

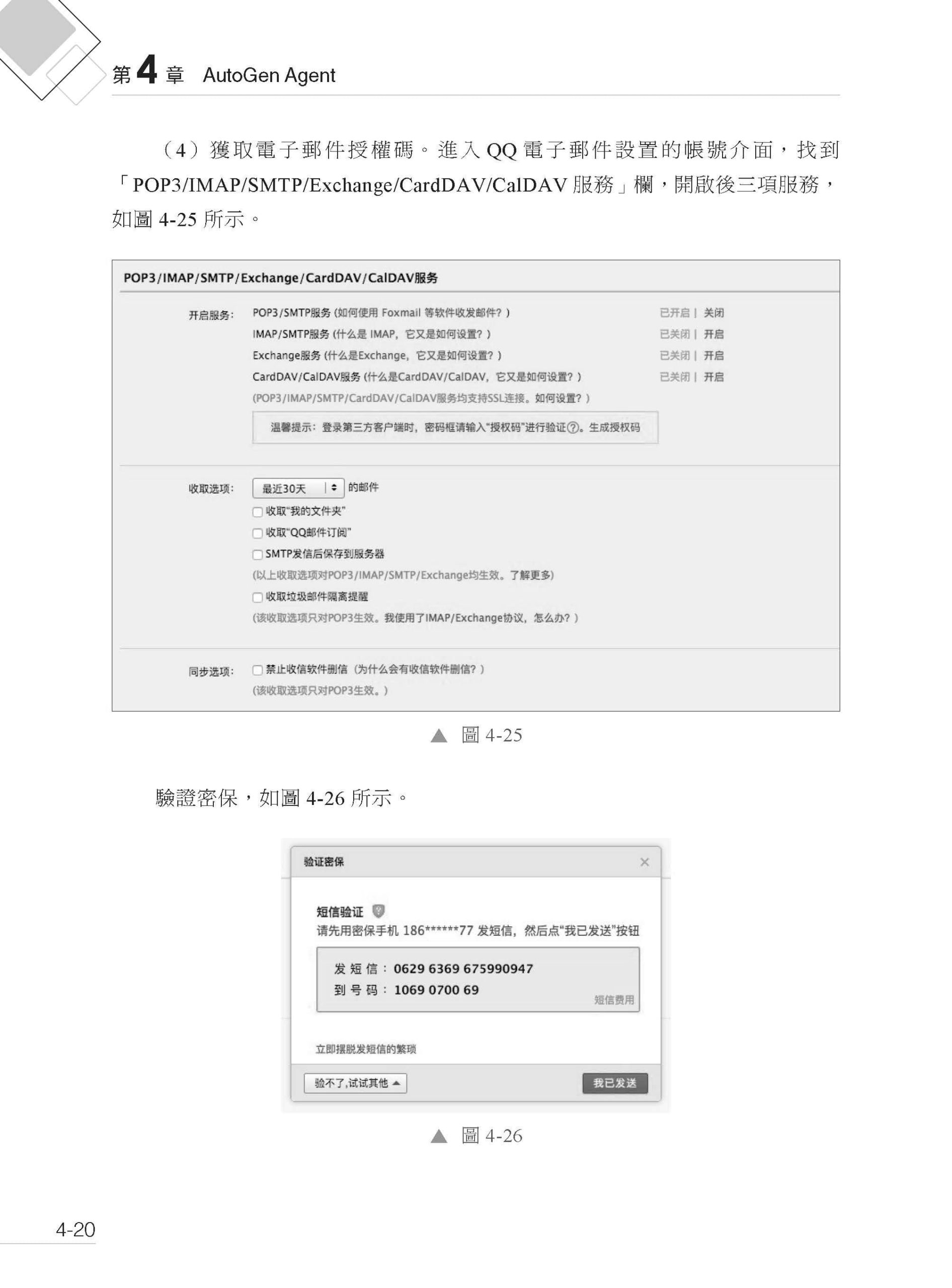





描述
內容簡介
|
作者簡介
| 唐宇迪
華東理工大學博士,精通機器學習演算法,主攻計算機視覺方向,著有《跟迪哥學Python數據分析與機器學習實戰》一書,線上選課學員超過30萬人,累計開發課程50餘門,覆蓋人工智慧的各個熱門方向。聯通、移動、中信等公司的特邀企業培訓導師,開展線下與直播培訓百餘場,具有豐富的授課經驗。課程通俗易懂,擅長透過接地氣的方式講解複雜的演算法問題。
尹澤明 北京郵電大學博士,多年來致力於人工智慧、大數據、區塊鏈等新一代資訊技術的創新應用,曾主持過電信運營企業全國集中智能客服系統和基於區塊鏈的身分認證系統的建設和運營工作,率先嘗試和推動ASR、NLP、RPA等技術在面向公眾用戶和政企客戶服務場景中的應用。 |
目錄
| ▌第1章 Agent 框架與應用
1.1 初識Agent 1.1.1 感知能力 1.1.2 思考能力 1.1.3 動作能力 1.1.4 記憶能力 1.2 Agent 框架 1.2.1 Agent 框架理念 1.2.2 常用的Agent 框架 1.3 Multi-Agent 多角色協作 1.3.1 SOP 拆解 1.3.2 角色扮演 1.3.3 回饋迭代 1.3.4 監督控制 1.3.5 實例說明 1.4 Agent 應用分析 1.4.1 Agent 自身場景落地 1.4.2 Agent 結合RPA 場景落地 1.4.3 Agent 多態具身機器人
▌第2章 使用Coze 打造專屬Agent 2.1 Coze 平臺 2.1.1 Coze 平臺的優勢 2.1.2 Coze 平臺的介面 2.1.3 Coze 平臺的功能模組 2.2 Agent 的實現流程 2.2.1 Agent 需求分析 2.2.2 Agent 架構設計 2.3 使用Coze 平臺打造專屬的NBA 新聞幫手 2.3.1 需求分析與設計思路制定 2.3.2 NBA 新聞幫手的實現與測試 2.4 使用Coze 平臺打造小紅書文案幫手 2.4.1 需求分析與設計思路制定 2.4.2 小紅書文案幫手的實現與測試
▌第3章 打造專屬領域的客服聊天機器人 3.1 客服聊天機器人概述 3.1.1 客服聊天機器人價值簡介 3.1.2 客服聊天機器人研發工具 3.2 AI 課程客服聊天機器人整體架構 3.2.1 前端功能設計 3.2.2 後端功能設計 3.3 AI 課程客服聊天機器人應用實例
▌第4章 AutoGen Agent 開發框架實戰 4.1 AutoGen 開發環境 4.1.1 Anaconda 4.1.2 PyCharm 4.1.3 AutoGen Studio 4.2 AutoGen Studio 案例 4.2.1 案例介紹 4.2.2 AutoGen Studio 模型配置 4.2.3 AutoGen Studio 技能配置 4.2.4 AutoGen Studio 當地語系化配置
▌第5章 生成式代理——以史丹佛AI 小鎮為例 5.1 生成式代理簡介 5.2 史丹佛AI 小鎮專案簡介 5.2.1 史丹佛AI 小鎮專案背景 5.2.2 史丹佛AI 小鎮設計原理 5.2.3 史丹佛AI 小鎮典型情景 5.2.4 互動體驗 5.2.5 技術實現 5.2.6 社會影響 5.3 史丹佛AI 小鎮體驗 5.3.1 資源準備 5.3.2 部署運行 5.4 生成式代理的行為和互動 5.4.1 模擬個體和個體間的交流 5.4.2 環境互動 5.4.3 範例「日常生活中的一天」 5.4.4 自發社會行為 5.5 生成式代理架構 5.5.1 記憶和檢索 5.5.2 反思 5.5.3 計畫和反應 5.6 沙箱環境實現 5.7 評估 5.7.1 評估程式 5.7.2 條件 5.7.3 分析 5.7.4 結果 5.8 生成式代理的進一步探討
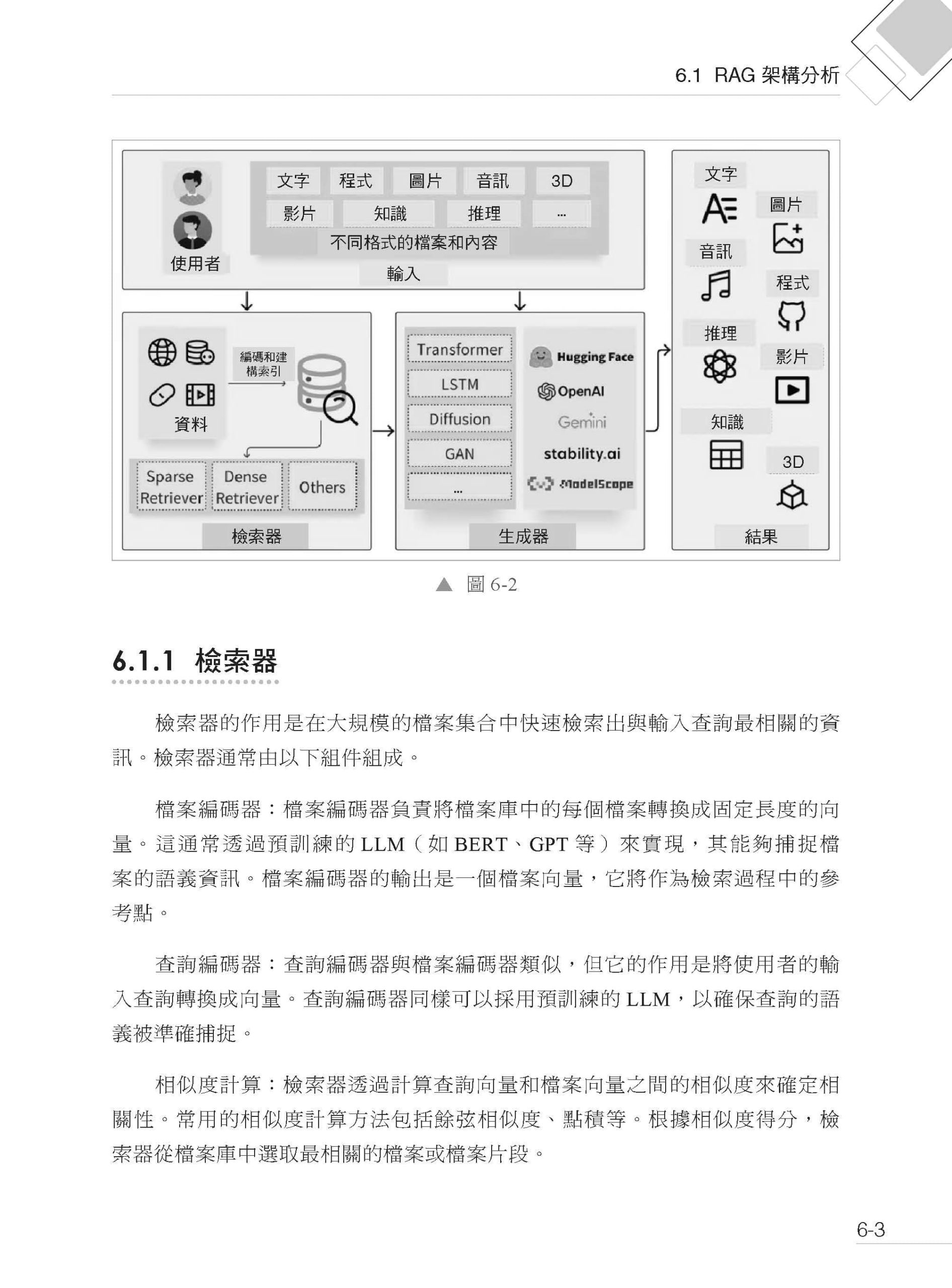
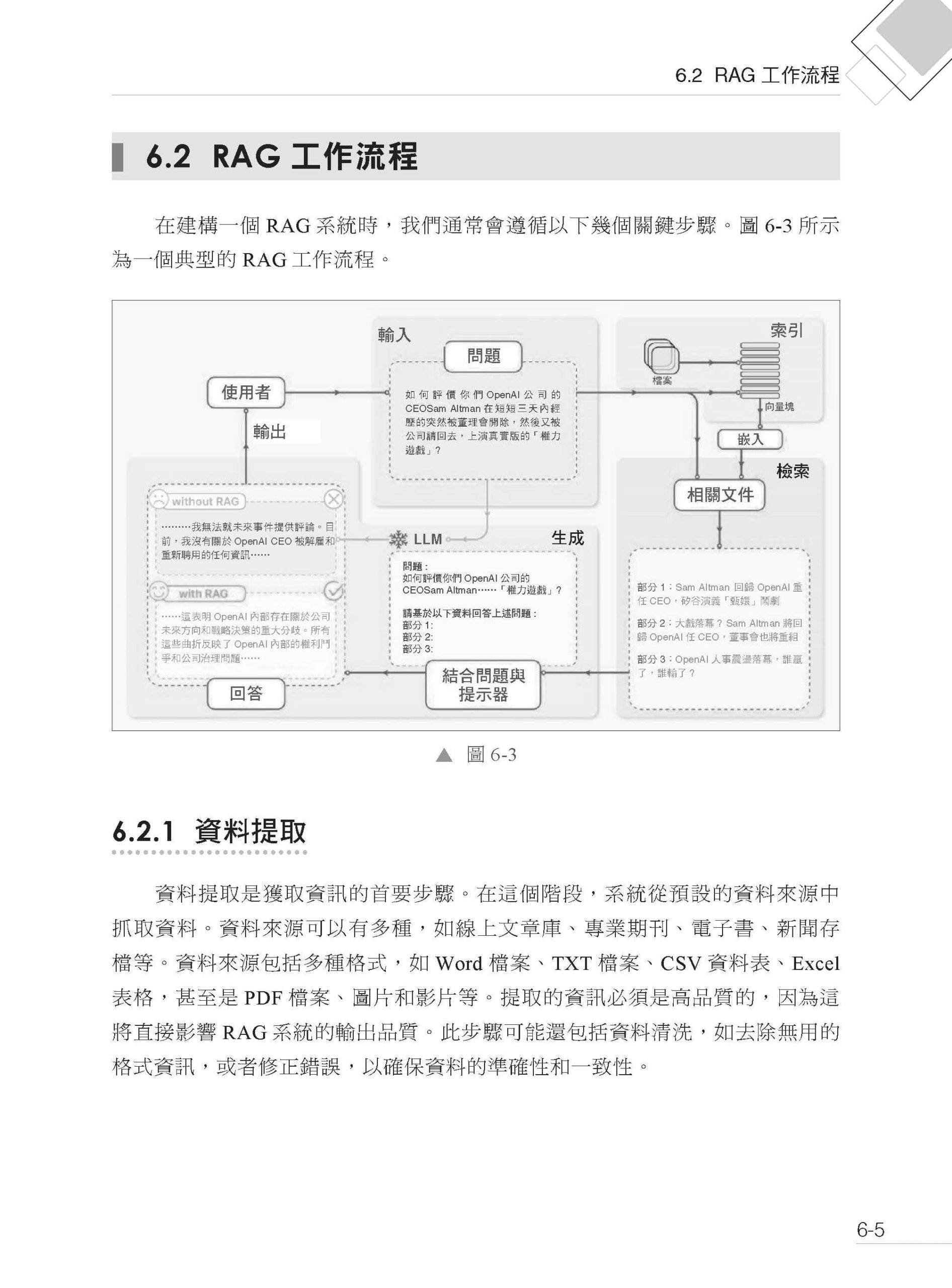
▌第6章 RAG 檢索架構分析與應用 6.1 RAG 架構分析 6.1.1 檢索器 6.1.2 生成器 6.2 RAG 工作流程 6.2.1 資料提取 6.2.2 文字分割 6.2.3 向量化 6.2.4 資料檢索 6.2.5 注入提示 6.2.6 提交給LLM 6.3 RAG 與微調和提示詞工程的比較 6.4 基於LangChain 的RAG 應用實戰 6.4.1 基礎環境準備 6.4.2 收集和載入資料 6.4.3 分割原始檔案 6.4.4 資料向量化後入庫 6.4.5 定義資料檢索器 6.4.6 建立提示 6.4.7 呼叫LLM 生成答案
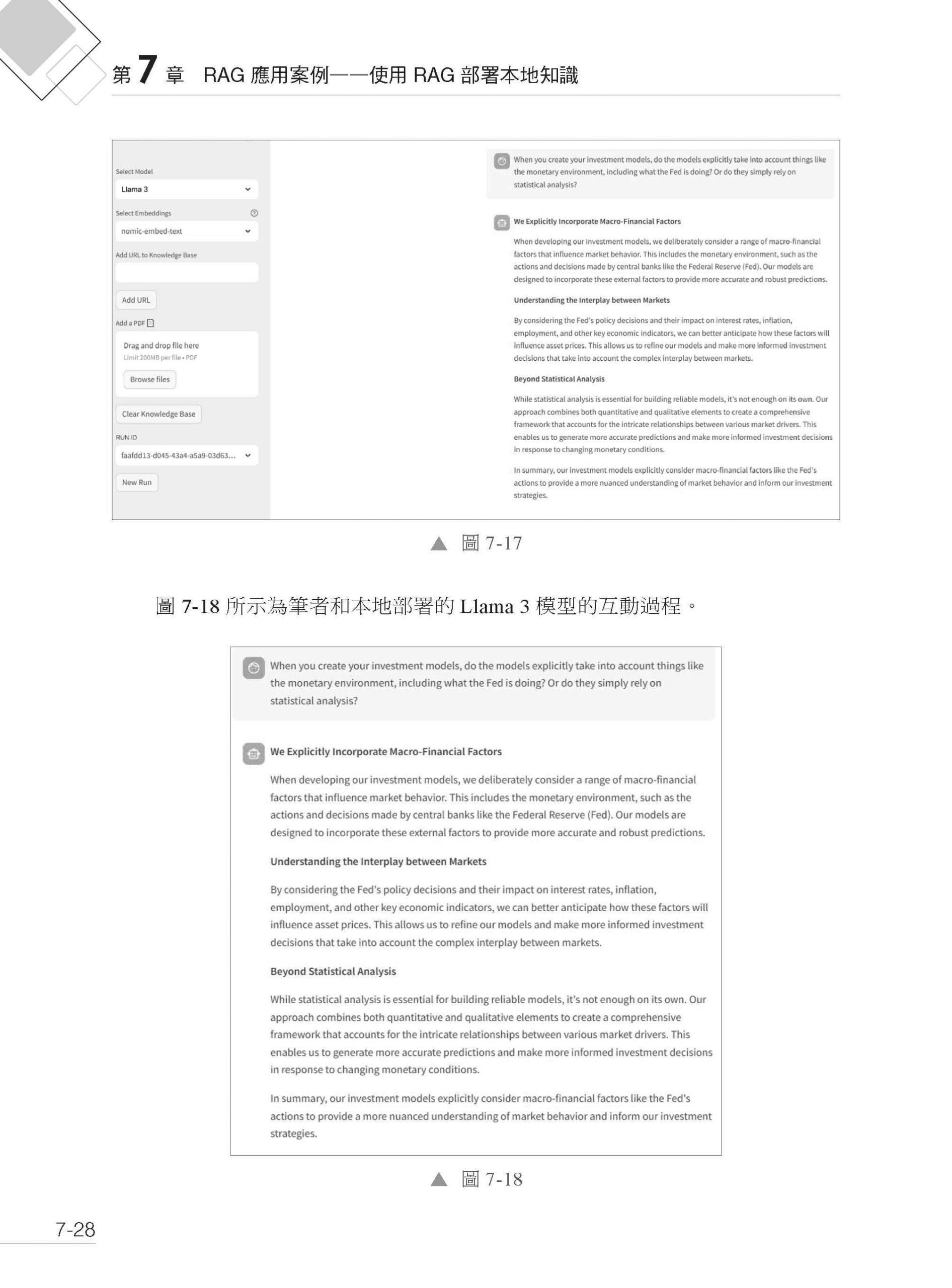
▌第7章 RAG 應用案例——使用RAG 部署本地知識 7.1 部署本地環境及安裝資料庫 7.1.1 在Python 環境中建立虛擬環境並安裝所需的函式庫 7.1.2 安裝phidata 函式庫 7.1.3 安裝和配置Ollama 7.1.4 基於Ollama 安裝Llama 3 模型和nomic-embed-text 模型 7.1.5 下載和安裝Docker 並用Docker 下載向量資料庫的鏡像 7.2 程式部分及前端展示配置 7.2.1 assistant.py 程式 7.2.2 app.py 程式 7.2.3 啟動AI 互動頁面 7.2.4 前端互動功能及對應程式 7.3 呼叫雲端大語言模型 7.3.1 配置大語言模型的API Key 7.3.2 修改本地RAG 應用程式 7.3.3 啟動並呼叫雲端大語言模型
▌第8章 LLM 本地部署與應用 8.1 硬體準備 8.2 作業系統選擇 8.3 架設環境所需組件 8.4 LLM 常用知識介紹 8.4.1 分類 8.4.2 參數大小 8.4.3 訓練過程 8.4.4 模型類型 8.4.5 模型開發框架 8.4.6 量化大小 8.5 量化技術 8.6 模型選擇 8.6.1 通義千問 8.6.2 ChatGLM 8.6.3 Llama 8.7 模型應用實現方式 8.7.1 Chat 8.7.2 RAG 8.7.3 高效微調 8.8 通義千問1.5-0.5B 本地Windows 部署實戰 8.8.1 介紹 8.8.2 環境要求 8.8.3 相依函式庫安裝 8.8.4 快速使用 8.8.5 量化 8.9 基於LM Studio 和AutoGen Studio 使用通義千問 8.9.1 LM Studio 介紹 8.9.2 AutoGen Studio 介紹 8.9.3 LM Studio 的使用 8.9.4 在LM Studio 上啟動模型的推理服務 8.9.5 啟動AutoGen Studio 服務 8.9.6 進入AutoGen Studio 介面 8.9.7 使用AutoGen Studio 配置LLM 服務 8.9.8 把Agent 中的模型置換成通義千問 8.9.9 運行並測試Agent
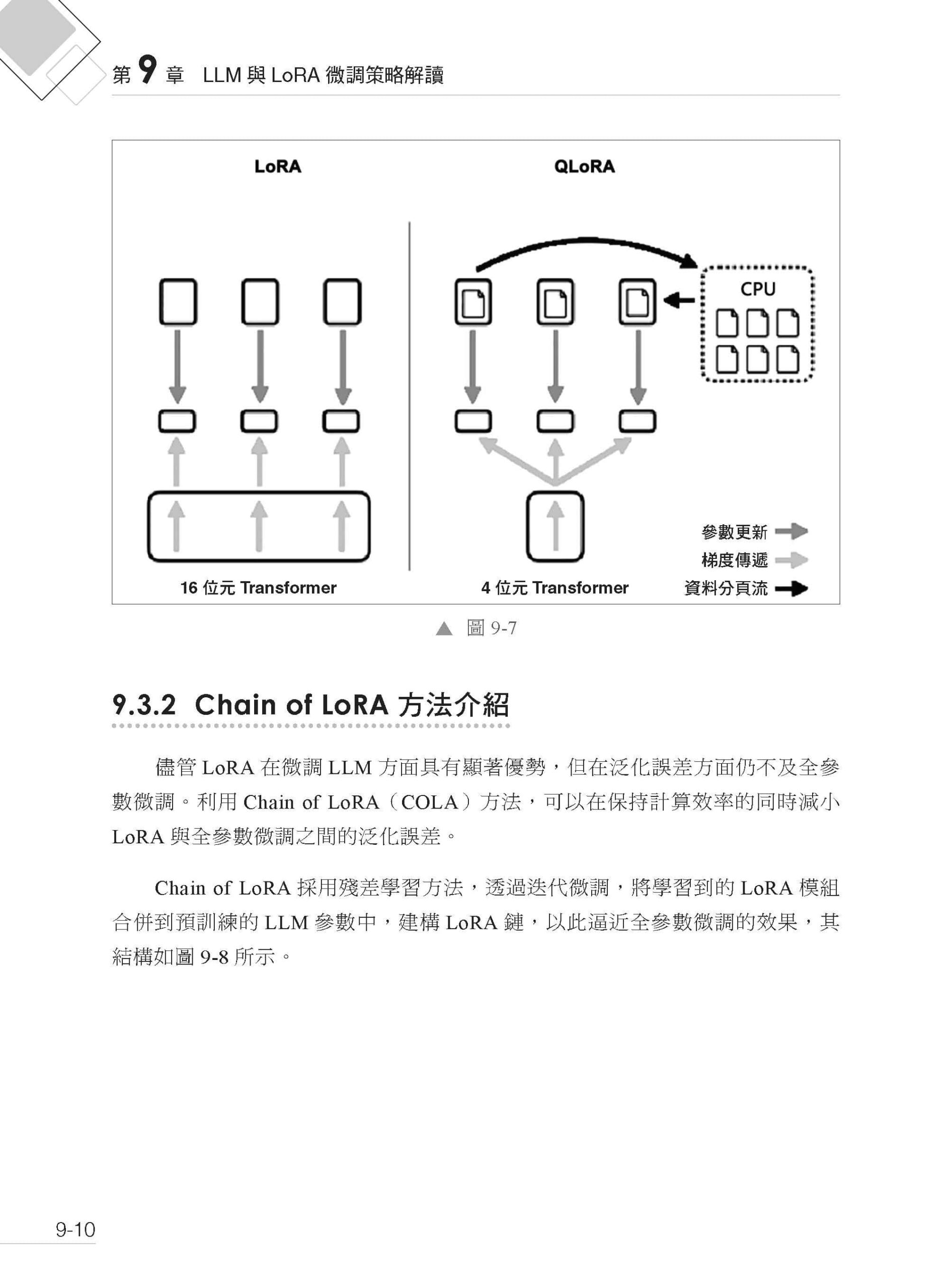
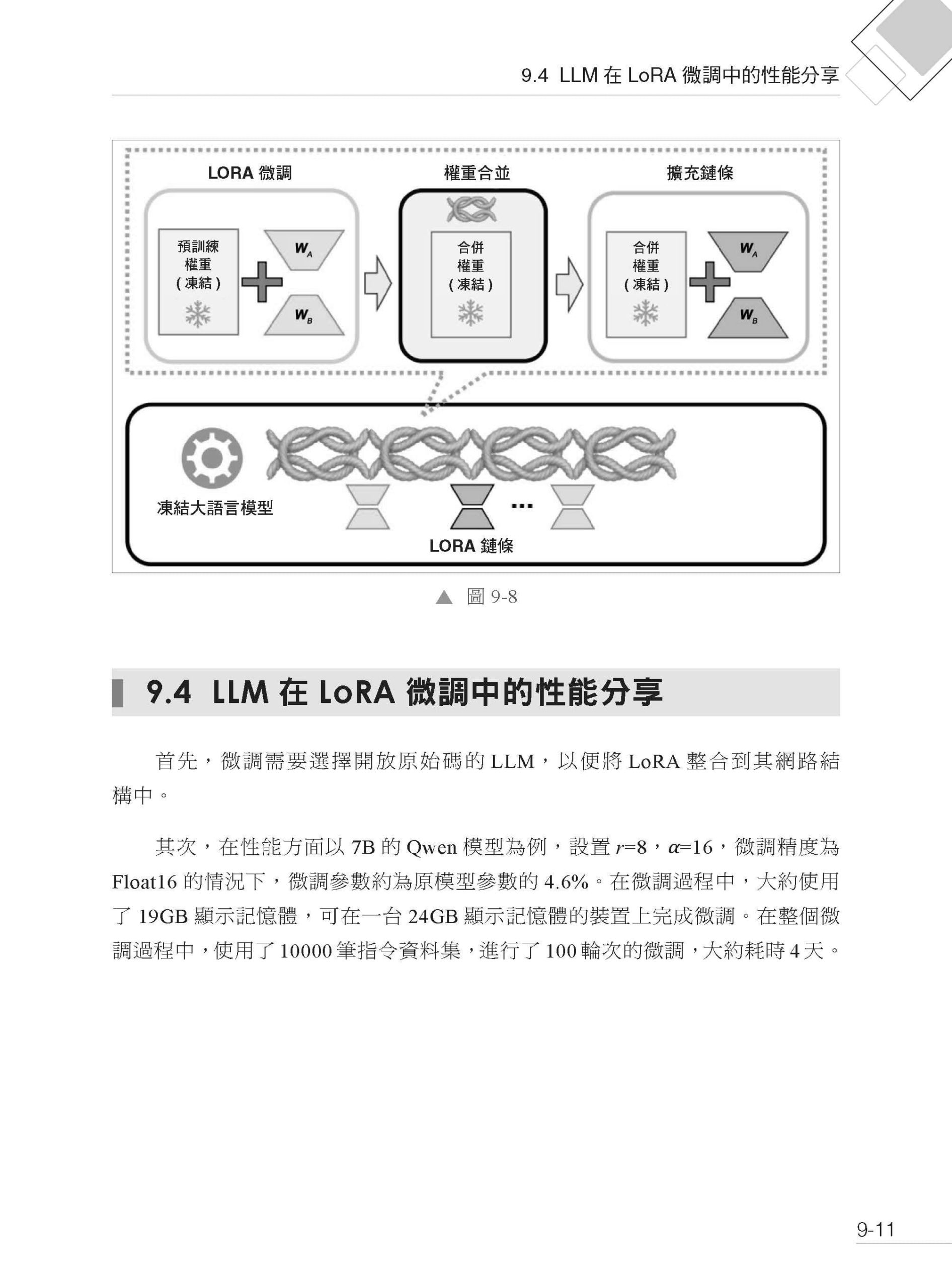
▌第9章 LLM 與LoRA 微調策略解讀 9.1 LoRA 技術 9.1.1 LoRA 簡介 9.1.2 LoRA 工作原理 9.1.3 LoRA 在LLM 中的應用 9.1.4 實施方案 9.2 LoRA 參數說明 9.2.1 注意力機制中的LoRA 參數選擇 9.2.2 LoRA 網路結構中的參數選擇 9.2.3 LoRA 微調中基礎模型的參數選擇 9.3 LoRA 擴充技術介紹 9.3.1 QLoRA 介紹 9.3.2 Chain of LoRA 方法介紹 9.4 LLM 在LoRA 微調中的性能分享
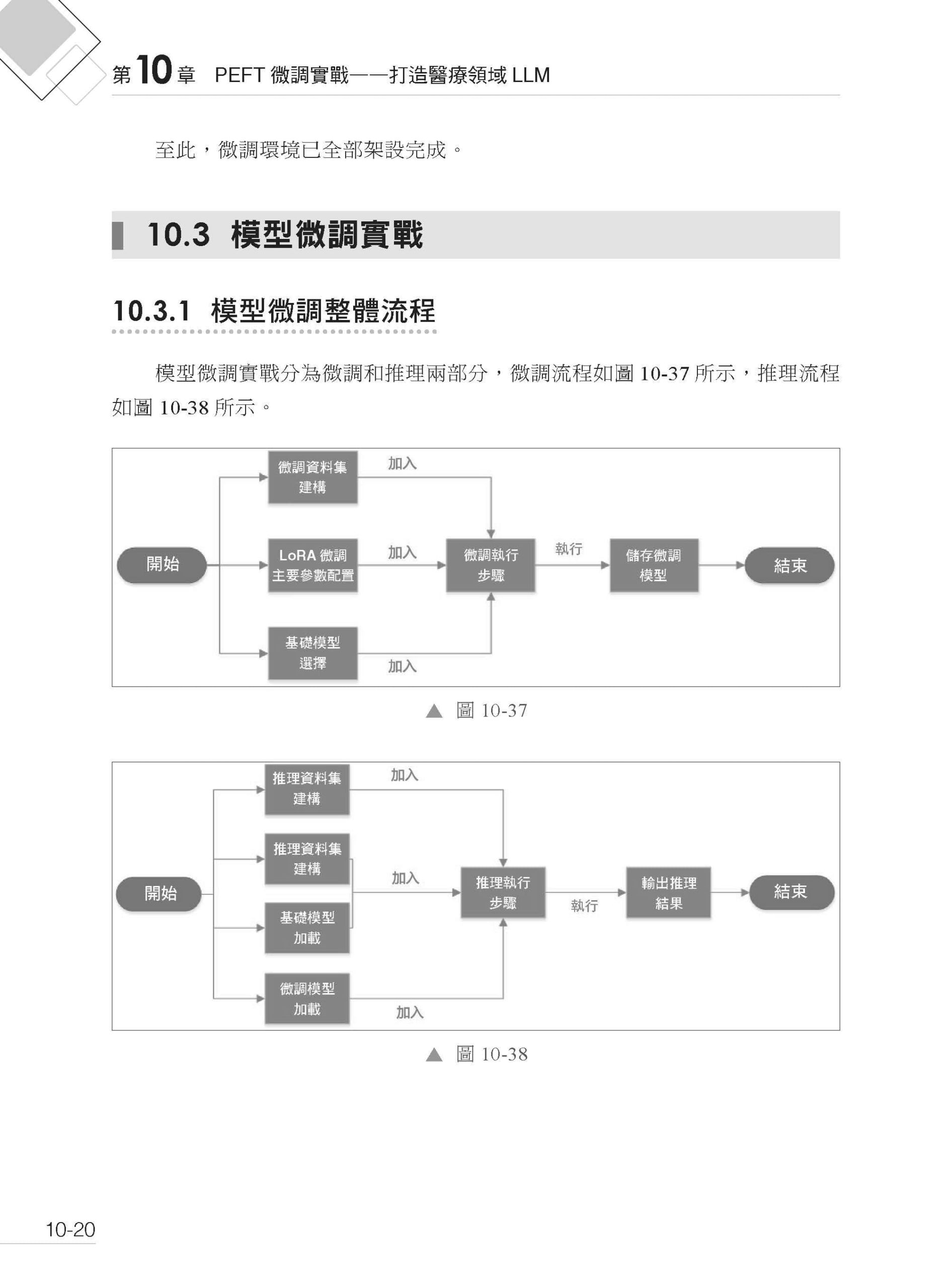
▌第10章 PEFT 微調實戰——打造醫療領域LLM 10.1 PEFT 介紹 10.2 工具與環境準備 10.2.1 工具安裝 10.2.2 環境架設 10.3 模型微調實戰 10.3.1 模型微調整體流程 10.3.2 專案目錄結構說明 10.3.3 基礎模型選擇 10.3.4 微調資料集建構 10.3.5 LoRA 微調主要參數配置 10.3.6 微調主要執行流程 10.3.7 運行模型微調程式 10.4 模型推理驗證
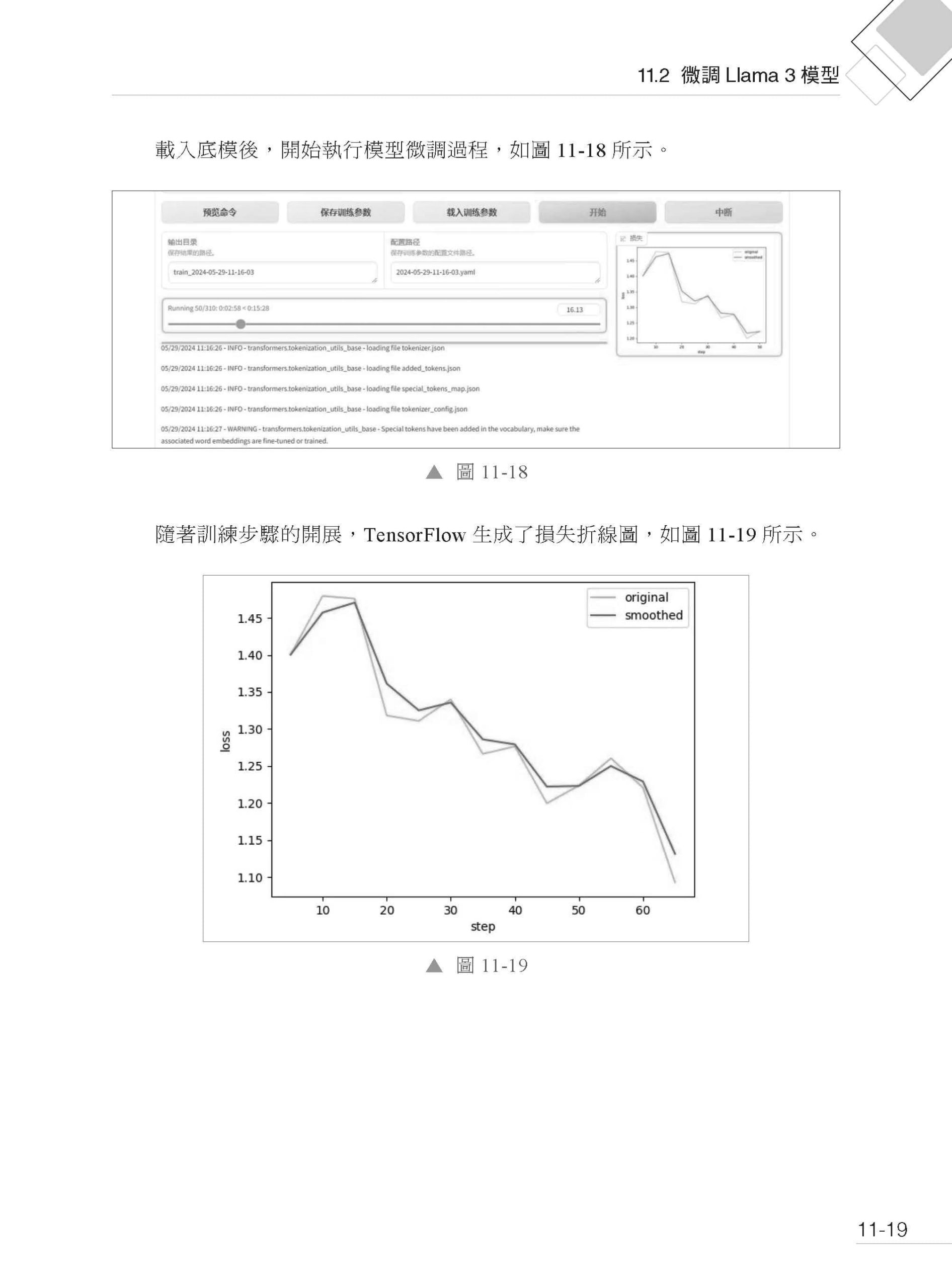
▌第11章 Llama 3 模型的微調、量化、部署和應用 11.1 準備工作 11.1.1 環境配置和相依函式庫安裝 11.1.2 資料收集和前置處理 11.2 微調Llama 3 模型 11.2.1 微調的意義與目標 11.2.2 Llama 3 模型下載 11.2.3 使用Llama-factory 進行LoRA 微調 11.3 模型量化 11.3.1 量化的概念與優勢 11.3.2 量化工具Llama.cpp 介紹 11.3.3 Llama.cpp 部署 11.4 模型部署 11.4.1 部署環境選擇 11.4.2 部署流程詳解 11.5 低程式應用範例 11.5.1 架設本地大語言模型 11.5.2 架設使用者介面 11.5.3 與知識庫相連 11.6 未來展望 |
序
| 自大語言模型爆紅之後,AI 已不再是程式設計師和科學研究人員的專屬工具,越來越多的業務人員開始使用AI 工具和各種大語言模型框架來提高工作效率。近年來,各種AI 工具層出不窮,基本上已經滲透到各行各業。AI 工具雖多,卻不是為每個業務人員量身定做的,很難與實際業務場景相結合,並且業務人員無法針對現有工具進行最佳化,使得AI 工具經常在各個業務場景中只是曇花一現,無法與實際業務場景深度結合。
那麼「AI+ 企業」這條路該如何走呢?絕對不是只依賴大語言模型與AI工具。現有的大語言模型雖然能力很強,能理解的知識面也很廣,但它就像一個光桿司令,只能回答人們提出的問題,無法實際執行各項任務。與之相反,AI 工具(當然也包括其他軟體、程式等)雖然可以執行各項任務,但其並不是Agent,通常需要人們預先定義好參數、設置好流程,然後才能執行實際的任務。總而言之,其還需要人參與到實際任務中,並不是真正意義上的全流程自動化。那麼能否將大語言模型與AI 工具結合在一起,讓大語言模型自己使用各種各樣的外部工具來完成任務呢?(就像人一樣,不僅擁有大腦,還具備雙手來使用各種工具,從而完成不同業務場景的任務。)目前的答案只有一個詞,那就是Agent。 Agent 具備哪些能力?為什麼它是目前「AI+ 行業」的唯一答案呢?下面列舉幾個關鍵字:感知、記憶、決策、回饋、工具呼叫、大語言模型、多Agent 協作。掌握了這些關鍵字,對Agent 就有了一個基本認識。 感知:能獲取周圍環境的資訊,如使用者輸入的資料、上傳的照片,或一個網頁連結,感知就是能夠理解使用者的輸入。 記憶:Agent 做過什麼事,得到過什麼樣的回饋,中間經歷了哪些過程,Agent 都需要記住,後面在做決策的時候還會參考之前的記憶,人類能「吾日三省吾身」,它也可以! 決策:現在Agent 配置了很多工具,它需要知道什麼時候用什麼工具,透過呼叫不同的工具來完成使用者交給它的任務。 回饋:這一次跌倒,下一次還要再跌倒嗎?既然有記憶,就要根據記憶進行反思,接下來做這件事的時候是不是該最佳化一下了。 工具呼叫:常見的方式就是使用API,讓Agent 具備各種各樣的能力,並且可以讓它根據感知和記憶的資訊來填寫其中的參數,從而實現自動化。 大語言模型:Agent 是如何完成感知、記憶和決策的呢?這些事都需要交給「大腦」,也就是大語言模型。 多Agent 協作:單兵作戰是可以完成一些工作的,但是面對複雜業務,就需要多個角色透過互動和分析來一起完成相應工作。 讀者不僅要從概念上理解Agent,還要動手跟著本書內容做一些實際業務場景的應用,包括使用各種Agent 框架實現實際的業務需求,以及外部工具的呼叫、大語言模型的微調、本地知識庫的架設,從而理解建構Agent 的全流程。接下來就一起動手來建構Agent 吧! 繁體中文出版說明 本書作者為中國大陸人士,書中部分使用服務、網站及軟體為中國大陸特有。為保持全書之完整及確保程式碼執行正確,本書部分圖片維持簡體中文介面,讀者可根據上下文閱讀,特此說明。 |