







描述
內容簡介
| ★人工智慧的起源與發展歷程
☆機器學習的基本概念與分類方法 ★神經網路的基礎結構與演化歷程 ☆自然語言處理技術的發展與應用 ★大型語言模型的構建原理與應用範疇 ☆互動格式種類與ChatGPT介面詳解 ★提示工程的原理、組成與實用技巧 ☆工作記憶與長短期記憶的管理策略 ★外部工具的整合方法與應用實例 ☆ChatGPT擴充功能與Assistants API解析 ★自主Agent系統的架構設計與案例分析 ☆大型語言模型的安全技術與防護措施
【內容簡介】 本書涵蓋人工智慧的起源與發展,從達特茅斯會議探討機器思考,到現代大型語言模型的構建與應用,深入解析機器學習的概念、分類及運作,並介紹神經網路的結構與演變。自然語言處理技術部分展示NLP在科技中的應用,大型語言模型章節探討文字生成、自回歸模型與訓練過程,並指出其局限。入門部分介紹Completion、ChatML和Chat Completion等互動格式,詳解ChatGPT介面運作。提示工程章節涵蓋提示原理、組成與技巧,提升AI模型表現。工作記憶與長短期記憶管理探討減輕記憶負擔的方法及其對AI效率的影響。外部工具整合與應用實例展示如何增強AI功能,介紹基於提示和微調的工具如Self-ask、ReAct及Toolformer。ChatGPT擴充功能與Assistants API解析讓讀者了解如何定制和擴展AI應用,自主Agent系統章節通過案例展示其設計與應用潛力。進階部分探討無梯度最佳化、自主Agent系統及微調技術,提供深入研究與開發AI的知識。最後,大型語言模型的安全技術與防護措施闡述提示注入攻擊、防禦策略、越獄攻擊、資料投毒及模型浮水印方法,保障AI系統安全。 |
作者簡介
|
目錄
| ▌第1 篇 基礎
第1 章 從人工智慧的起源到大型語言模型 1.1 人工智慧的起源 1.1.1 機器能思考嗎 1.1.2 達特茅斯會議 1.2 什麼是機器學習 1.2.1 演繹推理與歸納推理 1.2.2 人工程式設計與自動程式設計 1.2.3 機器學習的過程 1.2.4 機器學習的分類 1.3 什麼是神經網路 1.3.1 還原論與湧現性 1.3.2 神經網路的發展歷史 1.3.3 神經網路基礎 1.3.4 神經網路的三要素 1.4 自然語言處理的發展歷程 1.4.1 什麼是自然語言處理 1.4.2 文字的向量化 1.4.3 神經網路中的自監督學習 1.5 大型語言模型 1.5.1 什麼是大型語言模型 1.5.2 語言模型中的token 1.5.3 自回歸模型與文字生成 1.5.4 統一自然語言任務 1.5.5 大型語言模型的訓練過程 1.5.6 大型語言模型的局限性
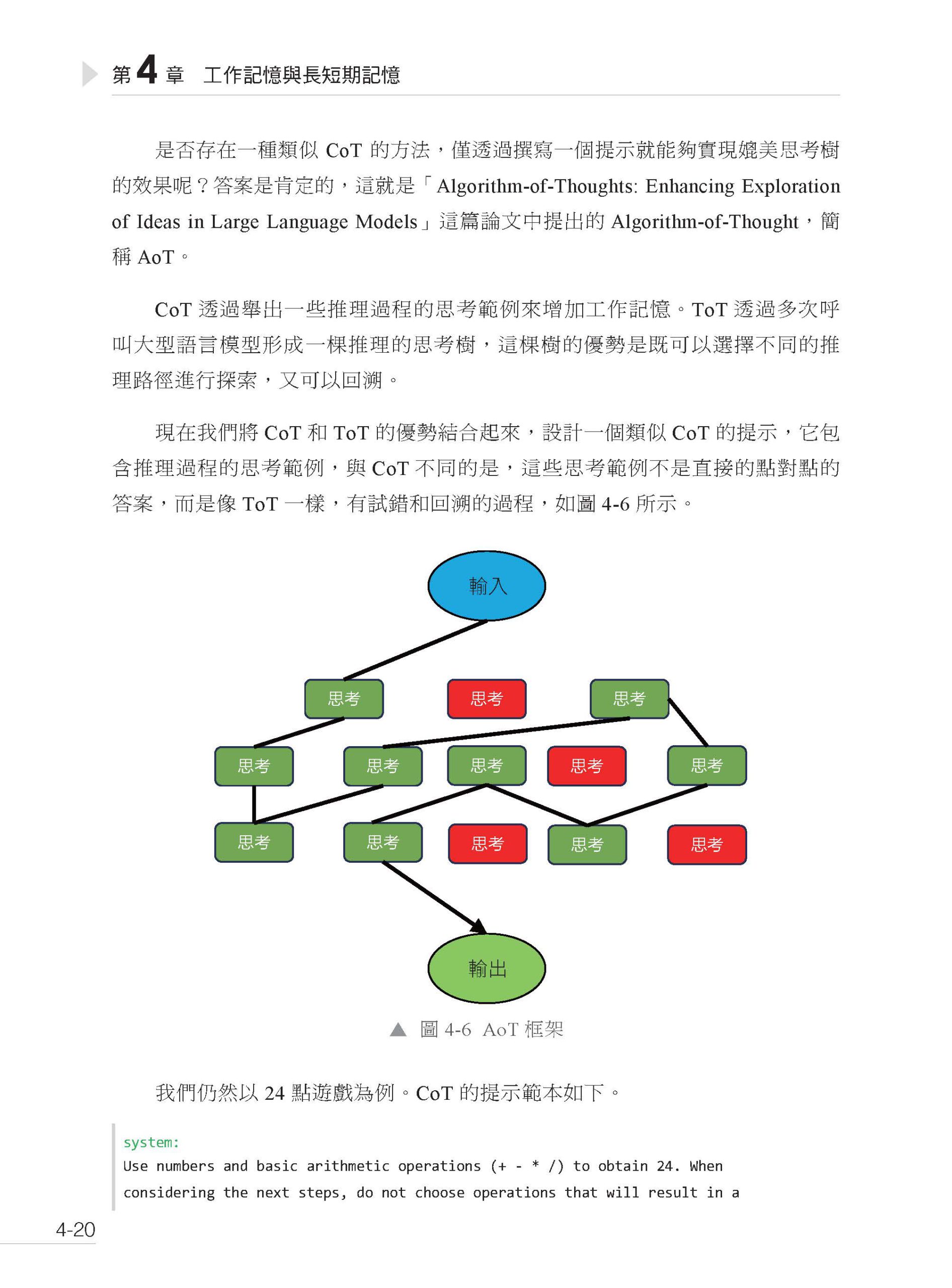
▌第2篇 入門 第2章 互動格式 2.1 Completion 互動格式 2.2 ChatML 互動格式 2.3 Chat Completion 互動格式 第3 章 提示工程 3.1 什麼是提示工程 3.2 提示的組成 3.3 提示的基礎技巧 3.3.1 在提示的末尾重複關鍵指令 3.3.2 使用更清晰的語法 3.3.3 儘量使用範例 3.3.4 明確要求大型語言模型回覆高品質的回應 3.4 Chat Completion 互動格式中的提示 3.5 提示範本與多輪對話 第4 章 工作記憶與長短期記憶 4.1 什麼是工作記憶 4.2 減輕工作記憶的負擔 4.2.1 Chain-of-Thought 4.2.2 Self-Consistency 4.2.3 Least-to-Most 4.2.4 Tree-of-Tought 和Graph-of-Tought 4.2.5 Algorithm-of-Tought 4.2.6 Chain-of-Density 4.3 關於大型語言模型的思考能力 4.4 長短期記憶 4.4.1 什麼是記憶 4.4.2 短期記憶 4.4.3 長期記憶 第5 章 外部工具 5.1 為什麼需要外部工具 5.2 什麼是外部工具 5.3 使用外部工具的基本原理 5.4 基於提示的工具 5.4.1 Self-ask 框架 5.4.2 ReAct 框架 5.4.3 改進ReAct 框架 5.5 基於微調的工具 5.5.1 Toolformer 5.5.2 Gorilla 5.5.3 function calling 第6 章 ChatGPT 介面與擴充功能詳解 6.1 OpenAI 大型語言模型簡介 6.2 ChatGPT 擴充功能原理 6.2.1 網頁即時瀏覽 6.2.2 執行Python 程式 6.2.3 影像生成 6.2.4 本地檔案瀏覽 6.3 Chat Completion 介面參數詳解 6.3.1 模型回應傳回的參數 6.3.2 向模型發起請求的參數 6.4 Assistants API 6.4.1 工具 6.4.2 執行緒 6.4.3 執行 6.4.4 Assistants API 整體執行過程 6.5 GPTs 與GPT 商店 6.5.1 GPTs 功能詳解 6.5.2 GPT 商店介紹 6.5.3 案例:私人郵件幫手
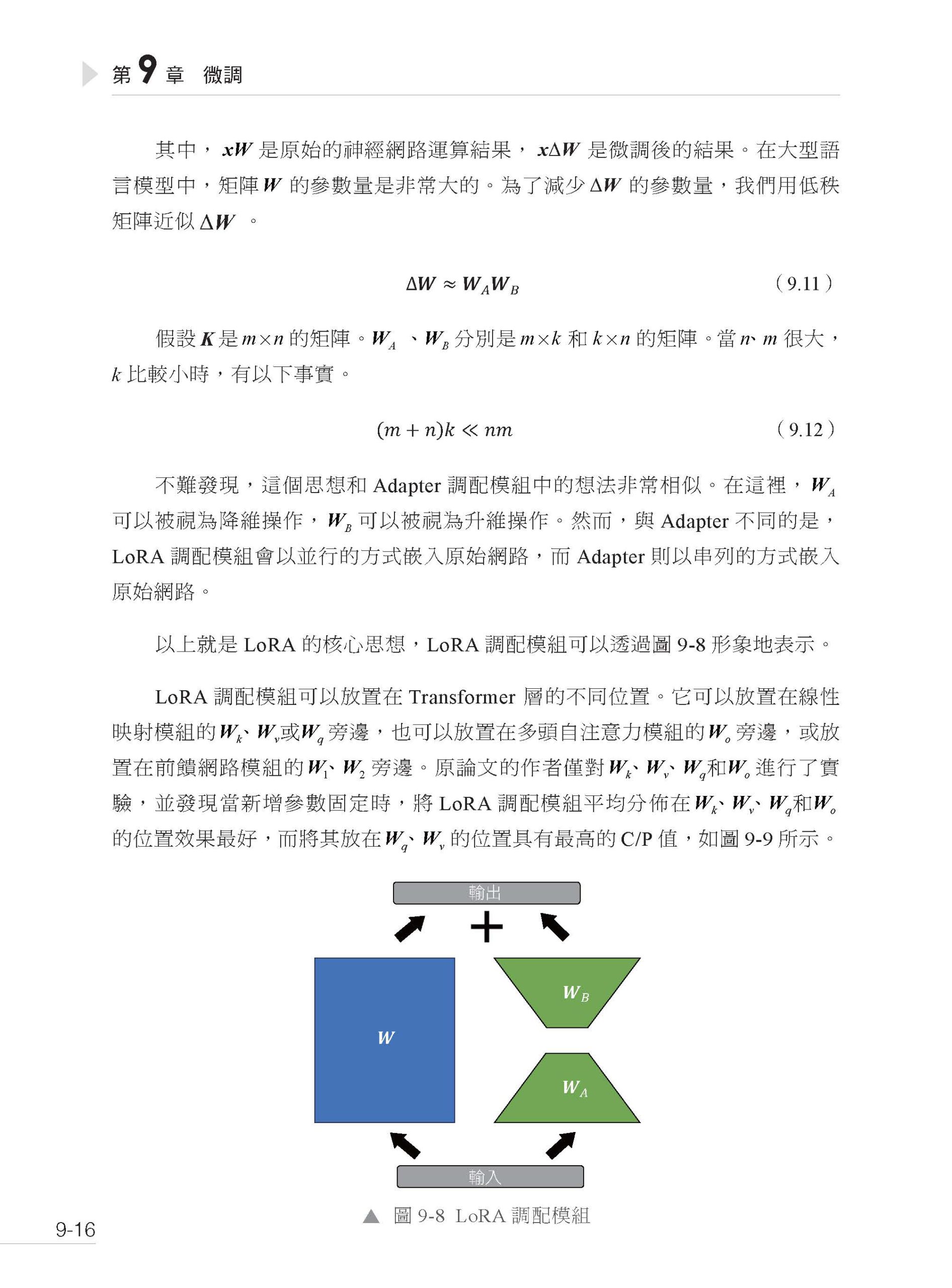
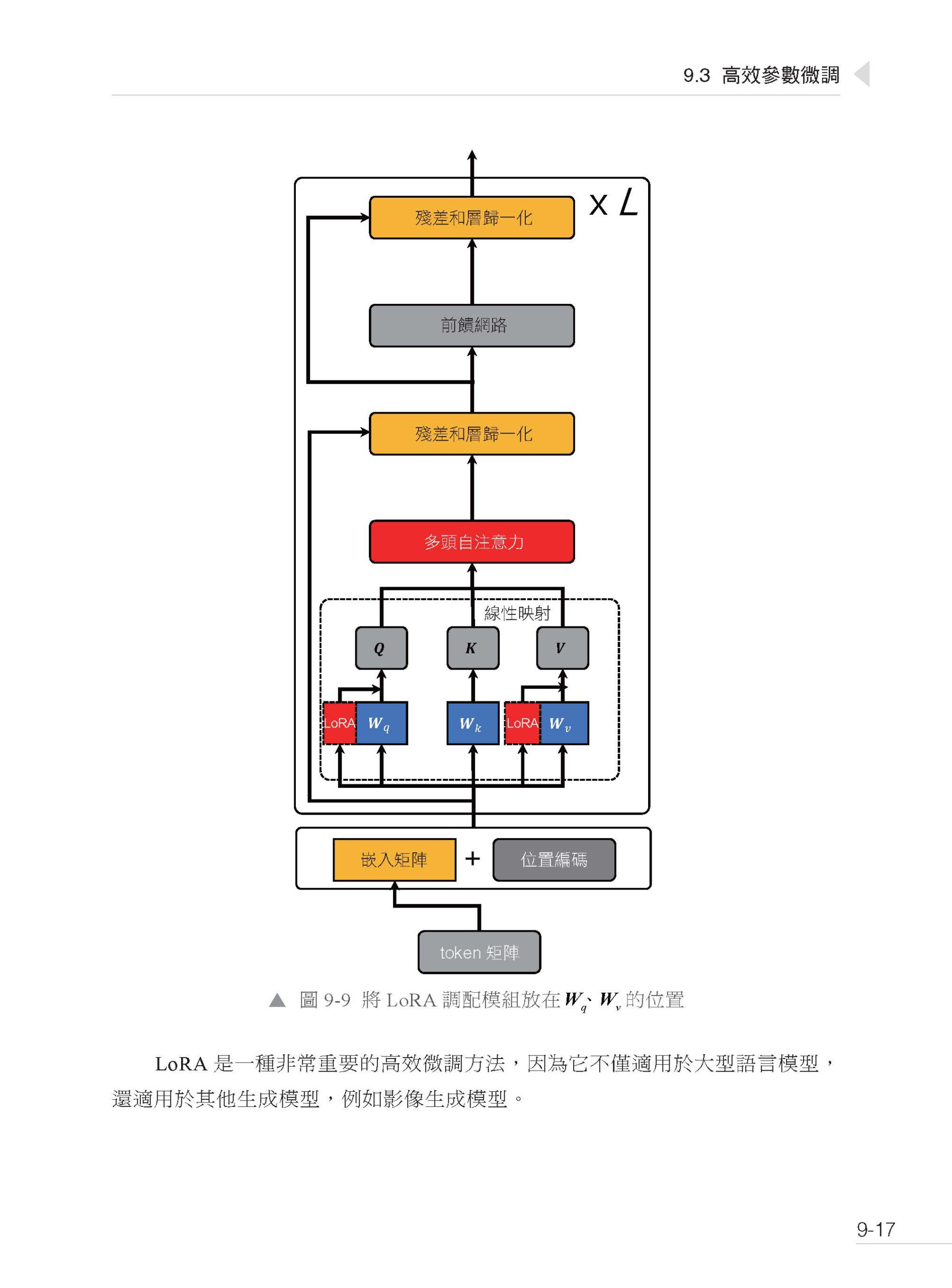
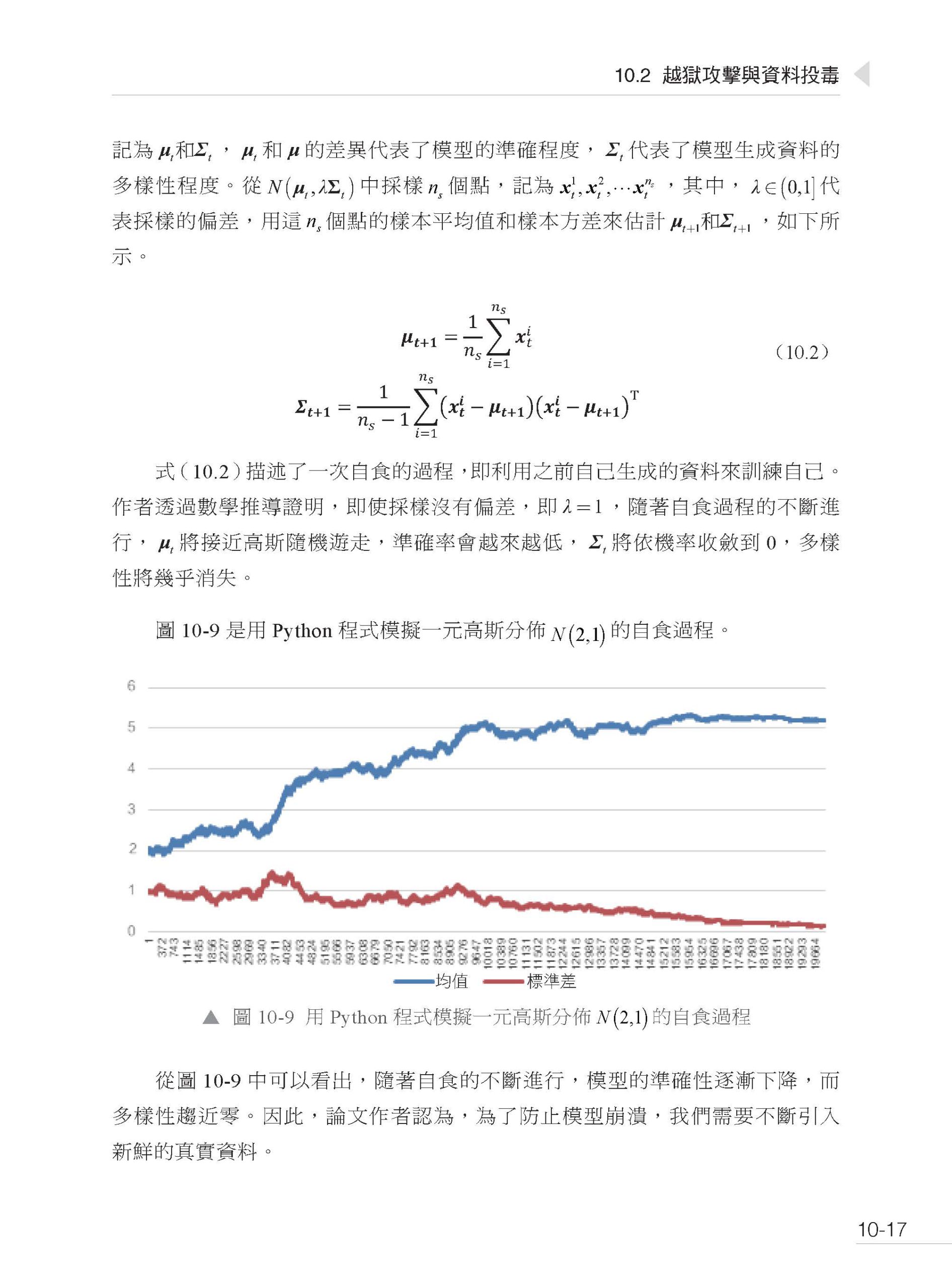
▌第3 篇 進階 第7 章 無梯度最佳化 7.1 單步最佳化 7.2 強化學習入門 7.3 多步最佳化中的預測 7.4 多步最佳化中的訓練 7.5 多步最佳化中的訓練和預測 第8 章 自主Agent 系統 8.1 自主Agent 系統簡介 8.2 自主Agent 系統的基本組成 8.3 自主Agent 系統案例分析(一) 8.3.1 BabyAGI 8.3.2 AutoGPT 8.3.3 BeeBot 8.3.4 Open Interpreter 8.3.5 MemGPT 8.4 自主Agent 系統案例分析(二) 8.4.1 CAMEL 8.4.2 ChatEval 8.4.3 Generative Agents 第9 章 微調 9.1 三類微調方法 9.2 Transformer 解碼器詳解 9.2.1 Transformer 的原始輸入 9.2.2 靜態編碼和位置編碼 9.2.3 Transformer 層 9.3 高效參數微調 9.3.1 Adapter 高效微調 9.3.2 Prompt 高效微調 9.3.3 LoRA 高效微調 9.3.4 高效微調總結 9.4 微調RAG 框架 9.4.1 RAG 框架微調概述 9.4.2 資料準備和參數微調 9.4.3 效果評估 第10 章 大型語言模型的安全技術 10.1 提示注入攻擊 10.1.1 攻擊策略 10.1.2 防禦策略 10.2 越獄攻擊與資料投毒 10.2.1 衝突的目標與不匹配的泛化 10.2.2 對抗樣本 10.2.3 資料投毒 10.3 幻覺和偏見問題 10.4 為大型語言模型增加浮水印
▌第4 篇 展望 第11 章 大型語言模型的生態與未來 11.1 多模態大型語言模型 11.1.1 什麼是多模態 11.1.2 GPT-4V 簡介 11.1.3 Gemini 簡介 11.2 大型語言模型的生態系統 11.3 大型語言模型的第一性原理:Scaling Law 11.3.1 什麼是Scaling Law 11.3.2 Scaling Law 的性質 11.3.3 Scaling Law 的未來 11.4 通向通用人工智慧:壓縮即智慧 11.4.1 編碼與無失真壓縮 11.4.2 自回歸與無失真壓縮 11.4.3 無失真壓縮的極限 11.5 圖靈機與大型語言模型:可計算性與時間複雜度 11.5.1 圖靈機與神經網路 11.5.2 智慧的可計算性 11.5.3 邏輯推理的時間複雜度 參考文獻 |
序
|