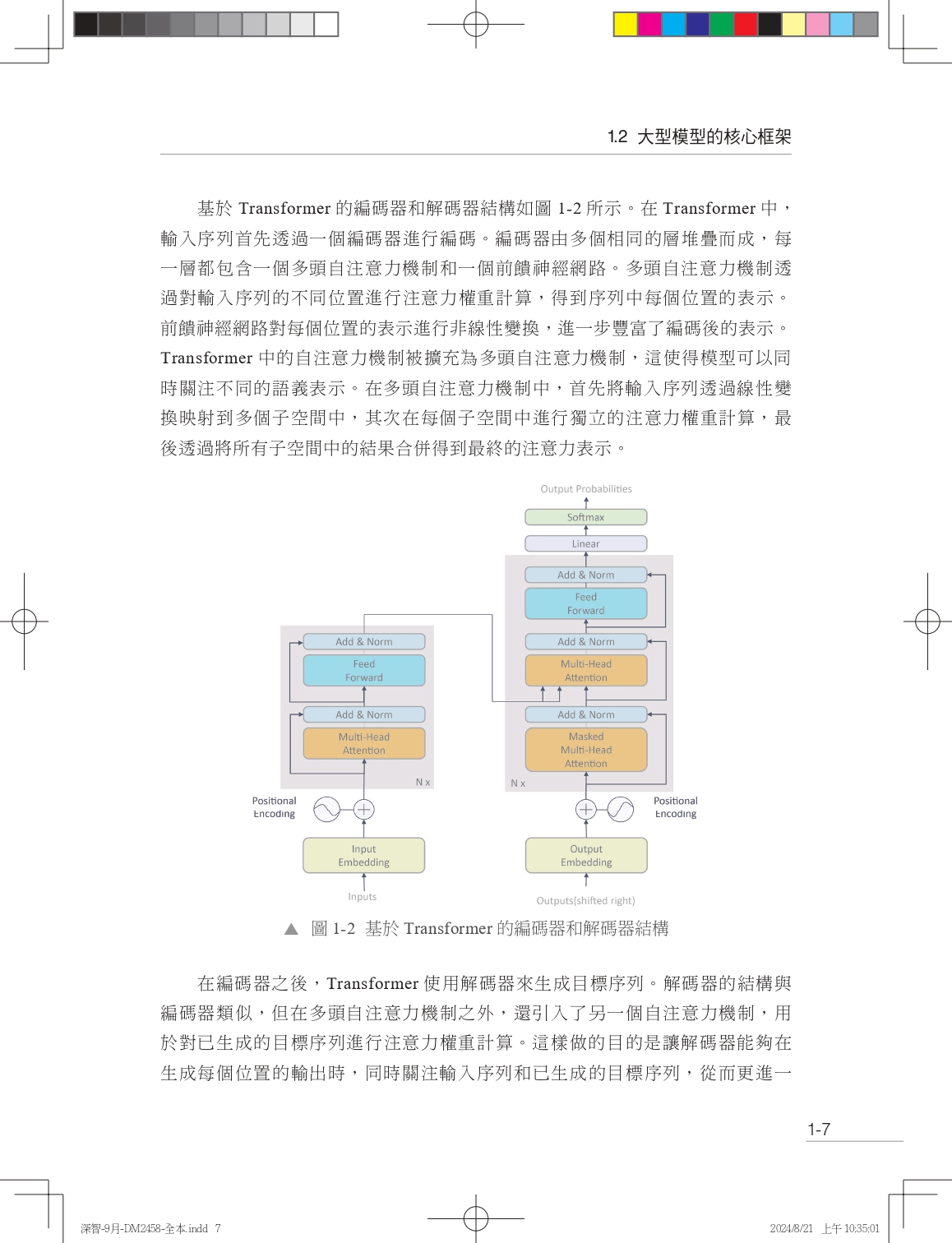
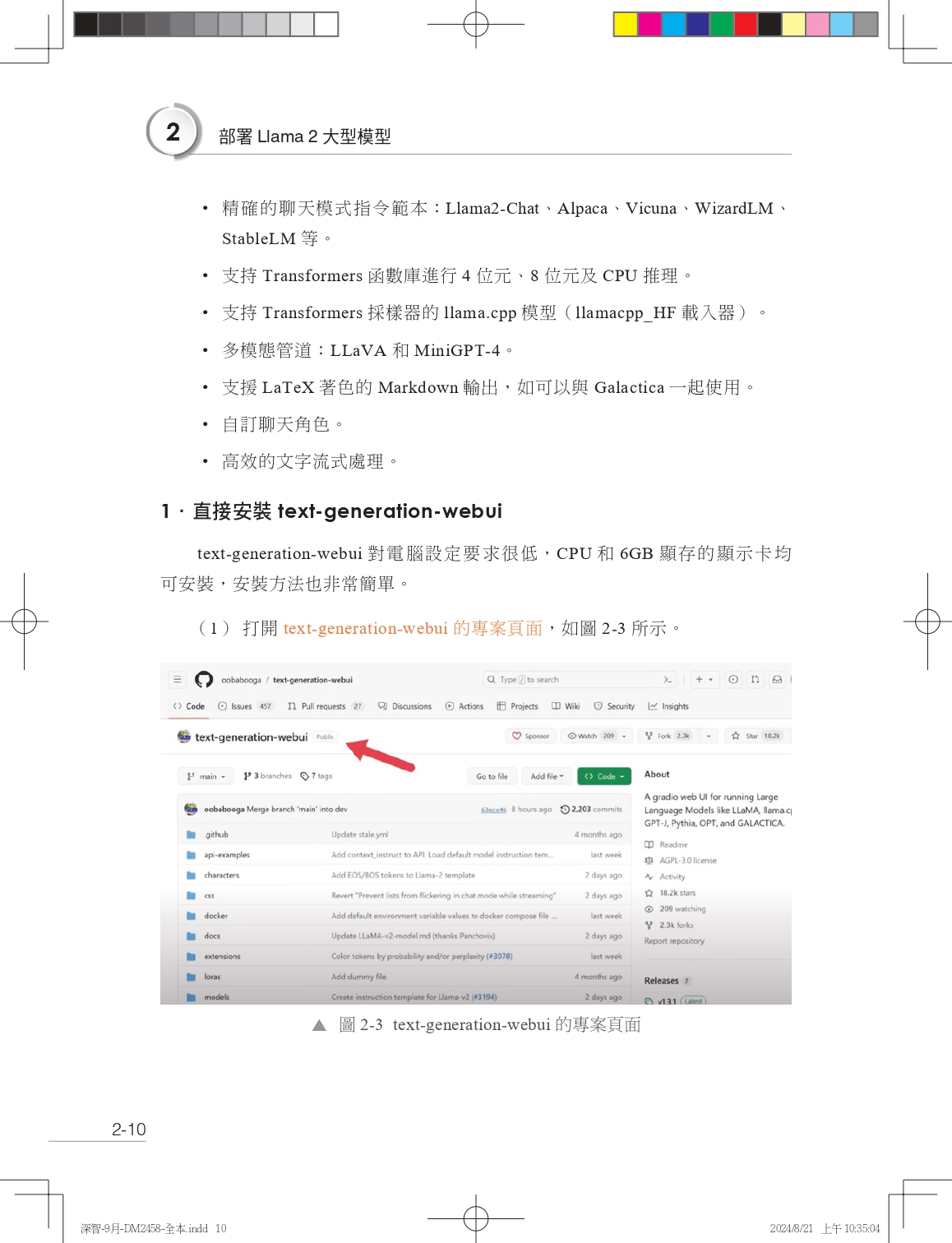
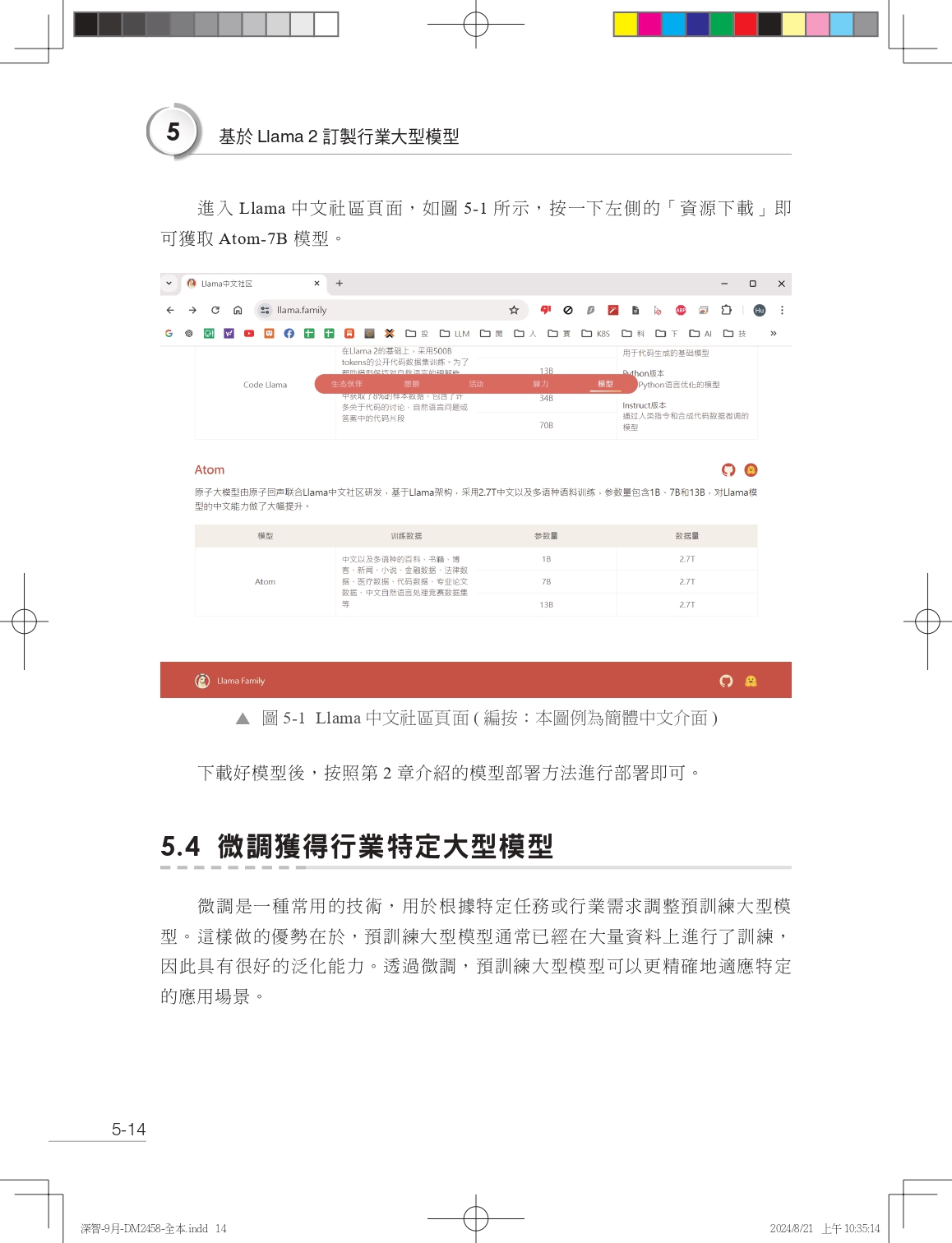
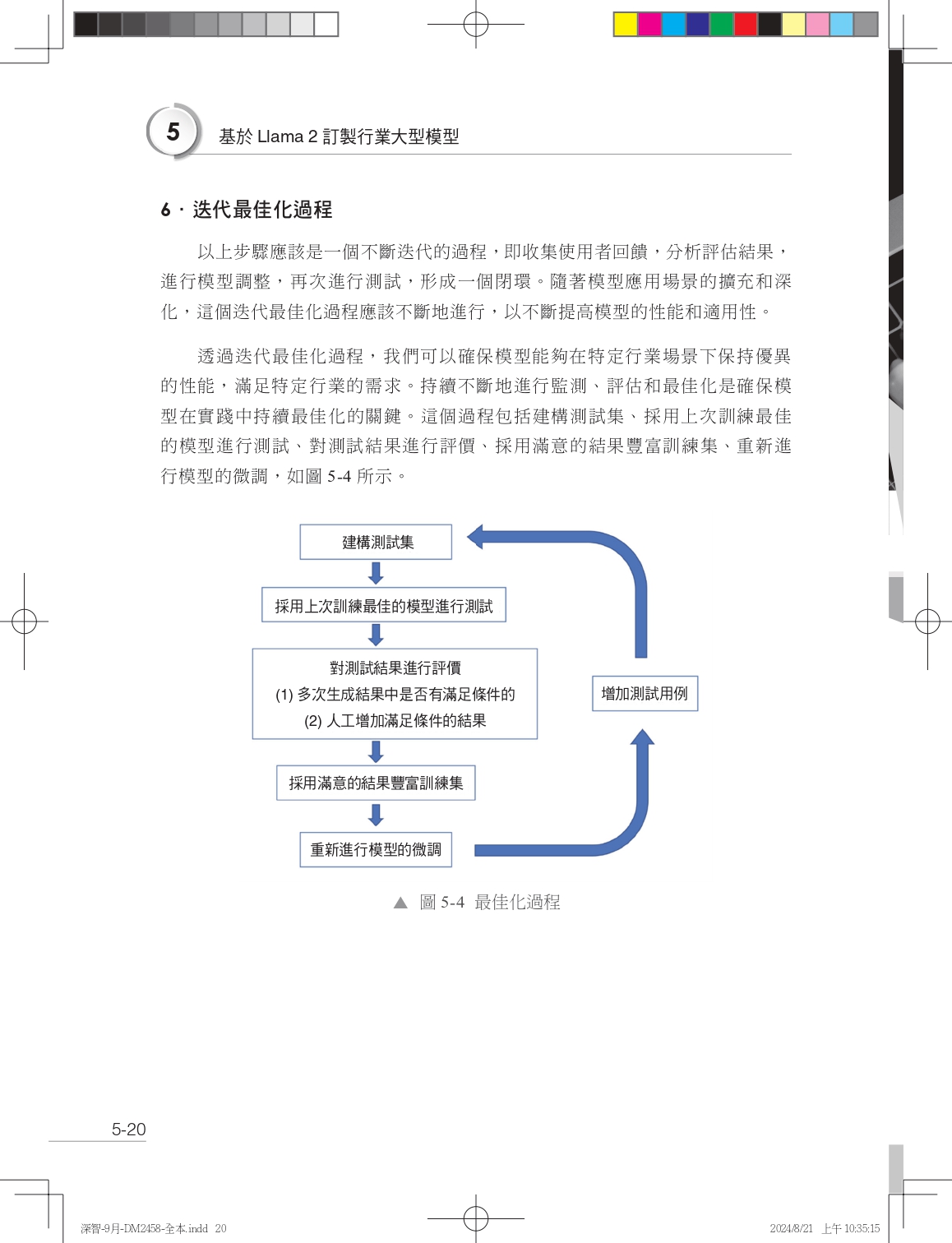
| 序言
目前,人工智慧和自然語言處理領域的發展正處於一個前所未有的黃金時代。預訓練大型模型,如GPT-4和Llama,不僅在學術界引起廣泛注意,還在工業界得到了廣泛應用。作為一支擁有多年研究和實踐經驗的學者團隊,我們深感有責任和義務將這一領域的最新進展和實踐經驗整合到一本全面、實用的指南中,而Llama又是如今備受歡迎、影響廣泛的開源預訓練大型模型,這就是《LLM的大開源時代》誕生的初衷。
本書內容圍繞Llama大型模型展開,涵蓋了從基礎理論到實際應用的全方位內容。我們力求使每章都具有很高的實用性,同時不忽略理論的深度。本書包含大量的程式示例、案例分析和最佳實踐,可以幫助讀者更好地理解和應用Llama大型模型。
本書的一個顯著特點是跨學科性。本書不僅討論了計算機科學和機器學習的基礎概念,還引入了語言學、資訊檢索和人機互動等多個學科的知識。這樣做的目的是讓讀者能夠全面地理解大型模型,以及它們在不同應用場景中的潛力和局限性。
在適用範圍方面,本書既適合剛入門的學生和研究人員閱讀,也適合有多年研究經驗的專家和工程師閱讀。本書盡量以淺顯易懂的語言解釋複雜的概念和算法,同時展示了技術細節並提供了拓展閱讀,以滿足不同讀者的需求。
在寫作分工方面,我們的團隊成員各自負責不同的章節,以確保每一部份都能得到專家級的處理。例如,擁有多年自然語言處理研究經驗的成員主要負責第1章和第7章,這兩章涉及大量的基礎理論和多語言大型模型技術;在工業界有豐富實踐經驗的成員主要負責其他章節,這些章節更側重於實際應用和行業大型模型訂製。
總體而言,我們希望本書能成為讀者探索Llama大型模型世界的可靠指南和實用參考書。無論你是希望深入了解這一領域的最新研究,還是希望將預訓練大型模型應用於實際問題,本書都將為你提供詳細的知識和靈感。
在這個快速發展和不斷變革的時代,讓我們一起探索人工智慧和自然語言處理的無限可能,開啟一個全新的學術和應用之旅!
本書主要內容
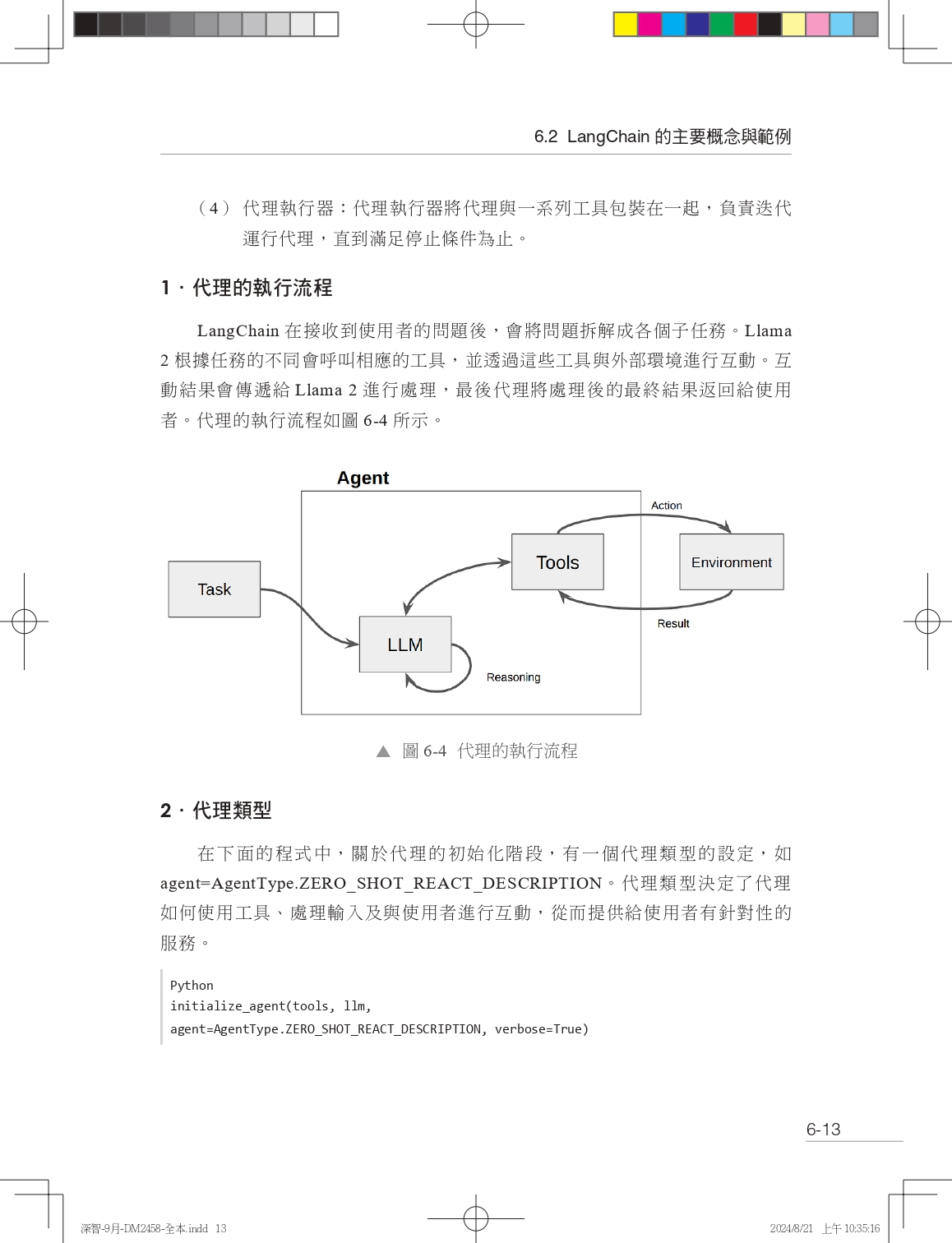
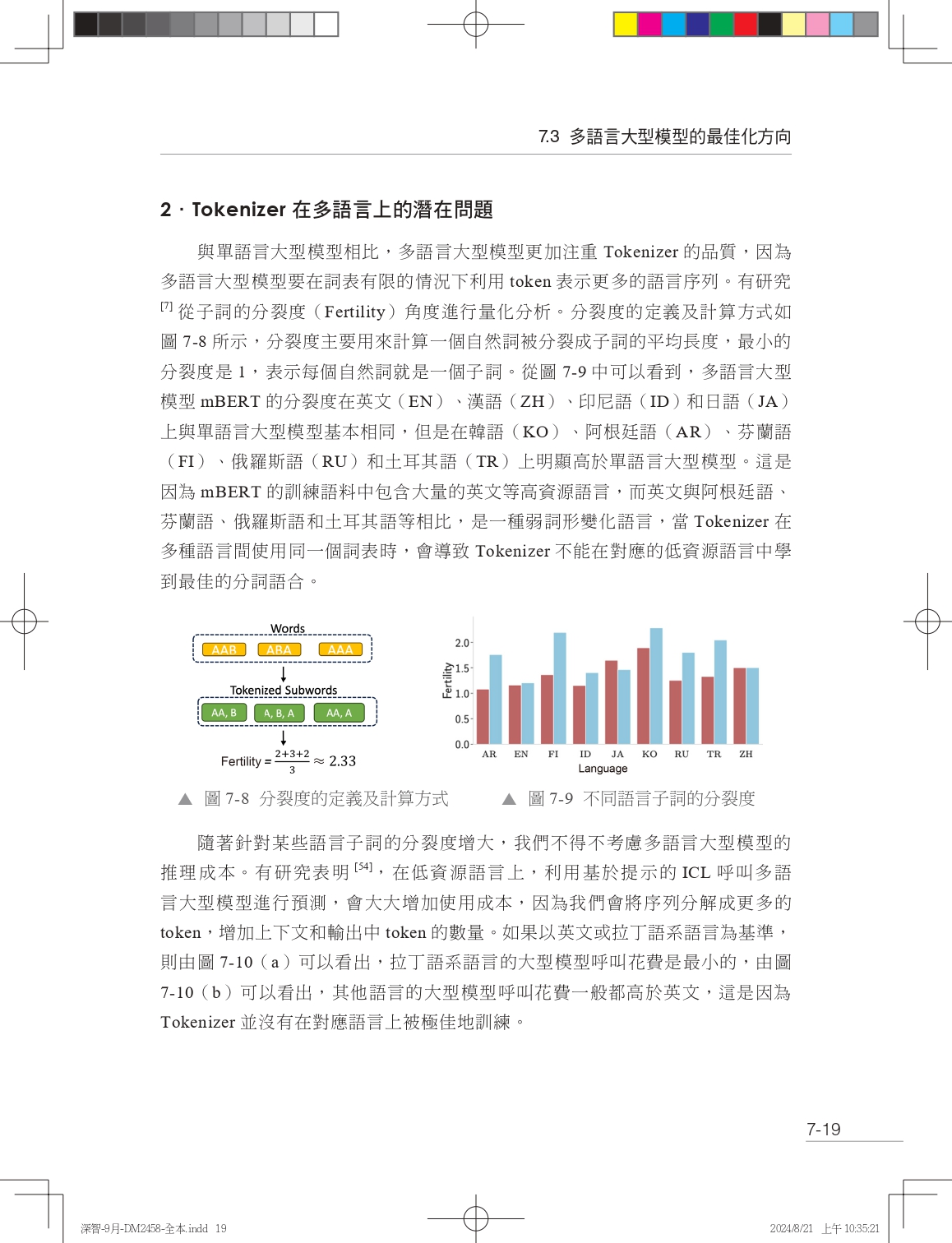
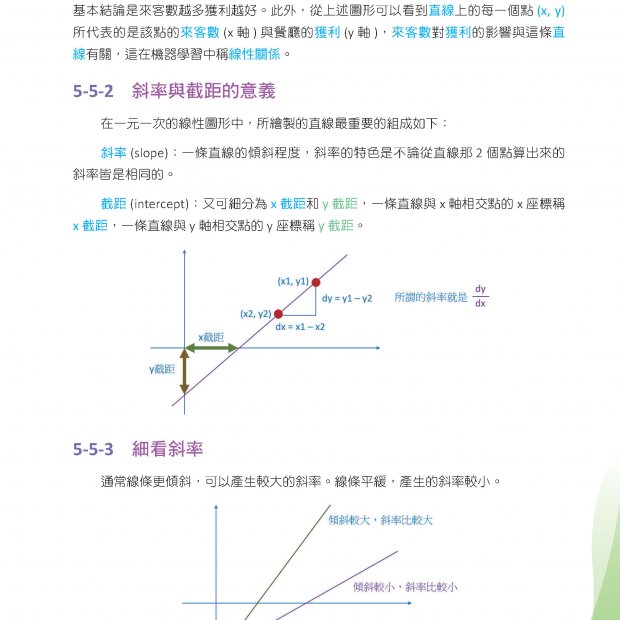
本書共包括7章,涵蓋了從基礎理論到實際應用的全方位內容。第1章深入探討了大型模型的基礎理論。第2章和第3章專注於Llama大型模型的部署和微調,提供了一系列實用的程式示例、案例分析和最佳實踐。第4章介紹了多輪對話難題,這是許多大型模型開發者和研究人員面臨的一大挑戰。第5章探討了如何基於Llama訂製行業大型模型,以滿足特定業務需求。第6章介紹了如何利用Llama和LangChain建構高效的文件問答模型。第7章展示了多語言大型模型的技術細節和應用場景。
本書既適合剛入門的學生和研究人員閱讀,也適合有多年研究經驗的專家和工程師閱讀,透過閱讀本書,讀者不僅能掌握Llama大型模型的核心概念和技術,還能學會如何將這些知識應用於實際問題,從而在這一快速發展的領域中取得優勢。 |