





描述
內容簡介
| ★NLP始祖N-Gram,Bag-of-Words詳細說明介紹實作
☆進入神經網路時代的Word2Vec、NPLM、RNN詳解及實作 ★序列至序列的神器Seq2Seq詳解及實作 ☆抓住字與字之間的關鍵Attention Mechanism詳解及實作 ★成為大神的Transformer詳解及實作 ☆第一個通用語言模型BERT詳解及實作 ★生成式語言模型GPT詳解及實作 ☆ChatGPT應用詳解及實作 ★最新一代GPT-4詳解及實作
全書從最基本的N-Gram 和簡單文字表示Bag-of-Words開始說明NLP的應用,接著進入NLP領域中最重要的隱空間表示法Word2Vec,正式進入了多維向量Embedding表示語義的年代。之後接連介紹了神經網路表示法RNN,以及將encoder及decoder連接的Seq2seq。本書最大的特色就是花了很大的篇幅介紹了注意力機制,詳解了大家最想不通的QKV查詢。在了解了注意力機制之後,就進入最重要的成神Transformer階段,並且帶有說明及完整的實作。最重要的Transformer解決之後,接下來就是強大應用的展現,包括了NLU的BERT說明及實作,以及現今AI基本GPT(屬於NLG)的自迴歸模型。本書也實作了自己使用維基文字生成的GPT模型,讓讀者一探AI一路走來的技術堆疊。最後一章更把目前當紅的ChatGPT所使用的RHLF技術完整走一遍,也使用了OpenAI的API來完成實作。 |
作者簡介
|
目錄
| 序章 看似尋常最崎崛,成如容易卻艱辛
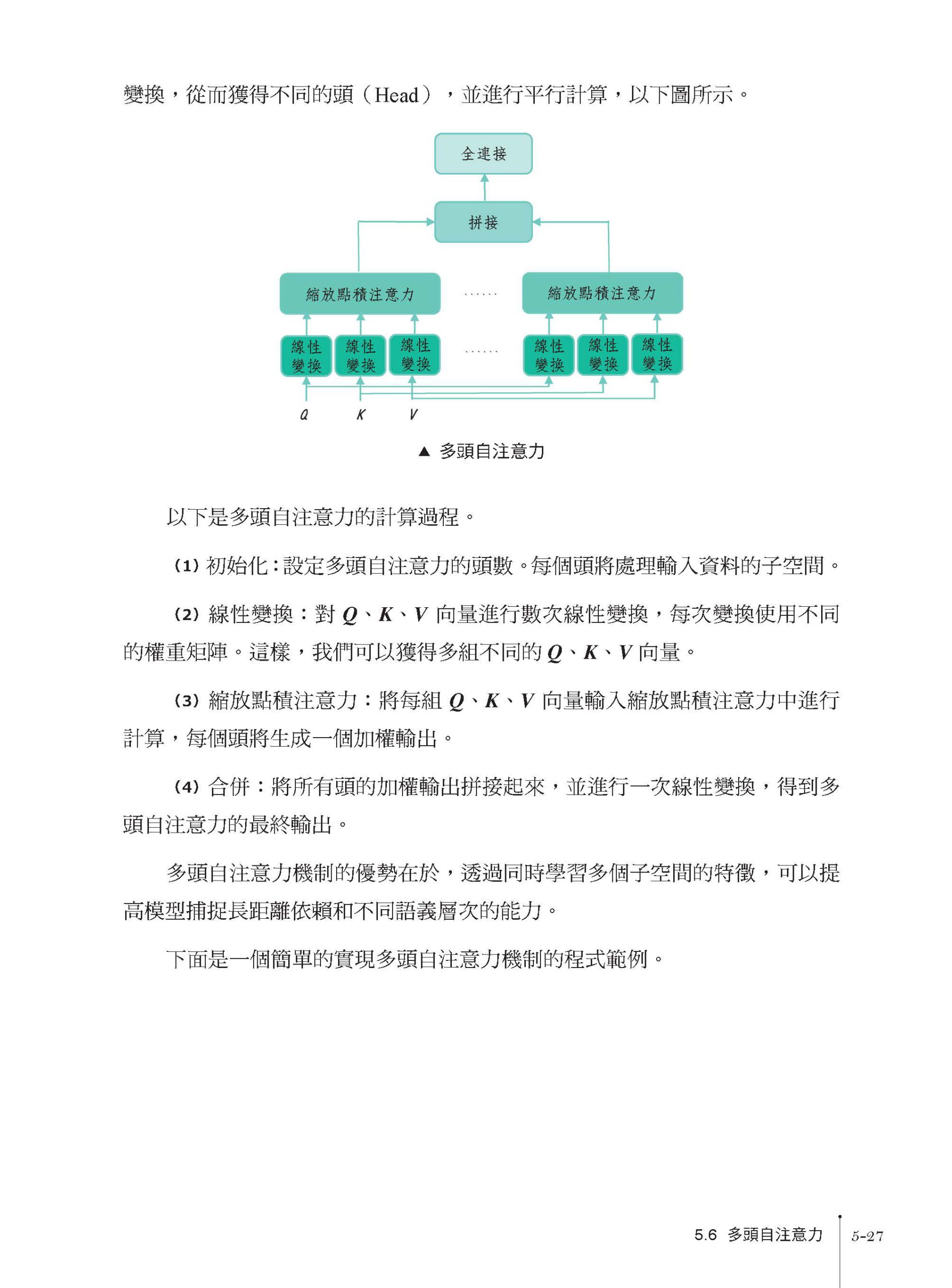
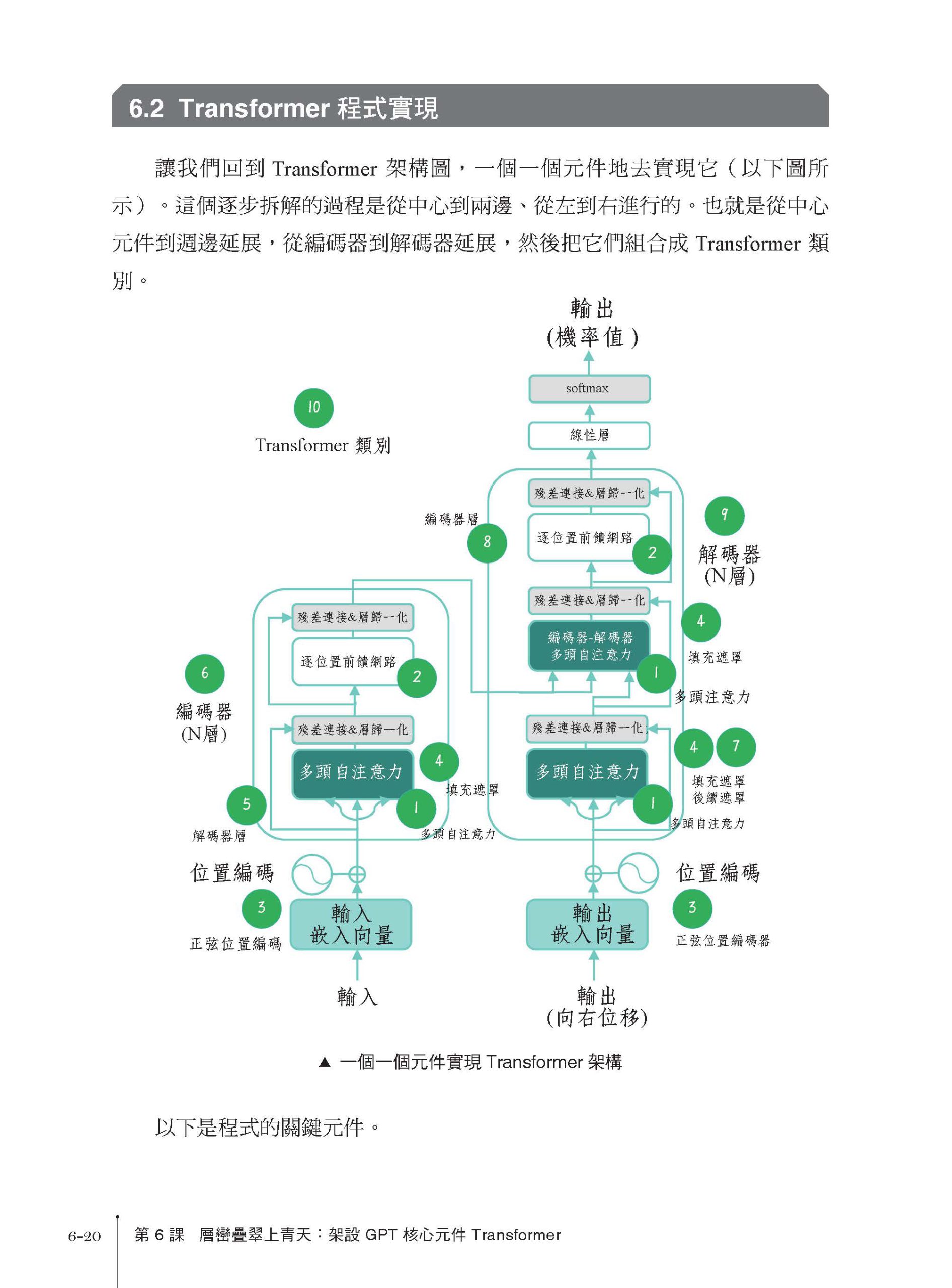
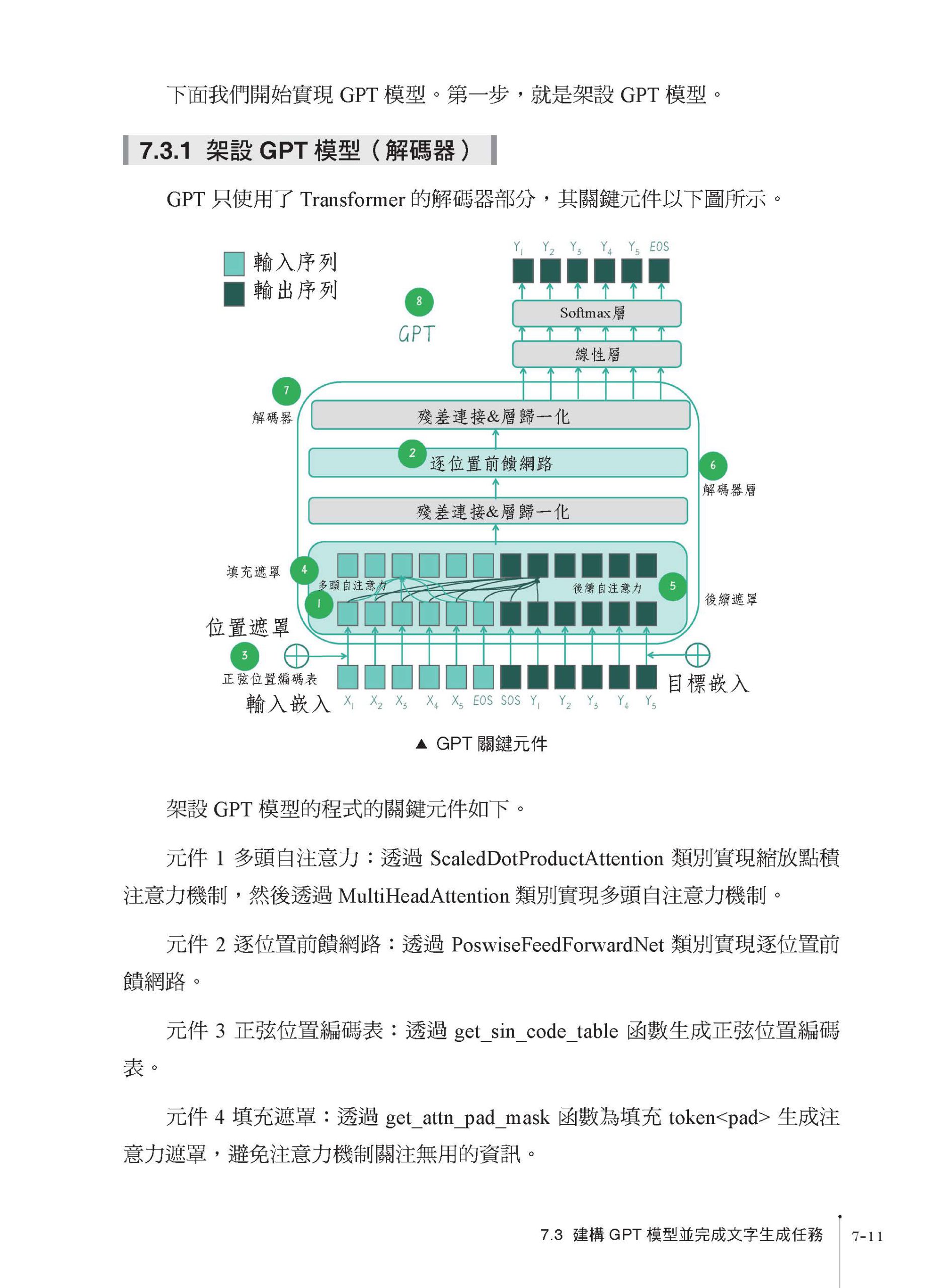
GPT-4:點亮通用人工智慧的火花 人工智慧演進之路:神經網路兩落三起 現代自然語言處理:從規則到統計 何為語言?資訊又如何傳播? NLP 是人類和電腦溝通的橋樑 NLP 技術的演進史 大規模預訓練語言模型:BERT 與GPT 爭鋒 語言模型的誕生和進化 統計語言模型的發展歷程 基於Transformer 架構的預訓練模型 " 預訓練+ 微調大模型" 的模式 以提示/ 指令模式直接使用大模型 從初代GPT 到ChatGPT,再到GPT-4 GPT 作為生成式模型的天然優勢 ChatGPT 背後的推手——OpenAI 從初代GPT 到ChatGPT,再到GPT-4 的進化史 第 1 課 高樓萬丈平地起:語言模型的雛形 N-Gram 和簡單文字表示 Bag-of-Words 1.1 N-Gram 模型 1.2 " 詞" 是什麼,如何" 分詞" 1.3 建立一個Bigram 字元預測模型 1.4 詞袋模型 1.5 用詞袋模型計算文字相似度 小結 思考 第 2 課 問君文字何所似:詞的向量表示 Word2Vec 和 Embedding 2.1 詞向量 ≈ 詞嵌入 2.2 Word2Vec:CBOW 模型和Skip-Gram 模型 2.3 Skip-Gram 模型的程式實現 2.4 CBOW 模型的程式實現 2.5 透過nn.Embedding 來實現詞嵌入 小結 思考 第 3 課 山重水盡疑無路:神經機率語言模型和循環神經網路 3.1 NPLM 的起源 3.2 NPLM 的實現 3.3 循環神經網路的結構 3.4 循環神經網路實戰 小結 思考 第 4 課 柳暗花明又一村:Seq2Seq 編碼器 - 解碼器架構 4.1 Seq2Seq 架構 4.2 建構簡單Seq2Seq 架構 小結 第 5 課 見微知著開慧眼:引入注意力機制 5.1 點積注意力 5.2 縮放點積注意力 5.3 編碼器- 解碼器注意力 5.4 注意力機制中的 Q、K、V 5.5 自注意力 5.6 多頭自注意力 5.7 注意力遮罩 5.8 其他類型的注意力 小結 思考 第 6 課 層巒疊翠上青天:架設 GPT 核心元件 Transformer 6.1 Transformer 架構剖析 6.1.1 編碼器- 解碼器架構 6.1.2 各種注意力的應用 6.1.3 編碼器的輸入和位置編碼 6.1.4 編碼器的內部結構 6.1.5 編碼器的輸出和編碼器- 解碼器的連接 6.1.6 解碼器的輸入和位置編碼 6.1.7 解碼器的內部結構 6.1.8 解碼器的輸出和Transformer 的輸出頭 6.2 Transformer 程式實現 6.3 完成翻譯任務 6.3.1 資料準備 6.3.2 訓練Transformer 模型 6.3.3 測試Transformer 模型 小結 思考 第 7 課 芳林新葉催陳葉:訓練出你的簡版生成式 GPT 7.1 BERT 與GPT 爭鋒 7.2 GPT:生成式自回歸模型 7.3 建構GPT 模型並完成文字生成任務 7.3.1 架設GPT 模型(解碼器) 7.3.2 建構文字生成任務的資料集 7.3.3 訓練過程中的自回歸 7.3.4 文字生成中的自回歸(貪婪搜索) 7.4 使用WikiText2 資料集訓練Wiki-GPT 模型 7.4.1 用WikiText2 建構Dataset 和DataLoader 7.4.2 用DataLoader 提供的資料進行訓練 7.4.3 用Evaluation Dataset 評估訓練過程 小結 思考 第 8 課 流水後波推前波:ChatGPT 基於人類回饋的強化學習 8.1 從GPT 到ChatGPT 8.2 在Wiki-GPT 基礎上訓練自己的簡版ChatGPT 8.3 用Hugging Face 預訓練GPT 微調ChatGPT 8.4 ChatGPT 的RLHF 實戰 8.4.1 強化學習基礎知識 8.4.2 簡單RLHF 實戰 小結 思考 第 9 課 生生不息的循環:使用強大的 GPT-4 API 9.1 強大的OpenAI API 9.2 使用GPT-4 API 小結 思考 後記 莫等閒,白了少年頭 |
序
| 前言
寫作時,時間流淌得很快。不知不覺,月已上中天,窗外燈火闌珊。 仰望蒼穹,月色如水,宇宙浩瀚。每每想起人類已在月球上留下腳印,而今再度出發,就不由在心中感慨——如此有幸,能生活在這個時代。 其實,從來沒有任何一種技術的突破,未經歷過一次次失敗,就能直接「降臨」到人類的眼前。 人工智慧(Artificial Intelligence,AI)技術,從誕生至今,其發展並不是一帆風順的:盛夏與寒冬交錯,期望和失望交融。 自然語言處理(Natural Language Processing,NLP) 技術是如此。ChatGPT 和 GPT-4 亦是如此。 從 N - Gram 和 Bag-of-Words 開始,自然語言處理技術和模型在不斷發展和演進,逐漸引入了更強大的神經網路模型(如 RNN、Seq2Seq、Transformer等)。現代預訓練語言模型(如BERT 和 GPT)則進一步提高了 NLP 任務的處理性能,成為目前自然語言處理領域的主流方法。 這一本小書,希望從純技術的角度,為你整理生成式語言模型的發展脈絡,對從 N-Gram、詞袋模型(Bag-of-Words,BoW)、Word2Vec(Word to Vector,W2V)、神經機率語言模型(Neural Probabilistic Language Model,NPLM)、循環神經網路(Recurrent Neural Network,RNN)、Seq2Seq(Sequence-to-Sequence,S2S)、注意力機制(Attention Mechanism)、Transformer、BERT到GPT的技術一一進行解碼,厘清它們的傳承關係。 這些具體技術的傳承關係如下。 ■N-Gram 和 Bag-of-Words :都是早期用於處理文字的方法,關注詞頻和局部詞序列。 ■Word2Vec :實現了詞嵌入方法的突破,能從詞頻和局部詞序列中捕捉詞彙的語義資訊。 ■NPLM :基於神經網路的語言模型,從此人類開始利用神經網路處理詞序列。 ■RNN :具有更強大的長距離依賴關係捕捉能力的神經網路模型。 ■Seq2Seq :基於 RNN 的編碼器 - 解碼器架構,將輸入序列映射到輸出序列,是 Transformer 架構的基礎。 ■Attention Mechanism :使 Seq2Seq 模型在生成輸出時更關注輸入序列的特定部分。 ■Transformer :摒棄了 RNN,提出全面基於自注意力的架構,實現高效平行計算。 ■BERT :基於 Transformer 的雙向預訓練語言模型,具有強大的遷移學習能力。 ■初代 GPT :基於 Transformer 的單向預訓練語言模型,採用生成式方法進行預訓練。 ■ChatGPT :從 GPT-3 開始,透過任務設計和微調策略的最佳化,尤其是基於人類回饋的強化學習,實現強大的文字生成和對話能力。 ■GPT-4:仍基於 Transformer 架構,使用前所未有的大規模計算參數和資料進行訓練,展現出比以前的 AI 模型更普遍的智慧,不僅精通語言處理,還可以解決涉及數學、編碼、視覺、醫學、法律、心理學等各領域的難題,被譽為 「通用人工智慧的星星之火」(Sparks of Artificial General Intelligence)。 今天,在我們為 ChatGPT、GPT-4 等大模型的神奇能力而驚歎的同時,讓我們對它們的底層邏輯與技術做一次嚴肅而快樂的探索。對我來說,這也是一次朝聖之旅,一次重溫人工智慧和自然語言處理技術 70 年間艱辛發展的旅程。 因此,我為一個輕鬆的序章取了一個略微沉重的標題:看似尋常最崎崛,成如容易卻艱辛。 格物致知,叩問蒼穹,直面失敗,勇猛前行。 向偉大的、不斷探索未知領域的科學家們致敬! 黃佳 2023 年春末夏初月夜 |