










描述
內容簡介
|
作者簡介
| 王曉華
高校計算機專業講師,研究方向為雲計算、大數據與人工智能。其著作包括《深入探索Mamba模型架構與應用》《PyTorch深度學習與計算機視覺實踐》《PyTorch語音識別實戰》《ChatGLM3大模型本地化部署、應用開發與微調》《新範式來臨 - 用PyTorch了解LLM開發微調ChatGLM全過程》《PyTorch 2.0深度學習從零開始學》《Spark 3.0大數據分析與挖掘:基於機器學習》《TensorFlow深度學習應用實踐》《OpenCV+TensorFlow深度學習與計算機視覺實戰》《TensorFlow語音識別實戰》《TensorFlow 2.0捲積神經網絡實戰》《深度學習的數學原理與實現》。 |
目錄
| ▌第1 章 高性能注意力與多模態融合
1.1 從湧現到飛躍:高性能大模型的崛起 1.1.1 大模型的「湧現」 1.1.2 大模型的發展歷程 1.1.3 高性能大模型的崛起 1.2 大模型的內功:高性能注意力機制的崛起 1.2.1 注意力機制的基本原理 1.2.2 注意力機制的變革與發展 1.2.3 高性能注意力機制崛起:GQA 與MLA 1.3 大模型的外拓:多模態融合 1.3.1 多模態外拓及其挑戰 1.3.2 融合策略與技術概覽 1.3.3 深度學習在多模態融合中的應用場景 1.4 高性能注意力與多模態融合的未來展望 1.4.1 融合技術的創新方向 1.4.2 注意力機制的前端探索 1.5 本章小結
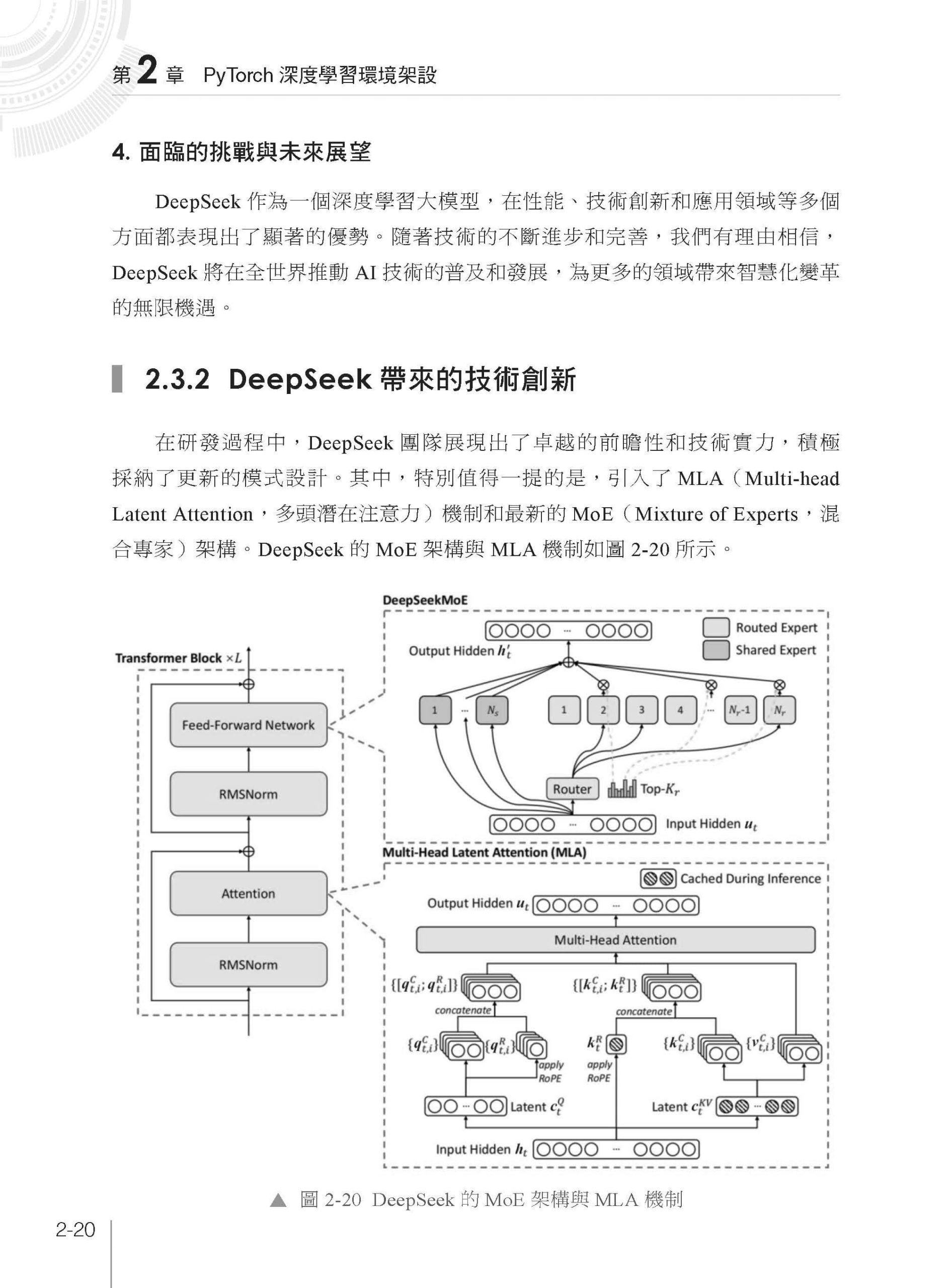
▌第2 章 PyTorch 深度學習環境架設 2.1 安裝Python 開發環境 2.1.1 Miniconda 的下載與安裝 2.1.2 PyCharm 的下載與安裝 2.1.3 計算softmax 函式練習 2.2 安裝PyTorch 2.0 2.2.1 NVIDIA 10/20/30/40 系列顯示卡選擇的GPU 版本 2.2.2 PyTorch 2.0 GPU NVIDIA 執行函式庫的安裝 2.2.3 Hello PyTorch 2.3 多模態大模型DeepSeek 初探與使用 2.3.1 DeepSeek 模型簡介 2.3.2 DeepSeek 帶來的技術創新 2.3.3 DeepSeek 的第三方服務與使用範例 2.4 本章小結
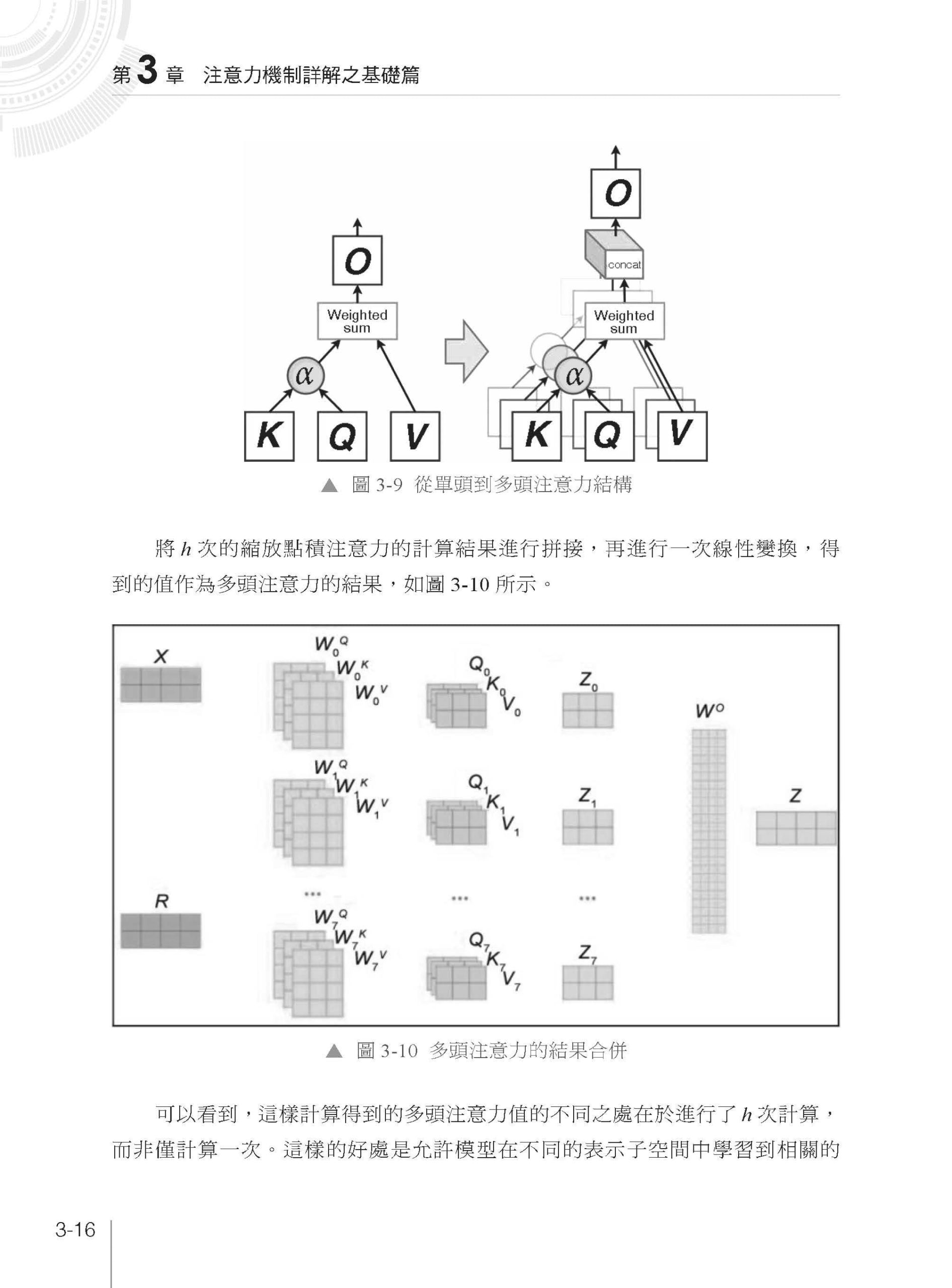
▌第3 章 注意力機制詳解之基礎篇 3.1 注意力機制與模型詳解 3.1.1 注意力機制詳解 3.1.2 自注意力(Self-Attention)機制 3.1.3 自注意力的程式實現 3.1.4 ticks 和Layer Normalization 3.1.5 多頭自注意力 3.2 注意力機制的應用實踐:編碼器 3.2.1 自編碼器的整體架構 3.2.2 回到輸入層:初始詞向量層和位置編碼器層 3.2.3 前饋層的實現 3.2.4 將多層模組融合的TransformerBlock 層 3.2.5 編碼器的實現 3.3 基礎篇實戰:自編碼架構的拼音中文字生成模型 3.3.1 中文字拼音資料集處理 3.3.2 架設文字與向量的橋樑—Embedding 3.3.3 自編碼模型的確定 3.3.4 模型訓練部分的撰寫 3.4 本章小結
▌第4 章 注意力機制詳解之進階篇 4.1 注意力機制的第二種形態:自迴歸架構 4.1.1 自迴歸架構重大突破:旋轉位置編碼 4.1.2 增加旋轉位置編碼的注意力機制與現有函式庫套件的實現 4.1.3 新型的啟動函式SwiGLU 詳解 4.1.4 「因果遮罩」與「錯位」輸入輸出格式詳解 4.2 進階篇實戰1:無須位置表示的飯店評論情感判斷 4.2.1 資料集的準備與讀取 4.2.2 使用sentencepiece 建立文字詞彙表 4.2.3 編碼情感分類資料集 4.2.4 基於新架構文字分類模型設計 4.2.5 情感分類模型的訓練與驗證 4.3 進階篇實戰2:基於自迴歸模型的飯店評論生成 4.3.1 資料集的準備與讀取 4.3.2 基於自迴歸文字生成模型的設計 4.3.3 評論生成模型的訓練 4.3.4 使用訓練好的模型生成評論 4.4 本章小結
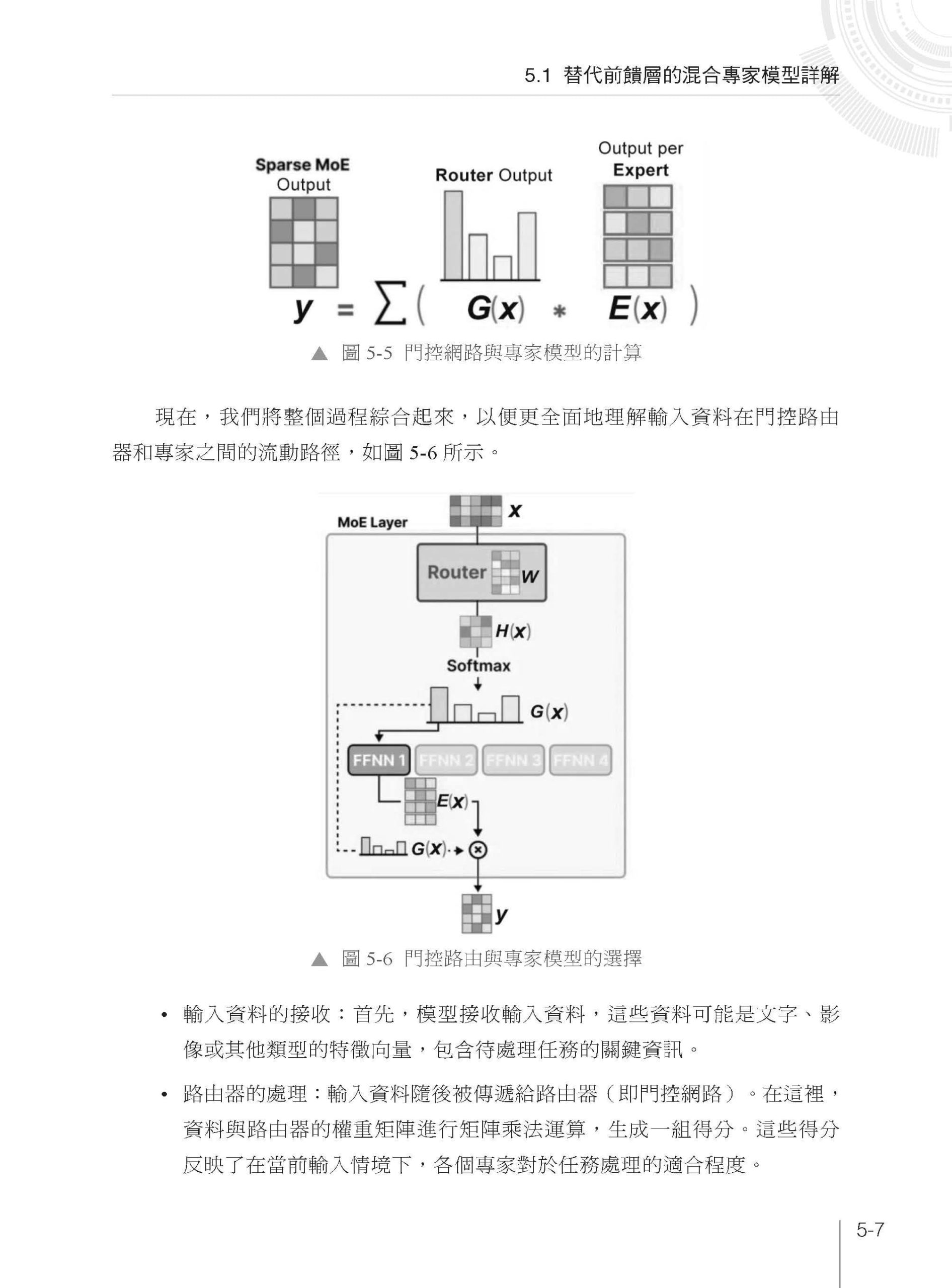
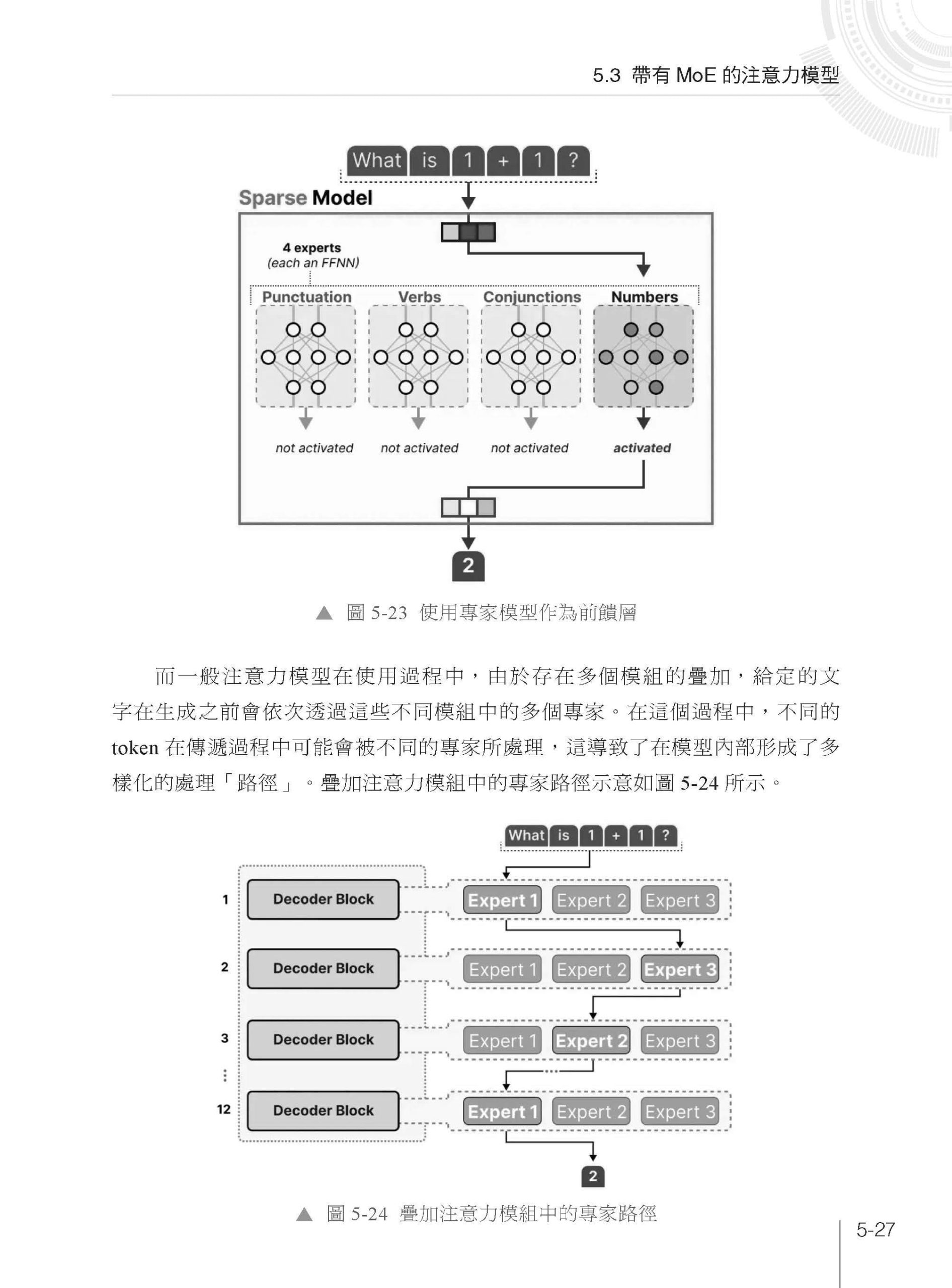
▌第5 章 注意力機制詳解之高級篇 5.1 替代前饋層的混合專家模型詳解 5.1.1 混合專家模型的基本結構 5.1.2 混合專家模型中的「專家」與「調控」程式實現 5.2 高級篇實戰1:基於混合專家模型的情感分類實戰 5.2.1 基於混合專家模型的MoE 評論情感分類實戰 5.2.2 混合專家模型中負載平衡的實現 5.2.3 修正後的MoE 門控函式 5.3 帶有MoE 的注意力模型 5.3.1 注意力機制中的前饋層不足 5.3.2 MoE 天然可作為前饋層 5.3.3 結合MoE 的注意力機制 5.4 高級篇實戰2:基於通道注意力的影像分類 5.4.1 資料集的準備 5.4.2 影像辨識模型的設計 5.4.3 結合通道注意力圖像分類模型 5.4.4 影像辨識模型SENet 的訓練與驗證 5.5 高級篇實戰3:基於MoE 與自注意力的影像分類 5.5.1 基於注意力機制的ViT 模型 5.5.2 Patch 和Position Embedding 5.5.3 視覺化的V-MoE 詳解 5.5.4 V-MoE 模型的實現 5.5.5 基於影像辨識模型V-MoE 的訓練與驗證 5.5.6 使用已有的函式庫套件實現MoE 5.6 本章小結
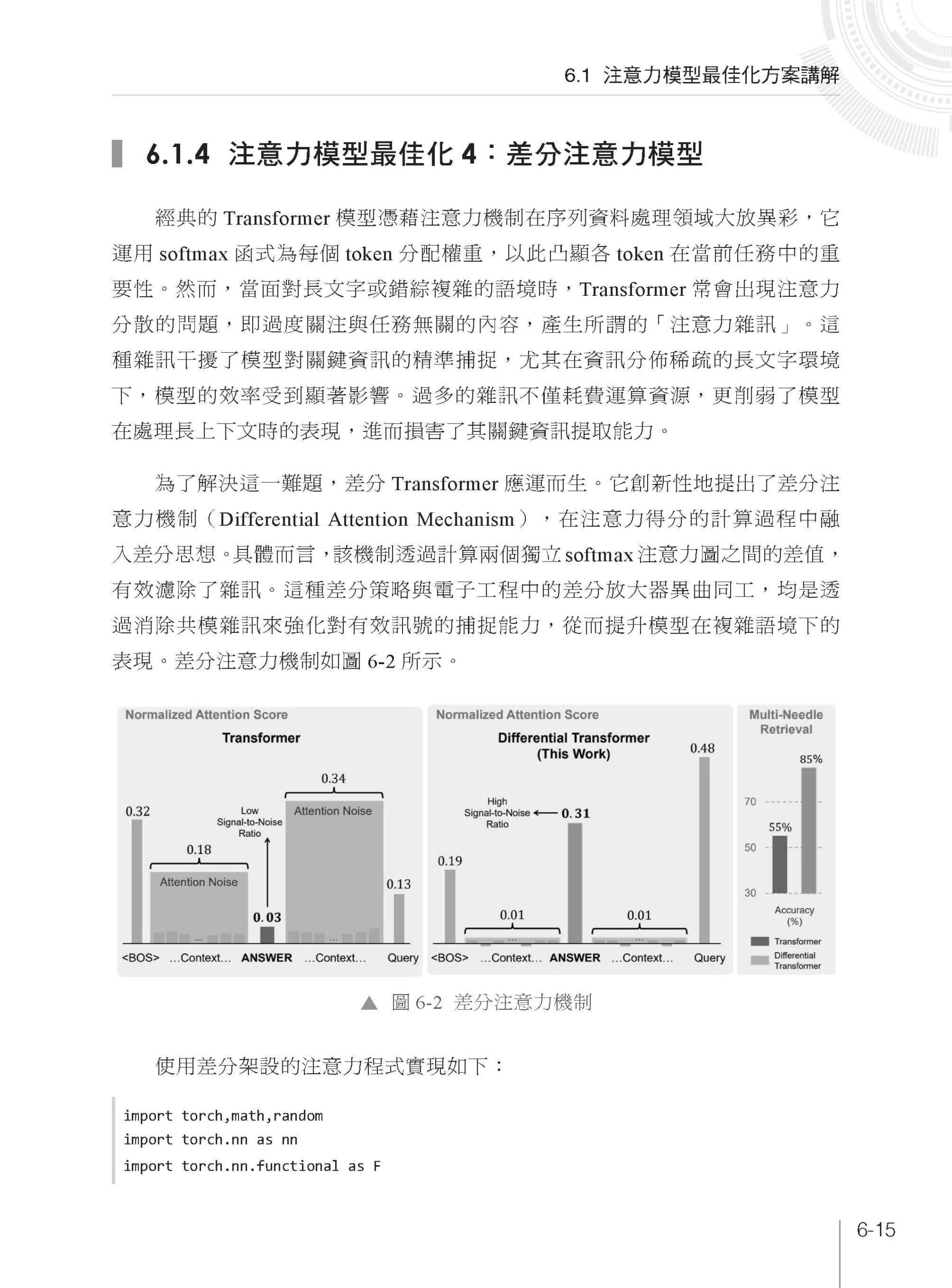
▌第6 章 注意力機制詳解之調優篇 6.1 注意力模型最佳化方案講解 6.1.1 注意力模型最佳化1:MQA 模型 6.1.2 注意力模型最佳化2:MLA 模型 6.1.3 注意力模型最佳化3:GQA 模型 6.1.4 注意力模型最佳化4:差分注意力模型 6.2 調優篇實戰1:基於MLA 的人類語音情感分類 6.2.1 情緒資料的獲取與標籤的說明 6.2.2 情緒資料集的讀取 6.2.3 語音情感分類模型的設計和訓練 6.3 本章小結
▌第7 章 旅遊特種兵迪士尼大作戰:DeepSeek API呼叫與高精準路徑最佳化 7.1 基於線上API 的大模型呼叫 7.1.1 DeepSeek 的註冊與API 獲取 7.1.2 帶有特定格式的DeepSeek 的API 呼叫 7.1.3 帶有約束的DeepSeek 的API 呼叫 7.2 智慧化DeepSeek 工具呼叫詳解 7.2.1 Python 使用工具的基本原理 7.2.2 在DeepSeek 中智慧地使用工具 7.2.3 在DeepSeek 中選擇性地使用工具 7.2.4 DeepSeek 工具呼叫判定依據 7.3 旅遊特種兵迪士尼大作戰:DeepSeek 高精準路徑最佳化 7.3.1 遊樂場資料的準備 7.3.2 普通大模型的迪士尼遊玩求解攻略 7.3.3 基於動態規劃演算法的迪士尼遊玩求解攻略 7.3.4 基於DeepSeek 的旅遊特種兵迪士尼大作戰 7.4 本章小結
▌第8 章 廣告文案撰寫實戰:多模態DeepSeek 當地語系化部署與微調 8.1 多模態DeepSeek-VL2 當地語系化部署與使用 8.1.1 Linux 版本DeepSeek-VL2 程式下載與影像問答 8.1.2 Windows 版本DeepSeek-VL2 程式下載 8.2 廣告文案撰寫實戰1:PEFT 與LoRA 詳解 8.2.1 微調的目的:讓生成的結果更聚焦於任務目標 8.2.2 微調經典方法LoRA 詳解 8.2.3 調配DeepSeek 微調的輔助函式庫PEFT 詳解 8.3 廣告文案撰寫實戰2:當地語系化DeepSeek-VL2 微調 8.3.1 資料的準備 8.3.2 微調模型的訓練 8.3.3 微調模型的使用與推斷 8.4 本章小結
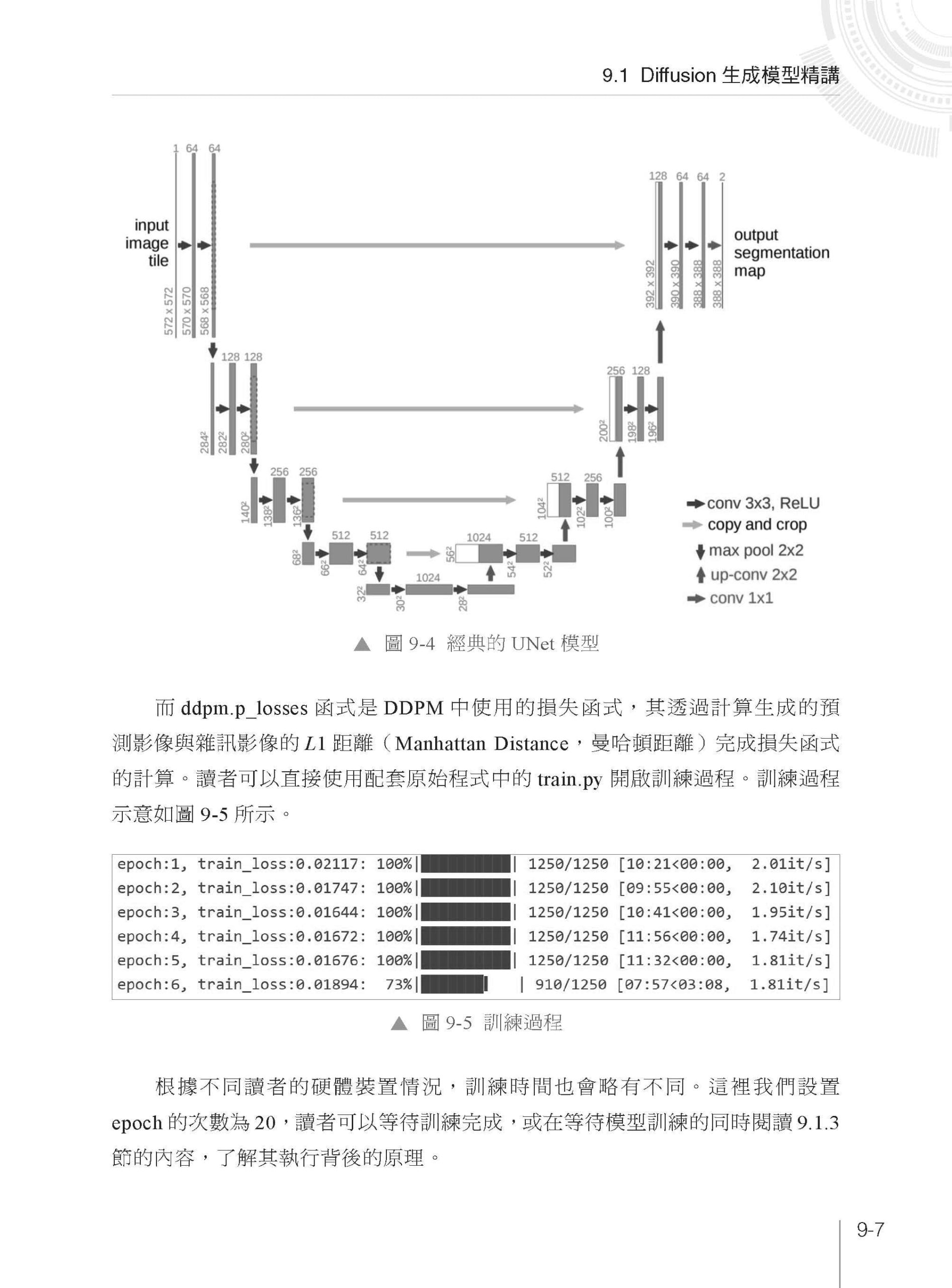
▌第9 章 注意力與特徵融合範式1:Diffusion 可控影像生成 9.1 Diffusion 生成模型精講 9.1.1 Diffusion Model 的精講 9.1.2 直接執行的經典DDPM 的模型訓練實戰 9.1.3 DDPM 的模型基本模組說明 9.1.4 DDPM 加噪與去噪詳解:結合成功執行的擴散模型程式 9.1.5 DDPM 的損失函式:結合成功執行的Diffusion Model 程式 9.2 可控影像生成實戰:融合特徵的注意力機制 9.2.1 擴散模型可控生成的基礎:特徵融合 9.2.2 注意力MQA 中的可控特徵融合 9.2.3 基於注意力的擴散模型的設計 9.2.4 影像的加噪與模型訓練 9.2.5 基於注意力模型的可控影像生成 9.3 本章小結
▌第10 章 注意力與特徵融合範式2:多模態圖文理解與問答 10.1 多模態圖文問答實戰 10.1.1 一種新的多模態融合方案 10.1.2 資料集的設計與使用 10.1.3 多模態融合資料集的訓練 10.1.4 多模態圖文問答的預測 10.2 更多的多模態融合方案 10.2.1 一種截斷的多模態融合方案 10.2.2 截斷後多模態模型的訓練與預測 10.2.3 一種加法基礎的多模態融合方案 10.3 本章小結
▌第11 章 注意力與特徵融合範式3:交叉注意力語音轉換 11.1 點對點語音辨識任務簡介 11.1.1 點對點的語音辨識 11.1.2 中文語音文字資料集說明 11.2 點對點音訊特徵提取函式庫librosa 的使用 11.2.1 音訊訊號的基本讀取方法 11.2.2 多特徵音訊取出 11.3 點對點語音辨識任務簡介 11.3.1 全中文音訊資料集的準備 11.3.2 音訊特徵的提取與融合 11.3.3 基於生成模型的點對點語音辨識任務 11.3.4 點對點語音辨識任務的訓練與預測 11.4 基於PyTorch 的資料處理與音訊特徵融合 11.4.1 THCHS30 資料集的處理 11.4.2 基於torchaudio 的音訊前置處理 11.4.3 基於不同角度的音訊特徵獲取和簡單融合 11.4.4 關於特徵融合的講解 11.5 用於特徵融合的交叉注意力 11.5.1 交叉注意力詳解 11.5.2 帶有遮罩的交叉注意力 11.5.3 完整的帶有遮罩的交叉注意力點對點語音辨識 11.5.4 基於交叉注意力的點對點語音辨識的訓練與預測 11.5.5 基於連接concat 的點對點語音辨識模型 11.6 本章小結
▌第12 章 多模態特徵token 壓縮 12.1 影像特徵壓縮的多種實現 12.1.1 Pixel-Shuffle 的token 壓縮 12.1.2 Cross-layer Token Fusion 壓縮 12.1.3 AvgPool 的token 壓縮 12.2 基於AvgPool 與自編碼器的語音辨識 12.2.1 修改後的AvgPool 函式 12.2.2 自編碼器語音辨識模型1:資料準備 12.2.3 自編碼器語音辨識模型2:模型設計 12.2.4 自編碼器語音辨識模型3:模型的訓練與預測 12.3 本章小結
▌第13 章 從二維到一維:影像編碼器詳解與圖形重建實戰 13.1 影像編碼器 13.1.1 從自然語言處理講起 13.1.2 影像的編碼與解碼VQ-VAE 13.1.3 為什麼VQ-VAE 採用離散向量 13.1.4 VQ-VAE 的核心實現 13.2 基於VQ-VAE 的手寫體生成 13.2.1 影像的準備與超參數設置 13.2.2 VQ-VAE 的編碼器與解碼器 13.2.3 VQ-VAE 的模型設計 13.2.4 VQ-VAE 的訓練與預測 13.2.5 獲取編碼後的離散token 13.3 基於FSQ 的人臉生成 13.3.1 FSQ 演算法簡介與實現 13.3.2 人臉資料集的準備 13.3.3 基於FSQ 的人臉重建方案 13.3.4 基於FSQ 的人臉輸出與離散token 13.4 基於FSQ 演算法的語音儲存 13.4.1 無監督條件下的語音儲存 13.4.2 可作為密碼機的離散條件下的語音辨識 13.5 本章小結
▌第14 章 基於PyTorch 的點對點視訊分類實戰 14.1 視訊分類資料集的準備 14.1.1 HMDB51 資料集的準備 14.1.2 視訊抽幀的處理 14.1.3 基於PyTorch 的資料登錄 14.2 注意力視訊分類實戰 14.2.1 對於視訊的Embedding 編碼器 14.2.2 視訊分類模型的設計 14.2.3 視訊分類模型的訓練與驗證 14.3 使用預訓練模型的視訊分類 14.3.1 torchvision 簡介 14.3.2 基於torchvision 的點對點視訊分類實戰 14.4 本章小結
▌第15 章 基於DeepSeek 的跨平臺智慧客服開發實戰 15.1 智慧客服的設計與基本實現 15.1.1 智慧客服架設想法 15.1.2 商品介紹資料的格式與說明 15.1.3 基於DeepSeek 的智慧客服設計 15.2 帶有跨平臺使用者端的智慧客服開發實戰 15.2.1 跨平臺使用者端Gradio 使用詳解 15.2.2 一個簡單的Gradio 範例 15.2.3 基於DeepSeek 的跨平臺智慧客服實現 15.3 本章小結 |
序
| 前言
多模態大模型DeepSeek 以其卓越的技術與出色的性能,在人工智慧領域熠熠生輝,成為一顆璀璨的明珠。其成功的秘訣在於對注意力機制的突破性創新與MoE 創新架構的巧妙運用,為人工智慧領域帶來了前所未有的變革。 DeepSeek 不僅在理論上獲得了顯著突破,更在實際應用中展現出其強大的能力。透過高效融合多種模態的資料,DeepSeek 在影像辨識、自然語言處理、語音辨識等領域均獲得了令人矚目的成果,為人工智慧的多元化應用提供了強大的支援。 在此背景下,本書深入剖析注意力機制與多模態融合的基本原理,全面展示它們的技術概況,並結合豐富的應用案例,展望這兩大技術的未來發展趨勢。透過架設PyTorch 深度學習環境,讀者可以親自動手實踐書中的豐富案例,從而在實踐中更深入地理解這兩大技術的精髓,並提高大模型應用程式開發能力。 本書不僅適合深度學習初學者、工程師、研究者、學校的師生閱讀,也適合想要掌握最新注意力機制與多模態融合技術的高等院校師生閱讀。
▍本書目的 當前,高性能大模型DeepSeek 備受矚目,而其背後的注意力機制與多模態融合技術更是成為深度學習研究領域的熱點。本書致力於成為讀者全面掌握DeepSeek 核心技術的寶典,透過深入淺出的原理講解與實例分析,引導讀者系統學習DeepSeek 的核心原理、架構及應用程式開發方法。 本書深入剖析了DeepSeek 的核心技術——多頭潛在注意力(MLA)與混合專家模型(MoE),詳細闡述它們的工作原理與技術優勢。此外,本書還詳細探討DeepSeek 中的多模態融合方法,結合豐富的API 應用實例,為讀者提供全面的理論與實踐指導,助力讀者深入理解高性能大模型的運行機制。 透過本書的學習,讀者不僅能全面理解DeepSeek 中的高性能注意力機制與多模態融合技術,更能熟練地將這些知識應用於情感分類、影像辨識、語音辨識、文字生成、影像生成、圖文問答、視訊分類、智慧客服等實際場景中,從而在深度學習領域取得顯著的進步。
▍本書內容安排 第1 章,高性能注意力與多模態融合。本章首先介紹以DeepSeek 為代表的高性能大模型的崛起,並深入探討注意力機制的發展,闡述其基本原理、發展變種以及在多架構中高性能的崛起。緊接著,我們探討多模態融合,包括其面臨的挑戰、融合策略與技術概覽、應用場景。最後,我們將展望多模態融合與注意力的未來發展方向,探討它們潛在的創新與前端技術。 第2 章,PyTorch 深度學習環境架設。本章指導讀者架設PyTorch 深度學習環境,包括Python 開發環境的安裝、PyTorch 2.0 的安裝與配置,以及多模態大模型DeepSeek 的用法。透過本章的學習,讀者將能夠熟悉PyTorch 的基本操作,為多模態融合與注意力機制的研究打下基礎。 第3 章,注意力機制詳解之基礎篇。注意力機制在深度學習中發揮著越來越重要的作用,本章將詳細介紹注意力機制的基本原理,包括自注意力機制、ticks 和Layer Normalization、多頭自注意力等關鍵概念。此外,我們還將透過編碼器這一應用實踐,展示注意力機制在實際任務中的運用。最後,透過一個實戰案例——自編碼架構的拼音中文字生成模型,讀者將進一步加深對注意力機制的理解。 第4 章,注意力機制詳解之進階篇。在基礎篇的基礎上,本章將進一步探討注意力機制的進階應用。我們將介紹自迴歸架構這一重要形態,包括旋轉位置編碼、新型啟動函數SwiGLU 等關鍵技術。此外,還將透過兩個實戰案例—無須位置表示的飯店評論情感判斷與基於自迴歸模型的飯店評論生成,展示注意力機制在文字處理任務中的強大能力。 第5 章,注意力機制詳解之高級篇。結合DeepSeek 基本架構,高級篇將深入探討注意力機制的更高級應用。我們將首先介紹替代前饋層的混合專家(MoE)模型,闡述其基本結構與實現方式。緊接著,透過兩個實戰案例—基於MoE 模型的情感分類與帶有MoE 的注意力模型,展示混合專家模型在提升注意力機制性能方面的潛力。最後,我們還將探討基於通道注意力的影像分類技術,進一步拓展注意力機制的應用領域。 第6 章,注意力機制詳解之調優篇。調優是提升深度學習模型性能的關鍵環節。本章將介紹針對注意力模型的多種最佳化方案,包括MQA 模型、MLA模型、GQA 模型以及差分注意力模型等。此外,還將透過一個實戰案例—基於MLA 的人類語音情感分類,展示最佳化方案在實際任務中的應用效果。而MLA注意力模型本身也是DeepSeek 取得成功的關鍵模組。 第7 章,旅遊特種兵迪士尼大作戰:DeepSeek API 呼叫與高精準路徑最佳化。本章將詳細介紹DeepSeek 大語言模型線上API 的呼叫方法。我們將從帳戶註冊開始,逐步講解API 金鑰的獲取、基礎對話流程的建立,並透過一個具體案例展示其強大的應用能力——旅遊特種兵迪士尼大作戰。 第8 章,廣告文案撰寫實戰:多模態DeepSeek 當地語系化部署與微調。本 章將實現基於多模態大模型DeepSeek 的當地語系化部署,並對模型的應用進行深入探索。針對Windows 系統環境下的DeepSeek-VL2,我們將詳細闡述額外安裝和編譯包的必要步驟,確保模型能夠在該系統上順利運行。為了進一步提升模型的調配性,使其能夠更進一步地服務於特定的輸出任務,我們深入講解了PEFT(參數高效微調)與LoRA(低秩調配)這兩種先進的微調方法。透過這些精細化的調整和最佳化,我們在推斷階段獲得了顯著成效,並完成了廣告文案撰寫的實戰案例。 第9~15 章,多模態大模型應用程式開發實戰。這7 章分別探討注意力與特徵融合在不同領域的應用範式與實戰案例。從Diffusion 可控影像生成到多模態圖文理解與問答,再到交叉注意力語音轉換和DeepSeek 智慧客服應用程式開發等任務,我們將詳細闡述注意力與特徵融合技術的實現細節與應用效果。透過影像生成、圖文問答、語音轉換、特徵壓縮、影像編碼、視訊分類、智慧客服等實戰案例的學習,讀者將能夠更深入地理解注意力與特徵融合在實際問題中的解決方案與實現過程。
▍本書特點 (1)結構清晰,條理分明:本書按照主題進行章節劃分,從基礎概念到高級應用,逐步深入。每一章都圍繞一個核心主題展開,如「高性能注意力與多模態融合」「PyTorch 深度學習環境架設」等,使得讀者能夠循序漸進地學習和掌握相關知識。 (2)理論與實踐相結合:書中不僅詳細闡述了深度學習中的注意力機制與多模態融合的理論知識,還透過大量的實戰案例,指導讀者如何將理論應用到DeepSeek 大模型應用程式開發中。這種理論與案例實踐相結合的方式,有助讀者更進一步地理解和掌握所學的內容。 (3)內容豐富,涵蓋面廣:本書涵蓋深度學習的多個方面,包括多模態融合、注意力機制的各種形態、模型最佳化等。此外,還涉及影像、文字、語音等多種資料型態,為讀者提供了全面的學習資源。 (4)注重前端技術與創新:本書詳細介紹了深度學習領域的最新技術和創新方向,如多模態大模型、混合專家模型等。這使得讀者能夠緊接技術發展的步伐,了解並掌握深度學習最前端的知識。 (5)語言通俗易懂,適合不同層次的讀者:本書採用通俗易懂的語言進行闡述,避免使用過於晦澀難懂的術語。這使得初學者和有一定基礎的讀者,都能夠輕鬆理解並掌握書中的內容。 (6)案例豐富,操作性強:本書提供了大量的實戰案例,包括影像生成、圖文問答、語音轉換、特徵壓縮、影像編碼、視訊分類、智慧客服等。這些案例不僅具有代表性,而且具有很強的操作性,能夠幫助讀者在實際操作中鞏固所學知識。
▍本書適合的讀者 • DeepSeek 應用程式開發初學者:對於使用DeepSeek 應用程式開發的初學者,本書詳細講解DeepSeek 高性能的核心技術以及DeepSeek 應用程式開發方法,引導讀者快速入門大模型開發。 • 高性能注意力機制與多模態融合初學者:對於深度學習初學者,本書以清晰的結構、理論與實踐相結合、豐富的內容和前端技術介紹,為讀者提供了一本極具價值的深度學習入門指南。 • 深度學習研究者與開發人員:對於在深度學習領域工作的研究者、工程師和開發者,本書提供了關於融合技術和注意力機制的深入理解和實踐指導,有助他們在相關專案中取得更好的成果。 • DeepSeek 大模型原理和架構研究者:對於具有一定深度學習基礎知識的研究者,本書詳細講解了DeepSeek 內部原理和運作架構。透過閱讀本書,讀者能夠更加了解DeepSeek 模型的設計思想、工作原理以及各組成部分之間的協作作用。 • 資料科學家和機器學習工程師:對於處理多模態資料(如文字、影像、音訊等)的資料科學家和機器學習工程師,本書提供了豐富的多模態應用案例,有助他們拓寬視野,提升技能。 • 人工智慧專業學生與同好:本書適合作為人工智慧、機器學習或深度學習相關課程的高級教材或參考書,有助學生深入理解多模態融合與注意力機制的原理和應用。
▍作者與鳴謝 本書作者王曉華為大專院校電腦專業教師,擔負資料探勘、人工智慧、資料結構等多項大學及所究所學生課程,研究方向為資料倉儲與資料探勘、人工智慧、機器學習,在研和參研多項科學研究項目。 本書的順利出版離不開清華大學出版社各位老師的幫助,在此表示感謝。
作者 |