












描述
內容簡介
|
用 Colab × Gemini × BERT × Apps Script 完成爬蟲、AI 標註、模型訓練與智慧儀表板, 做出你的第一個可上線 AI 產品。
►把海量評論,變成可執行的產品洞察 每天都有大量使用者在 App Store 與 Google Play 留下評論。 有人抱怨閃退、登入失敗、付款卡住;也有人稱讚體驗順暢、功能好用。這些聲音,是產品團隊最直接、也最真實的市場回饋。 然而,當評論累積到成千上萬筆,人工閱讀很快就會失去效率。 本書將帶你從零開始,打造一套 AI 評論洞察系統:從蒐集評論、清理資料、LLM 自動標註、到 BERT 分類模型訓練、智慧儀表板建置,最後完成部署上線。 你不需要具備工程背景。只要跟著書中的實作流程,就能一步步將大量評論轉化為可追蹤、可分析、可行動的產品洞察,讓產品決策更有依據。 你將學會: ►爬取 App Store 與 Google Play 評論 ►清理評論資料,掌握問題與趨勢 ►使用 LLM 自動完成資料標註 ►訓練 BERT,建立評論分類模型 ►打造智慧儀表板,呈現關鍵洞察 ►串接 Apps Script,完成雲端部署 適合讀者: ►產品經理 ►行銷企劃 ►數據分析新手 ►AI 轉型學習者 ►想打造第一個 AI 產品的人 【跨界聯合推薦】(依姓氏筆畫排列) 王道平|前 NIQ 港澳台總經理、蓋洛普優勢認證教練 孔令傑|國立臺灣大學資訊管理學系副教授 吳政隆|東吳大學資料科學系教授 金凱儀|東吳大學資料科學系教授、巨量資料管理學院院長 彭建文|《國際PJ法®》創辦人、品碩創新管理顧問執行長、前台積電營運效率部門主管 曾友志|資深產品與增長顧問、Mr. PM 下午先生 |
作者簡介
| 董建祺
畢業於台科大企管所與東吳資科所,現任外商零售數據分析師,擁有七年以上資料領域經驗。曾於國內外研討會發表多篇論文。近期投入經營個人品牌《JT用數據說故事》,專注分享數據職涯經驗與多元知識。 歡迎透過以下網站了解更多,或與我聯繫: 個人網站:chienchitung.com 部落格/電子報:jtdatastoryteller.com 劉柔萱 擁有資訊工程與資料科學雙重學術背景,現職於金融業從事資訊相關工作,長期關注資料分析、人工智慧與數據應用領域,對此抱有高度熱忱。 劉嘉玲 現任外商消費品銷售卓越策略主管,長期專注於商業策略、數據分析與 AI 應用,致力將資料科學落實在實務洞察與問題解決。曾於2025年國際先進機器學習與資料科學(AMLDS)國際研討會榮獲最佳口頭發表獎 。 |
目錄
| ▍第 1 篇 為什麼你需要這本書?
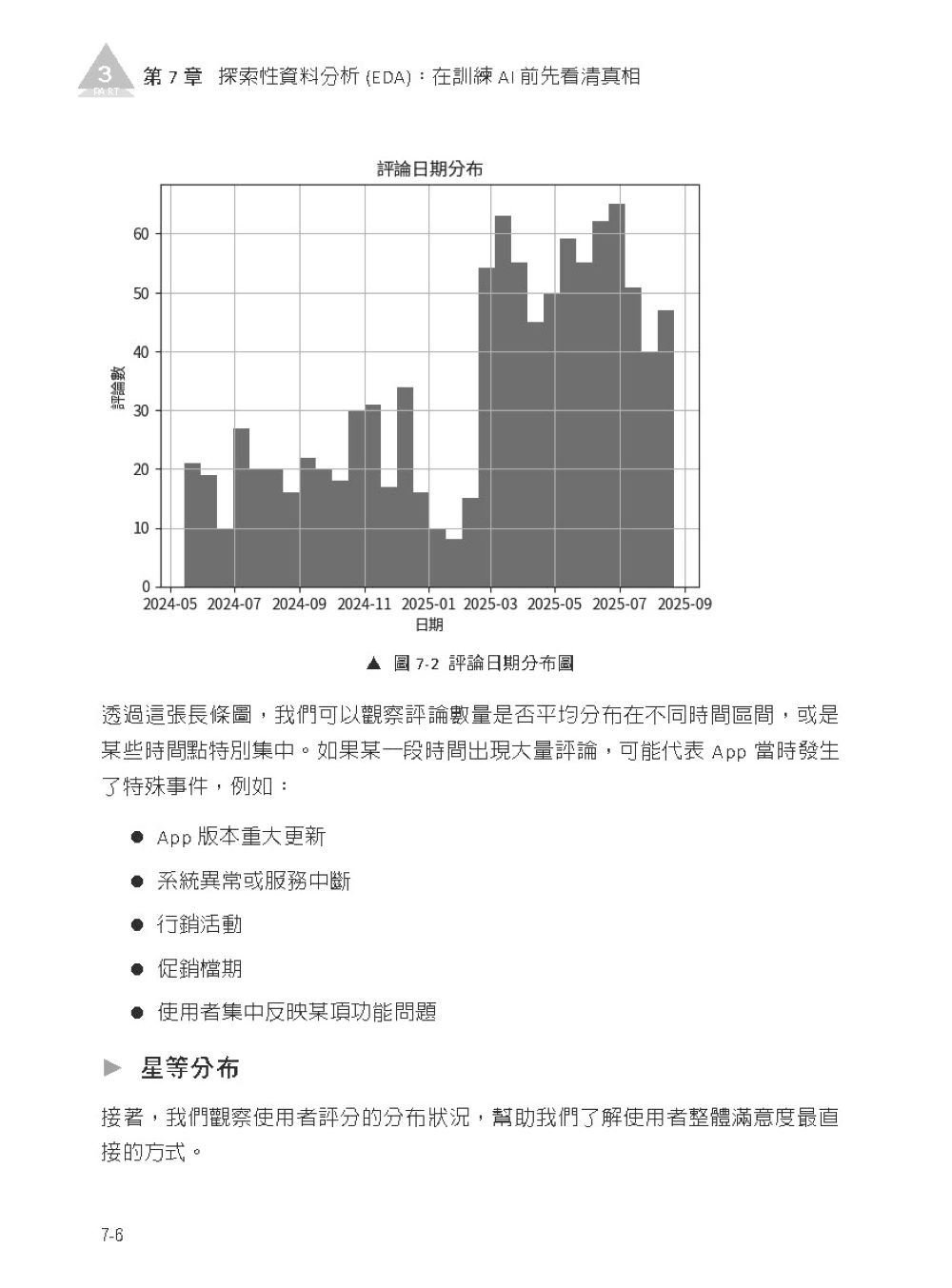
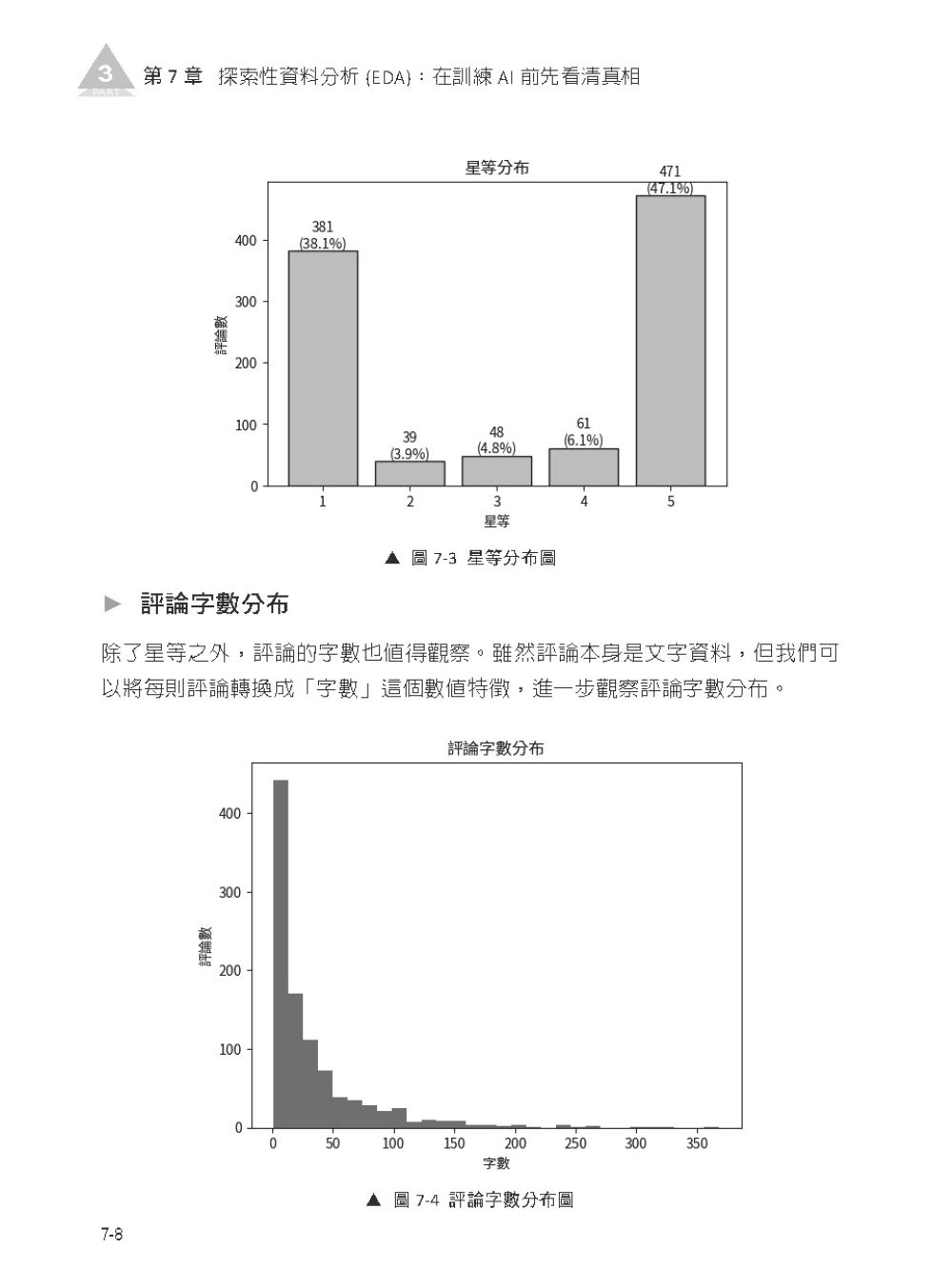
► 第 1 章 背景介紹 1-1 App 評論能告訴你什麼? 1-2 為什麼手動看評論行不通? 1-3 本書目標:讓你打造一個真正可運作的 AI 專案 1-4 打造 App 評論洞察系統的七個階段 1-5 為什麼這本書特別適合非技術背景的讀者? ► 第 2 章 小白也能上手的開發工具箱清單 2-1 選工具的哲學:便宜、好用、能快速上手 2-2 Google Colab:開啟你的雲端實驗室 2-3 工具包備忘錄:實作中會遇到的「工具」預覽 2-4 工具上場時機:每個階段該用什麼、在哪一章使用 ▍第 2 篇 數據採集實戰 — 打造自動化爬蟲機器人 ► 第 3 章 初探爬蟲—從App Store 與 Google Play搬回資料 3-1 爬蟲原理白話解說: 模擬人類行為,自動取得網頁資訊 3-2 找出資料來源:評論從哪裡被取得? 3-3 工具挑選:選擇最合適的工具 3-4 建立欄位清單:資料收集前的最後確認 ► 第 4 章 打造你的第一個評論爬蟲 4-1 爬蟲邏輯設計:抓取策略與架構圖 4-2 環境準備:套件安裝與匯入 4-3 實作 App Store 評論爬蟲 4-4 實作 Google Play 評論爬蟲 4-5 延伸選讀:使用 SerpApi 取得更多 App Store 歷史評論 ► 第 5 章 評論資料取得、整理與保存 5-1 讓評論資料取得流程更穩定 5-2 結構化儲存: 將散亂的資料存成好讀的 CSV 或 Excel 檔案 5-3 將爬取資料寫入 Google 試算表 ▍第 3 篇 數據煉金術 — 從資料清理到視覺化分析 ► 第 6 章 數據大掃除:確保資料的品質 6-1 初步探索資料:找出需要清理的問題 6-2 資料前處理:去除特殊符號、處理重複資料與空值 ► 第 7 章 探索性資料分析 (EDA):在訓練 AI 前先看清真相 7-1 什麼是探索性資料分析(EDA)? 7-2 數值分布觀察:星等與評論長度 7-3 文字前處理:中文分詞與停用詞 7-4 找出代表性關鍵字:TF-IDF 7-5 文字視覺化:製作評論文字雲 ▍第 4 篇 AI 標註革命 — 結合LLM 的高效標註流程 ► 第 8 章 規則定義:如何教 AI 看懂人話? 8-1 標註任務設計:情感分類與自定義分類 8-2 標註工具實作:手動標註的流程與規範 8-3 標註工程的品質與一致性檢查 ► 第 9 章 利用 LLM 加速標註流程 9-1 為什麼我們需要 LLM 輔助標註? 9-2 提示詞工程:讓 AI 精準分類 9-3 環境準備:申請 API 金鑰與設定開發環境 9-4 LLM 自動標註程式實作:情感分類 9-5 LLM 自動標註程式實作:自定義分類 9-6 進行資料驗證,確認 AI 標註品質 9-7 標註資料:關鍵詞萃取與資料整合 ▍第 5 篇 深度學習實務 — BERT 模型的訓練與部署 ► 第 10 章 理解 BERT 模型的核心原理 10-1 為什麼 BERT 懂語境,而關鍵字搜尋不懂? 10-2 BERT 是如何「讀懂」一句話? 10-3 BERT 如何學習語言?預訓練的兩大任務 ► 第 11 章 手把手訓練你的 AI 分類器 11-1 資料集準備:訓練集與驗證集的切分 11-2 訓練模型程式碼逐行拆解 11-3 模型成效評估:什麼是 F1-score ?怎麼看模型準不準? 11-4 擴展應用:從情感分類到問題分類 ► 第 12 章 模型優化與 Hugging Face 部署 12-1 調整超參數:如何讓模型更聰明? 12-2 部署至 Hugging Face:建立你的雲端模型庫 ▍第 6 篇 系統視覺化 — 打造專業級分析儀表板 ► 第 13 章 儀表板系統設計與開發邏輯 13-1 產品設計思維: 使用者想看哪些關鍵圖表? 13-2 儀表板設計流程:從策略到視覺的五層思考 13-3 Excalidraw 快速畫出產品原型 13-4 Data Studio 製作基礎產品原型 ► 第 14 章 實作 AI 評論洞察系統 14-1 Vibe Coding 用自然語言「說」出你的系統 14-2 Vibe Coding 與 AI Coding 的差異 14-3 認識兩個工具:Google AI Studio 與 Google Apps Script 14-4 使用 Google AI Studio 進行系統開發 14-5 搞懂系統背後的設計邏輯 ▍第 7 篇 上線與維護 — 邁向正式產品之路 ► 第 15 章 系統測試與部署 15-1 為什麼我們需要進行系統測試與使用者測試? 15-2 透過持續迭代,完成最小可行產品 15-3 部署至自訂網域,隨時隨地分享你的專案成果 15-4 部署後的維護與更新流程 ► 第 16 章 專案回顧與未來擴展 16-1 從非技術小白到 AI 產品開發者的技能地圖 16-2 未來延伸:引入 AI Agent 進行工作流自動化 16-3 第五層技能:指揮層(Orchestration Layer) ▍結語:這只是起點 ▍致謝 |
序
| 導讀
在數位時代,App 已經成為人們生活的一部分。購物、娛樂、社交、運動、健康管理,幾乎都能透過手機完成。對使用者來說,選擇越多,期待也越高;一旦體驗不好,他們通常不會打電話給客服抱怨,而是直接在評論區留下一顆星,寫下「閃退」、「無法登入」、「付款失敗」、「客服都不回」,然後刪除App,轉向其他競品。 對產品團隊來說,這些評論是最直接的使用者回饋。量化數據能告訴你「發生了什麼事」,例如留存率下降、評分變低、轉換率下滑;但評論資料更接近「原因」。當使用者寫下「更新後每次開啟都閃退」、「付款一直失敗」、「客服都不回」,這些文字其實就是產品改善的線索。問題不在於評論沒有價值,而是它們太多、太亂、太難被系統化整理。 這本書要解決的,就是這個問題:如何用 AI 自動分析 App 評論,把大量文字變成可以支持決策的洞察。 |