





描述
內容簡介
| AI讀心數 - 推薦系統演算法核心程式碼精通 網際網路快速發展,使用者和內容規模均迅速增長。如何讓使用者找到感興趣的內容成為許多公司的核心問題。推薦系統屬於被動型消費。和搜尋系統是連接使用者和內容的關鍵橋樑。深度學習技術開始進入推薦系統,深度學習的推薦系統顯著提升了內容分發的準確性和使用者體驗,推薦演算法工程師因此進入了一個新的時代。推薦演算法也在迅速發展,從業者需要不斷學習新知識。
推薦系統的鏈路很長,包括召回、粗排、精排和重排等多個模組,掌握整體架構並深入理解各個模組的細節是困難且重要的。本書主要介紹推薦演算法技術,涵蓋召回、粗排、精排和重排等模組,讓讀者熟悉推薦演算法的全過程,加深系統化理解,並掌握關鍵技術細節。
書中介紹的技術也適用於搜尋和廣告等領域。幫助讀者掌握推薦演算法的整體架構和核心模組的知識框架,以及一些工作必備的經典模型,深入理解其出發點和具體實現方案,並在實際工作中靈活運用。處於資訊爆炸時代的推薦演算法工程師需要不斷學習新知識,接受更多挑戰。希望本書分享的知識和經驗能夠幫助讀者一臂之力。 |
作者簡介
|
目錄
| 第 1 章 推薦系統概述
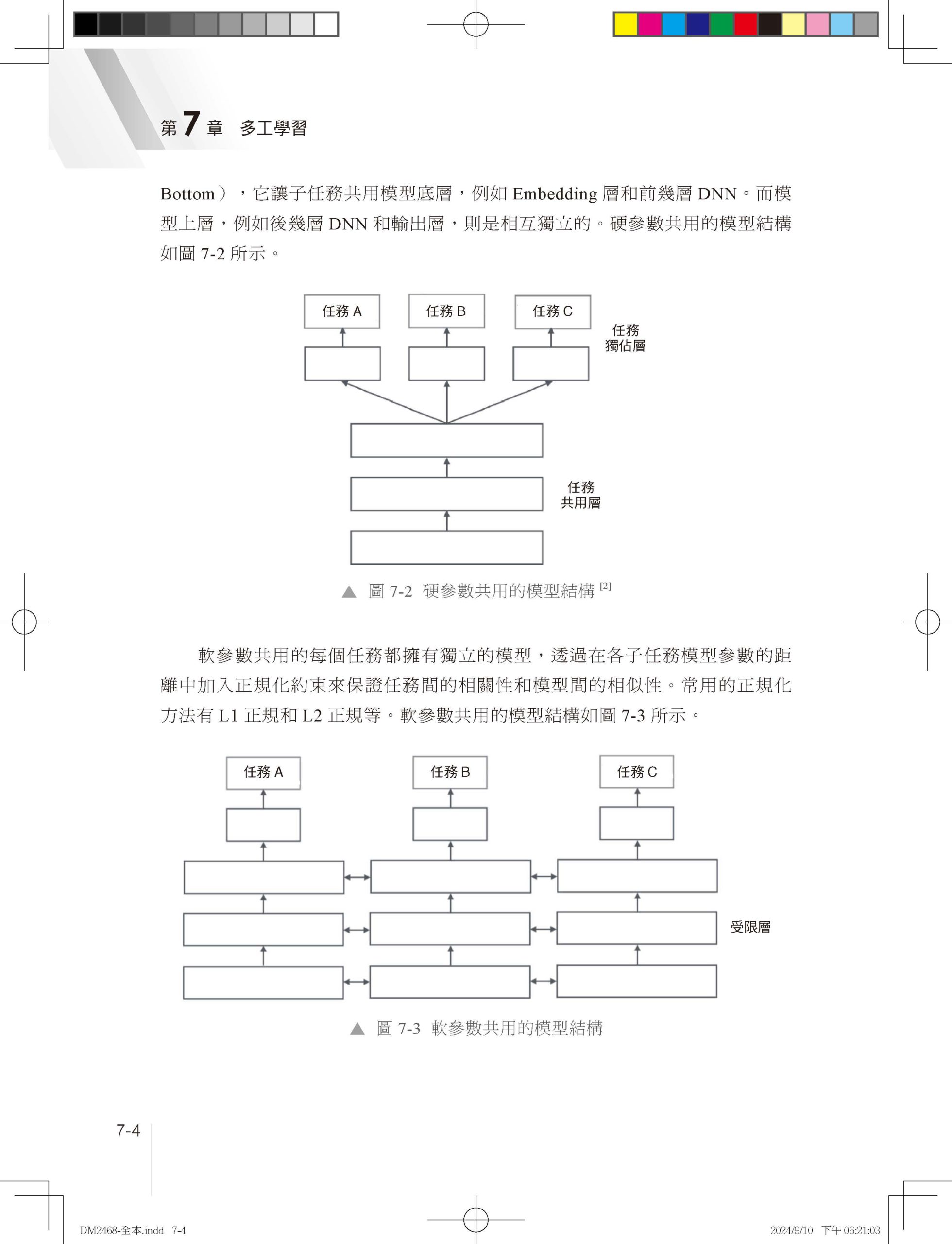
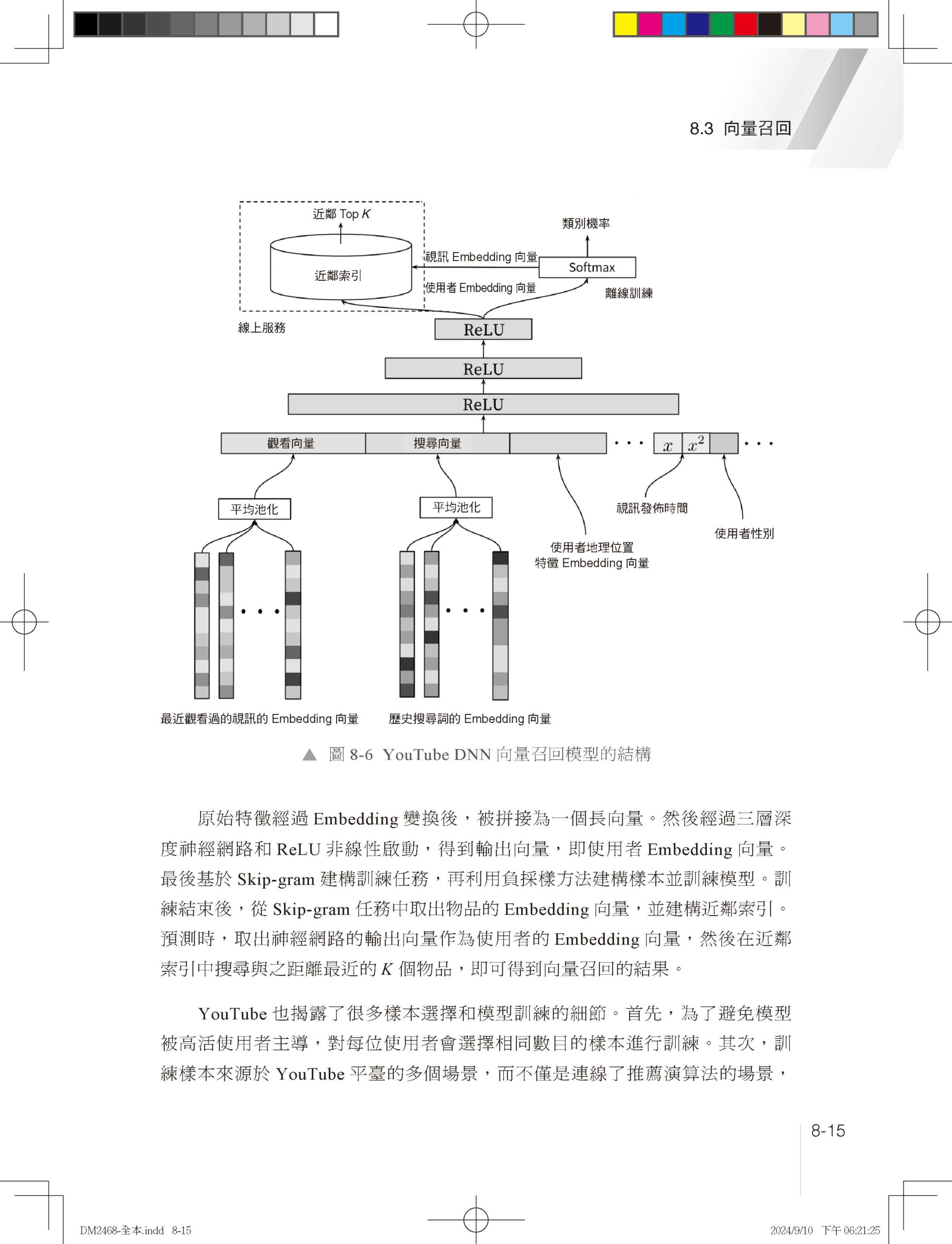
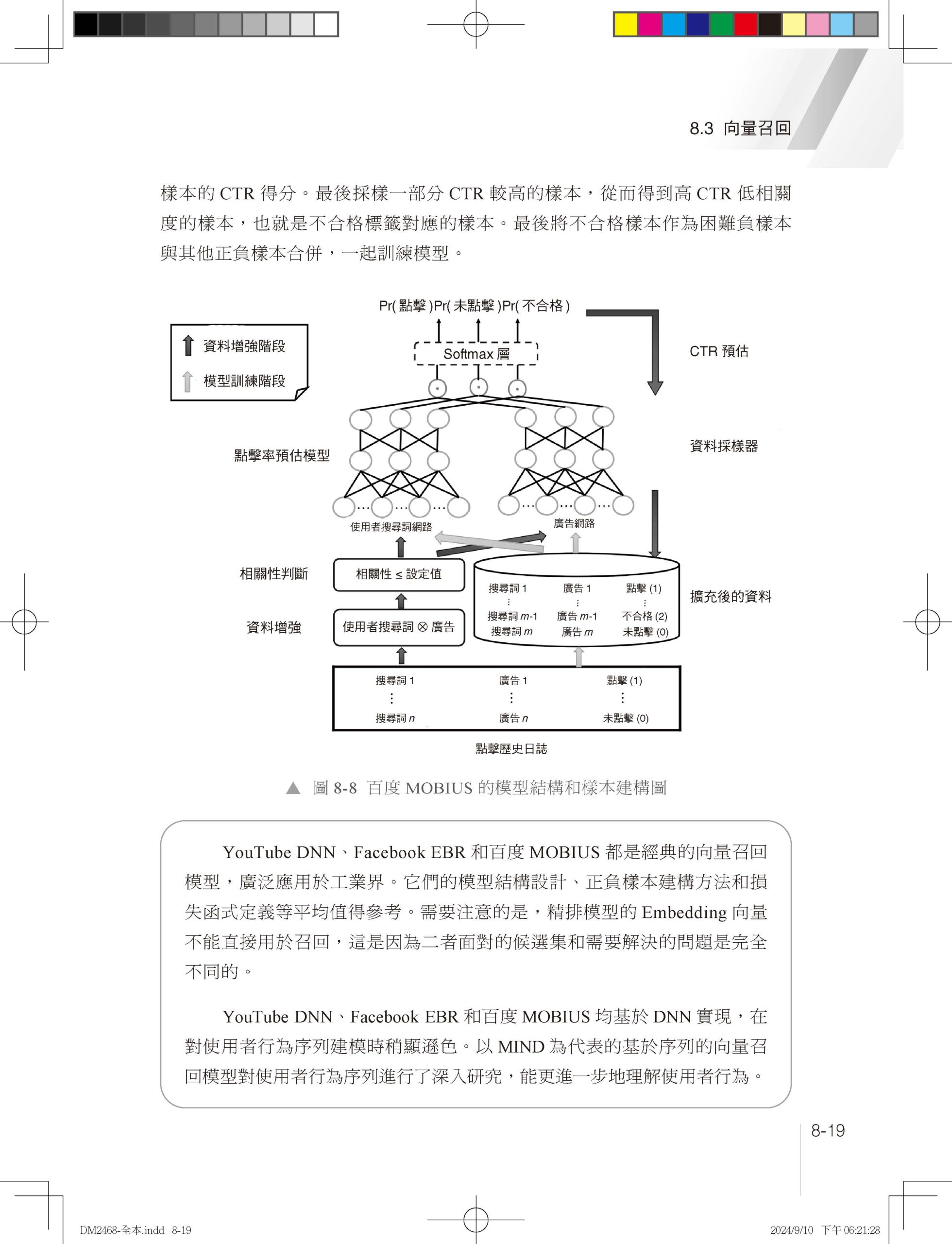
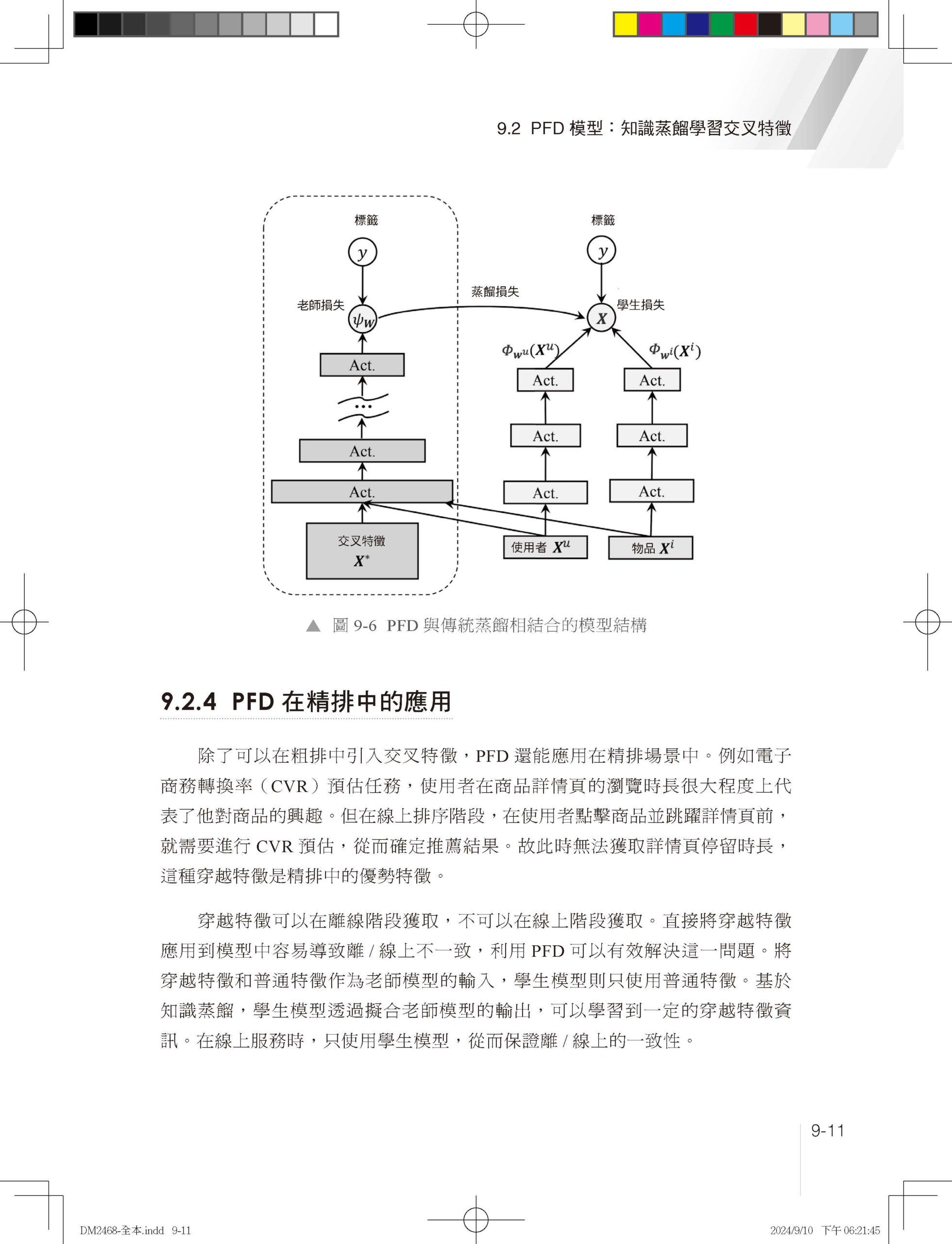
1.1 為什麼需要推薦系統 1.1.1 推薦系統與使用者體驗 1.1.2 推薦系統與內容生產 1.1.3 推薦系統與平臺發展 1.2 推薦系統分類 1.2.1 業務領域分類 1.2.2 內容媒體分類 1.2.3 互動形態分類 1.2.4 應用場景分類 1.3 推薦系統架構 1.4 本章小結 第 2 章 資料樣本和特徵工程 2.1 資料樣本 2.1.1 樣本不均衡問題 2.1.2 樣本不置信問題 2.1.3 離/線上樣本不一致問題 2.2 特徵工程 2.2.1 特徵類目系統 2.2.2 特徵處理範式 2.2.3 特徵重要性評估 2.3 本章小結 參考文獻 第 3 章 傳統推薦演算法 3.1 協作過濾 3.1.1 基於使用者的協作過濾 3.1.2 基於物品的協作過濾 3.1.3 協作過濾的優點和局限性 3.2 矩陣分解 3.2.1 矩陣分解實現方法 3.2.2 矩陣分解的優點和局限性 3.3 邏輯回歸 3.3.1 邏輯回歸求解過程 3.3.2 邏輯回歸的優點和局限性 3.4 因數分解機 3.4.1 因數分解機模型簡化 3.4.2 因數分解機的優點和局限性 3.5 組合模型 3.5.1 GBDT + LR 組合模型結構 3.5.2 GBDT 特徵轉換過程 3.5.3 組合模型的思考和總結 3.6 本章小結 參考文獻 第 4 章 特徵交叉 4.1 特徵交叉概述 4.1.1 特徵交叉的意義 4.1.2 特徵交叉基本範式 4.1.3 特徵交叉的困難 4.2 Deep Crossing:經典DNN框架模型 4.2.1 業務背景和特徵系統 4.2.2 模型結構 4.2.3 實現方法 4.3 FNN 4.3.1 為什麼Embedding收斂慢 4.3.2 模型結構 4.4 PNN 4.4.1 模型結構 4.4.2 特徵交叉實現方法 4.5 Wide&Deep:異質模型奠基者 4.5.1 「記憶」和「泛化」 4.5.2 模型結構 4.5.3 系統實現 4.5.4 程式解析 4.6 DeepFM:異質模型Wide側引入FM 4.6.1 模型結構 4.6.2 程式解析 4.7 DCN:異質模型Wide側引入高階交叉 4.8 NFM:異質模型Deep側引入顯式交叉 4.9 xDeepFM:異質模型引入子分支 4.10 本章小結 參考文獻 第 5 章 使用者行為序列建模 5.1 使用者行為序列建模概述 5.1.1 行為序列建模的意義 5.1.2 行為序列建模的基本範式 5.1.3 行為序列建模的主要困難 5.1.4 行為序列特徵工程 5.2 DIN:基於注意力機制建模使用者行為序列 5.2.1 背景 5.2.2 模型結構 5.2.3 模型訓練方法 5.2.4 程式解析 5.3 DIEN:GRU建模使用者行為序列 5.3.1 模型結構:興趣取出層 5.3.2 模型結構:興趣進化層 5.4 BST:Transformer建模使用者行為序列 5.4.1 模型結構 5.4.2 程式解析 5.5 DSIN:基於Session建模使用者行為序列 5.6 MIMN:基於神經圖靈機建模長週期行為序列 5.6.1 工程設計:UIC模組 5.6.2 MIMN模型結構 5.7 SIM:基於檢索建模長週期行為序列 5.8 ETA:基於SimHash實現檢索索引線上化 5.8.1 ETA模型結構 5.8.2 SimHash原理 5.9 本章小結 參考文獻 第 6 章 Embedding表徵學習 6.1 Embedding表徵學習概述 6.1.1 Embedding概述 6.1.2 Embedding表徵學習的意義 6.1.3 Embedding表徵學習的基本範式 6.1.4 Embedding表徵學習的主要困難 6.2 基於序列的Embedding建模方法 6.2.1 Word2vec任務定義:CBOW和Skip-gram 6.2.2 Word2vec模型結構 6.2.3 Word2vec訓練方法 6.2.4 Item2vec:推薦系統引入序列Embedding 6.2.5 序列建模總結和思考 6.3 基於同構圖遊走的Graph Embedding 6.3.1 DeepWalk:同構圖遊走演算法開山之作 6.3.2 LINE:一階相似度和二階相似度探索 6.3.3 Node2vec:同質性和結構等價性探索 6.3.4 同構圖遊走的優缺點 6.4 基於異質圖遊走的Graph Embedding 6.4.1 Metapath2vec 6.4.2 EGES 6.4.3 異質圖遊走的優缺點 6.5 圖神經網路 6.5.1 GCN:圖神經網路開山之作 6.5.2 GraphSAGE:圖神經網路工業應用的高潮 6.5.3 圖神經網路總結 6.6 向量檢索技術 6.6.1 向量距離計算方法 6.6.2 向量檢索演算法 6.6.3 向量檢索常用工具:Faiss 6.7 本章小結 參考文獻 第 7 章 多工學習 7.1 多工學習發展歷程 7.1.1 為什麼需要多工學習 7.1.2 多工學習的基本框架 7.1.3 多工學習的困難和挑戰 7.2 ESMM模型:解決SSB和DS問題的利器 7.2.1 樣本選擇偏差和資料稀疏問題 7.2.2 ESMM模型結構 7.2.3 ESMM核心程式 7.3 MMOE模型:多專家多門控網路 7.3.1 MMOE模型結構 7.3.2 MMOE核心程式 7.4 PLE模型:解決負遷移和蹺蹺板現象的利器 7.4.1 負遷移和蹺蹺板現象 7.4.2 單層CGC模型結構 7.4.3 PLE模型結構 7.4.4 PLE核心程式 7.5 多工融合 7.5.1 網格搜尋 7.5.2 排序模型 7.5.3 強化學習 7.6 本章小結 參考文獻 第 8 章 召回演算法 8.1 召回概述 8.1.1 推薦底池 8.1.2 多路召回 8.1.3 召回的困難 8.1.4 召回評價系統 8.2 個性化召回 8.2.1 基於內容的個性化召回 8.2.2 基於協作過濾的個性化召回 8.2.3 基於社交關係的個性化召回 8.3 向量召回 8.3.1 實現方法 8.3.2 YouTube DNN 8.3.3 Facebook EBR 8.3.4 百度MOBIUS 8.4 使用者行為序列類向量召回 8.4.1 多峰興趣建模的意義 8.4.2 MIND的模型結構 8.4.3 膠囊網路 8.5 樣本選擇偏差問題 8.5.1 召回樣本建構方法 8.5.2 ESAM和遷移學習 8.6 召回檢索最佳化和TDM 8.6.1 TDM線上檢索過程 8.6.2 TDM索引建構和模型訓練過程 8.6.3 JTM 8.6.4 OTM 8.7 本章小結 參考文獻 第 9 章 粗排演算法 9.1 粗排概述 9.1.1 粗排樣本和特徵 9.1.2 粗排發展歷程 9.1.3 粗排的困難 9.1.4 粗排評價系統 9.2 PFD模型:知識蒸餾學習交叉特徵 9.2.1 PFD模型結構 9.2.2 PFD模型原理 9.2.3 PFD與傳統蒸餾相結合 9.2.4 PFD在精排中的應用 9.3 COLD模型:顯式特徵交叉 9.3.1 雙塔內積模型 9.3.2 COLD模型 9.4 FSCD模型:效果和效率聯合最佳化 9.4.1 FSCD特徵選擇原理 9.4.2 FSCD訓練步驟 9.5 本章小結 參考文獻 第 10 章 重排演算法 10.1 重排概述 10.1.1 為什麼需要重排 10.1.2 重排的困難和挑戰 10.1.3 流量調控 10.2 打散和多樣性 10.2.1 打散 10.2.2 多樣性 10.2.3 多樣性發展歷程 10.3 上下文感知和PRM模型 10.3.1 什麼是上下文感知 10.3.2 PRM模型結構 10.3.3 其他上下文感知實現方案 10.4 即時性和延遲回饋問題 10.4.1 推薦系統即時性的意義 10.4.2 推薦系統即時性分類 10.4.3 延遲回饋問題 10.4.4 延遲回饋最佳化方案 10.5 端上重排和EdgeRec 10.5.1 為什麼需要端上模型 10.5.2 端上推理引擎 10.5.3 EdgeRec系統架構 10.5.4 EdgeRec模型結構 10.6 本章小結 參考文獻 |
序
|