 LLaMA 系列 參考文獻 第3 章 預訓練資料建構 3.1 資料的常見類別及其來源 3.1.1 網頁資料 3.1.2 書籍資料 3.1.3 百科資料 3.1.4 程式資料 3.1.5 其他資料 3.2 資料的前置處理方式 3.2.1 正文提取 3.2.2 品質過濾 3.2.3 檔案去重 3.2.4 資料集淨化 3.3 常用資料集的完整建構方式 3.3.1 C4 3.3.2 MassiveText 3.3.3 RefinedWeb 3.3.4 ROOTS 3.4 困難和挑戰 3.4.1 資料收集的局限性 3.4.2 資料品質評估的挑戰 3.4.3 自動生成資料的風險 參考文獻 第4 章 大型語言模型預訓練 4.1 大型語言模型為什麼這麼強 4.2 大型語言模型的核心模組 4.2.1 核心架構 4.2.2 組成模組選型 4.3 大型語言模型怎麼訓練 4.3.1 訓練目標 4.3.2 資料配比 4.4 預訓練還有什麼沒有解決 參考文獻 第5 章 挖掘大型語言模型潛能:有監督微調 5.1 揭開有監督微調的面紗 5.1.1 什麼是有監督微調 5.1.2 有監督微調的作用與意義 5.1.3 有監督微調的應用場景 5.2 有監督微調資料的建構 5.2.1 有監督微調資料的格式 5.2.2 有監督微調資料的自動化建構 5.2.3 有監督微調資料的選擇 5.3 大型語言模型的微調方法 5.3.1 全參數微調 5.3.2 轉接器微調 5.3.3 首碼微調 5.3.4 提示微調 5.3.5 低秩調配 5.4 大型語言模型的微調和推理策略 5.4.1 混合微調策略 5.4.2 基於上下文學習的推理策略 5.4.3 基於思維鏈的推理策略 5.5 大型語言模型微調的挑戰和探索 5.5.1 大型語言模型微調的幻覺問題 5.5.2 大型語言模型微調面臨的挑戰 5.5.3 大型語言模型微調的探索與展望 參考文獻 第6 章 大型語言模型強化對齊 6.1 強化學習基礎 6.1.1 強化學習的基本概念 6.1.2 強化學習中的隨機性 6.1.3 強化學習的目標 6.1.4 Q 函數與V 函數 6.2 DQN 方法 6.2.1 DQN 的結構 6.2.2 DQN 訓練:基本思想 6.2.3 DQN 訓練:目標網路 6.2.4 DQN 訓練:探索策略 6.2.5 DQN 訓練:經驗重播 6.2.6 DQN 訓練:完整演算法 6.2.7 DQN 決策 6.3 策略梯度方法 6.3.1 策略網路的結構 6.3.2 策略網路訓練:策略梯度 6.3.3 策略網路訓練:優勢函數 6.3.4 PPO 演算法 6.4 揭秘大型語言模型中的強化建模 6.4.1 Token-level 強化建模 6.4.2 Sentence-level 強化建模 6.5 獎勵模型 6.5.1 獎勵模型的結構 6.5.2 獎勵模型的訓練 6.5.3 獎勵模型損失函數分析 6.6 RLHF 6.6.1 即時獎勵 6.6.2 RLHF 演算法 6.7 RLHF 實戰框架 6.8 RLHF 的困難和問題 6.8.1 資料瓶頸 6.8.2 硬體瓶頸 6.8.3 方法瓶頸 參考文獻 第7 章 大型語言模型的評測 7.1 基座語言模型的評測 7.1.1 主要的評測維度和基準概述 7.1.2 具體案例:LLaMA 2 選取的評測基準 7.2 大型語言模型的對話能力評測 7.2.1 評測任務 7.2.2 評測集的建構標準 7.2.3 評測方式 7.3 大型語言模型的安全性評測 7.3.1 評測任務 7.3.2 評測方式和標準 7.4 行業大型語言模型的評測:以金融業大型語言模型為例 7.4.1 金融業大型語言模型的自動化評測集 7.4.2 金融業大型語言模型的人工評測集 7.5 整體能力的評測 7.6 主流評測資料集及基準 參考文獻 第8 章 大型語言模型的應用 8.1 大型語言模型為什麼需要提示工程 8.1.1 人類和大型語言模型進行複雜決策的對比 8.1.2 提示工程的作用 8.2 什麼是提示詞 8.2.1 提示詞的基礎要素 8.2.2 提示詞設計的通用原則 8.3 推理引導 8.3.1 零樣本提示 8.3.2 少樣本提示 8.3.3 思維鏈提示 8.3.4 自我一致性提示 8.3.5 思維樹提示 8.4 動態互動 8.4.1 檢索增強生成技術 8.4.2 推理和行動協作技術 8.5 案例分析 8.5.1 案例介紹 8.5.2 工具設計 8.5.3 提示詞設計 8.5.4 案例執行 8.6 侷限和發展 8.6.1 目前的侷限 8.6.2 未來的發展 參考文獻 第9 章 專案實作 9.1 大型語言模型訓練面臨的挑戰 9.2 大型語言模型訓練整體說明 9.2.1 資料並行 9.2.2 模型並行 9.2.3 ZeRO 並行 9.3 大型語言模型訓練技術選型技巧 9.4 大型語言模型訓練最佳化秘笈 9.4.1 I/O 最佳化 9.4.2 通訊最佳化 9.4.3 穩定性最佳化 9.5 大型語言模型訓練專案實作 9.5.1 DeepSpeed 架構 9.5.2 DeepSpeed 訓練詳解 9.5.3 DeepSpeed 訓練優化實作 9.6 強化學習專案實作 9.6.1 DeepSpeed-Chat 混合引擎架構 9.6.2 DeepSpeed-Chat 訓練詳解 9.6.3 DeepSpeed-Chat 訓練優化實作 9.7 大型語言模型推理工程 9.7.1 提升規模:模型量化 9.7.2 提高並行度:張量並行 9.7.3 推理加速:運算元最佳化 9.7.4 降低計算量:KV-Cache 9.7.5 推理工程綜合實作 參考文獻 第10 章 一步步教你訓練7B 大型語言模型 10.1 自動化訓練框架 10.1.1 自動化訓練框架介紹 10.1.2 主要模組介紹 10.2 動手訓練7B 大型語言模型 10.2.1 語料前置處理 10.2.2 預訓練實作 10.2.3 指令微調實作 10.3 小結 |
序
|