







描述
內容簡介
推薦系統對電商的重要性好比大樓的地基,在既有的商品品項上創造更大的利潤一直是演算法工程師深度挖掘的目標。深度學習早就跳出CV和NLP的範疇,進而分析購買行為。本書不但深入介紹了DNN,更將序列資料中最重要的Embedding包含進來,進而介紹各大巨頭的推薦系統,包括了特徵工程、注意力機制等,也說明了Youtube、Facebook、阿里巴巴等推薦系統的原理介紹,全書還使用了Spark MLlib來分析幾個案例,讓平凡百姓也能一窺矽谷等級實作的精彩內容。
✤ 本書特色
本書希望討論的是推薦系統相關的「經典的」或「前端的」技術內容。其中注重討論的是深度學習在推薦系統業界的應用。需要明確的是,本書不是一本機器學習或深度學習的入門書,雖然書中會穿插機器學習基礎知識的介紹,但絕大多數內容建立在讀者有一定的機器學習基礎上;本書也不是一本純理論書籍,而是一本從工程師的實際經驗角度出發,介紹深度學習在推薦系統領域的應用方法,以及推薦系統相關的業界前端知識的技術書。
✤ 本書讀者群
本書的目標讀者可分為兩種:
一種是網際網路企業相關方向,特別是推薦、廣告、搜尋領域的從業者。希望這些同行能夠透過學習本書熟悉深度學習推薦系統的發展脈絡,釐清每個關鍵模型和技術的細節,進而在工作中應用甚至改進這些技術點。另一種是有一定機器學習基礎,希望進入推薦系統領域的同好、在校學生。本書儘量用平實的語言,從細節出發,介紹推薦系統技術的相關原理和應用方法,幫助讀者從零開始建置前端、實用的推薦系統知識系統。
作者簡介
王喆
畢業於清華大學計算機科學與技術系,美國流媒體公司Roku資深機器學習工程師,推薦系統架構負責人。
曾任Hulu高級研究工程師,品友互動廣告效果算法組負責人。
清華大學KEG實驗室學術搜索引擎AMiner早期發起人之一。
主要研究方向為推薦系統、計算廣告、個性化搜索,發表相關領域學術論文7篇,擁有專利3項,是《百面機器學習:算法工程師帶你去面試》等技術書的聯合作者。
曾擔任KDD、CIKM等國際會議審稿人。
目錄
01 網際網路的增長引擎—推薦系統
1.1 為什麼推薦系統是網際網路的增長引擎
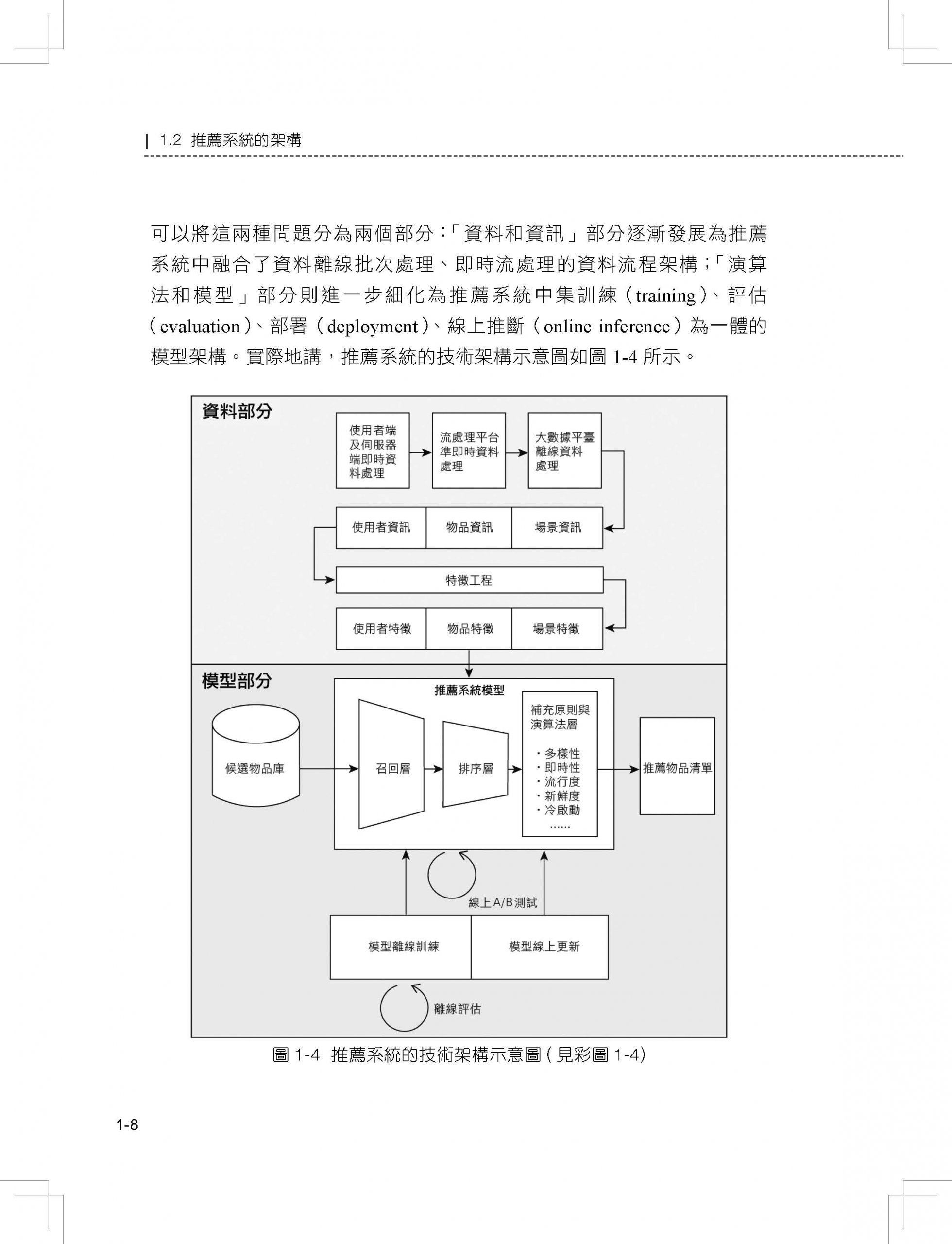
1.2 推薦系統的架構
1.3 本書的整體結構
02 前深度學習時代—推薦系統的進化之路
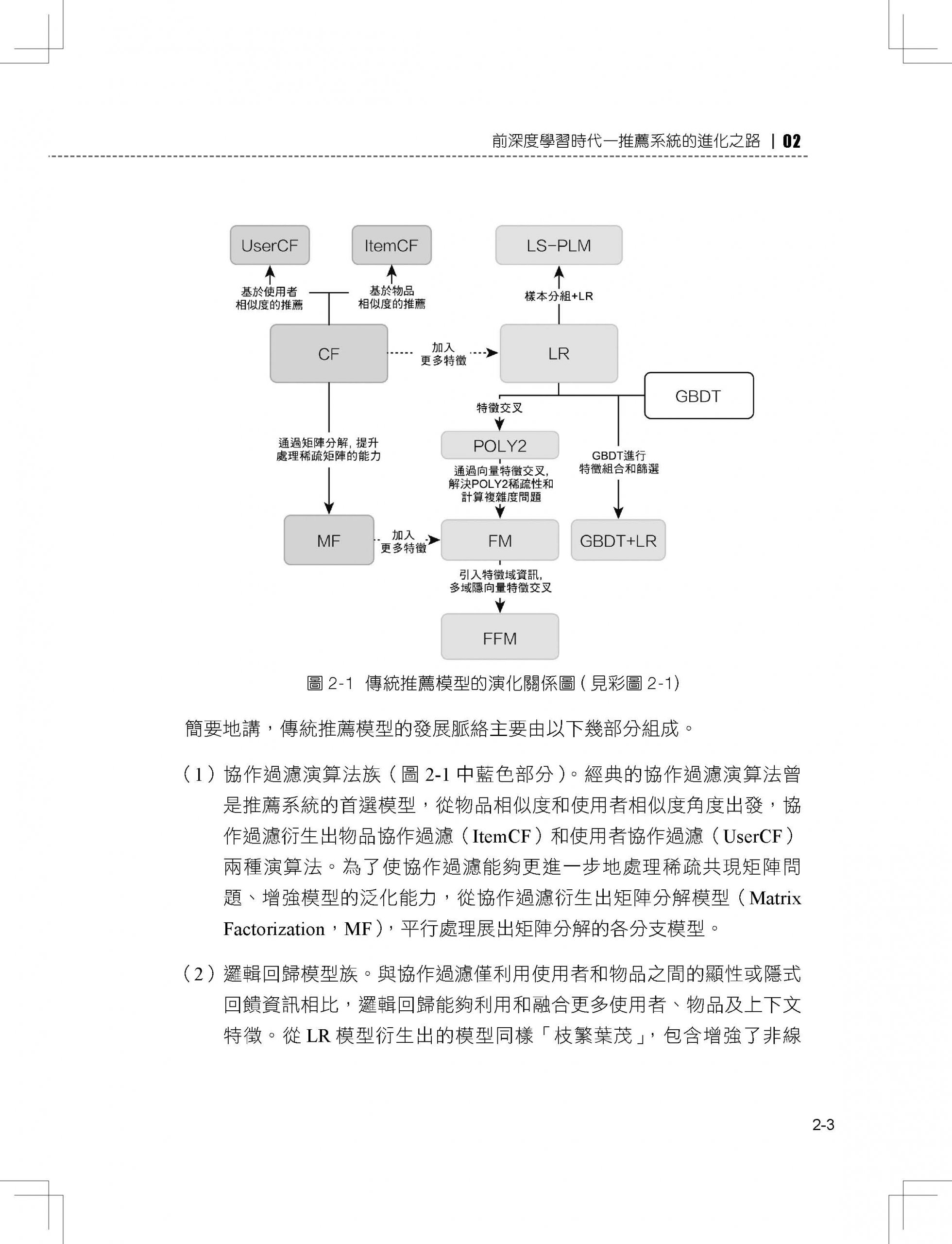
2.1 傳統推薦模型的演化關係圖
2.2 協作過濾—經典的推薦演算法
2.3 矩陣分解演算法—協作過濾的進化
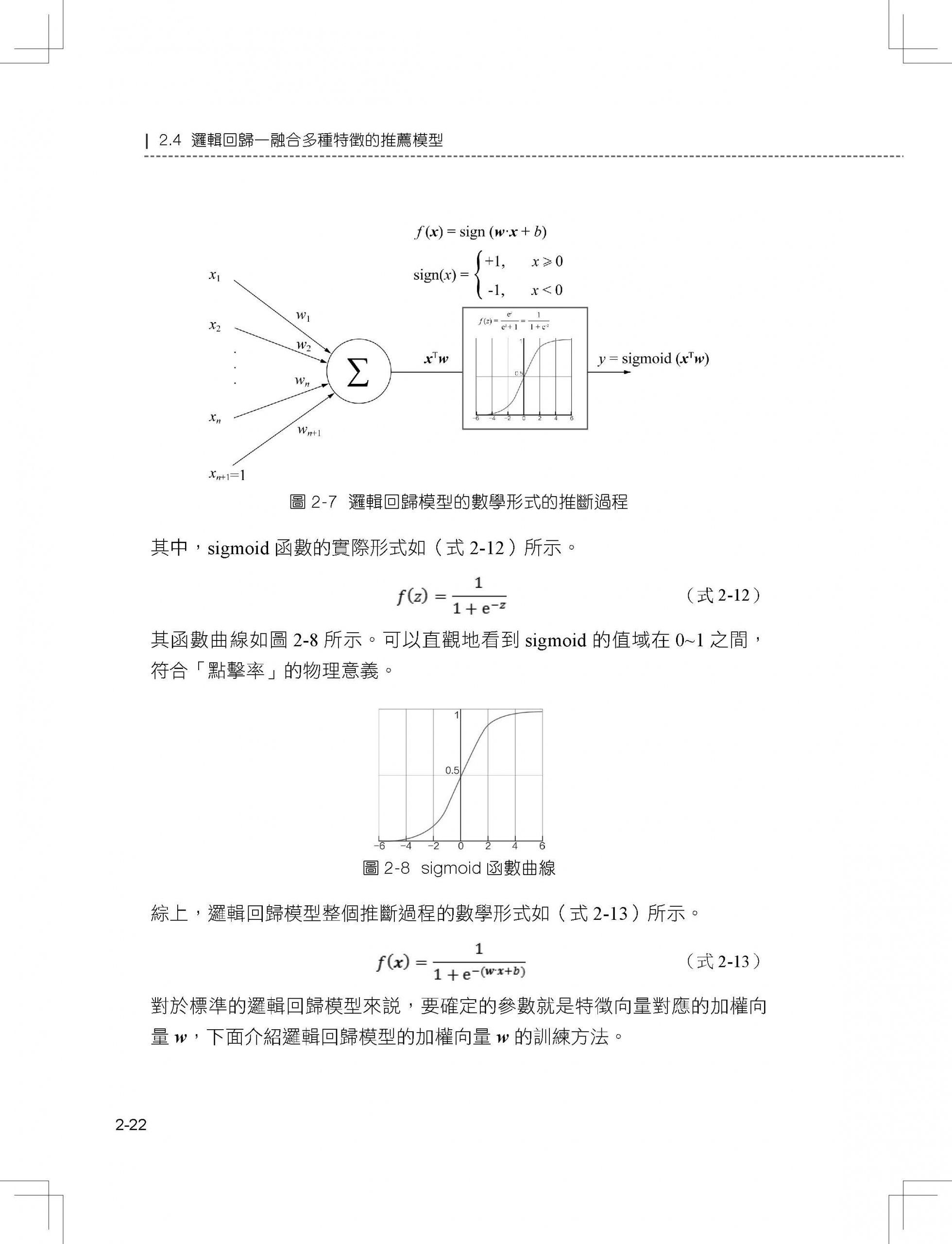
2.4 邏輯回歸—融合多種特徵的推薦模型
2.5 從FM 到FFM—自動特徵交換的解決方案
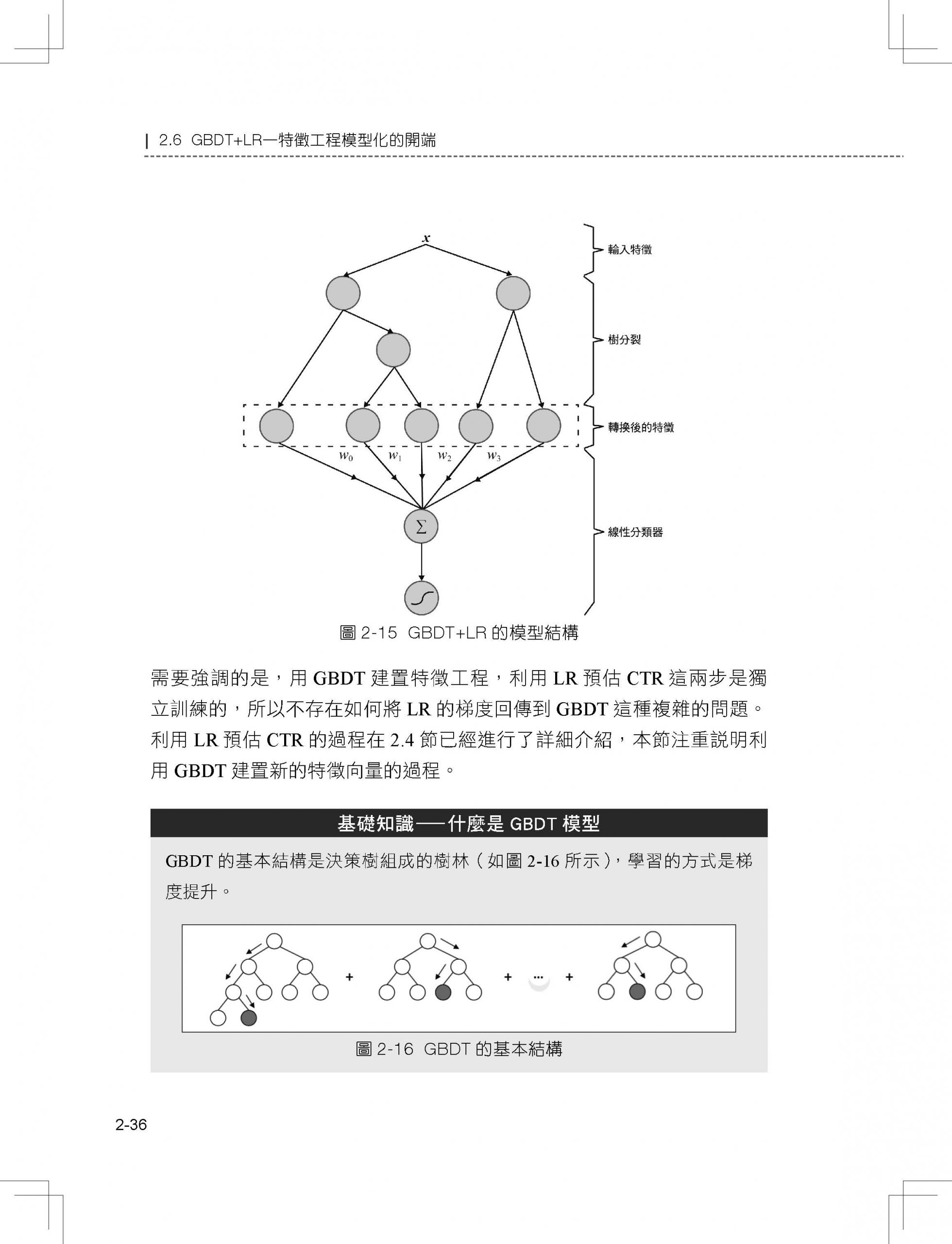
2.6 GBDT+LR—特徵工程模型化的開端
2.7 LS-PLM—阿里巴巴曾經的主流推薦模型
2.8 歸納—深度學習推薦系統的前夜
03 浪潮之巔—深度學習在推薦系統中的應用
3.1 深度學習推薦模型的演化關係圖
3.2 AutoRec—單隱層神經網路推薦模型
3.3 Deep Crossing 模型—經典的深度學習架構
3.4 NeuralCF 模型—CF 與深度學習的結合
3.5 PNN 模型—加強特徵交換能力
3.6 Wide&Deep 模型—記憶能力和泛化能力的綜合
3.7 FM 與深度學習模型的結合
3.8 注意力機制在推薦模型中的應用
3.9 DIEN—序列模型與推薦系統的結合
3.10 強化學習與推薦系統的結合
3.11 歸納—推薦系統的深度學習時代
04 Embedding 技術在推薦系統中的應用
4.1 什麼是Embedding
4.2 Word2vec—經典的Embedding 方法
4.3 Item2vec—Word2vec 在推薦系統領域的推廣
4.4 Graph Embedding—引用更多結構資訊的圖嵌入技術
4.5 Embedding 與深度學習推薦系統的結合
4.6 局部敏感雜湊—讓Embedding 插上翅膀的快速搜尋方法
4.7 歸納—深度學習推薦系統的核心操作
05 多角度檢查推薦系統
5.1 推薦系統的特徵工程
5.2 推薦系統召回層的主要策略
5.3 推薦系統的即時性
5.4 如何合理設定推薦系統中的最佳化目標
5.5 推薦系統中比模型結構更重要的是什麼
5.6 冷啟動的解決辦法
5.7 探索與利用
06 深度學習推薦系統的工程實現
6.1 推薦系統的資料流程
6.2 推薦模型離線訓練之Spark MLlib
6.3 推薦模型離線訓練之Parameter Server
6.4 推薦模型離線訓練之TensorFlow
6.5 深度學習推薦模型的上線部署
6.6 工程與理論之間的權衡
07 推薦系統的評估
7.1 離線評估方法與基本評價指標
7.2 直接評估推薦序列的離線指標
7.3 更接近線上環境的離線評估方法—Replay
7.4 A/B 測試與線上評估指標
7.5 快速線上評估方法—Interleaving
7.6 推薦系統的評估系統
08 深度學習推薦系統的前端實作
8.1 Facebook 的深度學習推薦系統
8.2 Airbnb 基於Embedding 的即時搜尋推薦系統
8.3 YouTube 深度學習視訊推薦系統
8.4 阿里巴巴深度學習推薦系統的進化
09 建置屬於你的推薦系統知識架構
9.1 推薦系統的整體知識架構圖
9.2 推薦模型發展的時間線
9.3 如何成為一名優秀的推薦工程師
A 後記
序
前言
推薦系統的深度學習時代
1992 年,全錄公司帕拉奧圖研究中心(Xerox Palo Alto Research Center)的David Goldberg 等學者建立了應用協作過濾演算法的推薦系統1。如果以此作為推薦系統領域的開端,那麼推薦系統距今已有28 年歷史。在這28年中,特別是近5 年,推薦系統技術的發展日新月異。毫無疑問,為推薦系統插上翅膀的,是深度學習帶來的技術革命。2012 年,隨著深度學習網路AlexNet 在著名的ImageNet 競賽中一舉奪魁2,深度學習引爆了影像、語音、自然語言處理等領域,就連網際網路商業化最成功、機器學習模型應用最廣泛的推薦、廣告和搜尋領域,也被深度學習的浪潮一一席捲。2015年,隨著微軟、Google、百度、阿里等公司成功地在推薦、廣告等業務場景中應用深度學習模型,推薦系統領域正式邁入了深度學習時代。
處於深度學習時代的推薦系統演算法工程師(以下簡稱推薦工程師)是幸運的,我們見證了最深刻、也是最快速的技術變革;但某種意義上,我們也是不幸的,因為在這個技術日新月異、模型高速演化的時代,一不小心我們就處於被淘汰的邊緣。然而,這個時代,終究為對技術充滿熱情的工程師留下了充足的發展空間。在熱忱的推薦工程師架設自己的技術藍圖、豐富自己的技術儲備時,希望本書能成為他們腦海中推薦系統技術的思維導圖,幫助他們建置深度學習推薦系統的技術架構。
✤ 本書緣起
寫作本書的動機,一是我一直有結構化地整理推薦系統知識的願望,二是電子工業出版社編輯的邀請。2018 年12 月,鄭柳潔編輯看了我的技術專欄和一些公眾號文章,與我聯繫,邀請我寫一本推薦或廣告演算法方面的技術書。那時,我剛和Hulu 的同事們結束了《百面機器學習:演算法工程師帶你去面試》的撰寫工作。這本講機器學習面試的書市場反響不錯,著實幫助了很多同學。這段寫作經歷讓我體會到,認真做一件事情、認真寫技術內容是能夠讓很多讀者受益的。我已在推薦和廣告領域工作了8 個年頭,正好經歷了深度學習在推薦系統領域發展的浪潮。因此,我選擇了「深度學習推薦系統」這個主題,期望能把自己有限的知識和經驗分享給對這個領域有興趣的同學和同行。
✤ 本書特色
本書希望討論的是推薦系統相關的「經典的」或「前端的」技術內容。其中注重討論的是深度學習在推薦系統業界的應用。需要明確的是,本書不是一本機器學習或深度學習的入門書,雖然書中會穿插機器學習基礎知識的介紹,但絕大多數內容建立在讀者有一定的機器學習基礎上;本書也不是一本純理論書籍,而是一本從工程師的實際經驗角度出發,介紹深度學習在推薦系統領域的應用方法,以及推薦系統相關的業界前端知識的技術書。
✤ 本書讀者群
本書的目標讀者可分為兩種:
一種是網際網路企業相關方向,特別是推薦、廣告、搜尋領域的從業者。希望這些同行能夠透過學習本書熟悉深度學習推薦系統的發展脈絡,釐清每個關鍵模型和技術的細節,進而在工作中應用甚至改進這些技術點。另一種是有一定機器學習基礎,希望進入推薦系統領域的同好、在校學生。本書儘量用平實的語言,從細節出發,介紹推薦系統技術的相關原理和應用方法,幫助讀者從零開始建置前端、實用的推薦系統知識系統。