






描述
內容簡介
|
★★★★★【機器學習唯一指定】★★★★★ AI 專業大師 陳昭明 老師全新力作,帶你一次到位,完整學習Scikit-learn!
以Scikit-learn套件為主體,介紹各類的演算法,同時提供大量應用實例,全面性的掌握理論、技術與實作,為機器學習入門者的最佳夥伴! ★詳細的程式說明 ★遵循完整的機器學習開發流程 ★資料的探索、清理、特徵工程、模型訓練、評估、參數調校到最終的部署
本書主要的特點 1. 以完整的機器學習開發流程角度出發。 2. 每一個演算法都包括原理、自行開發、Scikit-learn函數用法,最後再附應用實例。 3. 以「統計/數學」為出發點,介紹機器學習必備的數理基礎,使用大量圖解,並以程式開發加深掌握演算法原理,增進學習樂趣。 4. 完整實用的範例程式及各種演算法的延伸應用,能在企業內應用自如。 |
作者
| 陳昭明
★曾任職於 IBM、工研院等全球知名企業 ★IT 邦幫忙 2018 年 AI 組【冠軍】 ★多年 AI 課程講授經驗 |
目錄
| 第 1 章 Scikit-learn入門
1-1 Scikit-learn簡介 1-2 學習地圖 1-3 開發環境安裝 1-4 Jupyter Notebook 1-5 撰寫第一支程式 1-6 本章小結 1-7 延伸練習
第 2 章 資料前置處理 2-1 資料源(Data Sources) 2-2 Scikit-learn內建資料集 2-3 資料清理 2-4 遺失值(Missing value)處理 2-5 離群值(Outlier)處理 2-6 類別變數編碼 2-7 其他資料清理 2-8 本章小結 2-9 延伸練習
第 3 章 資料探索與分析 3-1 資料探索的方式 3-2 描述統計量(Descriptive statistics) 3-3 統計圖 3-4 實務作法 3-5 本章小結 3-6 延伸閱讀
第 4 章 特徵工程 4-1 特徵縮放(Feature Scaling) 4-2 特徵選取(Feature Selection) 4-3 特徵萃取(Feature Extraction) 4-4 特徵生成(Feature Generation) 4-5 小結 4-6 延伸練習
第 5 章 迴歸 5-1 線性迴歸(Linear regression) 5-2 非線性迴歸(Non-linear regression) 5-3 迴歸的假設與缺點 5-4 時間序列分析(Time Series Analysis) 5-5 過度擬合(Overfitting)與正則化(Regularization) 5-6 偏差(Bias)與變異(Variance) 5-7 本章小結 5-8 延伸練習
第 6 章 分類演算法(一) 6-1 羅吉斯迴歸(Logistic Regression) 6-2 最近鄰(K nearest neighbor) 6-3 單純貝氏分類法(Naïve Bayes Classifier) 6-4 本章小結 6-5 延伸練習
第 7 章 分類演算法(二) 7-1 支援向量機(Support Vector Machine) 7-2 決策樹(Decision Tree) 7-3 隨機森林(Random Forest) 7-4 ExtraTreesClassifier 7-5 本章小結 7-6 延伸練習
第 8 章 模型效能評估與調校 8-1 模型效能評估 8-2 效能衡量指標(Performance Metrics) 8-3 ROC/AUC 8-4 詐欺偵測(Fraud Detection)個案研究 8-5 本章小結 8-6 延伸練習
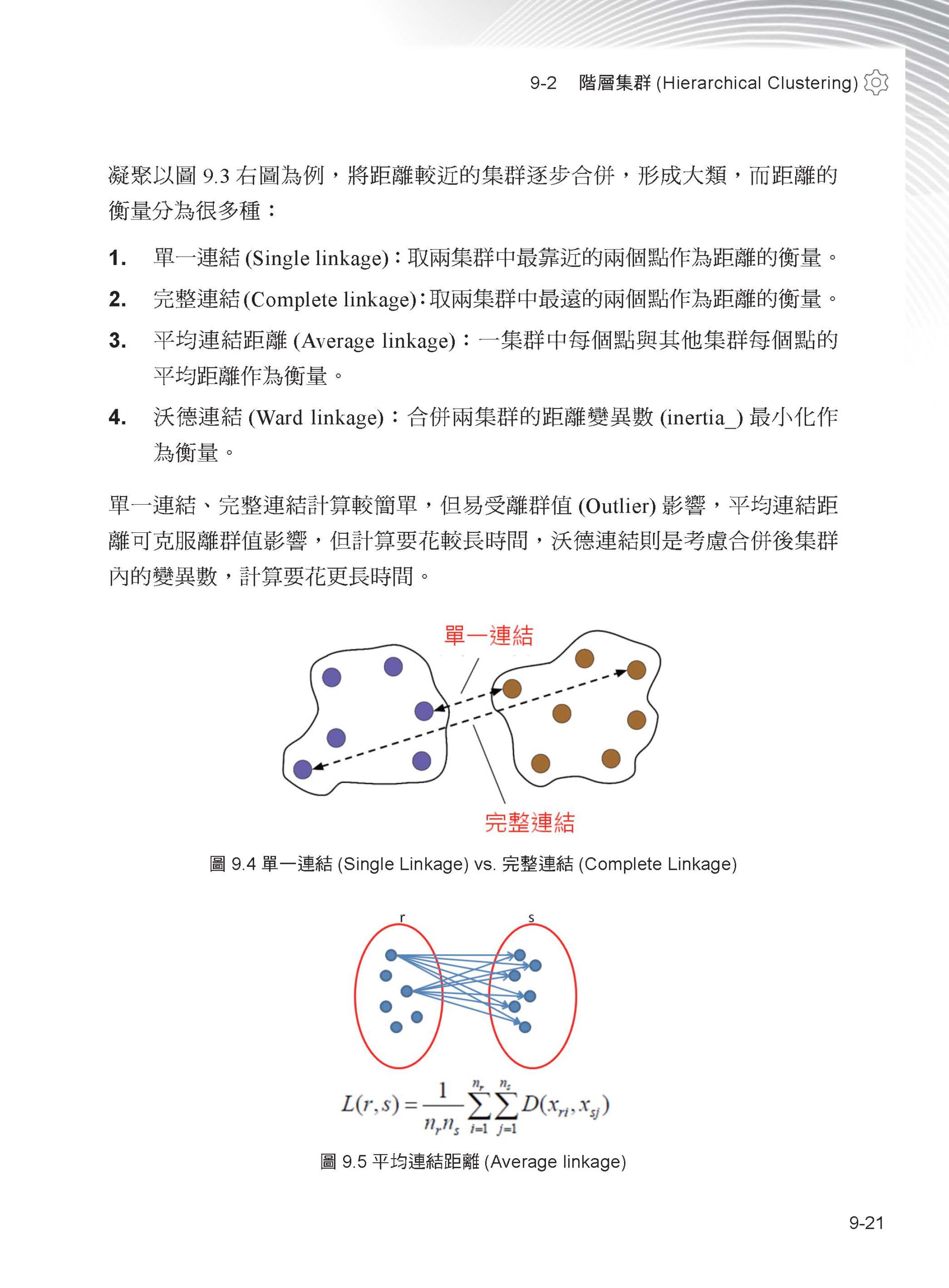
第 9 章 集群 9-1 K-Means Clustering 9-2 階層集群(Hierarchical Clustering) 9-3 以密度為基礎的集群(DBSCAN) 9-4 高斯混合模型(Gaussian Mixture Models) 9-5 影像壓縮(Image Compression) 9-6 客戶區隔(Customer Segmentation) 9-7 本章小結 9-8 延伸練習
第 10 章 整體學習 10-1 整體學習概念說明 10-2 多數決(Majority Voting) 10-3 裝袋法(Bagging) 10-4 強化法(Boosting) 10-5 堆疊(Stacking) 10-6 本章小結 10-7 延伸練習
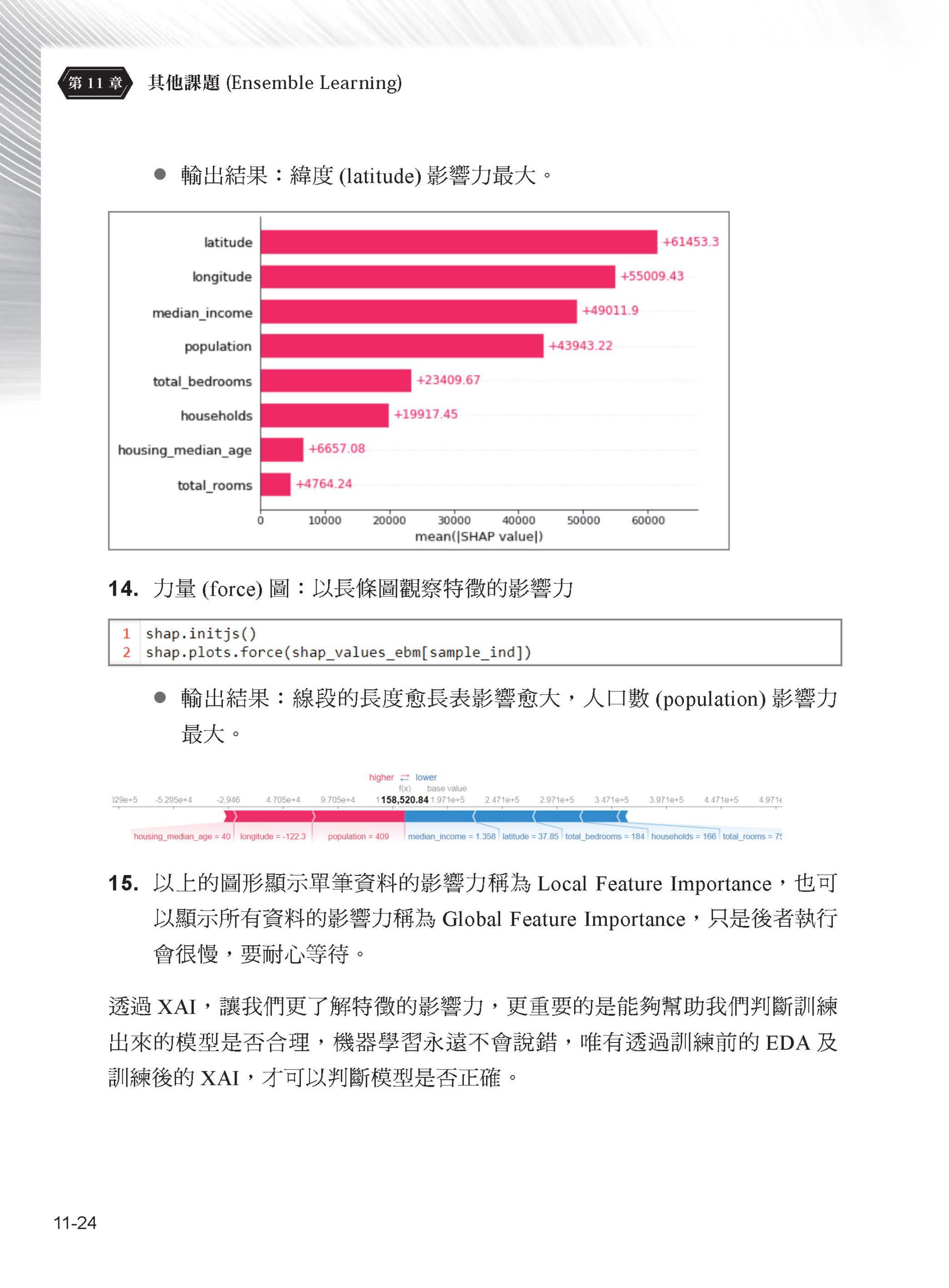
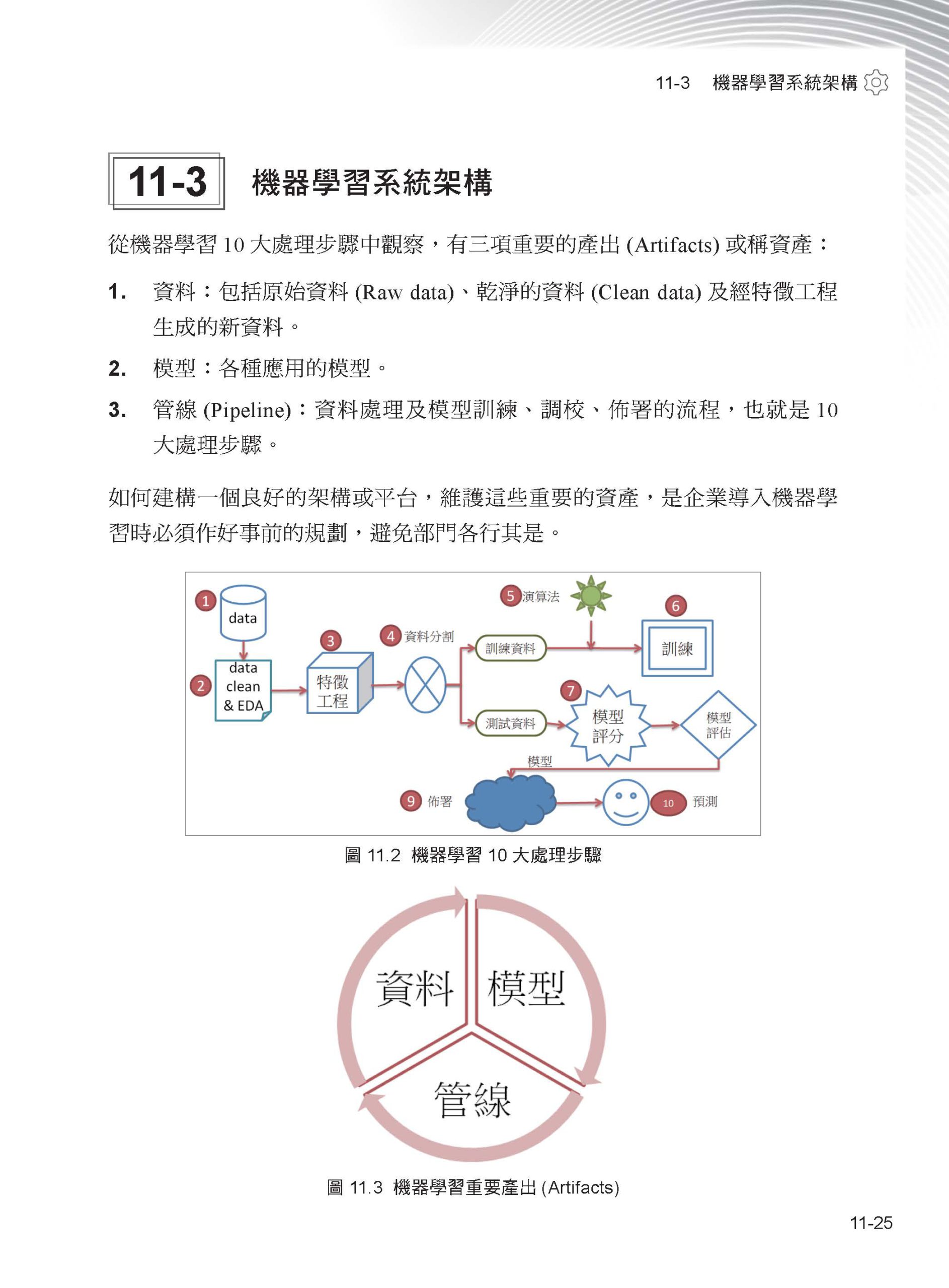
第 11 章 其他課題 11-1 半監督式學習(Semi-supervised learning) 11-2 可解釋的AI(Explainable AI, XAI) 11-3 機器學習系統架構 11-4 結語 |
序
| 前言 (Preface)
為何撰寫本書 近期AI發展相較以往,更加如火如荼,去年(2022) Text to image、ChapGPT引爆生成式AI (Generative AI)熱潮,衝擊藝術創作市場及Google搜索引擎霸主地位,相信有更多人因而希望探究AI科學,了解其背後的技術,或從事相關工作;然而,AI領域博大精深,不是一蹴可幾,需要奠定紮實的基礎,一步一腳印才能進入AI殿堂。
筆者從事機器學習教育訓練多年,其間也在『IT邦幫忙』撰寫上百篇的文章,從學員及讀者的回饋獲得許多寶貴意見,有感於在教學現場的時間壓力下,很多細節無法盡情的討論,難免有許多內容成為遺珠之憾,因此,撰寫本書,針對機器學習作較全面性的介紹,讓讀者有充裕的時間思考,或者挑選有興趣的課題深入研究。
本書以Scikit-learn套件為主體,介紹各類的演算法,不只是說明用法,也涵蓋背後的原理、數學公式推導,並示範如何自行開發演算法,與Scikit-learn演算法相互驗證,同時介紹大量應用實例,期望讀者能全面性的掌握理論、技術與實作。另外書中每個範例都有詳細的程式說明,也遵循完整的機器學習開發流程,讓讀者能充分理解每個環節的重要任務,包括資料的探索、清理、特徵工程、模型訓練、評估、參數調校到最終的佈署,希望這本書能成為機器學習入門者最佳的夥伴,在讀者紮根的過程中,貢獻一點微薄的力量。
本書主要的特點 1. 本書不是以Scikit-learn的模組分類介紹,而是以完整的機器學習開發流程角度出發。 2. 每一個演算法都包括原理、自行開發、Scikit-learn函數用法,最後再附應用實例。 3. 由於筆者身為統計人,希望能「以統計/數學為出發點」,介紹機器學習必備的數理基礎,但又不希望讓離開校園已久的在職者看到一堆數學符號就心生恐懼,因此,會有大量圖解,並以程式開發加深演算法原理的掌握,增進學習樂趣。 4. 完整的範例程式及各種演算法的延伸應用,以實用為要,希望能觸發創意,在企業內應用自如。
目標對象 1. 機器學習的入門者:須熟悉Python程式語言及資料科學基礎套件NumPy、Pandas及MatPlotLib。 2. 資料工程師及分析師:以模型開發及導入為職志,希望能應用各種演算法,或更進一步改良與實作演算法。 3. 資訊工作者:希望能擴展機器學習知識領域。 4. 從事其他領域的工作,希望能一窺機器學習奧秘者。
閱讀重點 1. 第一章:Scikit-learn模組及機器學習分類、學習地圖、開發流程。 2. 第二章:資料前置處理,包括資料清理、資料探索、特徵工程。 3. 第三章:資料探索與分析,包括描述統計量、統計圖分析。 4. 第四章:特徵工程,包括特徵縮放(Feature Scaling)、特徵選取(Feature Selection)、特徵萃取(Feature Extraction)及特徵生成(Feature Generation),內含各式降維演算法說明、維度災難(Curse of dimensionality)概念說明。 5. 第五章:迴歸(Regression),包括線性迴歸、多項式迴歸、時間序列等演算法,還有正則化(Regularization)、過度擬合(Overfitting)、偏差(Bias)與變異(Variance)的平衡。 6. 第六~七章:分類演算法,包括羅吉斯迴歸(Logistic Regression)、最近鄰(KNN)、單純貝氏分類法(Naïve bayes classifier)、支援向量機(SVM)、決策樹(Decision Tree)及隨機森林(Random forest)等,包括各項演算法的原理、開發邏輯、應用與優缺點說明。 7. 第八章:模型效能評估與調校,包括交叉驗證法、參數調校、管線(Pipeline)、混淆矩陣(Confusion Matrix)、效能衡量指標(Performance metrics)。 8. 第九章:集群(Clustering)演算法,K-Means、階層式集群、以密度為基礎的集群(DBSCAN)、高斯混合模型(GMM)等。 9. 第十章:整體學習(Ensemble Learning)演算法,包括多數決(Majority Voting)、裝袋法(Bagging)、強化法(Boosting)、堆疊法(Stacking)。 10. 第十一章:介紹其他課題,包括半監督式學習(Semi-supervised learning)、Active learning、可解釋的AI(Explainable AI, XAI)、機器學習架構。
本書包括許多應用範例,包括: 1 分類 1.1 鳶尾花(Iris)品種分類 1.2 葡萄酒分類 1.3 乳癌診斷 1.4 人臉資料集(LFW)辨識 1.5 新聞資料集(News groups)分類 1.6 鐵達尼號生存預測 1.7 手寫阿拉伯數字辨識 1.8 員工流失預測 1.9 信用卡詐欺 2 迴歸及時間預測 2.1 股價預測 2.2 房價預測 2.3 計程車小費預測 2.4 航空公司客運量預測 2.5 以人臉上半部預測人臉下半部 2.6 糖尿病指數預測 3 集群 3.1 手寫阿拉伯數字影像生成 3.2 客戶區隔(RFM) 3.3 影像壓縮 3.4 離群值偵測 4 商品推薦 4.1 協同過濾 4.2 KNN 5 影像 5.1 去躁(Image denoising) 5.2 影像生成 5.3 影像壓縮 6 自然語言 6.1 文章大意預測 6.2 垃圾信分類 6.3 問答(Q&A)
本書範例程式碼、參考超連結、勘誤表全部收錄在 https://github.com/mc6666/Scikit_learn_Book,並隨時更新相關資訊。
致謝 因個人能力有限,還是有許多議題成為遺珠之憾,仍待後續的努力,感謝深智出版社的大力支援,使本書得以順利出版,最後要謝謝家人的默默支持。
內容如有疏漏、謬誤或有其他建議,歡迎來信指教(mkclearn@gmail.com)或在『IT邦幫忙』(https://ithelp.ithome.com.tw/users/20001976/articles)留言討論。 |