
網路爬蟲(web crawler)是一個程式,也稱做網路蜘蛛(spider),又被叫做網路機器人(robot)。主要是透過URL(Uniform Resource Locator)在遵循一定規則下,抓取網路相關訊息。
隨著大數據的發展,數據規模與種類越來越多,但真正有價值的數據卻像是沙漠中的綠洲。為了從這些大規模數據獲得有價值的資訊,因此有了網路爬蟲科學的發展,而從這些爬蟲獲得的資訊做更進一步的分析則造就了數據分析科學的發展。
本文將介紹網路爬蟲知識,同時也解說有關國內指標性論壇”批踢踢實業坊”的一些背景。PTT的一篇文章主要由標題、作者、推噓文數量、發表日期等構成,因此以下將展示如何查詢這些資料與數據。大量數據資料如果經過適當的處理、抽取出其中的資訊,就能讓我們見微知著,發揮出數位資訊驚人的妙用。一起來認識網路爬蟲吧!
爬蟲的類型
網路爬蟲可以根據爬蟲結構、技術與目的將爬蟲類型分成通用網路爬蟲、聚焦網路爬蟲。
通用網路爬蟲
常見的Google、Yahoo、百度搜尋引擎皆算是通用網路爬蟲類型,這類爬蟲主要是蒐集每個網站的特色數據,所爬取的範圍與數據量龐大。
聚焦網路爬蟲
又稱主題網路爬蟲,主要是依據需求選擇性的爬取相關頁面,不會廣泛爬取無關的頁面。
增量網路爬蟲
主要是指爬取新增網頁或是已經更新的網頁,對一些沒有更新的網頁不會執行下載。這類爬蟲可以減少數據下載量、在時間與儲存空間可以節省,相對需要比較複雜的演算法,設計執行上比較困難,實務上目前比較少使用。
深層網路爬蟲
是指大部分內容無法從靜態的URL取得,例如:需要用戶名稱與密碼的頁面,只有用戶提交表單時才能獲得的網頁訊息。
實務上我們可以將通用網路爬蟲稱搜尋引擎。
實務上聚焦網路爬蟲、增量網路爬蟲與深層網路爬蟲皆是有特定工作目的,執行定向爬取數據,可以將之歸為一類,這就是我們一般所稱的網路爬蟲。
搜尋引擎與爬蟲原理
搜尋引擎工作原理
搜尋引擎工作原理也可稱通用網路爬蟲工作原理,可以參考下圖:
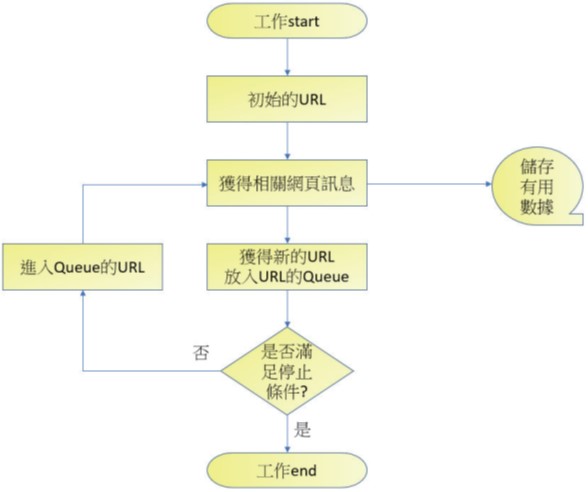
上述流程圖觀念如下:
- 首先我們可以給搜尋引擎一個最初化的URL,讓搜尋引擎開始工作。
- 搜尋引擎會根據URL獲得相關訊息,如果是有用的網頁訊息則儲存,如果發現新的URL則將此URL儲存至URL佇列(Queue)內。
- 如果搜尋條件滿足就離開,否則進入Queue的URL佇列。一般設計搜尋引擎會設置一個停止條件,搜尋引擎會在停止條件到達時終止爬取網頁工作。如果沒有設定終止條件,搜尋引擎會一直爬取,直到沒有新的URL,Queue的URL佇列是空的才停止。
- 從Queue的URL佇列提取一個新的URL,進入步驟2。
網路爬蟲工作原理
網路爬蟲工作原理與搜尋引擎類似,不過第一步是需增加設計爬蟲方案,一個網頁搜尋完畢需增加篩選新的URL,可以參考下圖:
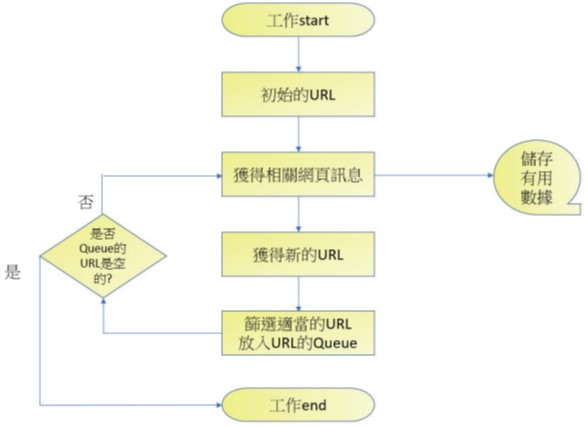
它的工作原理如下:
- 首先設定爬取內容與方案。
- 由所設定的URL開始工作,如果獲得相關有用的訊息則儲存。
- 開始工作時可能會發現新的URL,這時會將篩選有用的URL放置URL佇列(Queue)。
- 如果URL佇列是空的表示已經滿足此工作。
認識批踢踢實業坊
批踢踢實業坊簡稱批踢踢,或稱PTT,這是一個台灣的電子佈告欄(BBS),提供自由的言論空間,在台灣學術網路的資源上使用Telnet BBS技術運作。
此網站HTML結構清楚適合講解網路爬蟲操作,這也是本文的主題。
讀者可以使用下列網址進入PTT。