


描述
內容簡介
|
用 PyTorch、NumPy、Google Colab T4 GPU 最強工具 完整實作 Perceptron、CNN、RNN、Transformer、GPT、RLHF 等經典論文
* Perceptron / MLP / Backpropagation / CNN / RNN / LSTM 精選論文實作 * 超過 30 個完整 Jupyter Notebook 重現論文過程 * 最棒的學習路徑,從 1958 到 2022,一次掌握 64 年 AI 發展史 * 串接 Google Colab 免費 GPU,無限制的運算資源,還有 T4 加速 * 用 PyTorch 撰寫 Attention、Transformer、BERT * 實作 AlphaGo,5 分鐘搞懂蒙地卡羅樹搜尋,自己幫你跑完整局棋 * 快速寫出 Visual Transformer 完整實作
快點上手全世界最強 AI 研究者的必讀論文,從此不用再苦苦爬 arXiv,不用再嫌自己看不懂數學,只要會寫程式。讓 PyTorch 帶你用 Vibe Coding 以百倍速度把論文變成能跑的程式碼。本書從入門到實戰,一路扶持你成為能駕馭 AI 論文的開發者。
從設定 Google Colab 環境與啟用 T4 GPU,熟悉 PyTorch 張量操作,活用 Perceptron、MLP、Backpropagation、Dropout、BatchNorm,立即感受大神們在完成論文的開心!
包括使用 CNN 做影像辨識,使用 Word2Vec 做詞嵌入,使用 RNN 和 LSTM 處理序列資料,使用 Seq2Seq 做機器翻譯,當然還有使用 Attention 機制,重現歷史的重要 AI 時刻。
掌握 Transformer 的關鍵思維,了解 BERT 與 GPT 的預訓練威力,結合 Decoder-Only 架構,不用再摸索無盡的論文海,不用再埋頭苦讀上百頁英文的官方文件,直接就動手做了
用 VAE 精準生成,了解 AI 最愛看的 GAN 生成對抗網路,使用 ResNet 建立一個 AI 專用的殘差連接流程,從零打造 Batch Normalization;再進一步實作 DQN 強化學習與 AlphaGo 蒙地卡羅樹搜尋策略,最後用 InstructGPT 與 RLHF,Dall-E、Stable Diffusion、Visual Transformer,了解 AI 圖片產生的原理。 |
作者簡介
| 胡嘉璽
研究領域為 LLM、Vibe Coding、Agent、量子電腦、虛擬化及容器。 聯絡方式:github/joshhu |
目錄
| 第0 章 本書執行環境設定
0.1 前言 0.2 為什麼選擇這個環境? 0.3 環境需求 0.4 安裝步驟 0.5 常見問題排解 0.6 本書程式碼結構 0.7 執行建議 0.8 開始學習
第1 章 複雜動力學第一定律 1.1 為什麼這篇文章重要? 1.2 從一杯咖啡說起 1.3 熵與複雜度:兩個不同的概念 1.4 Kolmogorov 複雜度:用程式長度衡量複雜性 1.5 精密度:捕捉「有意義的」複雜性 1.6 細胞自動機:複雜性的實驗室 1.7 程式碼解析:PyTorch 實作 1.8 與深度學習的深層關聯 1.9 實驗:親手驗證 1.10 思考題 1.11 本章小結
第2 章 循環神經網路的不合理有效性 2.1 為什麼這篇文章重要? 2.2 從一個簡單的問題開始 2.3 循環神經網路 (RNN) 的核心思想 2.4 展開的RNN:理解時間維度 2.5 字元級語言模型 2.6 反向傳播穿越時間 (BPTT) 2.7 梯度問題與解決方案 2.8 從隨機到莎士比亞 2.9 其他驚人的應用 2.10 採樣策略:溫度參數 2.11 程式碼解析:關鍵實作細節 2.12 與現代語言模型的關係 2.13 實驗:親手訓練一個字元級RNN 2.14 思考題 2.15 本章小結
第3 章 理解LSTM 網路 3.1 為什麼需要LSTM ? 3.2 梯度消失問題 3.3 LSTM 的解決方案:門控機制 3.4 LSTM 的數學公式 3.5 為什麼LSTM 能解決梯度消失? 3.6 用例子理解 LSTM 3.7 LSTM vs Vanilla RNN:梯度流動對比 3.8 程式碼解析:LSTM Cell 實作 3.9 門的視覺化解讀 3.10 LSTM 的反向傳播 3.11 LSTM 的變體 3.11 實際應用 3.12 LSTM 的局限性與 Transformer 3.13 思考題 3.14 本章小結
第4 章 循環神經網路的正規化 4.1 引言:RNN 的過擬合問題 4.2 問題:天真地將Dropout 應用於RNN 不管用! 4.3 Zaremba 等人的解決方案 4.4 變分 Dropout(Variational Dropout) 4.5 進階技術:其他 RNN 正規化方法 4.6 深入理解:為什麼位置很重要? 4.7 實驗結果 4.8 PyTorch 實作要點 4.9 完整實作:帶Dropout 的LSTM 語言模型 4.10 實驗分析與視覺化 4.11 常見問題與解決方案 4.12 與後續研究的關係 4.13 思考題 4.14 總結
第5 章 透過最小化描述長度保持神經網路簡單 5.1 引言:為什麼簡單的模型更好? 5.2 最小描述長度(MDL)原則 5.3 網路剪枝(Network Pruning) 5.4 漸進式剪枝(Iterative Pruning) 5.5 結構化剪枝vs 非結構化剪枝 5.6 與L1 正規化的關係 5.7 彩票假說(Lottery Ticket Hypothesis) 5.8 現代剪枝技術 5.9 PyTorch 實作要點 5.10 完整實作:PyTorch 剪枝流程 5.11 實際應用案例 5.12 思考題 5.13 總結
第6 章 指標網路 (Pointer Networks) 6.1 引言 6.2 問題定義 6.3 模型架構 6.4 數學推導 6.5 實作細節 6.6 訓練策略 6.7 應用:凸包問題 6.8 應用:旅行推銷員問題 6.9 應用:排序任務 6.10 進階技術 6.11 實驗結果分析 6.12 與後續研究的關係 6.13 視覺化與解釋 6.14 常見問題與解決方案 6.15 完整實作範例 6.16 思考題 6.17 延伸閱讀 6.18 本章小結
第7 章 AlexNet 深度學習革命的起點 7.1 引言 7.2 ImageNet 挑戰賽 7.3 AlexNet 架構 7.4 關鍵創新技術 7.5 資料增強 7.6 訓練細節 7.7 PyTorch 實作 7.8 視覺化分析 7.9 實驗與結果分析 7.10 資料增強實作 7.11 與後續網路的比較 7.12 現代視角 7.13 常見問題與解決方案 7.14 思考題 7.15 延伸閱讀 7.16 本章小結
第8 章 順序很重要 序列對序列(Sequence-to-Sequence) 處理集合 8.1 引言 8.2 排列不變性 8.3 讀取- 處理- 寫入架構 8.4 輸出順序問題 8.5 應用場景 8.6 注意力機制詳解 8.7 與DeepSets 的關係 8.8 完整模型實作 8.9 實驗結果 8.10 與其他論文的關聯 8.11 進階技術 8.12 常見問題與解決方案 8.13 思考題 8.14 延伸閱讀 8.15 本章小結
第9 章 GPipe 使用管線平行化高效訓練巨型神經網路 9.1 論文背景與動機 9.2 管線平行化的核心概念 9.3 微批次策略 9.4 梯度累積 9.5 重新實體化技術 9.6 實作細節 9.7 與資料平行化的比較 9.8 氣泡時間的視覺化 9.9 記憶體與計算的權衡 9.10 進階排程策略 9.11 實際應用與成果 9.12 PyTorch 實作要點 9.13 最佳化建議 9.14 現代擴展技術 9.15 相關論文連結 9.16 總結 9.17 數學推導補充 9.18 常見問題與解決方案 9.19 程式碼範例:完整訓練迴圈 9.20 效能基準參考
第10 章 ResNet 深度殘差學習 10.1 引言 10.2 論文資訊 10.3 退化問題的本質 10.4 殘差學習的核心思想 10.5 殘差區塊的設計 10.6 跳躍連接的數學分析 10.7 ResNet 架構變體 10.8 批次正規化的角色 10.9 實作細節 10.10 PyTorch 完整實作 10.11 梯度流動實驗 10.12 視覺化分析 10.13 ResNet 的影響與變體 10.14 訓練技巧 10.15 消融實驗 10.16 與其他架構的比較 10.17 實際應用建議 10.18 數學補充 10.19 常見問題 10.20 總結
第11 章 膨脹卷積 多尺度上下文聚合 11.1 引言 11.2 論文資訊 11.3 密集預測的挑戰 11.4 膨脹卷積的核心思想 11.5 多尺度上下文聚合 11.6 數學分析 11.7 PyTorch 實作 11.8 完整分割網路 11.9 一維膨脹卷積 11.10 感受野視覺化 11.11 網格效應問題 11.12 與其他技術的結合 11.13 應用場景 11.14 效能比較 11.15 實作細節 11.16 常見問題 11.17 延伸閱讀 11.18 總結
第12 章 訊息傳遞神經網路圖神經網路的統一框架 12.1 論文資訊 12.2 歷史背景與重要性 12.3 核心思想 12.4 數學框架 12.5 統一現有方法 12.6 實作細節 12.7 與 GCN 的比較 12.8 應用:量子化學性質預測 12.9 過度平滑問題 12.10 表達能力分析 12.11 圖級別讀出 12.12 現代發展 12.13 實際應用 12.14 程式碼實作重點 12.15 關鍵公式總結 12.16 總結 12.17 進階主題:批次處理與效率 12.18 進階主題:多關係圖 12.19 進階主題:圖生成 12.20 進階主題:可解釋性 12.21 常見錯誤與陷阱 12.22 實作檢查清單 12.23 論文連結
第13 章 Transformer 注意力就是你所需要的 13.1 論文資訊 13.2 歷史背景與重要性 13.3 核心思想 13.4 數學框架 13.5 多頭注意力(Multi-Head Attention) 13.6 位置編碼(Positional Encoding) 13.7 前饋網路(Feed-Forward Network) 13.8 層正規化(Layer Normalization) 13.9 完整 Transformer 架構 13.10 注意力的三種用途 13.11 訓練細節 13.12 計算複雜度分析 13.13 架構變體 13.14 現代改進 13.15 視覺化理解 13.16 實作要點 13.17 與其他架構的比較 13.18 影響與後續發展 13.19 關鍵公式總結 13.20 總結 13.21 深入理解:為什麼 Transformer 能成功? 13.22 實作細節探討 13.23 常見問題與解答 13.24 從零實作的檢查清單 13.25 延伸閱讀建議 13.26 思考題 13.27 論文連結
第14 章 Bahdanau 注意力機制- 神經機器翻譯的突破 14.1 論文資訊 14.2 歷史背景與重要性 14.3 問題背景:固定長度向量的瓶頸 14.4 核心思想:注意力機制 14.5 數學框架 14.6 與傳統 Seq2Seq 的比較 14.7 實驗結果 14.8 注意力的類型 14.9 深入理解:為什麼注意力有效? 14.10 實作細節 14.11 注意力的視覺化與解釋 14.12 雙向 RNN 的作用 14.13 超越機器翻譯 14.14 從 Bahdanau 到 Transformer 14.15 常見問題 14.16 實作要點 14.17 總結 14.18 深入分析:注意力的數學性質 14.19 進階主題:注意力變體 14.20 實作進階技巧 14.21 與現代架構的連結 14.22 思考題 14.23 延伸閱讀 14.24 論文連結
第15 章 深度殘差網路中的恆等映射 15.1 論文資訊 15.2 歷史背景與重要性 15.3 問題回顧:為什麼需要殘差連接? 15.4 原始 ResNet 塊的問題 15.5 解決方案:預活化殘差塊 15.6 數學分析 15.7 各種架構變體的比較 15.8 實驗結果 15.9 為什麼預活化有效? 15.10 實作要點 15.11 與其他技術的關係 15.12 直覺理解 15.13 常見問題 15.14 超深網路的挑戰 15.15 現代視角 15.16 總結 15.17 延伸閱讀 15.18 深入分析:恆等映射的理論基礎 15.19 進階實作技巧 15.20 實驗細節與技巧 15.21 思考題 15.22 常見錯誤與陷阱 15.23 論文連結
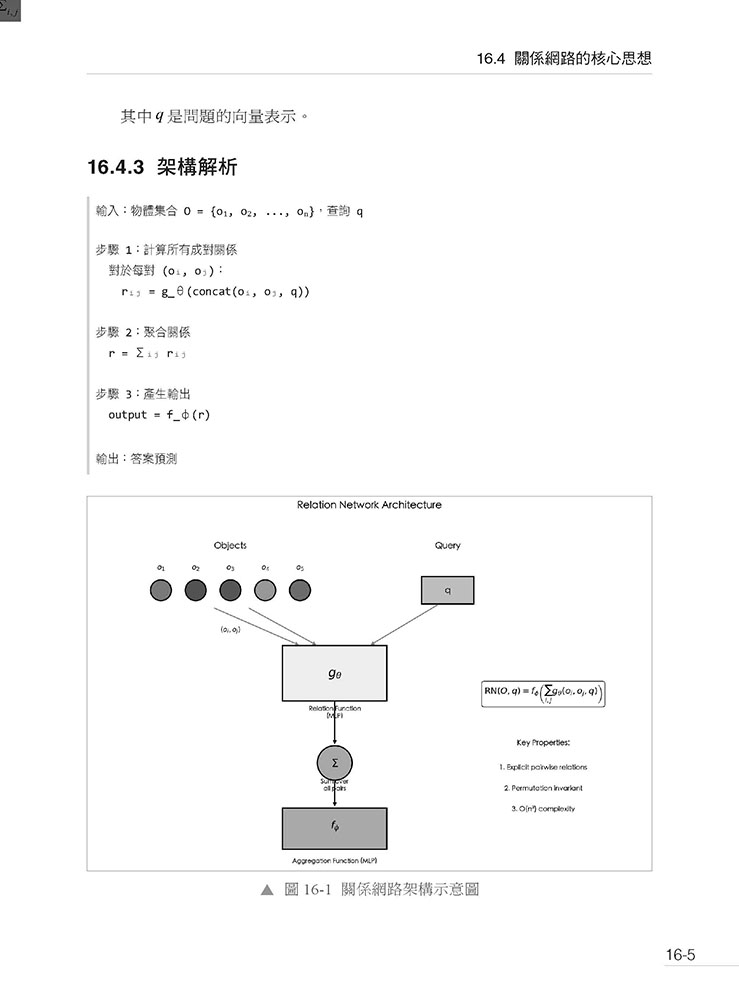
第16 章 關係網路 — 讓神經網路學會推理 16.1 引言 16.2 論文資訊 16.3 傳統方法的困境 16.4 關係網路的核心思想 16.5 為什麼這樣設計有效? 16.6 排列不變性 16.7 與其他架構的比較 16.8 Sort-of-CLEVR 資料集 16.9 實驗結果 16.10 視覺問答的完整流程 16.11 PyTorch 實作 16.12 座標編碼的重要性 16.13 實驗:排列不變性驗證 16.14 Sort-of-CLEVR 完整實作 16.15 文字推理:bAbI 任務 16.16 物理預測任務 16.17 訓練技巧 16.18 計算效率優化 16.19 與後續工作的關係 16.20 常見問題與解答 16.21 實作檢查清單 16.22 延伸閱讀 16.23 總結
第17 章 變分自編碼器 — 深度學習遇見貝葉斯推論 17.1 引言 17.2 論文資訊 17.3 從自編碼器到變分自編碼器 17.4 數學基礎 17.5 重參數化技巧 17.6 VAE 架構 17.7 KL 散度的閉式解 17.8 訓練過程 17.9 潛在空間的性質 17.10 生成新樣本 17.11 PyTorch 完整實作 17.12 卷積VAE 17.13 後驗崩塌問題 17.14 VAE 的變體 17.15 應用場景 17.16 與其他生成模型的比較 17.17 實驗:MNIST VAE 17.18 常見問題與解答 17.19 延伸閱讀 17.20 實作檢查清單 17.21 總結
第18 章 Relational RNN — 關係型循環神經網路 18.1 引言 18.2 論文資訊 18.3 核心概念:從記憶到關係 18.4 架構詳解 18.5 數學推導 18.6 關鍵創新點 18.7 實驗結果分析 18.8 實作考量 18.9 與其他方法的比較 18.10 程式碼架構說明 18.11 深入理解:為什麼記憶槽之間需要交互? 18.12 訓練技巧與最佳實踐 18.13 常見問題與解決方案 18.14 進階變體與擴展 18.15 與現代架構的比較 18.16 延伸閱讀與展望 18.17 本章小結
第19 章 咖啡自動機與不可逆性的奧秘 19.1 引言 19.2 論文資訊 19.3 核心概念:不可逆性的謎題 19.4 擴散過程與熵增加 19.5 相空間與Liouville 定理 19.6 Poincaré 回歸 19.7 Maxwell 妖精 19.8 Landauer 原理 19.9 計算不可逆性 19.10 資訊瓶頸與機器學習 19.11 時間箭頭的三種形式 19.12 生命與熱力學第二定律 19.13 不可逆性的層次 19.14 數學推導 19.15 實作要點 19.16 深層意義 19.17 延伸閱讀 19.18 本章小結
第20 章 神經圖靈機 — 可微分的通用計算 20.1 引言 20.2 論文資訊 20.3 從圖靈機到神經圖靈機 20.4 記憶體定址機制 20.5 讀寫操作 20.6 控制器架構 20.7 完整的NTM 架構 20.8 訓練與任務 20.9 視覺化分析 20.10 與其他架構的比較 20.11 NTM 的後續發展 20.12 實作挑戰與技巧 20.13 應用場景 20.14 與第十六章的關聯 20.15 數學基礎:為什麼這些操作是可微分的? 20.16 程式碼實作要點 20.17 總結
第21 章 Deep Speech 2 與 CTC —端到端語音辨識的突破 21.1 引言 21.2 論文資訊 21.3 CTC 的起源與核心問題 21.4 CTC 的數學原理 21.5 CTC 的實作 21.6 Deep Speech 2 架構 21.7 CTC 解碼 21.8 訓練技巧 21.9 實驗結果與分析 21.10 CTC 的局限性 21.11 後續發展 21.12 與其他章節的關聯 21.13 應用與影響 21.14 程式碼實作要點 21.15 總結
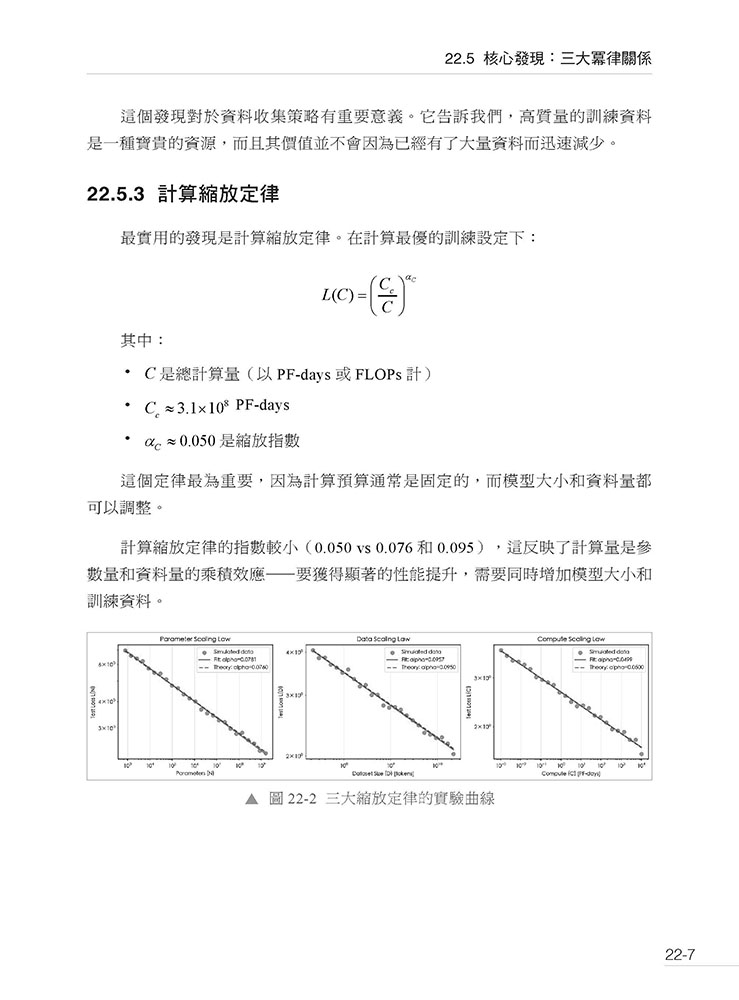
第22 章 Scaling Laws for Neural Language Models — 神經語言模型的縮放定律 22.1 引言:從經驗到定律 22.2 論文資訊 22.3 什麼是冪律關係 22.4 歷史背景:大模型時代的來臨 22.5 核心發現:三大冪律關係 22.6 數學框架:統一的損失預測模型 22.7 實驗設計:系統性的驗證方法 22.8 冪律的物理直覺 22.9 實作:冪律擬合與預測 22.10 架構變化的影響 22.11 遷移學習與微調 22.12 計算效率與實踐考量 22.13 後續發展:Chinchilla 定律 22.14 湧現能力與相變 22.15 資料質量與縮放定律 22.16 多模態縮放定律 22.17 縮放定律的局限性 22.18 實作:縮放定律實驗框架 22.19 與其他AI 領域的連結 22.20 縮放定律的哲學意涵 22.21 總結:預測AI 的未來
第23 章 GPT-3 — 語言模型是少樣本學習者 23.1 引言:大型語言模型的里程碑 23.2 從GPT 到GPT-3:進化之路 23.3 模型架構:巨型Transformer 23.4 訓練資料與方法 23.5 上下文學習:少樣本學習的新範式 23.6 實驗結果:全面的能力評估 23.7 文本生成:令人印象深刻的創作能力 23.8 分析:縮放定律的驗證 23.9 技術實作細節 23.10 社會影響與倫理考量 23.11 與其他模型的比較 23.12 後續發展與影響 23.13 實作考量 23.14 數學基礎:語言建模 23.15 與前一章的連結:縮放定律的實現 23.16 批評與反思 23.17 實作:簡化版GPT 的關鍵組件 23.18 未來展望 23.19 總結
第24 章 Vision Transformer — 影像也是一種語言 24.1 引言:當Transformer 遇見電腦視覺 24.2 從CNN 到Transformer:視覺模型的演進 24.3 Vision Transformer 的核心思想 24.4 ViT 架構詳解 24.5 模型配置與規模 24.6 訓練策略與資料需求 24.7 關鍵實驗結果 24.8 視覺化分析:ViT 學到了什麼? 24.9 與CNN 的深入比較 24.10 計算效率分析 24.11 ViT 的影響與後續發展 24.12 PyTorch 實作重點 24.13 實作注意事項 24.14 常見問題與解答 24.15 程式碼實作 24.16 延伸閱讀 24.17 實驗復現技巧 24.18 ViT 的數學推導補充 24.19 ViT 變體深入分析 24.20 本章總結 24.21 關鍵術語中英對照 24.22 論文連結
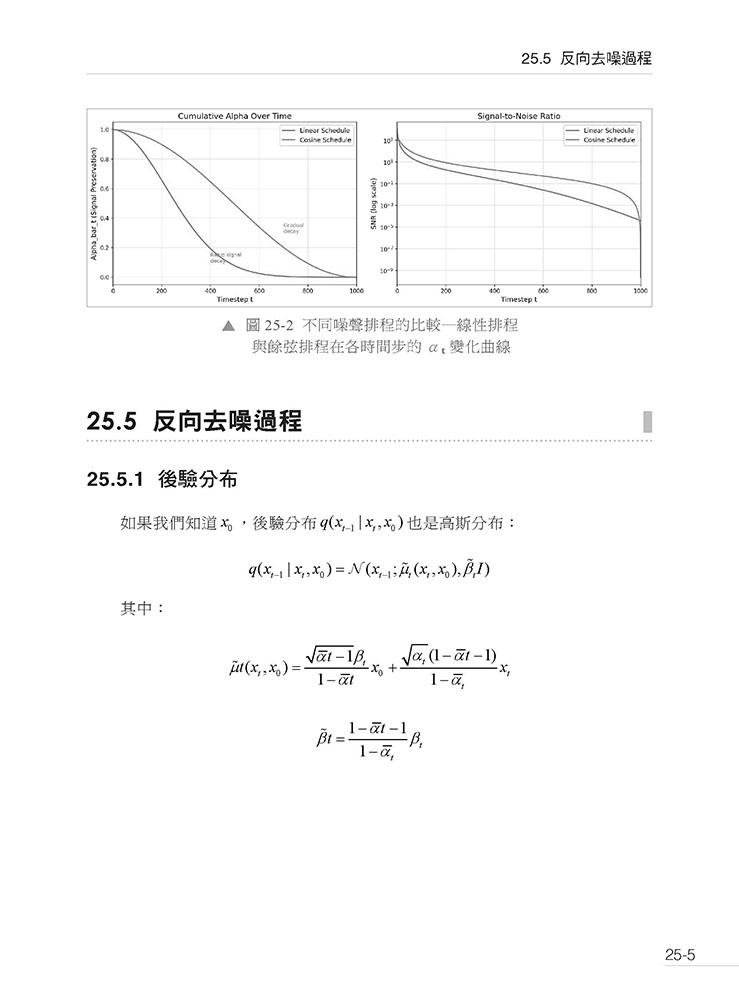
第25 章 DDPM — 擴散模型的奠基之作 25.1 引言:生成模型的新範式 25.2 論文資訊 25.3 擴散模型的歷史背景 25.4 前向擴散過程 25.5 反向去噪過程 25.6 訓練目標推導 25.7 採樣演算法 25.8 神經網路架構 25.9 訓練細節 25.10 實驗結果 25.11 與其他生成模型的比較 25.12 數學推導補充 25.13 程式碼實作重點 25.14 DDPM 的局限性 25.15 DDPM 的後續發展 25.16 物理直覺與視覺化 25.17 程式碼實作 25.18 延伸閱讀 25.19 本章總結 25.20 實作技巧與常見問題 25.21 DDPM 與Score-based Models 的聯繫 25.22 進階主題 25.23 關鍵數據回顧 25.24 關鍵術語中英對照 25.25 論文連結
第26 章 CLIP — 連接視覺與語言的橋樑 26.1 引言:從專家系統到通用視覺模型 26.2 論文資訊:多模態學習的基石 26.3 研究背景與動機 26.4 CLIP 的核心方法 26.5 模型架構 26.6 零樣本分類 26.7 實驗結果 26.8 CLIP 的能力與局限 26.9 對比學習的數學原理 26.10 訓練細節 26.11 CLIP 的應用 26.12 程式碼實作重點 26.13 CLIP 的變體與改進 26.14 CLIP 的社會影響 26.15 CLIP 的歷史意義 26.16 程式碼實作 26.17 延伸閱讀 26.18 本章總結 26.19 實作技巧與常見問題 26.20 與其他多模態模型的比較
第27 章 AlphaFold 2 — 解開生命的摺紙之謎 27.1 引言:五十年的科學難題 27.2 論文資訊:跨世紀難題的解答 27.3 蛋白質摺疊問題的背景 27.4 AlphaFold 2 的突破 27.5 AlphaFold 2 的架構 27.6 輸入特徵 27.7 Evoformer:核心創新 27.8 Structure Module 27.9 Recycling 機制 27.10 損失函式 27.11 訓練細節 27.12 實驗結果 27.13 AlphaFold 的影響 27.14 AlphaFold 2 的局限性 27.15 後續發展 27.16 程式碼實作重點 27.17 程式碼實作 27.18 實作注意事項 27.19 延伸閱讀 27.20 蛋白質結構預測的歷史回顧 27.21 本章總結 27.22 關鍵術語中英對照 27.23 論文連結
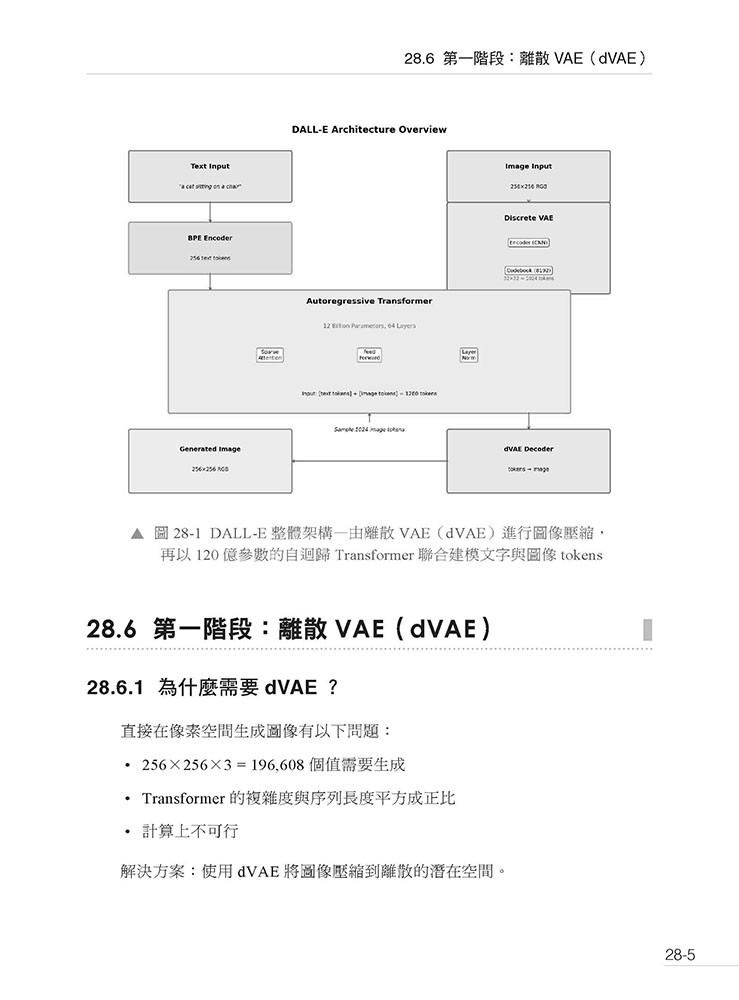
第28 章 DALL-E — 文字到圖像的零樣本生成 28.1 引言:當語言模型學會畫畫 28.2 論文資訊:零樣本生成的開端 28.3 DALL-E 之前的文字到圖像生成 28.4 核心思想:自迴歸生成 28.5 模型架構總覽 28.6 第一階段:離散VAE(dVAE) 28.7 第二階段:自迴歸Transformer 28.8 訓練流程 28.9 推論流程 28.10 零樣本能力展示 28.11 實作要點 28.12 與其他方法的比較 28.13 技術挑戰與解決方案 28.14 應用場景 28.15 局限性 28.16 實作建議 28.17 實作提示 28.18 延伸閱讀 28.19 歷史意義 28.20 本章總結 28.21 關鍵術語中英對照 28.22 論文連結
第29 章 Stable Diffusion — 潛在空間中的擴散模型 29.1 論文資訊:開源影像生成的基準 29.2 從像素擴散到潛在擴散 29.3 模型架構總覽 29.4 第一階段:感知壓縮模型 29.5 第二階段:潛在擴散模型 29.6 條件機制:Cross-Attention 29.7 Classifier-Free Guidance 29.8 訓練流程 29.9 採樣方法 29.10 完整推論流程 29.11 實作要點 29.12 應用場景 29.13 Stable Diffusion 的版本演進 29.14 技術挑戰與解決方案 29.15 與其他方法的比較 29.16 實作建議 29.17 延伸閱讀 29.18 開源生態系統 29.19 本章總結 29.20 關鍵術語中英對照 29.21 論文連結
第30 章 InstructGPT — 用人類回饋對齊語言模型 30.1 引言:讓AI 理解人類意圖 30.2 論文資訊:AI 對齊的里程碑 30.3 問題背景:為什麼需要對齊? 30.4 RLHF 方法總覽 30.5 階段一:監督式微調(SFT) 30.6 階段二:獎勵模型訓練(RM) 30.7 階段三:PPO 強化學習 30.8 人類標註指南 30.9 實驗結果 30.10 實作要點 30.11 RLHF 的挑戰與解決方案 30.12 後續發展 30.13 RLHF 的廣泛影響 30.14 實作建議 30.15 延伸閱讀 30.16 RLHF 與傳統強化學習的差異 30.17 本章總結 30.18 關鍵術語中英對照 30.19 論文連結
後記:站在巨人的肩膀上 |
序
|
|