





描述
內容簡介
|
\\好評再版// ★語音前端處理,語音辨識 ★語者自動分段標記演算法原理 ★基於WebRTC,Kaldi和gRPC,從零建構穩定、高性能、可商用的語音服務 ★前端演算法完整介紹 ★語音活動檢測、語音降噪、回聲消除、波束形成 ★WebRTC和Kaldi最佳化處理流程 ★形成語音演算法SDK ★微服務建構的RPC遠端呼叫框架和SDK
【內容簡介】 本書從語音辨識的概要談起,並且介紹了目前市場概況及常用的工具包括WebRTC及技術人最愛的Kaldi。接下來說明了語音訊號的聲學基和數位化、時頻變換的原理。語音技術中最重要的演算法也有說明,包括了各種VAD、單通道降噪、回聲消除等濾波器、波束形成的介紹。重點部分包括了語音辨識中最重要的特徵提取和聲學模型,如傳統及神經網路基礎的實作法。 在了解原理之後,即開始建立真正專案,包括使用Kaldi實作一個國語的模型。最近流行的語者自動分段標記在本書中也有實作,大量應用了深度學習的模型及音訊庫、函數庫等。如使用了CNCeleb的聲紋資料當作訓練集。在Kaldi的進階應用方面,也實作了其SDK的音訊特徵提取及WebRTC的語音活動檢測。 本書的收尾之作就是使用了gRPC進行一個完整的語音識別服務實作,使用了現在最好用的ProtoBuf的協定進行運作,完成了伺服器/客戶端應用開發,可以說是目前市面上最完整的語音辨識中文圖書。 |
作者簡介
|
目錄
| Chapter 01 語音辨識概述
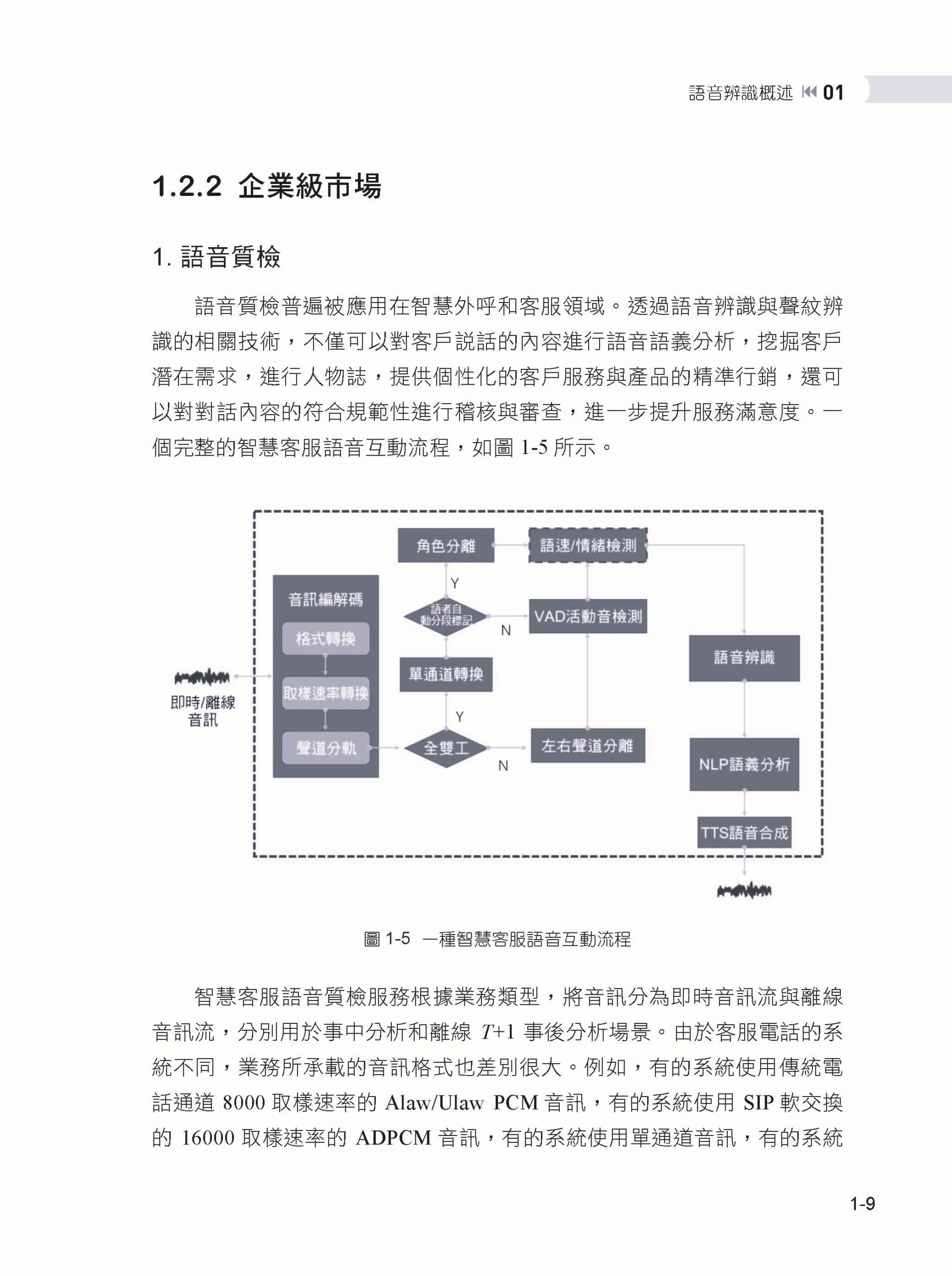
▌1.1 語音辨識發展歷程 ▌1.2 語音辨識產業與應用 1.2.1 消費級市場 1.2.2 企業級市場 ▌1.3 常用語音處理工具 1.3.1 WebRTC 1.3.2 Kaldi 1.3.3 點對點語音辨識工具套件
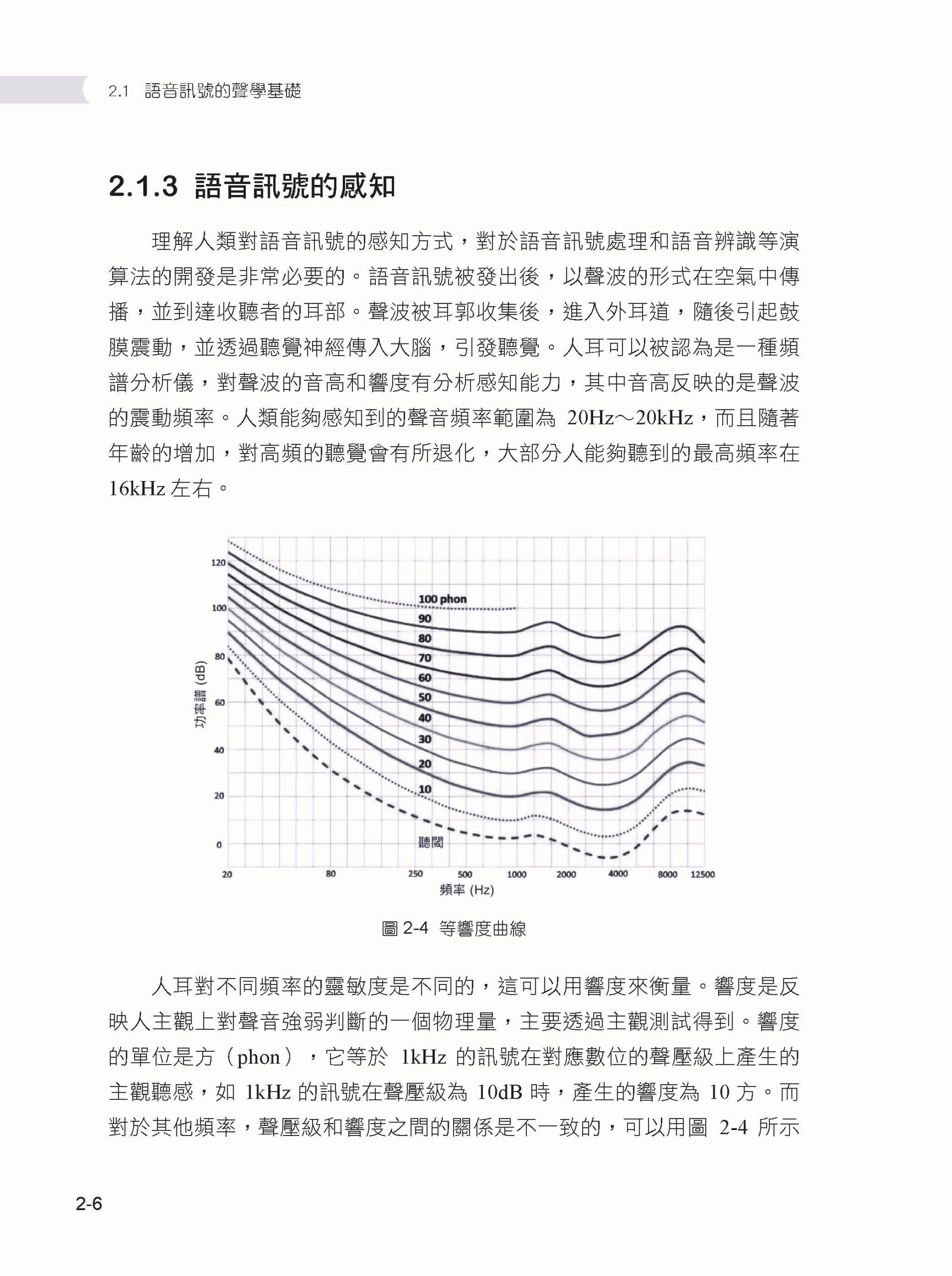
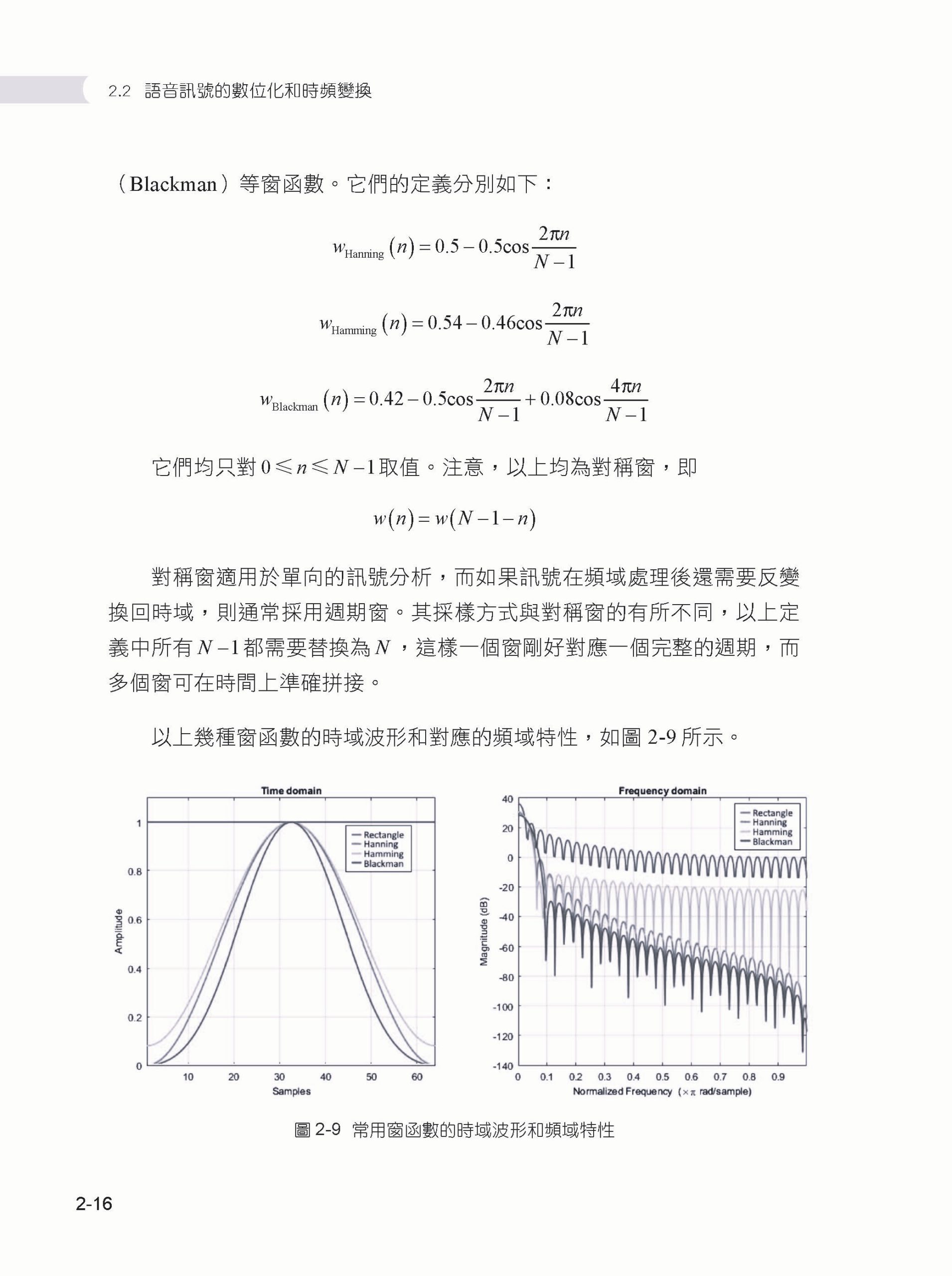
Chapter 02 語音訊號基礎 ▌2.1 語音訊號的聲學基礎 2.1.1 語音產生機制 2.1.2 語音訊號的產生模型 2.1.3 語音訊號的感知 ▌2.2 語音訊號的數位化和時頻變換 2.2.1 語音訊號的採樣、量化和編碼 2.2.2 語音訊號的時頻變換 ▌2.3 本章小結
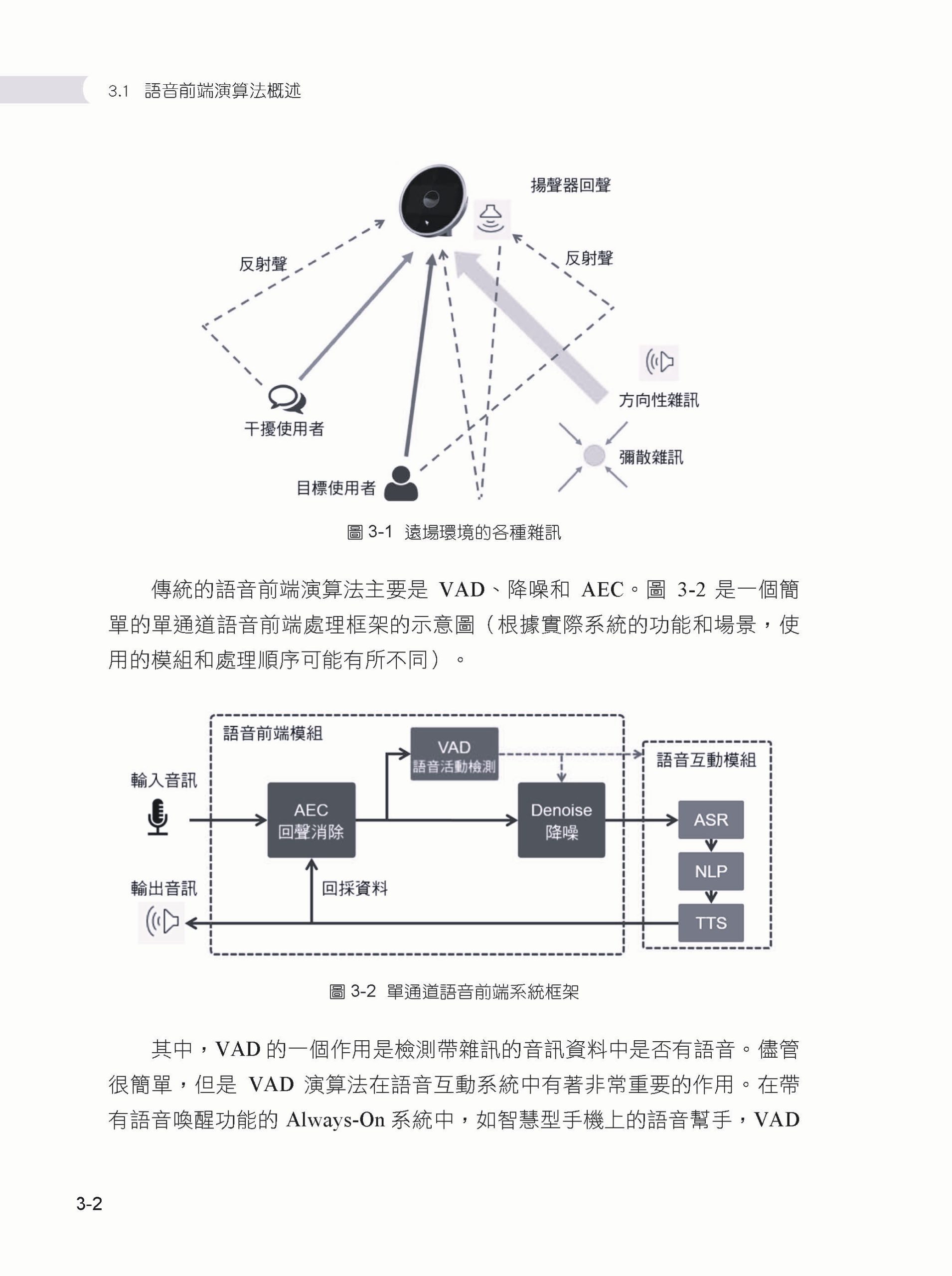
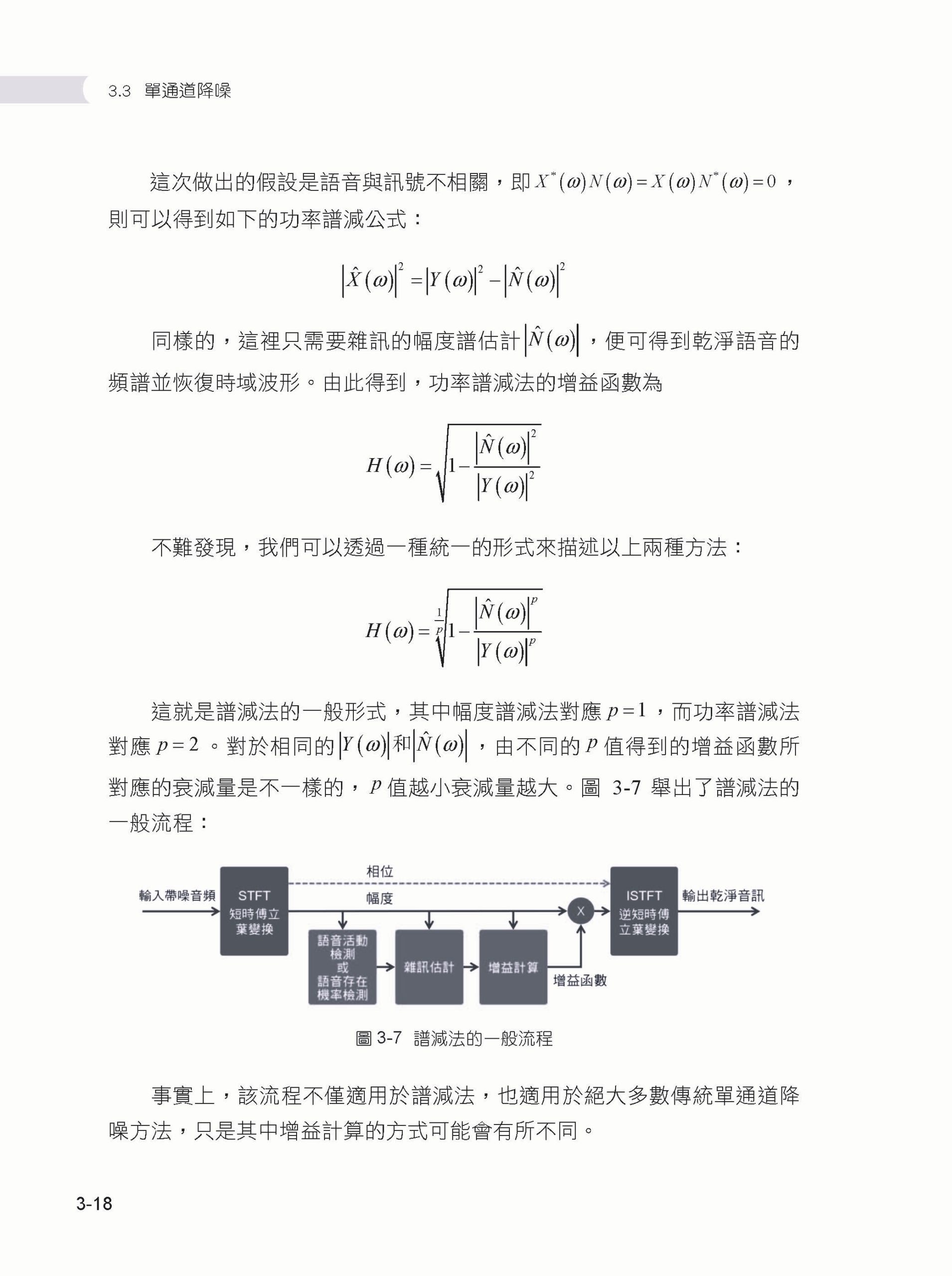
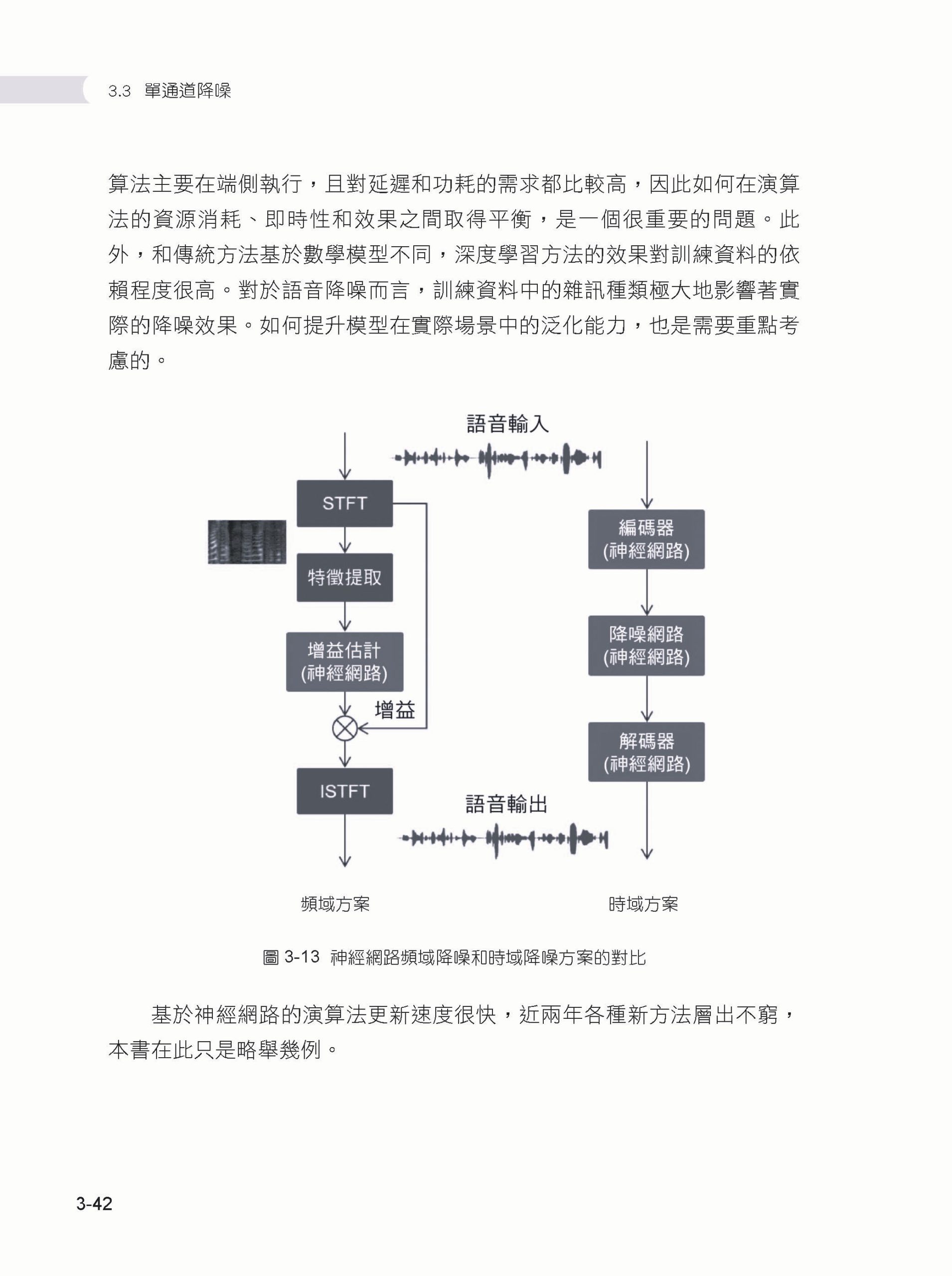
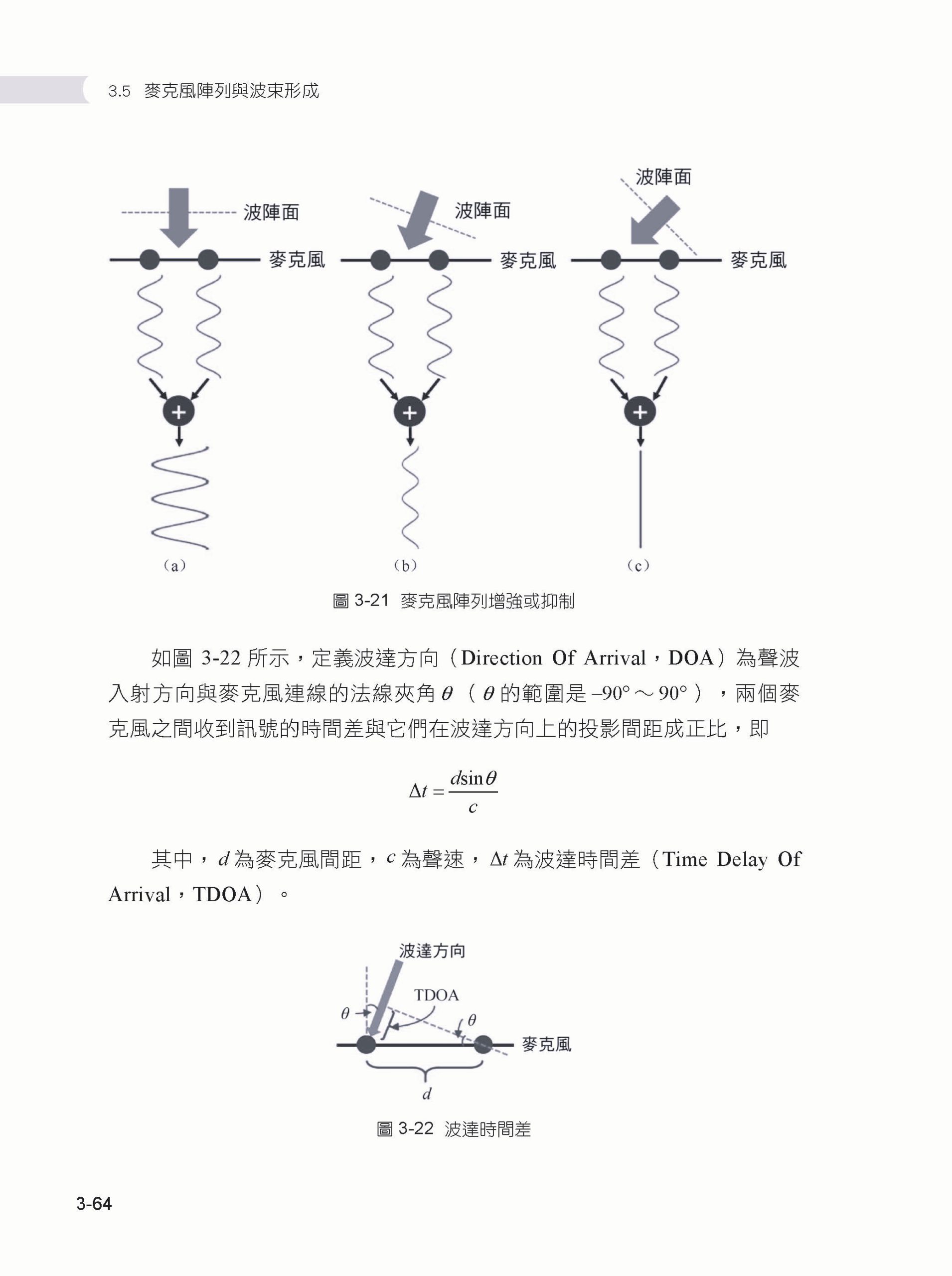
Chapter 03 語音前端演算法 ▌3.1 語音前端演算法概述 ▌3.2 VAD 3.2.1 基於門限判決的VAD 3.2.2 基於高斯混合模型的VAD 3.2.3 基於神經網路的VAD ▌3.3 單通道降噪 3.3.1 譜減法 3.3.2 維納濾波法 3.3.3 音樂雜訊和參數譜減法 3.3.4 貝氏準則下的MMSE 3.3.5 雜訊估計 3.3.6 基於神經網路的單通道降噪 ▌3.4 回音消除 3.4.1 回音消除概述 3.4.2 線性自我調整濾波 3.4.3 分區塊頻域自我調整濾波器 3.4.4 雙邊對話檢測 3.4.5 延遲估計 3.4.6 殘留回音消除 3.4.7 基於神經網路的回音消除 ▌3.5 麥克風陣列與波束形成 3.5.1 麥克風陣列概述 3.5.2 延遲求和波束形成 3.5.3 最小方差無失真回應波束形成 3.5.4 廣義旁波瓣對消波束形成 3.5.5 後置濾波 3.5.6 基於神經網路的波束形成 ▌3.6 聲源定位 3.6.1 GCC-PHAT 3.6.2 基於自我調整濾波的聲源定位 3.6.3 SRP-PHAT 3.6.4 子空間聲源定位演算法 3.6.5 基於神經網路的聲源定位 ▌3.7 其他未盡話題 ▌3.8 本章小結
Chapter 04 語音辨識原理 ▌4.1 特徵提取 4.1.1 特徵前置處理 4.1.2 常見的語音特徵 ▌4.2 傳統聲學模型 4.2.1 聲學建模單元 4.2.2 GMM-HMM 4.2.3 強制對齊 ▌4.3 DNN-HMM 4.3.1 語音辨識中的神經網路基礎 4.3.2 常見的神經網路結構 ▌4.4 語言模型 4.4.1 n-gram 語言模型 4.4.2 語言模型的評價指標 4.4.3 神經語言模型 ▌4.5 WFST 解碼器 4.5.1 WFST 原理 4.5.2 常見的WFST 運算 4.5.3 語音辨識中的WFST 解碼器 4.5.4 權杖傳遞演算法 4.5.5 Beam Search ▌4.6 序列區分性訓練 4.6.1 MMI 和bMMI 4.6.2 MPE 和sMBR 4.6.3 詞圖 4.6.4 LF-MMI ▌4.7 點對點語音辨識 4.7.1 CTC 4.7.2 Seq2Seq ▌4.8 語音辨識模型評估 ▌4.9 本章小結
Chapter 05 中文漢語模型訓練-- 以multi_cn 為例 ▌5.1 Kaldi 安裝與環境設定 ▌5.2 Kaldi 中的資料格式與資料準備 ▌5.3 語言模型訓練 ▌5.4 發音詞典準備 ▌5.5 特徵提取 ▌5.6 Kaldi 中的Transition 模型 ▌5.7 預對齊模型訓練 5.7.1 單音素模型訓練 5.7.2 delta 特徵模型訓練 5.7.3 lda_mllt 特徵變換模型訓練 5.7.4 語者自我調整訓練 ▌5.8 資料增強 5.8.1 資料清洗及重分割 5.8.2 速度增強和音量增強 5.8.3 SpecAugment ▌5.9 I-Vector 訓練 5.9.1 對角UBM 5.9.2 I-Vector 提取器 5.9.3 提取訓練資料的I-Vector ▌5.10 神經網路訓練 5.10.1 Chain 模型 5.10.2 Chain 模型態資料準備 5.10.3 神經網路設定與訓練 ▌5.11 解碼圖生成 ▌5.12 本章小結 ▌5.13 附錄 5.13.1 xconfig 中的描述符及網路設定表 5.13.2 Chain 模型中的egs 5.13.3 Kaldi nnet3 中迭代次數和學習率調整
Chapter 06 基於Kaldi 的語者自動分段標記 ▌6.1 語者自動分段標記概述 6.1.1 什麼是語者自動分段標記 6.1.2 語者自動分段標記技術 6.1.3 語者自動分段標記評價指標 ▌6.2 聲紋模型訓練-- 以CNCeleb 為例 6.2.1 聲紋資料準備 6.2.2 I-Vector 訓練 6.2.3 X-Vector 訓練 6.2.4 LDA/PLDA 後端模型訓練 6.2.5 語者自動分段標記後端模型訓練 ▌6.3 本章小結
Chapter 07 基於Kaldi 的語音SDK 實現 ▌7.1 語音特徵提取 7.1.1 音訊讀取 7.1.2 音訊特徵提取 ▌7.2 基於WebRTC 的語音活動檢測 ▌7.3 語者自動分段標記模組 7.3.1 I-Vector 提取 7.3.2 X-Vector 提取 7.3.3 語者自動分段標記演算法實現 ▌7.4 語音辨識解碼 ▌7.5 本章小結
Chapter 08 基於gRPC 的語音辨識服務 ▌8.1 gRPC 語音服務 ▌8.2 ProtoBuf 協定定義 ▌8.3 基於gRPC 的語音服務實現 8.3.1 gRPC Server 實現 8.3.2 gRPC Client 實現 8.3.3 gRPC 語音服務的編譯與測試 ▌8.4 本章小結
Appendix A 參考文獻 |
序
| 序
近年來,隨著深度學習技術的不斷發展,語音辨識準確率獲得了大幅提升,由此帶來了基於語音互動應用的豐富想像力,這些技術越來越多地影響著人們生產和生活的各方面。其中,消費級應用包括智慧喇叭、手機語音助理、車載智慧座艙、語音輸入法與翻譯機等;企業級應用包括智慧客服、語音品管、智慧教育、智慧醫療等。各類智慧語音應用的蓬勃發展使得越來越多的人加入語音領域的研究和落地,共同推動整個語音產業的發展。 得益於語音辨識技術的蓬勃發展和辨識率的節節攀升,業界湧現出眾多優秀的點對點語音工具套件,如Wenet,ESPNet,SpeechBrain 等。儘管如此,2009 年約翰霍普金斯大學夏季研討會孵化出的Kaldi 工具箱,以其穩定的演算法效果,活躍的社區氣氛,獲得了廣泛應用,極大地降低了語音辨識的上手門檻,也培養了大量的相關人才。目前,仍然有很多公司在使用基於Kaldi 的專案。 由於語音互動技術涉及的演算法與技術鏈較長,因此已有的語音演算法相關圖書主要集中在各類語音演算法的原理與訓練上,缺乏從語音互動角度出發,介紹語音互動所需的語音前後端各項演算法和整體解決方案的相關圖書。在語音應用的落地上,學術界也缺乏產業界的專案應用實作經驗。本書將致力於拉近學術界與產業界的距離,在系統地介紹語音互動流程中涉及的語音前端處理、語音辨識和語者自動分段標記等演算法原理的同時,詳細介紹如何基於WebRTC,Kaldi 和gRPC,從零建構產業界穩定、高性能、可商用的語音服務。 在前端演算法的相關章節中,本書系統地介紹了語音活動檢測、語音降噪、回音消除、波束形成等常用的語音前端處理演算法的原理,還針對各種演算法在實際場景中的專案實現方法,提供了大量的經驗複習。除了介紹傳統訊號的處理方法,本書還介紹了深度學習方法在語音前端領域中的發展和應用現狀。 在語音後端演算法方面,本書詳細介紹了語音辨識中的特徵提取、聲學模型、語言模型、解碼器和點對點語音辨識,以及語者自動分段標記中的聲紋Embedding 提取和聚類演算法。同時,還介紹了如何基於Kaldi 訓練語音辨識及語者自動分段標記模型。針對訓練模型時的很多細節問題,提供了詳細的解釋。 在語音演算法專案化方面,本書介紹了如何利用WebRTC 和Kaldi 最佳化處理流程,形成語音演算法SDK。基於流行的用於微服務建構的RPC 遠端呼叫框架和SDK,進一步介紹了如何實現一套方便使用者快捷連線的語音演算法的微服務。 本書由楊學銳、晏超、劉雪松合作撰寫。三位作者長期在最前線從事語音演算法工作,書中內容彙集了他們在產業界模型訓練和應用實作的思考與經驗複習,希望能給學術界的研究人員與產業界的從業人員帶來一絲啟發和幫助。其中楊學銳負責第1、4、5 章的撰寫及全書內容的審核校對,晏超負責第6、7、8 章的撰寫及工程程式的實現偵錯,劉雪松負責第2、3 章及第1章部分內容的撰寫和校對。 最後,感謝電子工業出版社李淑麗老師的辛苦工作,感謝吳伯庸和王金超對本書的貢獻,感謝陳勇的審稿與校對,感謝成書過程中給予過幫助的所有相關人士。 由於作者水準有限,書中如有任何錯誤與不足,懇請讀者們批評指正並提出寶貴意見。 作者 |